Tutorial: Erstellen einer Apache Spark-Anwendung mit IntelliJ mithilfe eines Synapse-Arbeitsbereichs
In diesem Tutorial wird gezeigt, wie Sie mit dem Plug-In „Azure-Toolkit für IntelliJ“ in Scala geschriebene Apache Spark-Anwendungen entwickeln und anschließend direkt aus der IntelliJ-IDE (Integrated Development Environment, integrierte Entwicklungsumgebung) an einen serverlosen Apache Spark-Pool übermitteln. Sie können das Plug-In auf mehrere Arten verwenden:
- Entwickeln einer Scala Spark-Anwendung und Übermitteln der Anwendung an einen Spark-Pool
- Zugreifen auf die Ressourcen Ihres Spark-Pools
- Entwickeln und lokales Ausführen einer Scala Spark-Anwendung
In diesem Tutorial lernen Sie Folgendes:
- Verwenden des Plug-Ins „Azure-Toolkit für IntelliJ“
- Entwickeln von Apache Spark-Anwendungen
- Übermitteln einer Anwendung an Spark-Pools
Voraussetzungen
Azure-Toolkit-Plug-In 3.27.0-2019.2 (kann über das IntelliJ-Plug-In-Repository installiert werden)
Scala-Plug-In (kann über das IntelliJ-Plug-In-Repository installiert werden)
Die folgende Voraussetzung gilt nur für Windows-Benutzer:
Beim Ausführen der lokalen Spark Scala-Anwendung auf einem Windows-Computer wird unter Umständen eine Ausnahme wie unter SPARK-2356 beschrieben ausgelöst. Diese Ausnahme tritt auf, weil die Datei „WinUtils.exe“ in Windows fehlt. Zur Behebung dieses Fehlers müssen Sie die ausführbare WinUtils-Datei herunterladen und an einem Speicherort wie C:\WinUtils\bin speichern. Fügen Sie anschließend die Umgebungsvariable HADOOP_HOME hinzu, und legen Sie den Wert der Variable auf C:\WinUtils fest.
Erstellen einer Spark Scala-Anwendung für einen Spark-Pool
Starten Sie IntelliJ IDEA, und wählen Sie Create New Project (Neues Projekt erstellen) aus, um das Fenster New Project (Neues Projekt) zu öffnen.
Wählen Sie im linken Bereich Apache Spark/HDInsight aus.
Wählen Sie im Hauptfenster Spark Project with Samples (Scala) (Spark-Projekt mit Beispielen (Scala)) aus.
Wählen Sie in der Dropdownliste Build tool (Buildtool) einen der folgenden Typen aus:
- Maven für die Unterstützung des Scala-Projekterstellungs-Assistenten
- SBT zum Verwalten von Abhängigkeiten und Erstellen für das Scala-Projekt
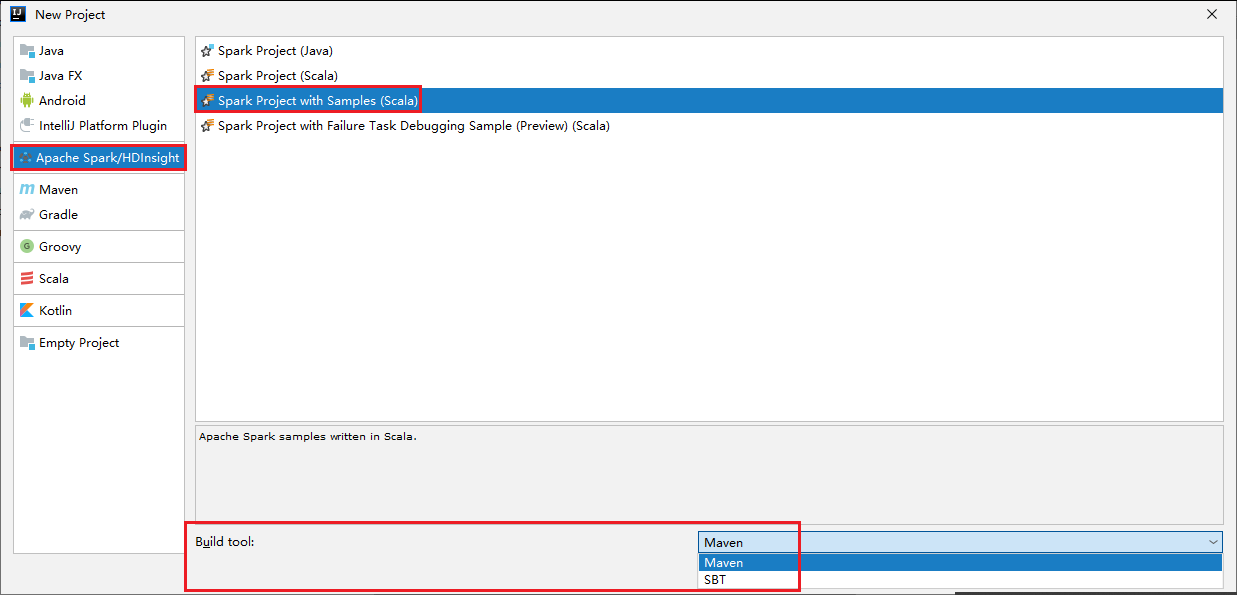
Wählen Sie Weiter aus.
Geben Sie im Fenster New Project (Neues Projekt) die folgenden Informationen an:
Eigenschaft BESCHREIBUNG Projektname Geben Sie einen Namen ein. In diesem Tutorial wird myAppverwendet.Projektspeicherort Geben Sie den gewünschten Speicherort für Ihr Projekt ein. Project SDK (Projekt-SDK) Dieses Feld ist bei der erstmaligen Verwendung von IDEA möglicherweise leer. Wählen Sie New... (Neu...) aus, und navigieren Sie zu Ihrem JDK. Spark-Version Der Erstellungs-Assistent integriert die passende Version für das Spark-SDK und das Scala-SDK. Hier können Sie die Spark-Version auswählen, die Sie benötigen. 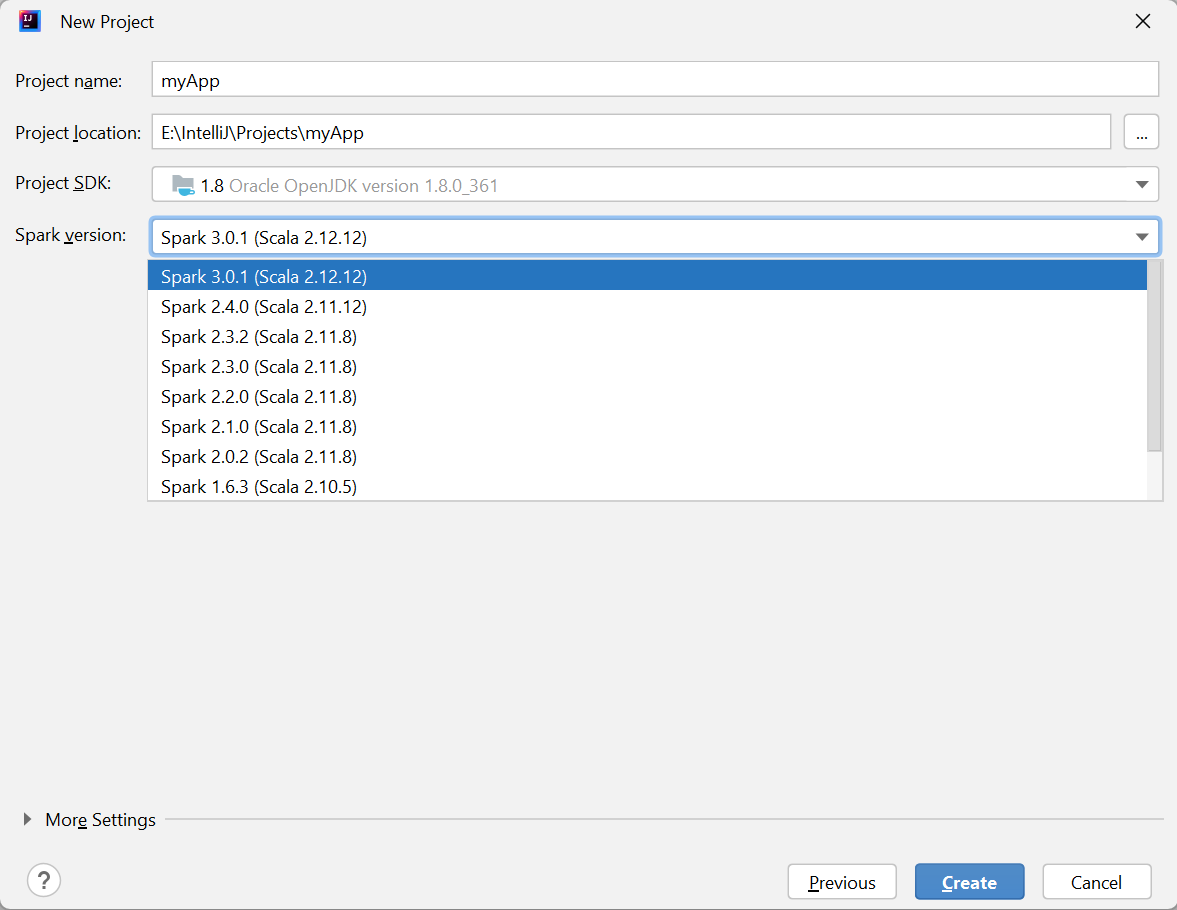
Wählen Sie Fertig stellen aus. Es kann einige Minuten dauern, bis das Projekt verfügbar ist.
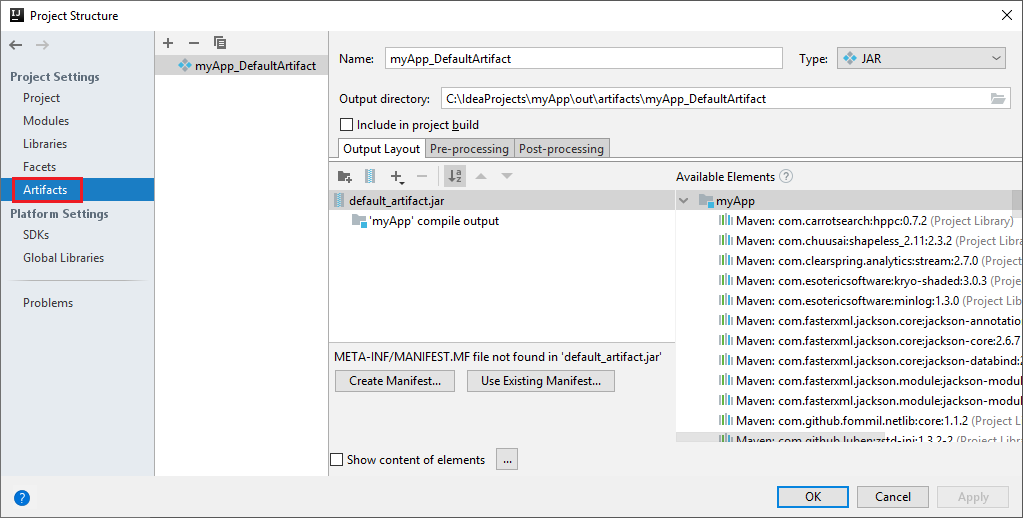
Das Spark-Projekt erstellt automatisch ein Artefakt. Führen Sie zum Anzeigen des Artefakts die folgenden Schritte aus:
a. Navigieren Sie auf der Menüleiste zu Datei>Projektstruktur.
b. Wählen Sie im Fenster Projektstruktur die Option Artefakte aus.
c. Wählen Sie Abbrechen aus, nachdem Sie sich das Artefakt angesehen haben.
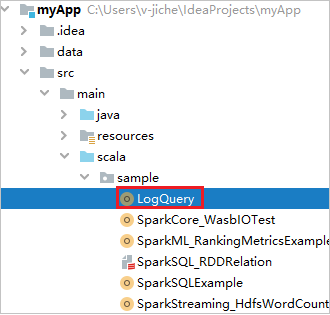
Navigieren Sie unter myApp>src>main>scala>sample>LogQuery zu LogQuery. In diesem Tutorial wird LogQuery verwendet.
Herstellen einer Verbindung mit Ihren Spark-Pools
Melden Sie sich beim Azure-Abonnement an, um eine Verbindung mit Ihren Spark-Pools herzustellen.
Melden Sie sich bei Ihrem Azure-Abonnement an.
Navigieren Sie in der Menüleiste zu Ansicht>Toolfenster>Azure Explorer.
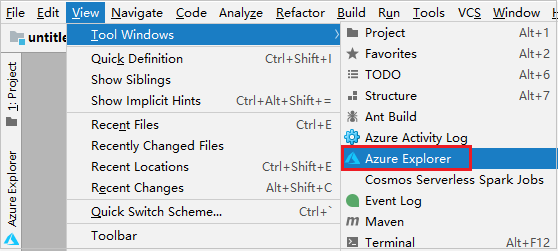
Klicken Sie im Azure Explorer mit der rechten Maustaste auf den Knoten Azure, und wählen Sie dann Anmelden aus.
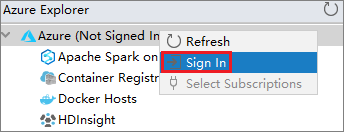
Wählen Sie im Dialogfeld Azure Sign In (Azure-Anmeldung) die Option Device Login (Geräteanmeldung) aus, und klicken Sie dann auf Sign in (Anmelden).
Wählen Sie im Dialogfeld Azure Device Login (Azure-Geräteanmeldung) die Option Copy&Open (Kopieren und öffnen) aus.
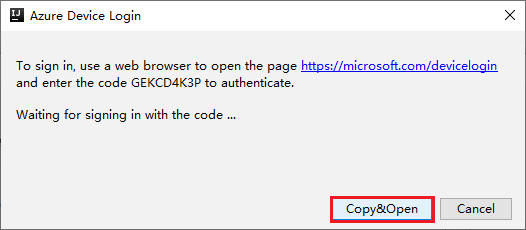
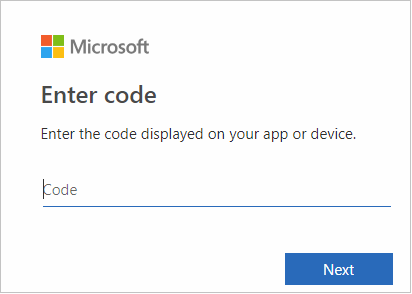
Fügen Sie den Code auf der Benutzeroberfläche des Browsers ein, und wählen Sie dann Next (Weiter) aus.
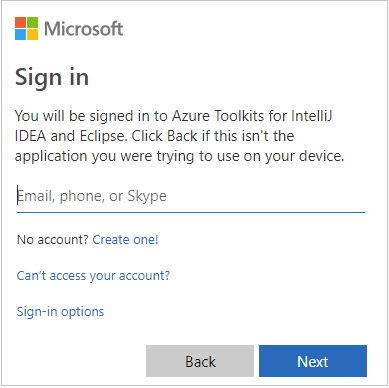
Geben Sie Ihre Azure-Anmeldeinformationen ein, und schließen Sie den Browser.
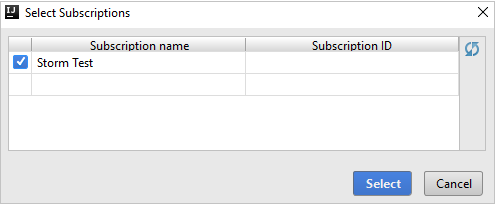
Nachdem Sie sich angemeldet haben, werden im Dialogfeld Abonnements auswählen alle Azure-Abonnements aufgelistet, die den Anmeldeinformationen zugeordnet sind. Wählen Sie Ihr Abonnement und anschließend Auswählen aus.
Erweitern Sie im Azure-Explorer die Option Apache Spark on Synapse (Apache Spark in Synapse), um die in Ihren Abonnements enthaltenen Arbeitsbereiche anzuzeigen.
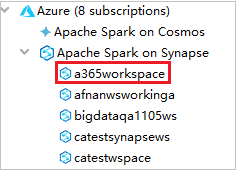
Zum Anzeigen der Spark-Pools können Sie einen Arbeitsbereich noch weiter erweitern.
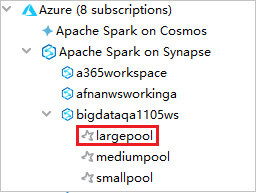
Remoteausführung einer Spark Scala-Anwendung für einen Spark-Pool
Nachdem Sie eine Scala-Anwendung erstellt haben, können Sie sie remote ausführen.
Öffnen Sie das Fenster für die Ausführungs-/Debugkonfiguration, indem Sie das Symbol auswählen.
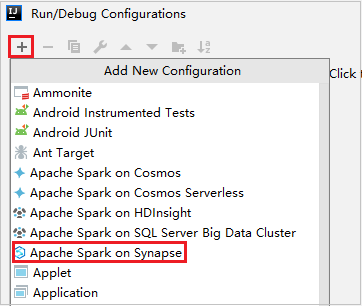
Wählen Sie im Dialogfeld für die Ausführungs-/Debugkonfiguration die Option + und anschließend Apache Spark on Synapse (Apache Spark in Synapse) aus.
Geben Sie im Fenster für die Ausführungs-/Debugkonfiguration die folgenden Werte an, und wählen Sie anschließend OK aus:
Eigenschaft Wert Spark-Pools Wählen Sie die Spark-Pools aus, in denen Sie Ihre Anwendung ausführen möchten. Select an Artifact to submit (Auswahl eines zu übermittelnden Artefakts) Behalten Sie die Standardeinstellung bei. „Main class name“ (Name der Hauptklasse) Der Standardwert ist die Hauptklasse der ausgewählten Datei. Sie können die Klasse ändern, indem Sie die Schaltfläche mit den Auslassungspunkten ( … ) und anschließend eine andere Klasse auswählen. Job configurations (Auftragskonfigurationen) Sie können die Standardschlüssel und -werte ändern. Weitere Informationen finden Sie unter Apache Livy-REST-API. Befehlszeilenargumente Sie können bei Bedarf durch Leerzeichen getrennte Argumente für die Hauptklasse eingeben. Referenced Jars and Referenced Files („Referenzierte JARs“ und „Referenzierte Dateien“) Sie können bei Bedarf die Pfade für die JAR-Dateien und für die anderen Dateien eingeben, auf die verwiesen wird. Sie können auch Dateien im virtuellen Dateisystem von Azure durchsuchen, das derzeit nur ADLS Gen2-Cluster unterstützt. Weitere Informationen finden Sie unter: Apache Spark-Konfiguration und Schnellstart: Verwenden von Azure Storage-Explorer zum Erstellen eines Blobs. Job Upload Storage (Speicher für Auftragsupload) Erweitern Sie die Option, um zusätzliche Optionen anzuzeigen. Speichertyp Wählen Sie in der Dropdownliste Use Azure Blob to upload (Azure-Blob für Upload verwenden) oder Use cluster default storage account to upload (Standardspeicherkonto des Clusters für Upload verwenden). Speicherkonto Geben Sie Ihr Speicherkonto ein. Storage Key (Speicherschlüssel) Geben Sie Ihren Speicherschlüssel ein. Speichercontainer Wählen Sie Ihren Speichercontainer aus der Dropdownliste aus, nachdem Sie Storage Account (Speicherkonto) und Storage Key (Speicherschlüssel) eingegeben haben. 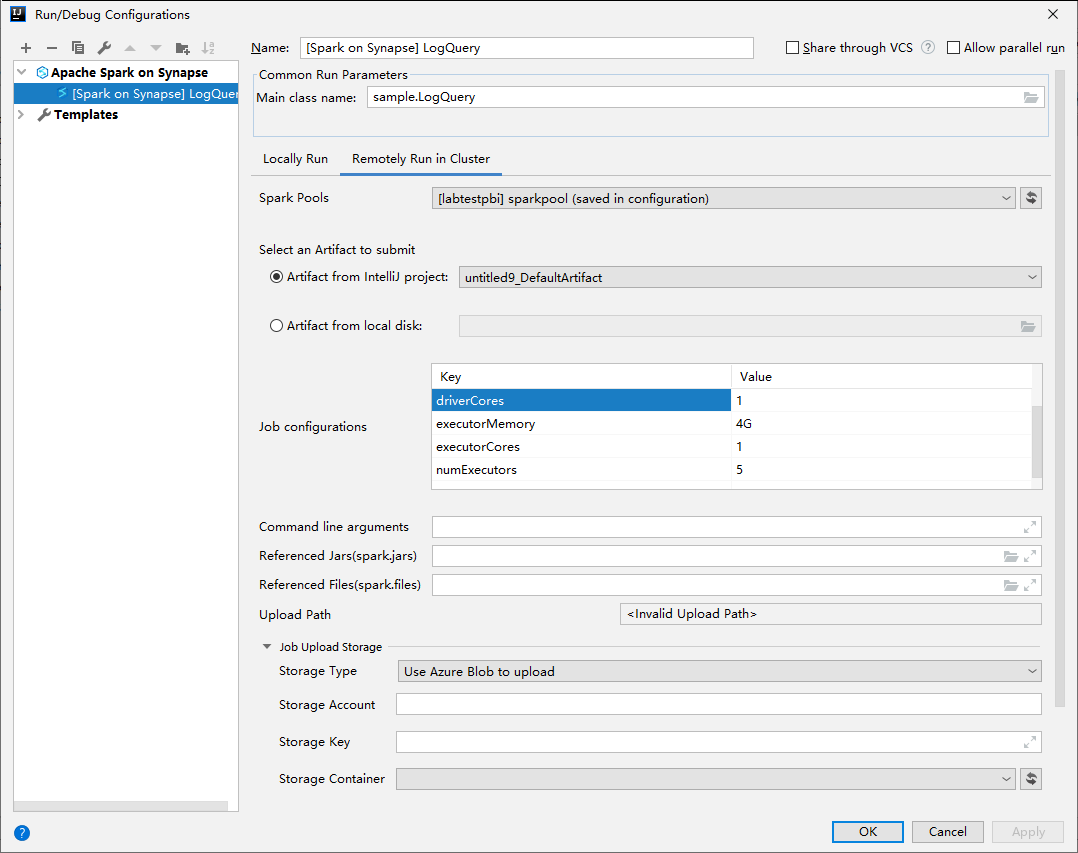
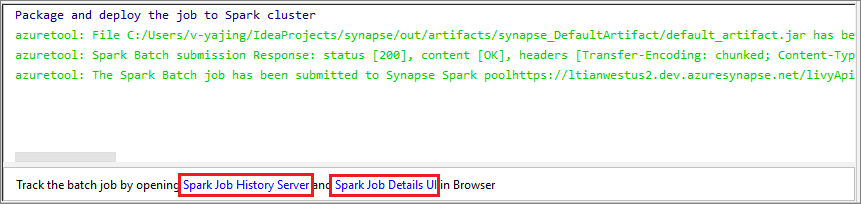
Wählen Sie das Symbol SparkJobRun aus, um Ihr Projekt an den ausgewählten Spark-Pool zu übermitteln. Auf der Registerkarte Remote Spark Job in Cluster (Remote-Spark-Auftrag auf Cluster) wird im unteren Bereich der Fortschritt der Auftragsausführung angezeigt. Sie können die Anwendung anhalten, indem Sie die rote Schaltfläche auswählen.

Lokales Ausführen/Debuggen von Apache Spark-Anwendungen
Im Anschluss erfahren Sie, wie Sie das lokale Ausführen und Debuggen für Ihren Apache Spark-Auftrag einrichten.
Szenario 1: Lokales Ausführen
Wählen Sie im Dialogfeld für die Ausführungs-/Debugkonfiguration das Plussymbol (+) aus. Wählen Sie anschließend die Option Apache Spark on Synapse (Apache Spark in Synapse) aus. Geben Sie zu speichernde Informationen für Name und Main class name (Name der main-Klasse) ein.
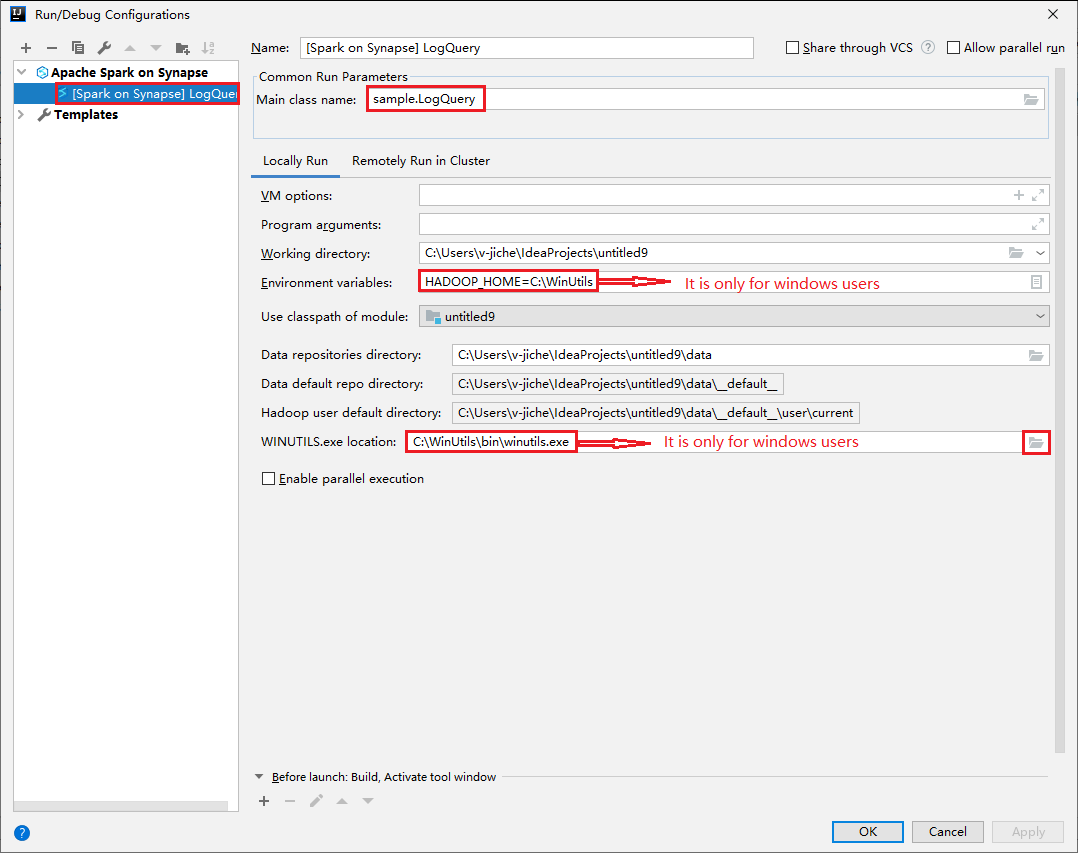
- Umgebungsvariablen und der Speicherort von „WinUtils.exe“ sind nur für Windows-Benutzer relevant.
- Umgebungsvariablen: Die Systemumgebungsvariable kann automatisch erkannt werden, wenn Sie sie zuvor festgelegt haben. In diesem Fall muss sie nicht manuell hinzugefügt werden.
- WinUtils.exe Location (Speicherort von „WinUtils.exe“): Zum Angeben des WinUtils-Speicherorts können Sie auf der rechten Seite das Ordnersymbol auswählen.
Wählen Sie anschließend die Schaltfläche für die lokale Wiedergabe aus.

Nach Abschluss der lokalen Ausführung können Sie die Ausgabedatei unter data>default überprüfen, sofern das Skript eine Ausgabe enthält.
Szenario 2: Lokales Debuggen
Öffnen Sie das Skript LogQuery, und legen Sie Breakpoints fest.
Wählen Sie das Symbol für Lokales Debuggen aus, um lokales Debuggen durchzuführen.

Zugreifen auf und Verwalten von Synapse-Arbeitsbereichen
Im Azure-Explorer im Azure-Toolkit für IntelliJ können verschiedene Vorgänge ausgeführt werden. Navigieren Sie in der Menüleiste zu Ansicht>Toolfenster>Azure Explorer.
Starten des Arbeitsbereichs
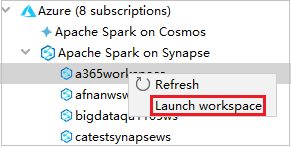
Navigieren Sie im Azure-Explorer zu Apache Spark on Synapse (Apache Spark in Synapse), und erweitern Sie den Knoten.
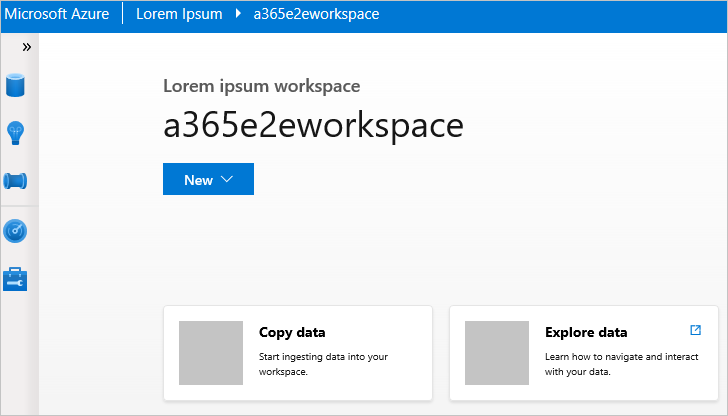
Klicken Sie mit der rechten Maustaste auf einen Arbeitsbereich, und wählen Sie Arbeitsbereich starten aus. Daraufhin wird eine Website geöffnet.
Spark-Konsole
Sie können „Spark Local Console(Scala)“ (Lokale Spark-Konsole (Scala)) oder „Spark Livy Interactive Session Console(Scala)“ (Spark-Livy-Konsole für interaktive Sitzungen) ausführen.
Lokale Spark-Konsole (Scala)
Vergewissern Sie sich, dass die Voraussetzung für „WINUTILS.EXE“ erfüllt wurde.
Navigieren Sie in der Menüleiste zu Run (Ausführen)>Edit Configurations... (Konfigurationen bearbeiten…).
Navigieren Sie im Fenster für die Ausführungs-/Debugkonfiguration im linken Bereich zu Apache Spark on Synapse>[Spark on Synapse] myApp (Apache Spark in Synapse > [Spark in Synapse] myApp).
Klicken Sie im Hauptfenster auf die Registerkarte Locally Run (Lokal ausführen).
Geben Sie die folgenden Werte an, und klicken Sie anschließend auf OK:
Eigenschaft Wert Umgebungsvariablen Stellen Sie sicher, dass für HADOOP_HOME der richtige Wert festgelegt ist. „WINUTILS.exe location“ (Speicherort von „WINUTILS.exe“) Stellen Sie sicher, dass der richtige Pfad festgelegt ist. 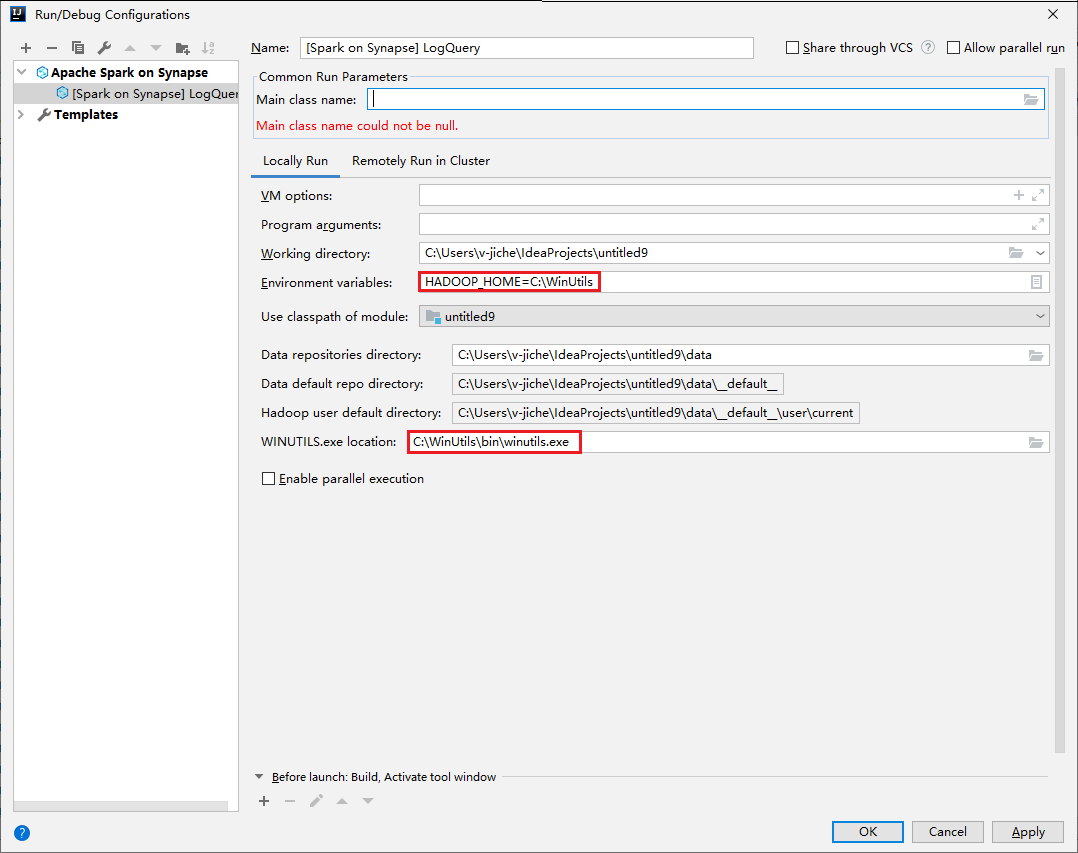
Navigieren Sie in „Project“ (Projekt) zu myApp>src>main>scala>myApp.
Navigieren Sie über die Menüleiste zu Tools>Spark Console>Run Spark Local Console(Scala) (Tools > Spark-Konsole > Lokale Spark-Konsole (Scala) ausführen).
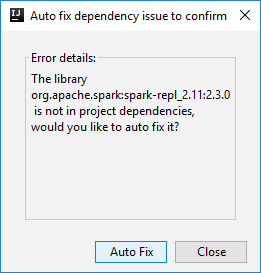
Zwei Dialogfelder werden möglicherweise angezeigt, in denen Sie gefragt werden, ob Probleme mit Abhängigkeiten automatisch behoben werden sollen. Klicken Sie ggf. auf Auto Fix (Automatisch beheben).
Die Konsole sollte in etwa wie auf dem folgenden Screenshot aussehen. Geben Sie im Konsolenfenster
sc.appNameein, und drücken Sie STRG+EINGABETASTE. Das Ergebnis wird angezeigt. Sie können die lokale Konsole beenden, indem Sie die rote Schaltfläche auswählen.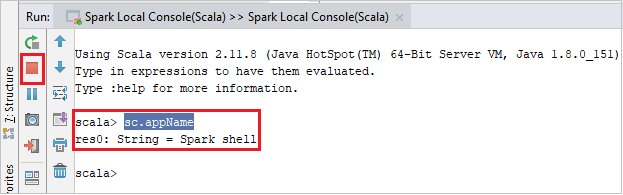
Spark-Konsole mit interaktiver Livy-Sitzung (Scala)
Wird nur für IntelliJ 2018.2 und 2018.3 unterstützt.
Navigieren Sie in der Menüleiste zu Run (Ausführen)>Edit Configurations... (Konfigurationen bearbeiten…).
Navigieren Sie im Fenster für die Ausführungs-/Debugkonfiguration im linken Bereich zu Apache Spark on synapse>[Spark on synapse] myApp (Apache Spark in Synapse > [Spark in Synapse] myApp).
Klicken Sie im Hauptfenster auf die Registerkarte Remotely Run in Cluster (Remoteausführung in Cluster).
Geben Sie die folgenden Werte an, und klicken Sie anschließend auf OK:
Eigenschaft Wert „Main class name“ (Name der Hauptklasse) Wählen Sie den Namen der Hauptklasse aus. Spark-Pools Wählen Sie die Spark-Pools aus, in denen Sie Ihre Anwendung ausführen möchten. 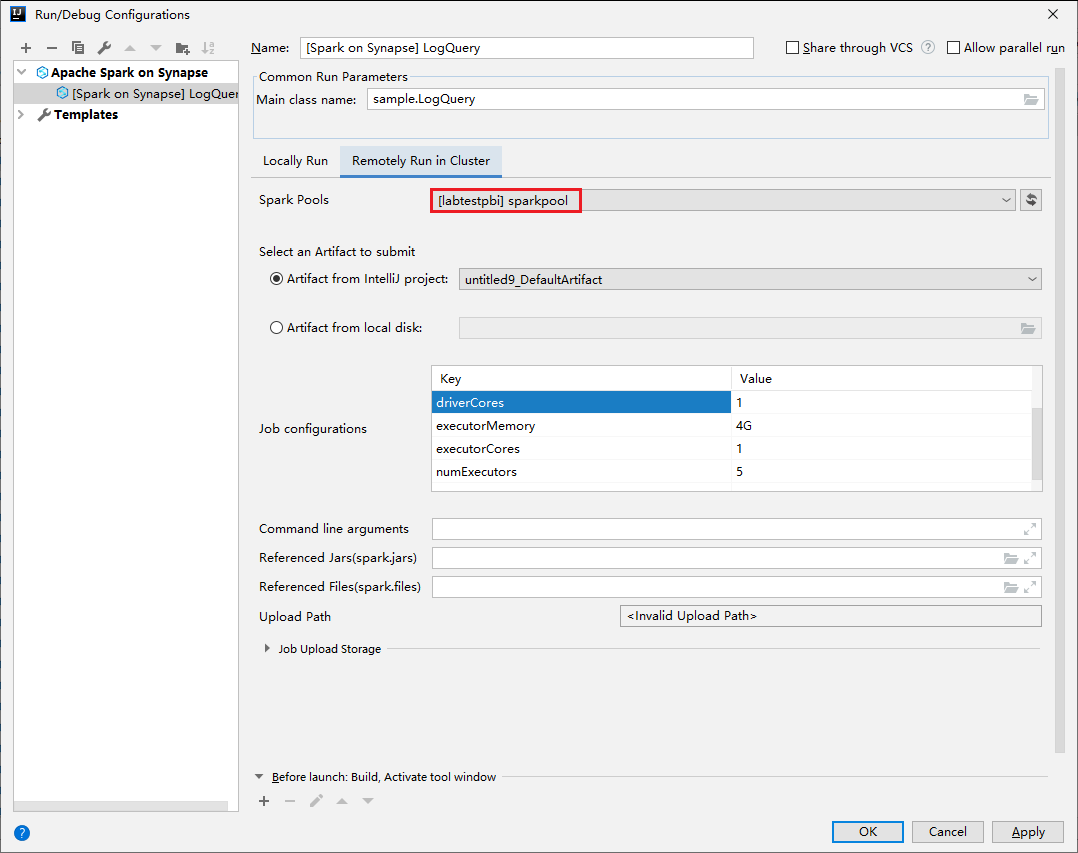
Navigieren Sie in „Project“ (Projekt) zu myApp>src>main>scala>myApp.
Navigieren Sie über die Menüleiste zu Tools>Spark console>Run Spark Livy Interactive Session Console(Scala) (Tools > Spark-Konsole > Spark-Konsole mit interaktiver Livy-Sitzung (Scala) ausführen).
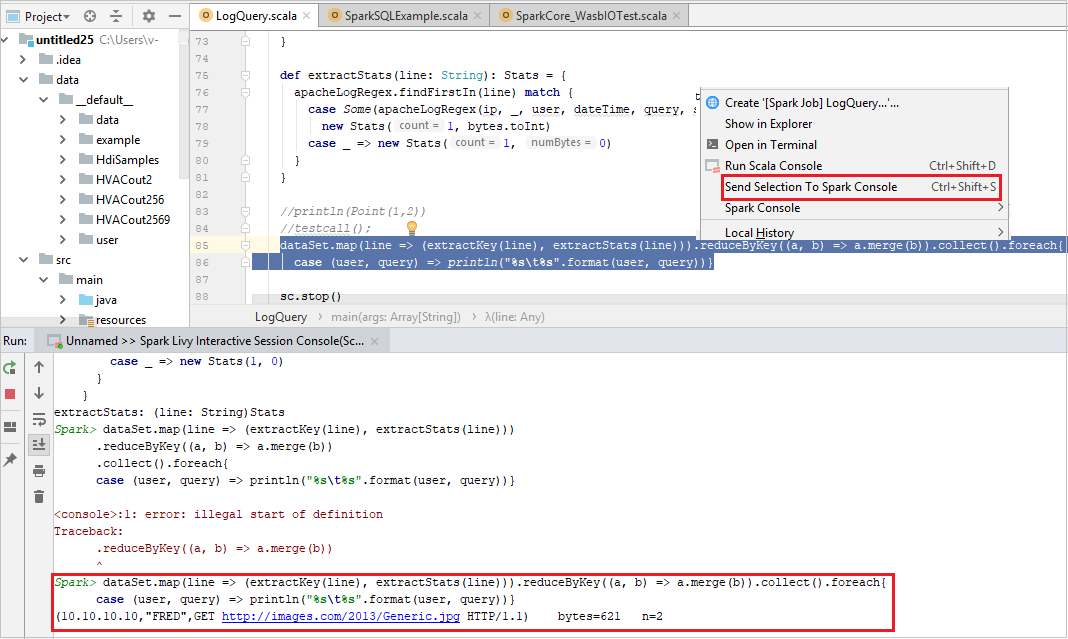
Die Konsole sollte in etwa wie auf dem folgenden Screenshot aussehen. Geben Sie im Konsolenfenster
sc.appNameein, und drücken Sie STRG+EINGABETASTE. Das Ergebnis wird angezeigt. Sie können die lokale Konsole beenden, indem Sie die rote Schaltfläche auswählen.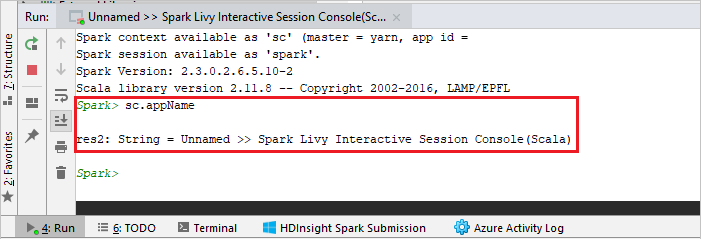
Senden der Auswahl an die Spark-Konsole
Sie können sich die Ergebnisse eines Skripts ansehen, indem Sie Code an die lokale Konsole oder an die Livy-Konsole für interaktive Sitzungen (Scala) senden. Markieren Sie dazu Code in der Scala-Datei, und klicken Sie mit der rechten Maustaste auf Send Selection To Spark Console (Auswahl an Spark-Konsole senden). Der ausgewählte Code wird an die Konsole gesendet und ausgeführt. Das Ergebnis wird nach dem Code in der Konsole angezeigt. Die Konsole überprüft, ob Fehler vorliegen.