Konfigurieren von Apache Ranger-Richtlinien für Spark SQL in HDInsight mit Enterprise-Sicherheitspaket
In diesem Artikel wird beschrieben, wie Apache Ranger-Richtlinien für Spark SQL in HDInsight mit Enterprise-Sicherheitspaket konfiguriert werden.
In diesem Artikel werden folgende Vorgehensweisen behandelt:
- Erstellen Sie Apache Ranger-Richtlinien.
- Überprüfen Sie die angewendeten Ranger-Richtlinien.
- Wenden Sie die Richtlinien zum Einrichten von Apache Ranger für Spark SQL an.
Voraussetzungen
- Ein Apache Spark-Cluster in HDInsight Version 5.1 mit Enterprise-Sicherheitspaket
Herstellen einer Verbindung mit der Apache Ranger-Administratoroberfläche
Stellen Sie in einem Browser mit der URL
https://ClusterName.azurehdinsight.net/Ranger/eine Verbindung mit der Ranger-Administrator-Benutzeroberfläche her.Ändern Sie
ClusterNamemit dem Namen Ihres Spark-Clusters.Melden Sie sich mit Ihren Microsoft Entra-Administratoranmeldeinformationen an. Die Microsoft Entra-Administratoranmeldeinformationen sind nicht identisch mit HDInsight-Clusteranmeldeinformationen oder Linux-HDInsight-Knoten-Secure Shell-Anmeldeinformationen.
Erstellen von Domänenbenutzern
Unter Erstellen eines HDInsight-Clusters mit ESP finden Sie Informationen zum Erstellen von sparkuser-Domänenbenutzern. In einem Produktionsszenario kommen die Domänenbenutzer von Ihrem Microsoft Entra-Mandanten.
Erstellen einer Ranger-Richtlinie
In diesem Abschnitt erstellen Sie zwei Ranger-Richtlinien:
- Eine Zugriffsrichtlinie für den Zugriff auf
hivesampletablevon Spark SQL - Eine Maskierungsrichtlinie zum Verschleiern der Spalten in
hivesampletable
Erstellen einer Ranger-Zugriffsrichtlinie
Öffnen Sie die Ranger-Administratoroberfläche.
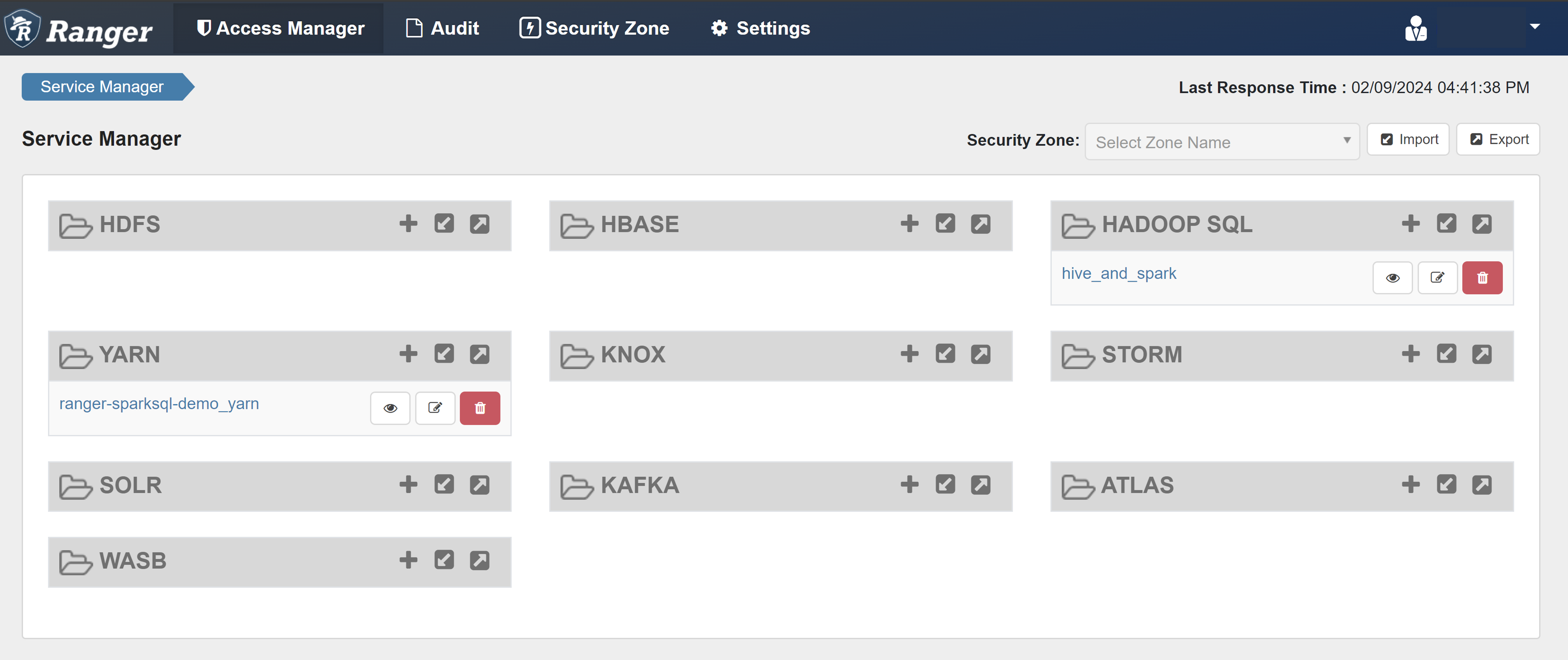
Wählen Sie unter HADOOP SQL die Option hive_and_spark aus.
Wählen Sie auf der Registerkarte Zugriff die Option Neue Richtlinie hinzufügenaus aus.
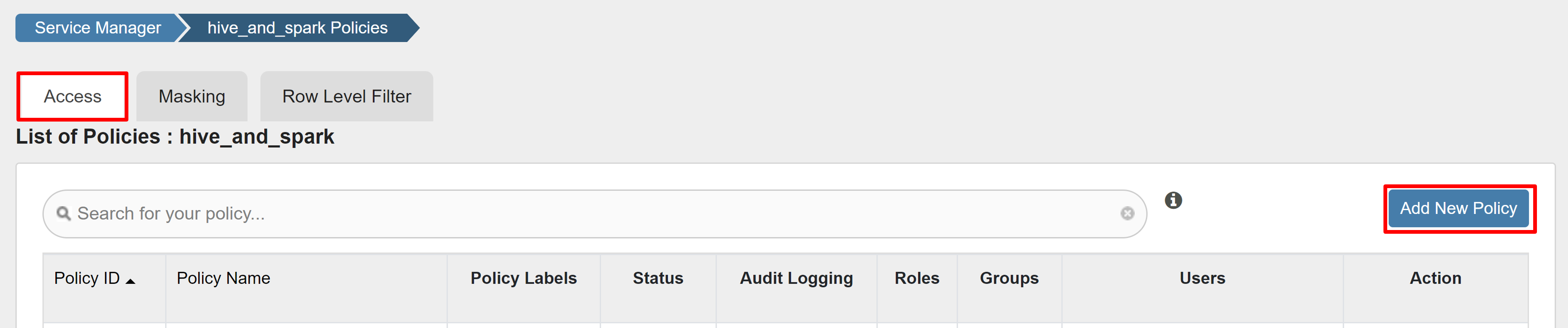
Geben Sie die folgenden Werte ein:
Eigenschaft Wert Richtlinienname read-hivesampletable-all database default table hivesampletable column * Benutzer auswählen sparkuserBerechtigungen select 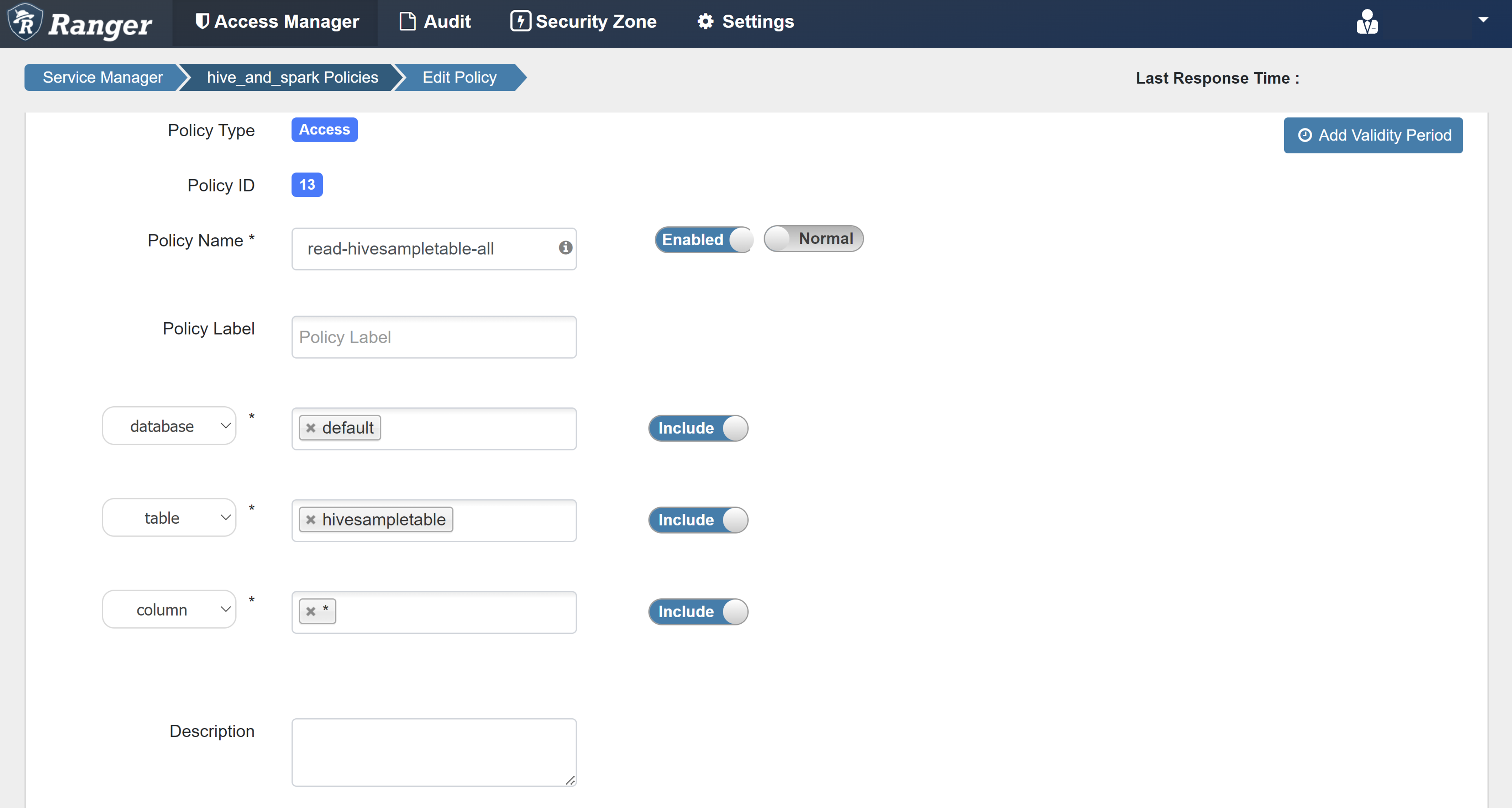
Wenn unter Benutzer auswählen nicht automatisch ein Domänenbenutzer eingetragen wird, warten Sie kurz, bis Ranger mit Microsoft Entra ID synchronisiert ist.
Wählen Sie Hinzufügen aus, um die Richtlinie zu speichern.
Öffnen Sie ein Zeppelin-Notebook und führen Sie den folgenden Befehl aus, um die Richtlinie zu überprüfen:
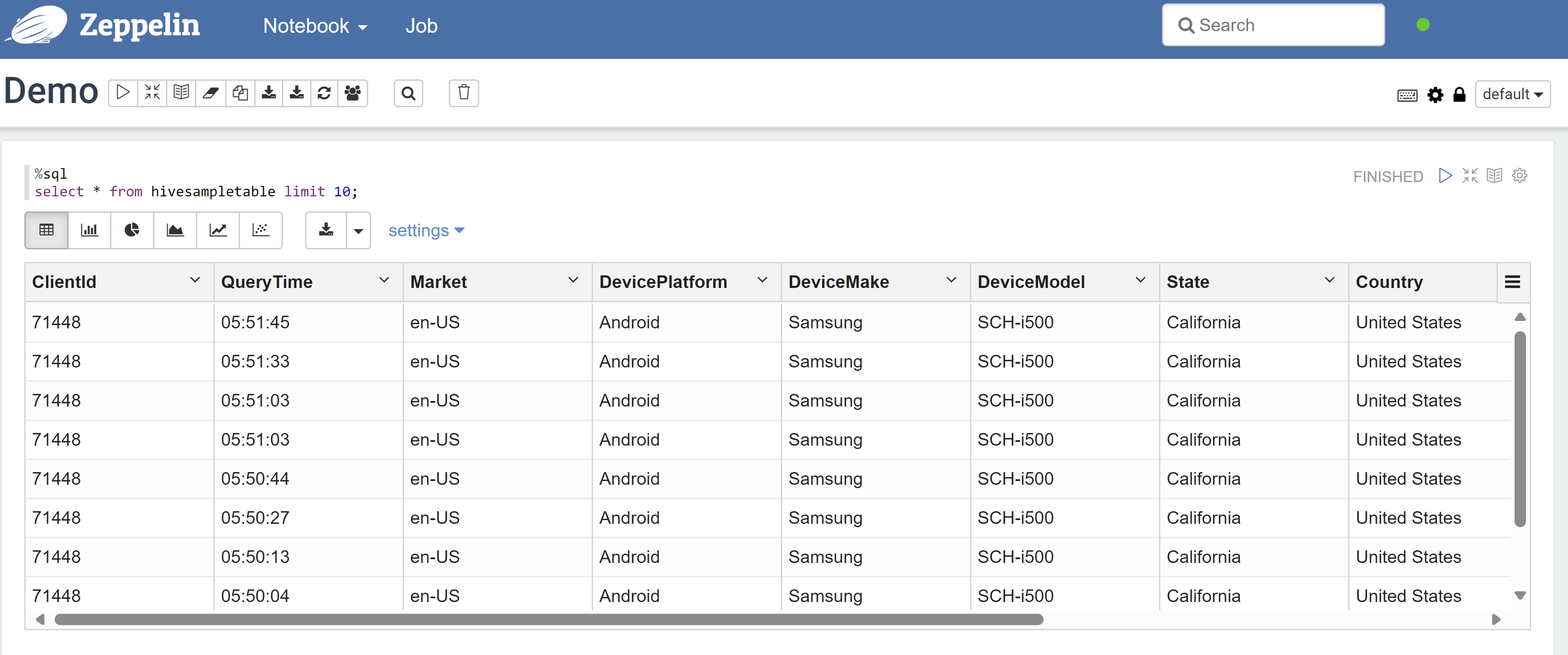
%sql select * from hivesampletable limit 10;Dies ist das Ergebnis, bevor eine Richtlinie angewendet wird:
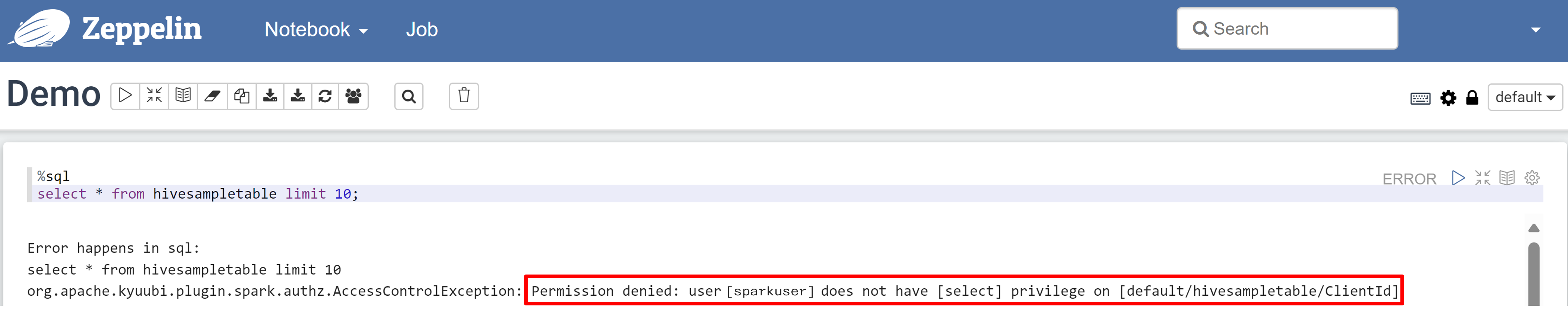
Hier sehen Sie das Ergebnis, nachdem eine Richtlinie angewendet wurde:




Erstellen einer Ranger-Maskierungsrichtlinie
Im folgenden Beispiel wird veranschaulicht, wie eine Richtlinie zum Verbergen einer Spalte erstellt wird:
Wählen Sie auf der Registerkarte Maskierung die Option Neue Richtlinie hinzufügen aus.
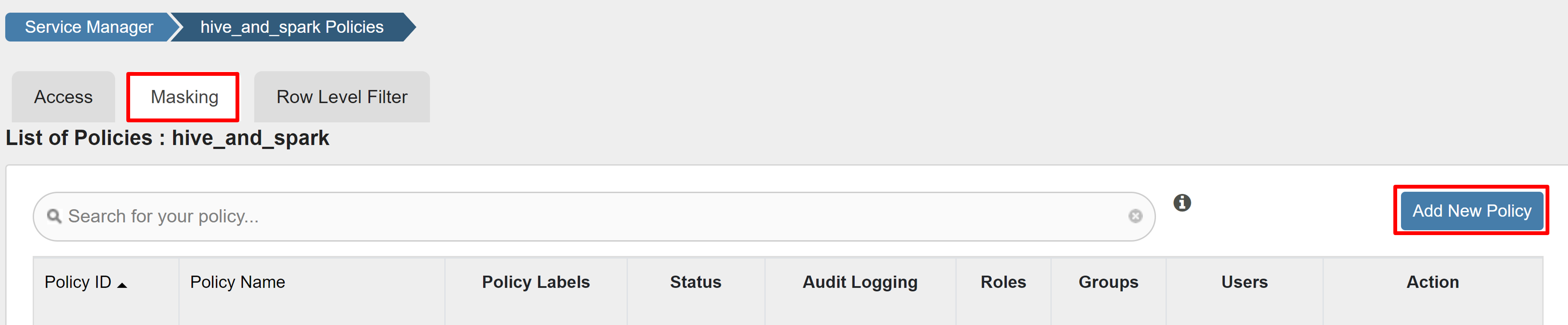
Geben Sie die folgenden Werte ein:
Eigenschaft Wert Richtlinienname mask-hivesampletable Hive-Datenbank default Hive-Tabelle hivesampletable Hive-Spalte devicemake Benutzer auswählen sparkuserZugriffstypen select Option „Maskierung“ auswählen Hash 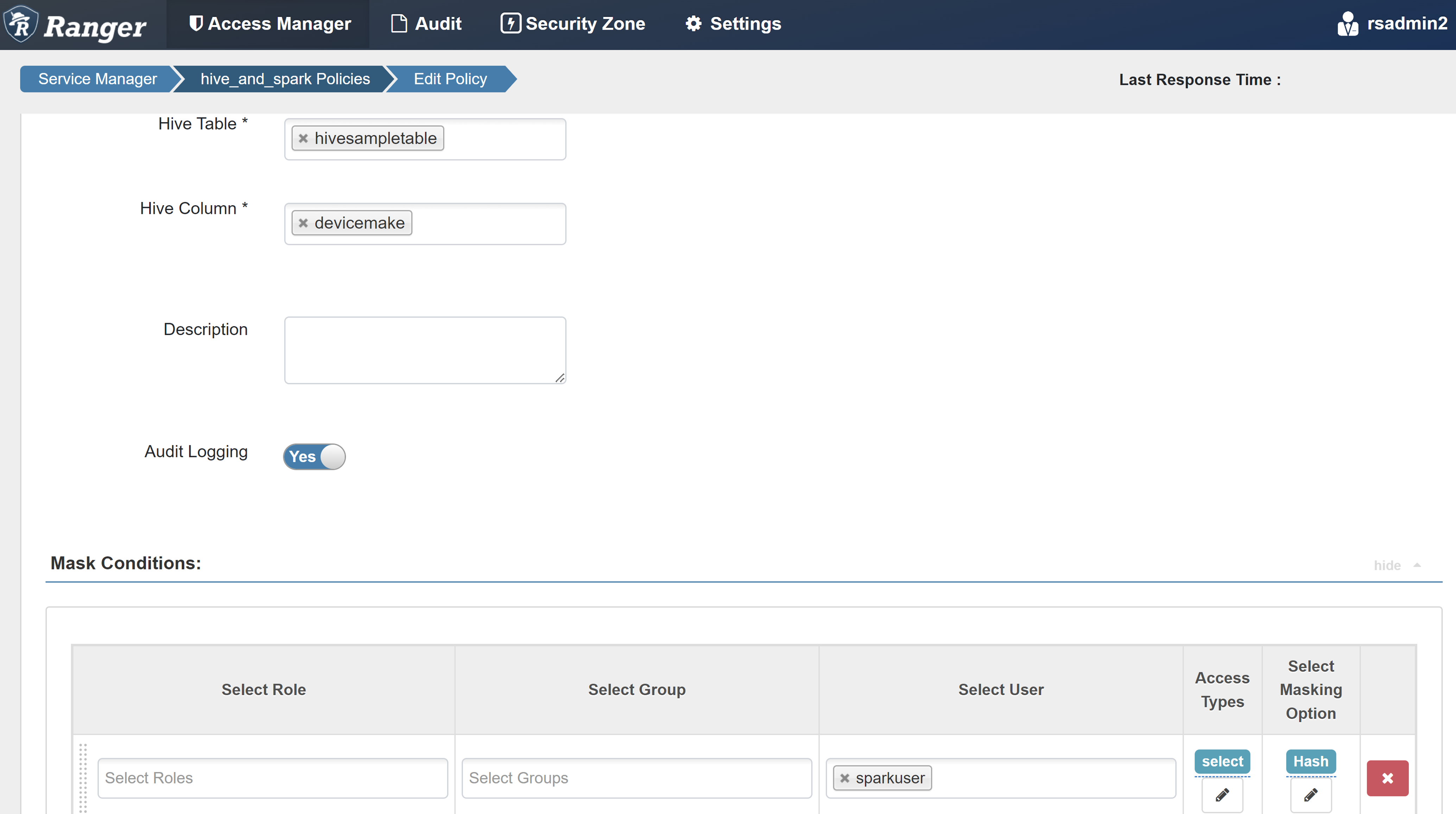
Wählen Sie Speichern aus, um die Richtlinie zu speichern.
Öffnen Sie ein Zeppelin-Notebook und führen Sie den folgenden Befehl aus, um die Richtlinie zu überprüfen:
%sql select clientId, deviceMake from hivesampletable;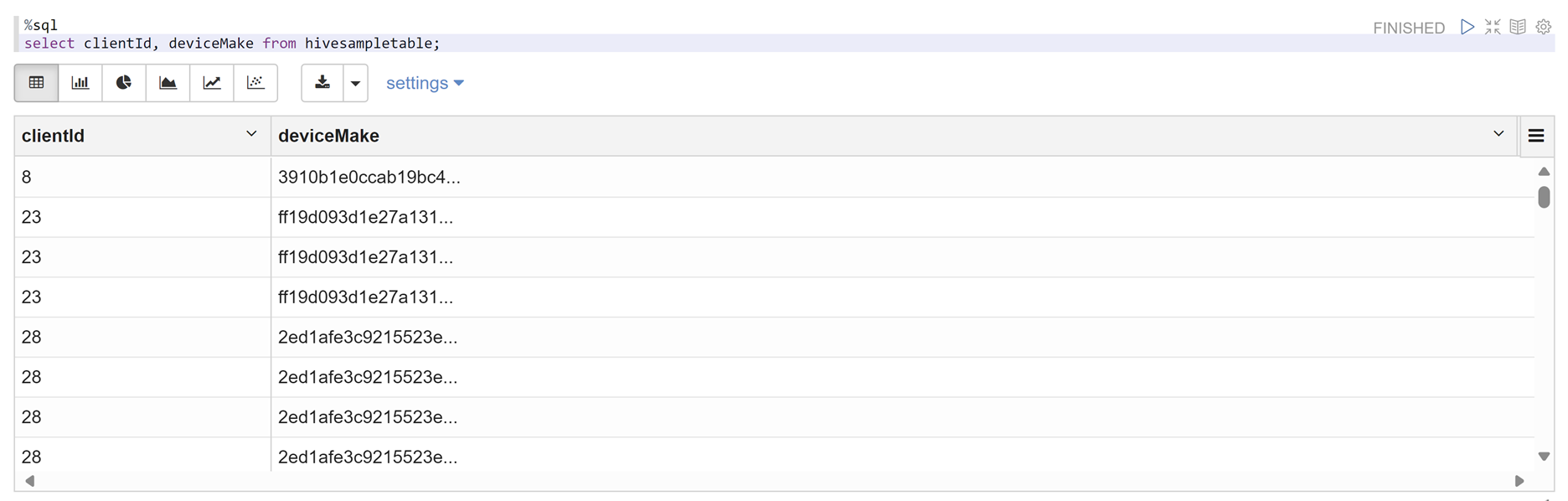



Hinweis
Standardmäßig werden die Richtlinien für Hive und Spark-SQL in Ranger verwendet.
Richtlinie zum Einrichten von Apache Ranger für Spark-SQL
In den folgenden Szenarien werden Richtlinien für die Erstellung eines HDInsight 5.1 Spark-Clusters unter Verwendung einer neuen Ranger-Datenbank und unter Verwendung einer vorhandenen Ranger-Datenbank untersucht.
Szenario 1: Verwenden einer neuen Ranger-Datenbank beim Erstellen des HDInsight 5.1 Spark-Clusters
Wenn Sie eine neue Ranger-Datenbank verwenden, um einen Cluster zu erstellen, wird das entsprechende Ranger-Repository, das die Ranger-Richtlinien für Hive und Spark enthält, unter dem Namen hive_and_spark im Hadoop-SQL-Dienst auf der Ranger-Datenbank erstellt.

Wenn Sie die Richtlinien bearbeiten, werden sie sowohl auf Hive als auch auf Spark angewendet.
Beachten Sie die folgenden Punkte:
Falls Sie zwei Metastore-Datenbanken mit demselben Namen haben, die sowohl für Hive- (z. B. DB1) als auch für Spark-Kataloge (z. B. DB1) verwendet werden:
- Wenn Spark den Spark-Katalog verwendet (
metastore.catalog.default=spark), werden die Richtlinien auf die DB1-Datenbank des Spark-Katalogs angewendet. - Wenn Spark den Hive-Katalog verwendet (
metastore.catalog.default=hive), werden die Richtlinien auf die DB1-Datenbank des Hive-Katalogs angewendet.
Von Ranger aus gesehen gibt es keine Möglichkeit, zwischen dem DB1 des Hive- und des Spark-Katalogs zu unterscheiden.
In solchen Fällen empfehlen wir Ihnen entweder:
- Den Hive-Katalog sowohl für Hive als auch für Spark zu verwenden.
- Oder unterschiedliche Datenbank-, Tabellen- und Spaltennamen für Hive- und Spark-Kataloge zu verwalten, damit die Richtlinien nicht katalogübergreifend auf Datenbanken angewendet werden.
- Wenn Spark den Spark-Katalog verwendet (
Wenn Sie den Hive-Katalog sowohl für Hive als auch für Spark verwenden, sollten Sie das folgende Beispiel in Betracht ziehen.
Angenommen, Sie erstellen eine Tabelle mit dem Namen Tabelle1 über Hive mit dem aktuellen Benutzer xyz. Dadurch wird eine Hadoop Distributed File System (HDFS)-Datei mit dem Namen table1.db erstellt, deren Besitzer der Benutzer xyz ist.
Stellen Sie sich nun vor, Sie verwenden den Benutzer abc, um die Spark SQL-Sitzung zu starten. Wenn Sie in dieser Sitzung des Benutzers abc versuchen, etwas in Tabelle1 zu schreiben, wird dies fehlschlagen, der der Tabellenbesitzer xyz ist.
In diesem Fall wird empfohlen, denselben Benutzer in Hive und Spark SQL zum Aktualisieren der Tabelle zu verwenden. Dieser Benutzer sollte über ausreichende Berechtigungen zum Ausführen von Aktualisierungsvorgängen verfügen.
Szenario 2: Verwenden einer vorhandenen Ranger-Datenbank (mit vorhandenen Richtlinien) beim Erstellen des HDInsight 5.1 Spark-Clusters
Wenn Sie einen HDInsight 5.1-Cluster unter Verwendung einer bestehenden Ranger-Datenbank erstellen, wird ein neues Ranger-Repository auf dieser Datenbank mit dem Namen des neuen Clusters in diesem Format erstellt: hive_and_spark.

Angenommen, Sie haben die Richtlinien im Ranger-Repository bereits unter dem Namen oldclustername_hive in der vorhandenen Ranger-Datenbank innerhalb des Hadoop SQL-Diensts definiert. Sie möchten die gleichen Richtlinien im neuen HDInsight 5.1 Spark-Cluster freigeben. Führen Sie die folgenden Schritte aus, um dieses Ziel zu erreichen.
Hinweis
Ein Benutzer, der über Ambari-Administratorrechte verfügt, kann Konfigurationsupdates ausführen.
Öffnen Sie die Ambari-Benutzeroberfläche von Ihrem neuen HDInsight 5.1-Cluster aus.
Wechseln Sie zum Spark3-Dienst, und wechseln Sie dann zu Configs.
Öffnen Sie die Konfiguration Erweiterte Ranger-Spark-Sicherheit.

Sie können diese Konfiguration auch mithilfe von SSH in /etc/spark3/conf öffnen.
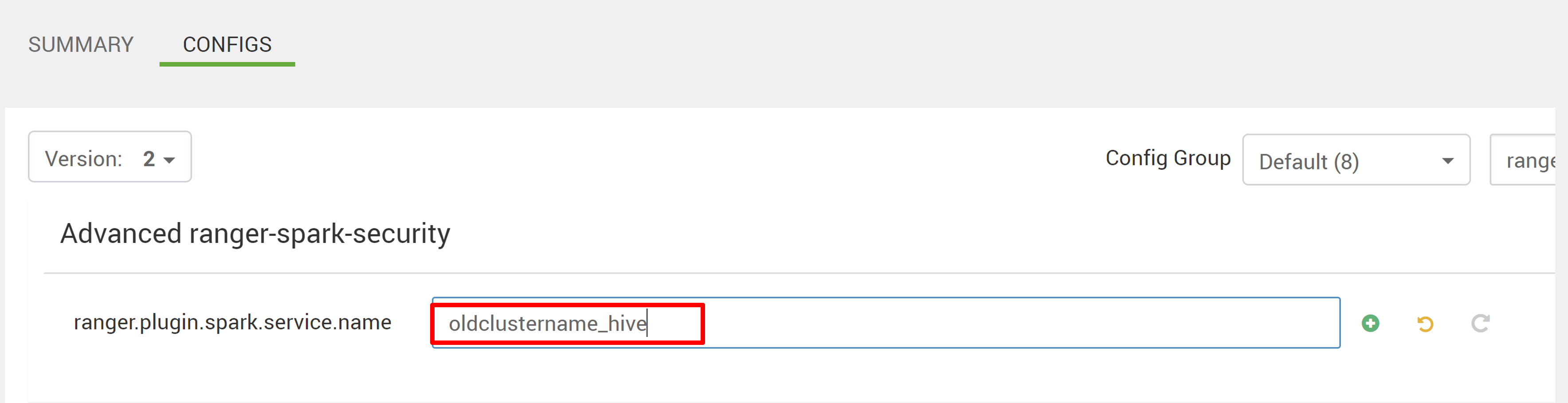
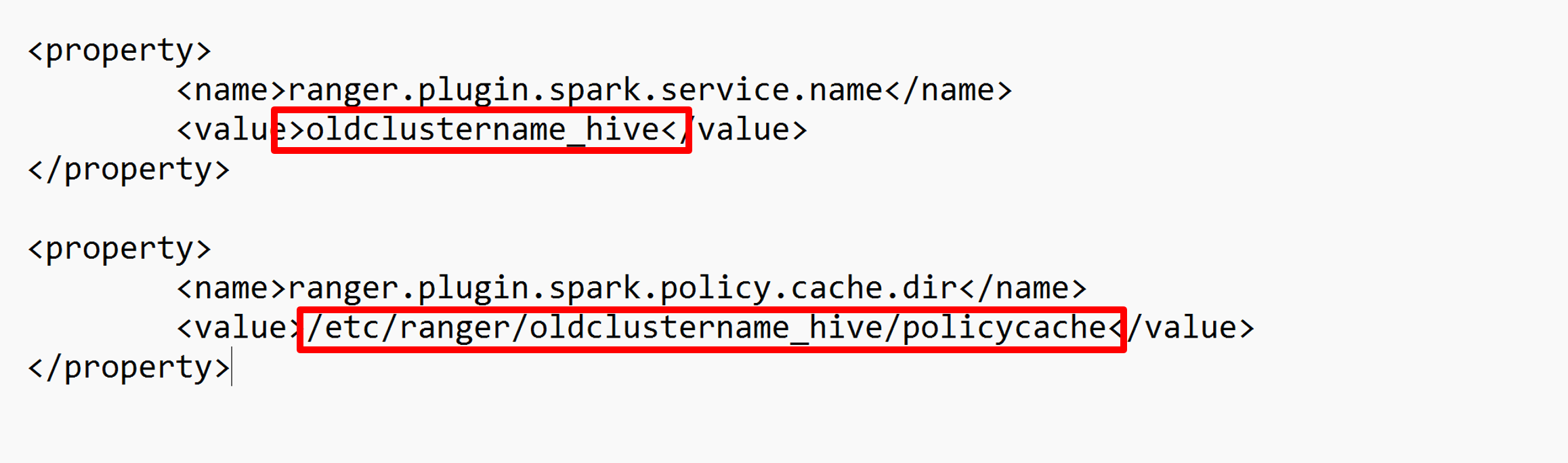
Bearbeiten Sie die beiden Konfigurationen ranger.plugin.spark.service.name und ranger.plugin.spark.policy.cache.dir, sodass sie auf das alte Richtlinien-Repository oldclustername_hive verweisen, und speichern Sie die Konfigurationen.
Ambari:
XML-Datei:
Starten Sie die Ranger- und Spark-Dienste in Ambari neu.
Öffnen Sie die Ranger-Administratorbenutzeroberfläche, und klicken Sie unter „HADOOP SQL Dienst“ auf die Schaltfläche „Bearbeiten“.
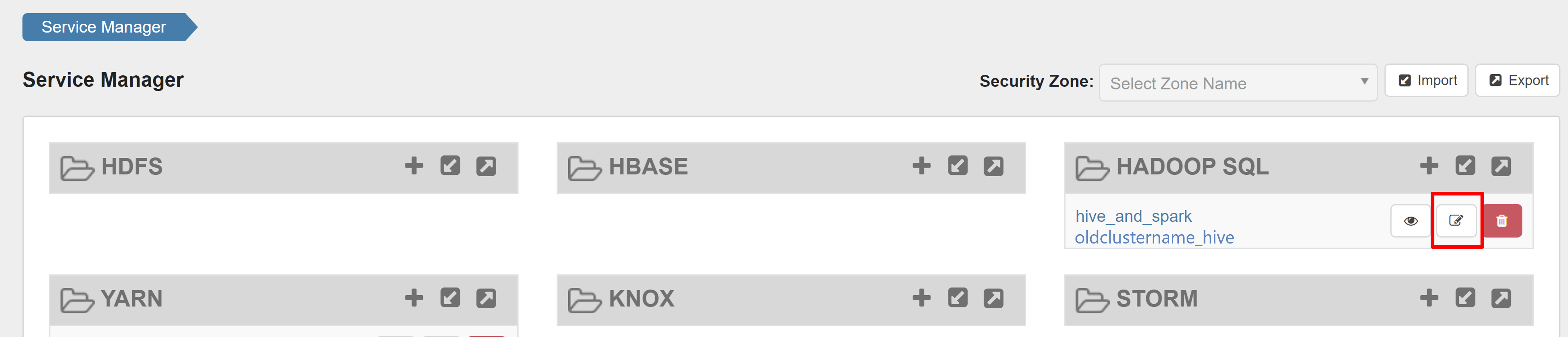
Fügen Sie für den Dienst oldclustername_hive den Benutzernamen rangersparklookup in den Listen policy.download.auth.users und tag.download.auth.users hinzu, und klicken Sie auf „Speichern“.






Die Richtlinien werden auf Datenbanken im Spark-Katalog angewendet. Wenn Sie auf die Datenbanken im Hive-Katalog zugreifen möchten:
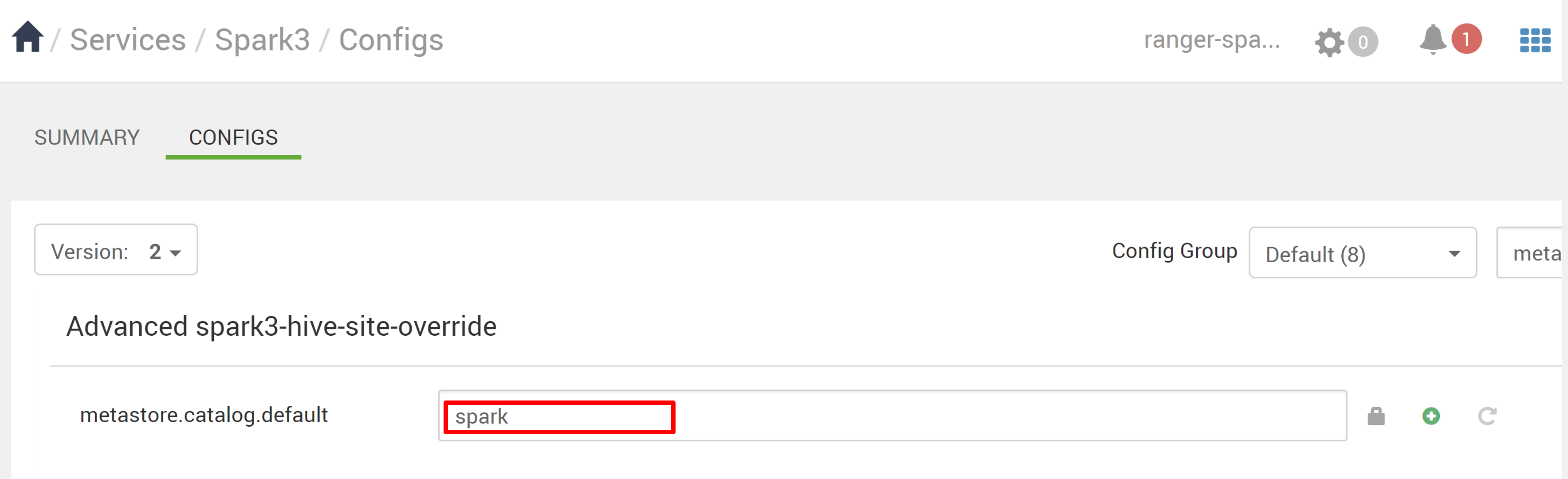
Wechseln Sie in Ambari zu Spark3>Configs.
Ändern Sie metastore.catalog.default von Spark aufHive.

Bekannte Probleme
- Die Apache Ranger-Integration in Spark SQL funktioniert nicht, wenn der Ranger-Administrator ausgefallen ist.
- Wenn Sie in Ranger-Überwachungsprotokollen auf die Spalte Ressource zeigen, wird nicht die gesamte Abfrage angezeigt, die Sie ausgeführt haben.