Migrieren von lokalem HDFS-Speicher zu Azure Storage mit Azure Data Box
Sie können Daten aus einem lokalen HDFS-Speicher (Hadoop Distributed File System) Ihres Hadoop-Clusters zu Azure Storage (Blob Storage oder Data Lake Storage) migrieren, indem Sie ein Data Box-Gerät verwenden. Sie können zwischen einer Data Box Disk, einer Data Box mit 80 TB oder einer Data Box Heavy mit 770 TB wählen.
Dieser Artikel enthält Informationen zur Durchführung dieser Aufgaben:
- Vorbereiten der Migration Ihrer Daten
- Kopieren Ihrer Daten auf ein Azure Data Box Disk-, Data Box- oder Data Box Heavy-Gerät
- Zurücksenden des Geräts an Microsoft
- Anwenden von Zugriffsberechtigungen auf Dateien und Verzeichnisse (nur Data Lake Storage)
Voraussetzungen
Sie benötigen Folgendes, um die Migration durchführen zu können:
Azure Storage-Konto
Einen lokalen Hadoop-Cluster, in dem Ihre Quelldaten enthalten sind.
Ein Azure Data Box-Gerät.
Verkabeln und verbinden Sie die Data Box oder Data Box Heavy mit einem lokalen Netzwerk.
Wenn du bereit bist, lass uns anfangen.
Kopieren Ihrer Daten auf ein Data Box-Gerät
Wenn Ihre Daten auf ein einzelnes Data Box-Gerät passen, kopieren Sie sie auf dieses Gerät.
Wenn die Menge Ihrer Daten die Kapazität des Data Box-Geräts überschreitet, verwenden Sie das optionale Verfahren zum Aufteilen der Daten auf mehrere Data Box-Geräte, und führen Sie dann diesen Schritt aus.
Zum Kopieren der Daten aus Ihrem lokalen HDFS-Speicher auf ein Data Box-Gerät richten Sie einige Dinge ein und verwenden dann das Tool DistCp.
Führen Sie diese Schritte aus, um Daten über die REST-APIs des Blob-/Objektspeichers auf Ihr Data Box-Gerät zu kopieren. Über die REST-API-Schnittstelle wird das Gerät als HDFS-Speicher für Ihren Cluster angezeigt.
Bevor Sie die Daten per REST kopieren, sollten Sie die Sicherheits- und Verbindungsprimitive zum Herstellen einer Verbindung mit der REST-Schnittstelle auf dem Data Box- oder Data Box Heavy-Gerät identifizieren. Melden Sie sich an der lokalen Webbenutzeroberfläche von Data Box an, und navigieren Sie zur Seite Verbindung herstellen und Daten kopieren. Suchen Sie für die Azure-Speicherkonten für Ihr Gerät unter „Zugriffseinstellungen“ nach REST, und wählen Sie diese Option aus.
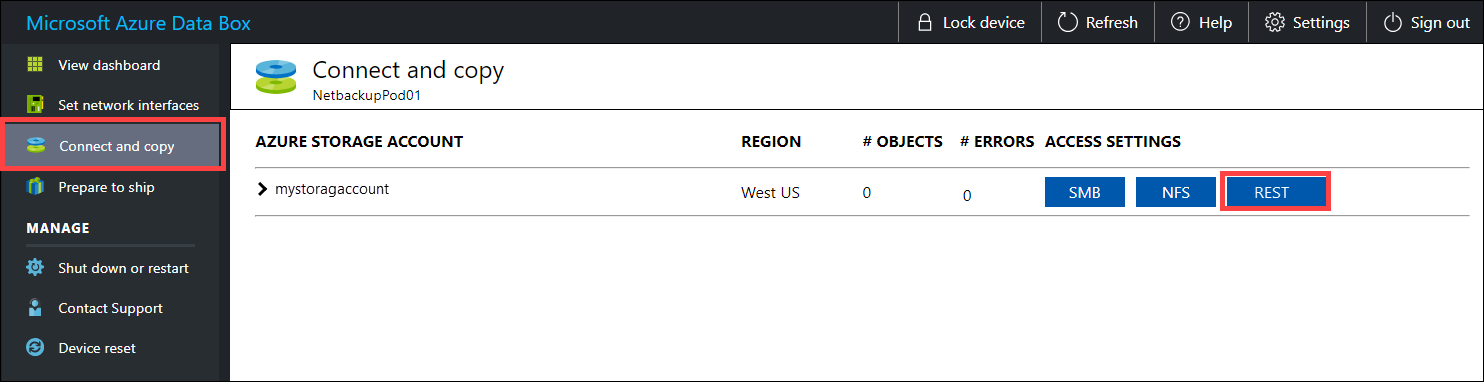
Kopieren Sie im Dialogfeld „Auf Speicherkonto zugreifen und Daten hochladen“ den Blob-Dienstendpunkt und den Speicherkontoschlüssel. Lassen Sie beim Blob-Dienstendpunkt den Teil
https://und den nachgestellten Schrägstrich weg.Der Endpunkt ist in diesem Fall:
https://mystorageaccount.blob.mydataboxno.microsoftdatabox.com/. Der Hostteil des verwendeten URI lautet:mystorageaccount.blob.mydataboxno.microsoftdatabox.com. Ein Beispiel hierfür finden Sie in der Beschreibung der Verbindungsherstellung mit REST per http.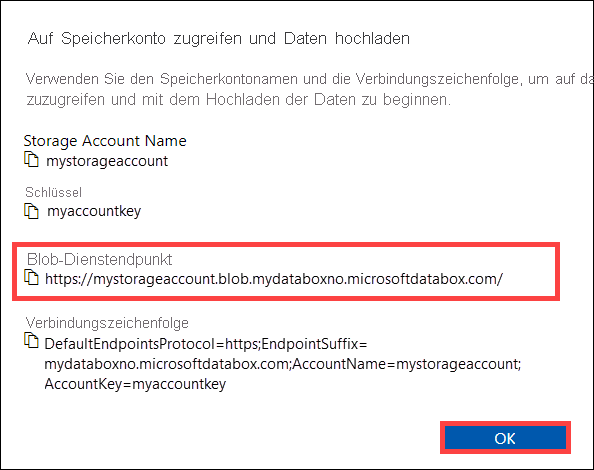
Fügen Sie
/etc/hostsauf jedem Knoten den Endpunkt und die Data Box- bzw. Data Box Heavy-IP-Adresse hinzu.10.128.5.42 mystorageaccount.blob.mydataboxno.microsoftdatabox.comFalls Sie für DNS einen anderen Mechanismus verwenden, sollten Sie sicherstellen, dass der Data Box-Endpunkt aufgelöst werden kann.
Legen Sie die Shellvariable
azjarsauf den Speicherort der JAR-Dateienhadoop-azureundazure-storagefest. Sie finden diese Dateien im Hadoop-Installationsverzeichnis.Um zu bestimmen, ob diese Dateien vorhanden sind, verwenden Sie den folgenden Befehl:
ls -l $<hadoop_install_dir>/share/hadoop/tools/lib/ | grep azure. Ersetzen Sie den Platzhalter<hadoop_install_dir>durch den Pfad zu dem Verzeichnis, in dem Sie Hadoop installiert haben. Achten Sie darauf, dass Sie vollqualifizierte Pfade zu verwenden.Beispiele:
azjars=$hadoop_install_dir/share/hadoop/tools/lib/hadoop-azure-2.6.0-cdh5.14.0.jarazjars=$azjars,$hadoop_install_dir/share/hadoop/tools/lib/microsoft-windowsazure-storage-sdk-0.6.0.jarErstellen Sie den Speichercontainer, den Sie beim Kopieren von Daten verwenden möchten. Sie müssen auch ein Zielverzeichnis als Teil dieses Befehls angeben. Dies kann zu diesem Zeitpunkt ein Dummyzielverzeichnis sein.
hadoop fs -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint>=<account_key> \ -mkdir -p wasb://<container_name>@<blob_service_endpoint>/<destination_directory>Ersetzen Sie den Platzhalter
<blob_service_endpoint>durch den Namen Ihres Endpunkts des Blobdiensts.Ersetzen Sie den Platzhalter
<account_key>durch den Zugriffsschlüssel Ihres Speicherkontos.Ersetzen Sie den Platzhalter
<container-name>durch den Namen Ihres Containers.Ersetzen Sie den Platzhalter
<destination_directory>durch den Namen des Verzeichnisses, in das Sie Ihre Daten kopieren möchten.
Führen Sie einen „list“-Befehl aus, um sicherzustellen, dass Ihr Container und Verzeichnis erstellt wurden.
hadoop fs -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint>=<account_key> \ -ls -R wasb://<container_name>@<blob_service_endpoint>/Ersetzen Sie den Platzhalter
<blob_service_endpoint>durch den Namen Ihres Endpunkts des Blobdiensts.Ersetzen Sie den Platzhalter
<account_key>durch den Zugriffsschlüssel Ihres Speicherkontos.Ersetzen Sie den Platzhalter
<container-name>durch den Namen Ihres Containers.
Kopieren Sie Daten aus dem Hadoop-HDFS zum Data Box-Blobspeicher in den zuvor erstellten Container. Wenn das Verzeichnis, in das Sie kopieren möchten, nicht gefunden wurde, wird es vom Befehl automatisch erstellt.
hadoop distcp \ -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint<>=<account_key> \ -filters <exclusion_filelist_file> \ [-f filelist_file | /<source_directory> \ wasb://<container_name>@<blob_service_endpoint>/<destination_directory>Ersetzen Sie den Platzhalter
<blob_service_endpoint>durch den Namen Ihres Endpunkts des Blobdiensts.Ersetzen Sie den Platzhalter
<account_key>durch den Zugriffsschlüssel Ihres Speicherkontos.Ersetzen Sie den Platzhalter
<container-name>durch den Namen Ihres Containers.Ersetzen Sie den Platzhalter
<exclusion_filelist_file>durch den Namen der Datei, die Ihre Liste ausgeschlossener Dateien enthält.Ersetzen Sie den Platzhalter
<source_directory>durch den Namen des Verzeichnisses, das die Daten enthält, die Sie kopieren möchten.Ersetzen Sie den Platzhalter
<destination_directory>durch den Namen des Verzeichnisses, in das Sie Ihre Daten kopieren möchten.
Die Option
-libjarswird verwendet, um die Dateihadoop-azure*.jarund die abhängige Dateiazure-storage*.jarfürdistcpverfügbar zu machen. Dies kann für einige Cluster bereits erfolgt sein.Im folgenden Beispiel wird veranschaulicht, wie der Befehl
distcpzum Kopieren von Daten verwendet wird.hadoop distcp \ -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.mystorageaccount.blob.mydataboxno.microsoftdatabox.com=myaccountkey \ -filter ./exclusions.lst -f /tmp/copylist1 -m 4 \ /data/testfiles \ wasb://hdfscontainer@mystorageaccount.blob.mydataboxno.microsoftdatabox.com/dataErhöhen Sie die Kopiergeschwindigkeit wie folgt:
Versuchen Sie, die Anzahl von Zuordnungen zu ändern. (Die Standardanzahl der Zuordnungen beträgt 20. Im obigen Beispiel werden
m= 4 Zuordnungen verwendet.)Probieren Sie
-D fs.azure.concurrentRequestCount.out=<thread_number>aus. Ersetzen Sie<thread_number>durch die Anzahl der Threads pro Zuordnung. Das Produkt aus der Anzahl der Zuordnungen und der Anzahl von Threads pro Zuordnung (m*<thread_number>) sollte 32 nicht überschreiten.Versuchen Sie, mehrere
distcp-Elemente parallel auszuführen.Beachten Sie hierbei, dass für große Dateien eine bessere Leistung als für kleine Dateien erzielt wird.
Wenn Dateien größer als 200 GB sind, empfehlen es sich, die Blockgröße mit den folgenden Parametern in 100 MB zu ändern:
hadoop distcp \ -libjars $azjars \ -Dfs.azure.write.request.size= 104857600 \ -Dfs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -Dfs.azure.account.key.<blob_service_endpoint<>=<account_key> \ -strategy dynamic \ -Dmapreduce.map.memory.mb=16384 \ -Dfs.azure.concurrentRequestCount.out=8 \ -Dmapreduce.map.java.opts=-Xmx8196m \ -m 4 \ -update \ /data/bigfile wasb://hadoop@mystorageaccount.blob.core.windows.net/bigfile
Senden des Data Box-Geräts an Microsoft
Führen Sie diese Schritte aus, um das Data Box-Gerät vorzubereiten und an Microsoft zu senden.
Bereiten Sie zunächst den Versand der Data Box oder Data Box Heavy vor.
Laden Sie die BOM-Dateien herunter, nachdem die Vorbereitung des Geräts abgeschlossen ist. Sie verwenden diese BOM-Dateien oder Manifestdateien später zur Überprüfung der in Azure hochgeladenen Daten.
Fahren Sie das Gerät herunter, und entfernen Sie die Kabel.
Planen Sie eine Abholung durch UPS.
Die entsprechenden Informationen für Data Box-Geräte finden Sie unter Zurücksenden der Azure Data Box.
Die entsprechenden Informationen für Data Box Heavy-Geräte finden Sie unter Zurücksenden von Azure Data Box Heavy.
Nachdem Ihr Gerät bei Microsoft eingegangen ist, wird es mit dem Netzwerk des Rechenzentrums verbunden, und die Daten werden in das Speicherkonto hochgeladen, das Sie bei der Bestellung des Geräts angegeben haben. Überprüfen Sie anhand der BOM-Dateien, ob Ihre gesamten Daten in Azure hochgeladen wurden.
Anwenden von Zugriffsberechtigungen auf Dateien und Verzeichnisse (nur Data Lake Storage)
Die Daten befinden sich bereits in Ihrem Azure Storage-Konto. Jetzt wenden Sie Zugriffsberechtigungen auf Dateien und Verzeichnisse an.
Hinweis
Dieser Schritt ist nur erforderlich, wenn Sie Azure Data Lake Storage als Datenspeicher verwenden. Falls Sie nur ein Blobspeicherkonto ohne hierarchischen Namespace als Datenspeicher nutzen, können Sie diesen Abschnitt überspringen.
Erstellen eines Dienstprinzipals für Ihr Konto mit aktiviertem Azure Data Lake Storage
Erstellen Sie einen Dienstprinzipal wie unter Erstellen einer Microsoft Entra-Anwendung und eines Dienstprinzipals mit Ressourcenzugriff über das Portal erläutert.
Achten Sie beim Ausführen der Schritte im Abschnitt Zuweisen der Anwendung zu einer Rolle des Artikels darauf, dem Dienstprinzipal die Rolle Mitwirkender an Storage-Blobdaten zuzuweisen.
Wenn Sie die im Abschnitt Abrufen von Werten für die Anmeldung des Artikels aufgeführten Schritte ausführen, speichern Sie die Werte für Anwendungs-ID und Clientgeheimnis in einer Textdatei. Sie benötigen sie bald.
Generieren einer Liste der kopierten Dateien mit deren Berechtigungen
Führen Sie im lokalen Hadoop-Cluster diesen Befehl aus:
sudo -u hdfs ./copy-acls.sh -s /{hdfs_path} > ./filelist.json
Dieser Befehl generiert eine Liste der kopierten Dateien mit deren Berechtigungen.
Hinweis
Abhängig von der Anzahl der Dateien im Hadoop Distributed File System (HDFS) kann das Ausführen dieses Befehls lange dauern.
Generieren einer Liste der Identitäten und Zuordnen dieser Identitäten zu Microsoft Entra-Identitäten
Laden Sie das Skript
copy-acls.pyherunter. Informationen hierzu finden Sie in diesem Artikel im Abschnitt Herunterladen von Hilfsskripts und Einrichten Ihres Edgeknotens, um sie auszuführen.Führen Sie den folgenden Befehl aus, um eine Liste der eindeutigen Identitäten zu generieren.
./copy-acls.py -s ./filelist.json -i ./id_map.json -gDieses Skript generiert eine Datei namens
id_map.json, die die Identitäten enthält, die Sie für das Zuordnen zu AAD-basierten (Azure Active Directory) Identitäten benötigen.Öffnen Sie die Datei
id_map.jsonin einem Text-Editor.Aktualisieren Sie für jedes JSON-Objekt, das in der Datei aufgeführt ist, das
target-Attribut von entweder einem Microsoft Entra-Benutzerprinzipalnamen oder einer Objekt-ID (OID) mit der entsprechenden zugeordneten Identität. Wenn Sie damit fertig sind, speichern Sie die Datei. Sie benötigen diese Datei im nächsten Schritt.
Anwenden von Berechtigungen auf kopierte Dateien und Anwenden von Identitätszuordnungen
Führen Sie den folgenden Befehl aus, um Berechtigungen auf die Daten anzuwenden, die Sie in das Konto mit aktiviertem Data Lake Storage kopiert haben:
./copy-acls.py -s ./filelist.json -i ./id_map.json -A <storage-account-name> -C <container-name> --dest-spn-id <application-id> --dest-spn-secret <client-secret>
Ersetzen Sie den Platzhalter
<storage-account-name>durch den Namen Ihres Speicherkontos.Ersetzen Sie den Platzhalter
<container-name>durch den Namen Ihres Containers.Ersetzen Sie die Platzhalter
<application-id>und<client-secret>durch die Anwendungs-ID bzw. den geheimen Clientschlüssel, die Sie notiert haben, als Sie den Dienstprinzipal erstellt haben.
Anhang: Aufteilen von Daten auf mehrere Data Box-Geräte
Bevor Sie Ihre Daten auf ein Data Box-Gerät verschieben, müssen Sie einige Hilfsskripts herunterladen, sicherstellen, dass Ihre Daten so organisiert sind, dass sie auf ein Data Box-Gerät passen, und alle nicht benötigten Dateien ausschließen.
Herunterladen von Hilfsskripts und Einrichten Ihres Edgeknotens, um sie auszuführen
Führen Sie auf Ihrem Edge- oder Hauptknoten Ihres lokalen Hadoop-Clusters diesen Befehl aus:
git clone https://github.com/jamesbak/databox-adls-loader.git cd databox-adls-loaderMit diesem Befehl wird das GitHub-Repository geklont, das die Hilfsskripts enthält.
Stellen Sie sicher, dass das jq-Paket auf Ihrem lokalen Computer installiert ist.
sudo apt-get install jqInstallieren Sie das Python-Paket Requests.
pip install requestsLegen Sie Ausführungsberechtigungen für die benötigten Skripts fest.
chmod +x *.py *.sh
Sicherstellen, dass Ihre Daten so organisiert sind, dass sie auf ein Data Box-Gerät passen
Wenn Ihr Datenvolumen die Größe eines einzelnen Data Box-Geräts überschreitet, können Sie Dateien in Gruppen aufteilen, die Sie auf mehreren Data Box-Geräten speichern können.
Wenn Ihre gesamten Daten auf ein einzelnes Data Box-Gerät passen, können Sie zum nächsten Abschnitt springen.
Führen Sie mit erhöhten Rechten das Skript
generate-file-listaus, das Sie entsprechend der Anleitung im vorherigen Abschnitt heruntergeladen haben.Nachstehend sind die Befehlsparameter beschrieben:
sudo -u hdfs ./generate-file-list.py [-h] [-s DATABOX_SIZE] [-b FILELIST_BASENAME] [-f LOG_CONFIG] [-l LOG_FILE] [-v {DEBUG,INFO,WARNING,ERROR}] path where: positional arguments: path The base HDFS path to process. optional arguments: -h, --help show this help message and exit -s DATABOX_SIZE, --databox-size DATABOX_SIZE The size of each Data Box in bytes. -b FILELIST_BASENAME, --filelist-basename FILELIST_BASENAME The base name for the output filelists. Lists will be named basename1, basename2, ... . -f LOG_CONFIG, --log-config LOG_CONFIG The name of a configuration file for logging. -l LOG_FILE, --log-file LOG_FILE Name of file to have log output written to (default is stdout/stderr) -v {DEBUG,INFO,WARNING,ERROR}, --log-level {DEBUG,INFO,WARNING,ERROR} Level of log information to output. Default is 'INFO'.Kopieren Sie die generierten Dateilisten in HDFS (Hadoop Distributed File System), damit der DistCp-Auftrag auf sie zugreifen kann.
hadoop fs -copyFromLocal {filelist_pattern} /[hdfs directory]
Ausschließen von nicht benötigten Dateien
Sie müssen einige Verzeichnisse aus dem „DisCp“-Auftrag ausschließen. Schließen Sie beispielsweise Verzeichnisse aus, die Statusinformationen enthalten, die für den Clusterbetrieb benötigt werden.
Erstellen Sie in dem lokalen Hadoop-Cluster, in dem Sie den DistCp-Auftrag ausführen möchten, eine Datei, die die Liste der Verzeichnisse enthält, die Sie ausschließen möchten.
Hier sehen Sie ein Beispiel:
.*ranger/audit.*
.*/hbase/data/WALs.*
Nächste Schritte
Informieren Sie sich darüber, wie Data Lake Storage mit HDInsight-Clustern funktioniert. Weitere Informationen finden Sie unter Verwenden von Azure Data Lake Storage mit Azure HDInsight-Clustern.