New Get Data Capabilities in the GA Release of SSDT Tabular 17.0 (April 2017)
With the General Availability (GA) release of SSDT 17.0, the modern Get Data experience in Analysis Service Tabular projects comes with several exciting improvements, including DirectQuery support (see the blog article “Introducing DirectQuery Support for Tabular 1400”), additional data sources (particularly file-based), and support for data access options that control how the mashup engine handles privacy levels, redirects, and null values. Moreover, the GA release coincides with the CTP 2.0 release of SQL Server 2017, so the modern Get Data experience benefits from significant performance improvements when importing data. Thanks to the tireless effort of the Mashup engine team, data import performance over structured data sources is now at par with legacy provider data sources. Internal testing shows that importing data from a SQL Server database through the Mashup engine is in fact faster than importing the same data by using SQL Server Native Client directly!
Last month, the blog article “What makes a Data Source a Data Source?” previewed context expressions for structured data sources—and the file-based data sources that SSDT Tabular 17.0 GA adds to the portfolio of available data sources make use of context expressions to define a generic file-based source as an Access Database, an Excel workbook, or as a CSV, XML, or JSON file. The following screenshot shows a structured data source with a context expression that SSDT Tabular created for importing an XML file.
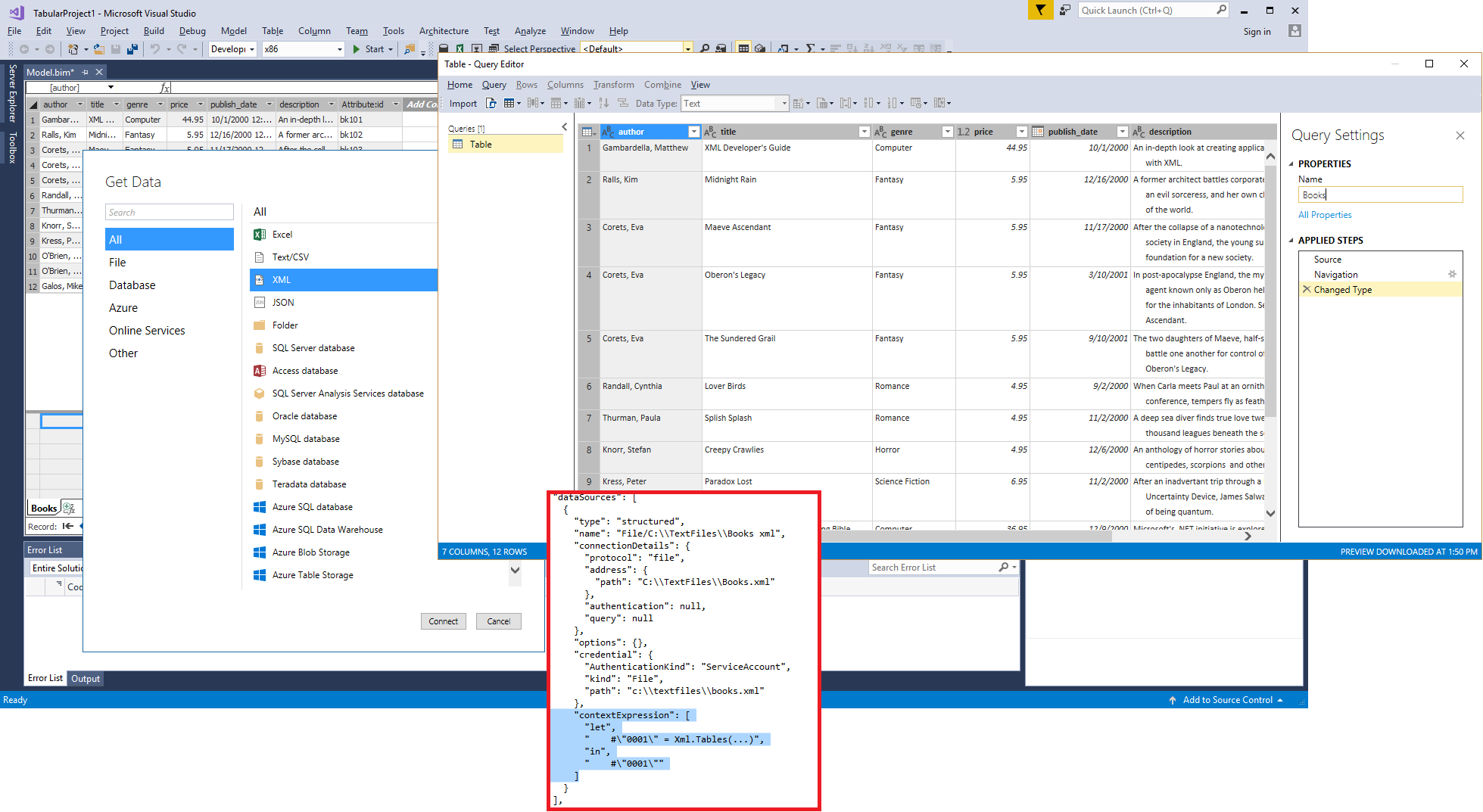
Note that file-based data sources are still a work in progress. Specifically, the Navigator window that Power BI Desktop shows for importing multiple tables from a source is not yet enabled so you end up immediately in the Query Editor in SSDT. This is not ideal because it makes it hard to import multiple tables. A forthcoming SSDT release is going to address this issue. Also, when trying to import from an Access database, note that SSDT Tabular in Integrated Workspace mode would require both the 32-bit and 64-bit ACE provider, but both cannot be installed on the same computer. This issue requires you to use a remote workspace server running SQL Server 2017 CTP 2.0, so that you can install the 32-bit driver on the SSDT workstation and the 64-bit driver on the server running Analysis Services CTP 2.0.
Keep in mind that SSDT Tabular 17.0 GA uses the Analysis Services CTP 2.0 database schema for Tabular 1400 models. This schema is incompatible with CTPs of SQL vNext Analysis Services. You cannot open Tabular 1400 models with previous schemas and you cannot deploy Tabular 1400 models with a CTP 2.0 database schema to a server running a previous CTP version.
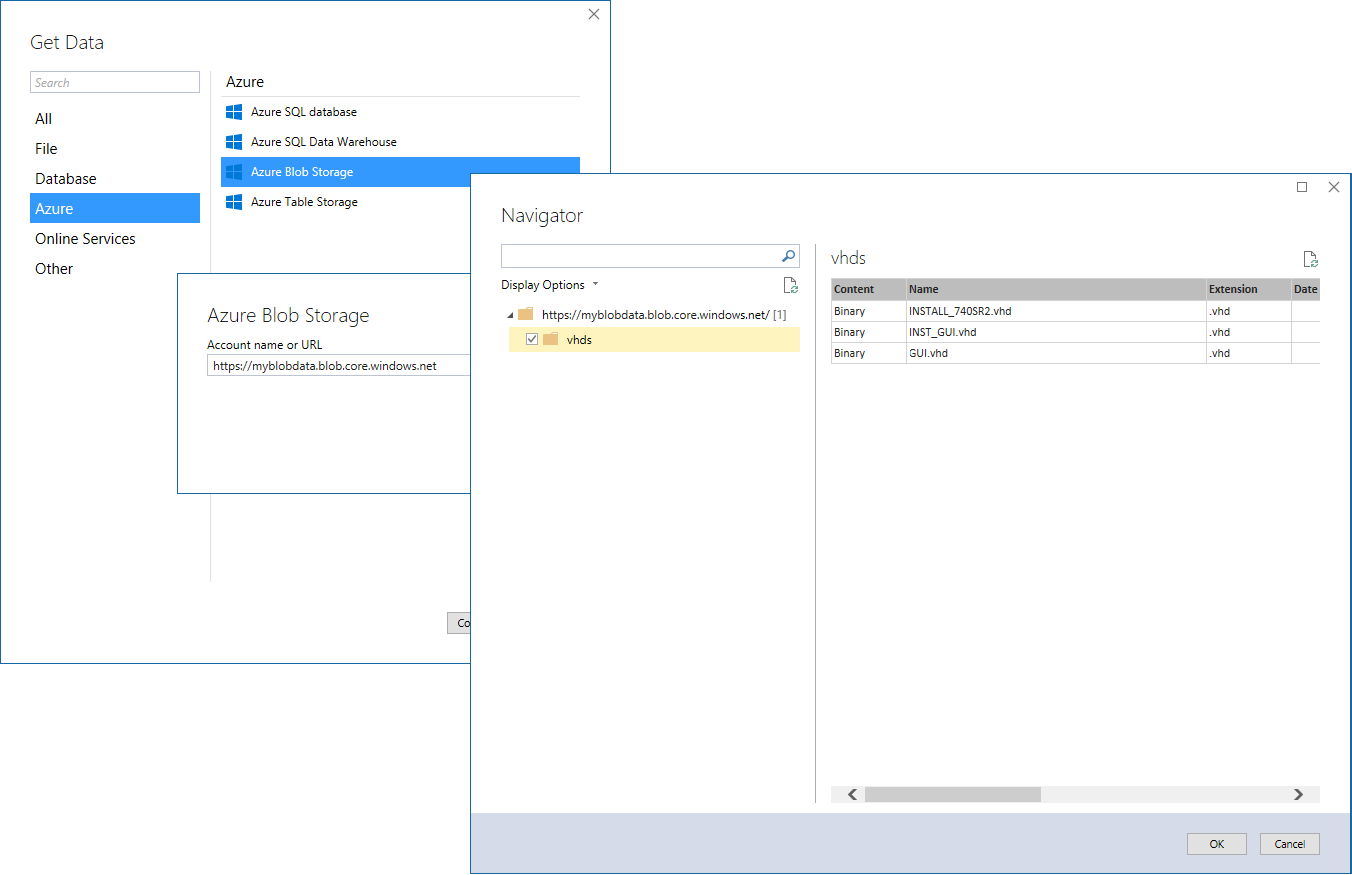
Another great data source that you can find for the first time in SSDT Tabular is Azure Blob Storage, which will be particularly interesting when Azure Analysis Services provides support for the 1400 compatibility level. When connecting to Azure Blob Storage, make sure you provide the account name or URL without any containers in the data source definition, such as https://myblobdata.blob.core.windows.net. If you appended a container name to the URL, SSDT Tabular would fail to generate the full set of data source settings. Instead, select the desired contain in the Navigator window, as illustrated in the following screenshot.
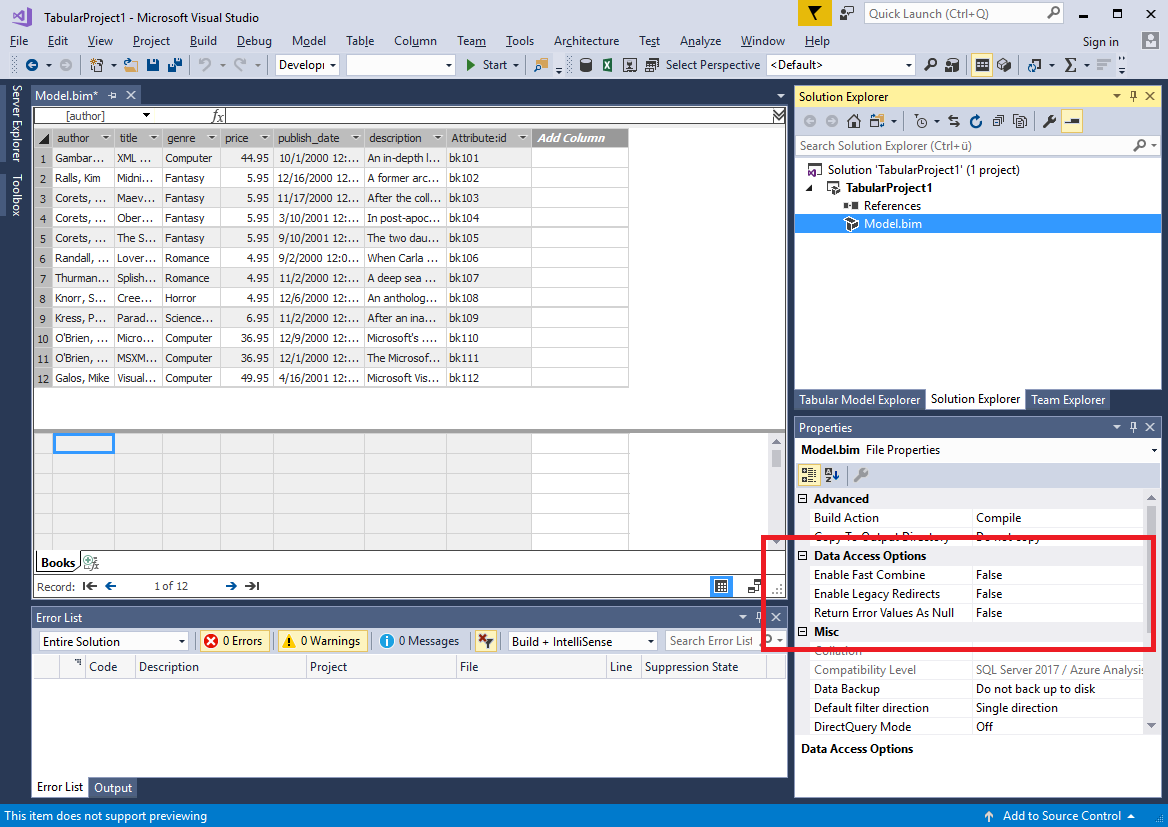
As mentioned above, SSDT Tabular 17.0 GA uses the Analysis Services CTP 2.0 database schema for Tabular 1400 models. This database schema is more complete than any previous schema version. Specifically, you can find additional Data Access Options in the Properties window when selecting the Model.bim file in Solution Explorer (see the following screenshot). These data access options correspond to those options in Power BI Desktop that are applicable to Tabular 1400 models hosted on an Analysis Services server, including:
- Enable Fast Combine (default is false) When set to true, the mashup engine will ignore data source privacy levels when combining data.
- Enable Legacy Redirects (default is false) When set to true, the mashup engine will follow HTTP redirects that are potentially insecure (for example, a redirect from an HTTPS to an HTTP URI).
- Return Error Values as Null (default is false) When set to true, cell level errors will be returned as null. When false, an exception will be raised if a cell contains an error.
And especially with the Enable Fast Combine setting you can now begin to refer to multiple data sources in a single source query.
Yet another great feature that is now available to you in SSDT Tabular is the Add Column from Example capability introduced with the April 2017 Update of Power BI Desktop. For details, refer to the article “Add a column from an example in Power BI Desktop.” The steps are practically identical. Add Column from Example is a great illustration of how the close collaboration and teamwork between the AS engine, Mashup engine, Power BI Desktop, and SSDT Tabular teams is compounding the value delivered to our customers.
Looking ahead, apart from tying up loose ends, such as the Navigator dialog for file-based sources, there is still a sizeable list of data sources we are going to add in further SSDT releases. Named expressions discussed in this blog article a while ago also still need to find their way into SSDT Tabular, and there are other things such as support for the full set of impersonation options that Analysis Services provides for data sources that can use Windows authentication. Currently, only service account and explicit Windows credentials can be used. Forthcoming impersonation options include current user and unattended accounts.
In short, the work to enable the modern Get Data experience in SSDT Tabular is not yet finished. Even though SSDT Tabular 17.0 GA is fully supported in production environments, Tabular 1400 is still evolving. The database schema is considered complete with CTP 2.0, but minor changes might still be coming. So please be invited to deploy SSDT Tabular 17.0 GA, use it to work with your Tabular 1200 models and take Tabular 1400 for a thorough test drive. And as always, please send us your feedback and suggestions by using ProBIToolsFeedback or SSASPrev at Microsoft.com. Or use any other available communication channels such as UserVoice or MSDN forums. Influence the evolution of the Analysis Services connectivity stack to the benefit of all our customers!
Comments
- Anonymous
April 19, 2017
I know PowerBI will be always ahead of SSAS on premise, but it seems Azure SSAS will be synchronized with PowerBI, can you guys explain what's the best practice to Develop for both.should we use PowerBI desktop only to develop datasets for PowerBI service, or SSDT will support that scenario too. and thanks, that's a fantastic release- Anonymous
April 19, 2017
Thanks for the feedback! We want to bridge the gap between Power BI and AS. Something similar to this is what we have in mind currently. Feel free to vote it up, might cause it to be done quicker! (+ you'll be notified when status changes).
- Anonymous
- Anonymous
April 20, 2017
The comment has been removed- Anonymous
April 21, 2017
The comment has been removed
- Anonymous
- Anonymous
April 20, 2017
You can install the ACE 32 and 64 bit drivers on the same computer by creating a shortcut to the installation file of the other driver you want to install, and adding "/passive" to the end of the target in the shortcut"C:\Users\Downloads\AccessDatabaseEngine.exe" /passive- Anonymous
April 21, 2017
Awesome! Thanks for adding a comment for this workaround, Joe. Truly appreciated.
- Anonymous
- Anonymous
April 21, 2017
"SSDT Tabular" ... starting to see this phrase used more and more... what is the implication? just SSDT + SSAS project template? or is there more to it?- Anonymous
April 21, 2017
SSDT means different things to different people, RDBMS, SSAS MD, SSAS Tabular, SSIS, SSRS, so “SSDT Tabular” hopefully makes it clear that this refers to the SSDT features available in the Analysis Services Tabular project type. That's pretty much it.
- Anonymous
- Anonymous
April 21, 2017
admittedly I don't work w/ a lot of tabular solutions using file-based sources... is the target use case simply enabling the "Power BI Grow Up Story" that Christian linked to in an earlier comment? Or are there a lot of companies looking to put a tabular model on top of their "spread-marts" and avoid the more traditional/costly/maintainable DW/ETL implementation? Or am I just reading too much into it?- Anonymous
April 21, 2017
That's a really good question, Bill, and I'm going to evade answering directly because I don't want to stop you reading too much into it. This new get data experience has so many valuable facets... Power BI is one aspect. Another is that you have way more data import capabilities than ever before, which can help you drive implementation costs down and reduce infrastructure complexity where reasonable. - Anonymous
April 21, 2017
Bill the issue is, Most of Business intelligence solution are based on spreadsheet and Desktop database solution, Personally I love to have access to a Data warehouse, but i never seen one, and I have been in my different companies.so now, we can still have a semantic model with minimum infrastructure investment, and that is very exciting for business users.
- Anonymous