Schnellstart: Erfassen von Daten mithilfe von Azure Synapse-Pipelines (Vorschau)
In dieser Schnellstartanleitung erfahren Sie, wie Sie Daten aus einer Datenquelle in einen Azure Synapse Data Explorer-Pool laden.
Voraussetzungen
Ein Azure-Abonnement. Erstellen Sie ein kostenloses Azure-Konto.
Erstellen eines Data Explorer-Pools über Synapse Studio oder im Azure-Portal
Erstellen Sie eine Data Explorer-Datenbank.
Wählen Sie in Synapse Studio im linken Bereich Daten aus.
Wählen Sie + (Neue Ressource hinzufügen) >Data Explorer-Pool aus, und verwenden Sie die folgenden Informationen:
Einstellung Vorgeschlagener Wert BESCHREIBUNG Poolname contosodataexplorer Name des zu verwendende Data Explorer-Pools Name TestDatabase Der Datenbankname muss innerhalb des Clusters eindeutig sein. Standardaufbewahrungszeitraum 365 Die Zeitspanne (in Tagen), für die garantiert wird, dass die Daten für Abfragen verfügbar bleiben. Die Zeitspanne wird ab dem Zeitpunkt gemessen, zu dem die Daten erfasst werden. Standardcachezeitraum 31 Die Zeitspanne (in Tagen), wie lange häufig abgefragte Daten im SSD-Speicher oder RAM (und nicht im längerfristigen Speicher) verfügbar bleiben. Wählen Sie Erstellen, um die Datenbank zu erstellen. Die Erstellung dauert in der Regel weniger als eine Minute.
Erstellen einer Tabelle
- Wählen Sie in Synapse Studio im linken Bereich Entwickeln aus.
- Wählen Sie unter KQL-Skripts die Option + (Neue Ressource hinzufügen) >KQL-Skript aus. Im rechten Bereich können Sie Ihr Skript benennen.
- Wählen Sie im Menü Verbinden mit den Eintrag contosodataexplorer aus.
- Wählen Sie im Menü Datenbank verwenden die Option TestDatabase aus.
- Fügen Sie den folgenden Befehl ein, und wählen Sie Ausführen aus, um die Tabelle zu erstellen.
.create table StormEvents (StartTime: datetime, EndTime: datetime, EpisodeId: int, EventId: int, State: string, EventType: string, InjuriesDirect: int, InjuriesIndirect: int, DeathsDirect: int, DeathsIndirect: int, DamageProperty: int, DamageCrops: int, Source: string, BeginLocation: string, EndLocation: string, BeginLat: real, BeginLon: real, EndLat: real, EndLon: real, EpisodeNarrative: string, EventNarrative: string, StormSummary: dynamic)Tipp
Vergewissern Sie sich, dass die Tabelle erstellt wurde. Wählen Sie im linken Bereich Daten, dann das Menü mit weiteren Optionen für contosodataexplorer und anschließend Aktualisieren aus. Erweitern Sie unter contosodataexplorer den Knoten Tabellen, und stellen Sie sicher, dass die Tabelle StormEvents in der Liste angezeigt wird.
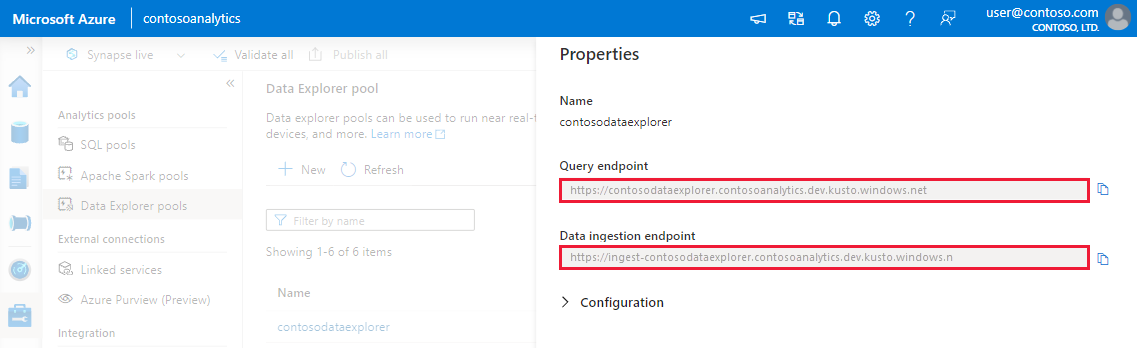
Abrufen der Abfrage- und Datenerfassungsendpunkte Sie benötigen den Abfrageendpunkt zum Konfigurieren Ihres verknüpften Diensts.
Wählen Sie in Synapse Studio im linken Bereich die Option Verwalten>Data Explorer-Pools aus.
Wählen Sie den Data Explorer-Pool aus, zu dem Sie Details anzeigen möchten.
Notieren Sie sich die Abfrage- und Datenerfassungsendpunkte. Verwenden Sie den Abfrageendpunkt als Cluster, wenn Sie Verbindungen mit Ihrem Data Explorer-Pool konfigurieren. Verwenden Sie beim Konfigurieren von SDKs für die Datenerfassung den Datenerfassungsendpunkt.
Erstellen eines verknüpften Diensts
In Azure Synapse Analytics definieren Sie in einem verknüpften Dienst Ihre Verbindungsinformationen für andere Dienste. In diesem Abschnitt erstellen Sie einen verknüpften Dienst für Azure Data Explorer.
Wählen Sie in Synapse Studio im linken Bereich Verwalten>Verknüpfte Dienste aus.
Wählen Sie + Neu aus.
Wählen Sie im Katalog den Dienst Azure Data Explorer und dann Weiter aus.

Verwenden Sie auf der Seite „Neue verknüpfte Dienste“ die folgenden Informationen:
Einstellung Vorgeschlagener Wert Beschreibung Name contosodataexplorerlinkedservice Der Name für den neuen verknüpften Azure Data Explorer-Dienst Authentifizierungsmethode Verwaltete Identität Die Authentifizierungsmethode für den neuen Dienst Kontoauswahlmethode Manuell eingeben Die Methode zum Angeben des Abfrageendpunkts Endpunkt https://contosodataexplorer.contosoanalytics.dev.kusto.windows.net Der Abfrageendpunkt, den Sie sich zuvor notiert haben Datenbank TestDatabase Die Datenbank, in der Sie Daten erfassen möchten 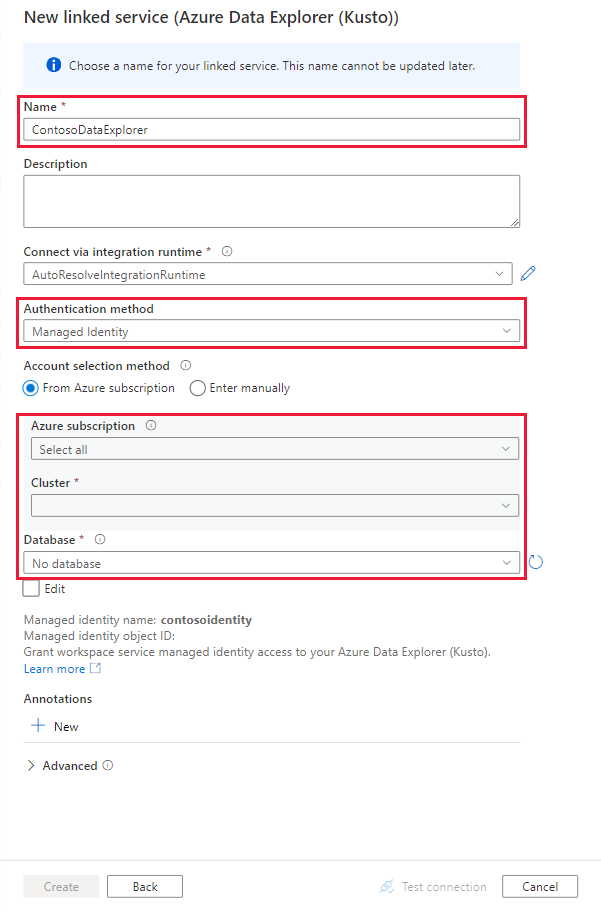
Wählen Sie Verbindung testen aus, um die Einstellungen zu überprüfen, und wählen Sie dann Erstellen aus.
Erstellen einer Pipeline zum Erfassen von Daten
Eine Pipeline enthält den logischen Ablauf für die Ausführung einer Aktivitätenmenge. In diesem Abschnitt erstellen Sie eine Pipeline mit einer Copy-Aktivität, die Daten aus Ihrer bevorzugten Quelle in einem Data Explorer-Pool erfasst.
Wählen Sie in Synapse Studio im linken Bereich Integrieren aus.
Wählen Sie +>Pipeline aus. Im rechten Bereich können Sie Ihre Pipeline benennen.
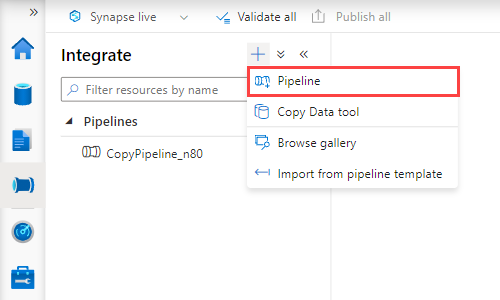
Ziehen Sie unter Aktivitäten>Verschieben und transformieren den Befehl Daten kopieren auf die Pipelinecanvas.
Wählen Sie die Copy-Aktivität aus, und wechseln Sie zur Registerkarte Quelle. Wählen Sie ein neues Quelldataset als Quelle aus, aus der Daten kopiert werden sollen, oder erstellen Sie ein neues Quelldataset.
Wechseln Sie zur Registerkarte Senke. Klicken Sie auf Neu, um ein neues Senkendataset zu erstellen.
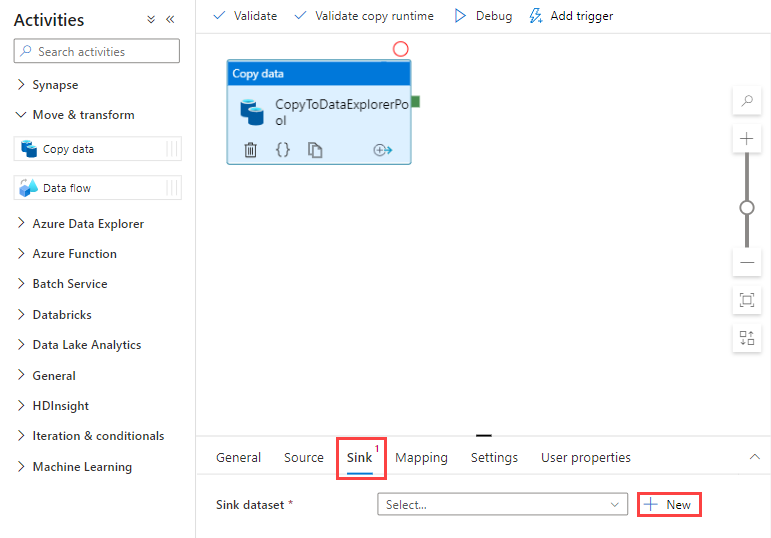
Wählen Sie im Katalog das Dataset Azure Data Explorer und dann Weiter aus.
Verwenden Sie im Bereich Eigenschaften festlegen die folgenden Informationen, und wählen Sie dann OK aus.
Einstellung Vorgeschlagener Wert Beschreibung Name AzureDataExplorerTable Der Name für die neue Pipeline Verknüpfter Dienst contosodataexplorerlinkedservice Der verknüpfte Dienst, den Sie zuvor erstellt haben Tabelle StormEvents Die zuvor erstellte Tabelle 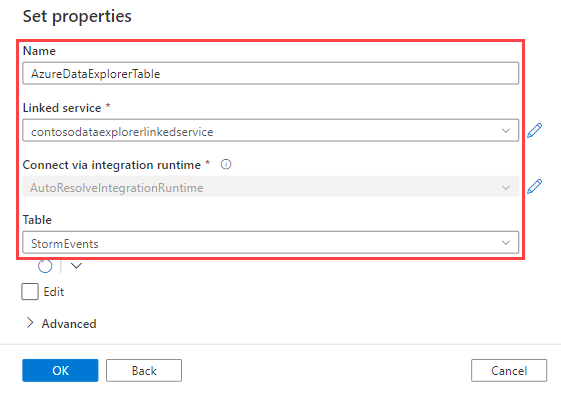
Wählen Sie zum Überprüfen der Pipeline auf der Symbolleiste die Option Überprüfen aus. Das Ergebnis der Pipelineüberprüfungsausgabe wird rechts auf der Seite angezeigt.
Debuggen und Veröffentlichen der Pipeline
Nach Abschluss der Konfiguration Ihrer Pipeline können Sie einen Debuglauf durchführen, bevor Sie Ihre Artefakte zur Überprüfung veröffentlichen, ob alles einwandfrei ist.
Wählen Sie auf der Symbolleiste Debuggen aus. Der Status der Pipelineausführung wird unten im Fenster auf der Registerkarte Ausgabe angezeigt.
Wenn die Pipelineausführung erfolgreich war, wählen Sie Alle veröffentlichen aus. Mit dieser Aktion werden erstellte Entitäten (Datasets und Pipelines) im Synapse Analytics-Dienst veröffentlicht.
Warten Sie, bis die Meldung Erfolgreich veröffentlicht angezeigt wird. Wenn Sie Benachrichtigungsmeldungen anzeigen möchten, wählen Sie oben rechts die Schaltfläche mit der Glocke aus.
Auslösen und Überwachen der Pipeline
In diesem Abschnitt lösen Sie die im vorherigen Schritt veröffentlichte Pipeline manuell aus.
Wählen Sie in der Symbolleiste die Option Trigger hinzufügen und dann Jetzt auslösen. Klicken Sie auf der Seite Pipelineausführung auf OK.
Wechseln Sie in der linken Randleiste zur Registerkarte Monitor. Sie sehen eine Pipelineausführung, die von einem manuellen Trigger ausgelöst wird.
Wenn die Pipelineausführung erfolgreich abgeschlossen wurde, wählen Sie den Link unter der Spalte Pipelinename aus, um Details zur Aktivitätsausführung anzuzeigen oder die Pipeline erneut auszuführen. Da in diesem Beispiel nur eine Aktivität vorhanden ist, wird in der Liste nur ein Eintrag angezeigt.
Wenn Sie Details zum Kopiervorgang anzeigen möchten, wählen Sie unter der Spalte Activity name (Aktivitätsname) den Link Details (das Brillensymbol) aus. Sie können Details wie die Menge der Daten, die aus der Quelle in die Senke kopiert wurden, den Datendurchsatz, die Ausführungsschritte mit entsprechender Dauer sowie die verwendeten Konfigurationen überwachen.
Wählen Sie oben den Link Alle Pipelineausführungen aus, um zurück zur Ansicht mit den Pipelineausführungen zu wechseln. Klicken Sie zum Aktualisieren der Liste auf Aktualisieren.
Vergewissern Sie sich, dass Ihre Daten korrekt in den dedizierten Data Explorer-Pool geschrieben werden.