Transformieren von Daten mit der Hadoop MapReduce-Aktivität in Azure Data Factory oder Synapse Analytics
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Die HDInsight MapReduce-Aktivität in einer Azure Data Factory- oder Synapse Analytics-Pipeline ruft ein MapReduce-Programm für Ihren eigenen oder bedarfsgesteuerten HDInsight-Cluster auf. Dieser Artikel baut auf dem Artikel zu Datentransformationsaktivitäten auf, der eine allgemeine Übersicht über die Datentransformation und die unterstützten Transformationsaktivitäten bietet.
Lesen Sie vor diesem Artikel die Einführungsartikel zu Azure Data Factory und Synapse Analytics, und arbeiten Sie das Tutorial: Transformieren von Daten durch.
Weitere Informationen zum Ausführen von Pig-/Hive-Skripts in einem HDInsight-Cluster über eine Pipeline mithilfe von Pig-/Hive-HDInsight-Aktivitäten finden Sie unter Pig und Hive.
Hinzufügen einer HDInsight MapReduce-Aktivität zu einer Pipeline mit Benutzeroberfläche
Führen Sie die folgenden Schritte aus, um eine HDInsight-MapReduce-Aktivität in einer Pipeline zu verwenden:
Suchen Sie im Bereich mit den Pipelineaktivitäten nach MapReduce, und ziehen Sie eine MapReduce-Aktivität in den Pipelinecanvas.
Wählen Sie die neue Hive-Aktivität im Canvas aus, wenn sie noch nicht ausgewählt ist.
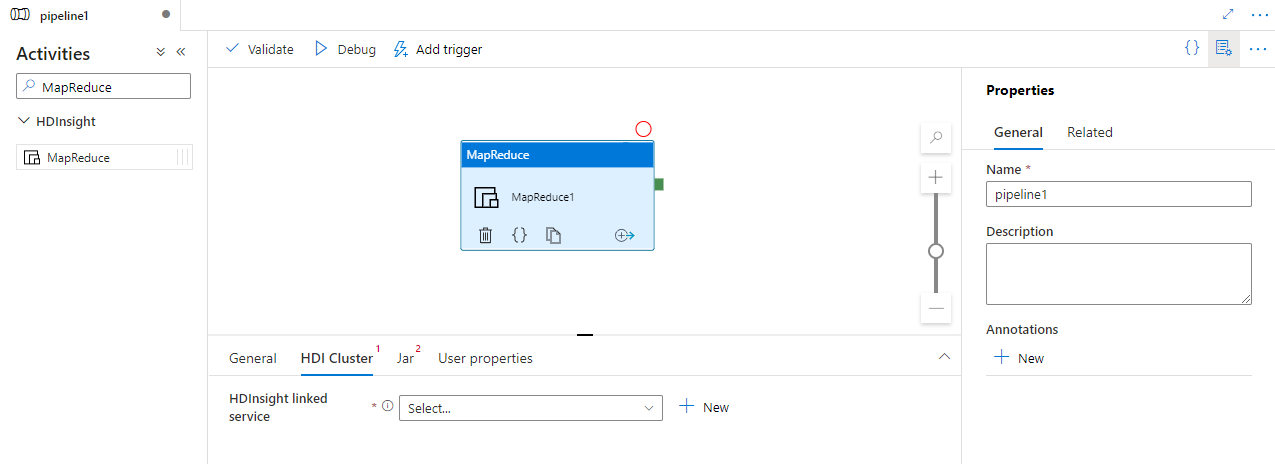
Wählen Sie die Registerkarte HDI-Cluster aus, um einen neuen verknüpften Dienst für einen HDInsight-Cluster auszuwählen oder zu erstellen, der zum Ausführen der MapReduce-Aktivität verwendet wird.
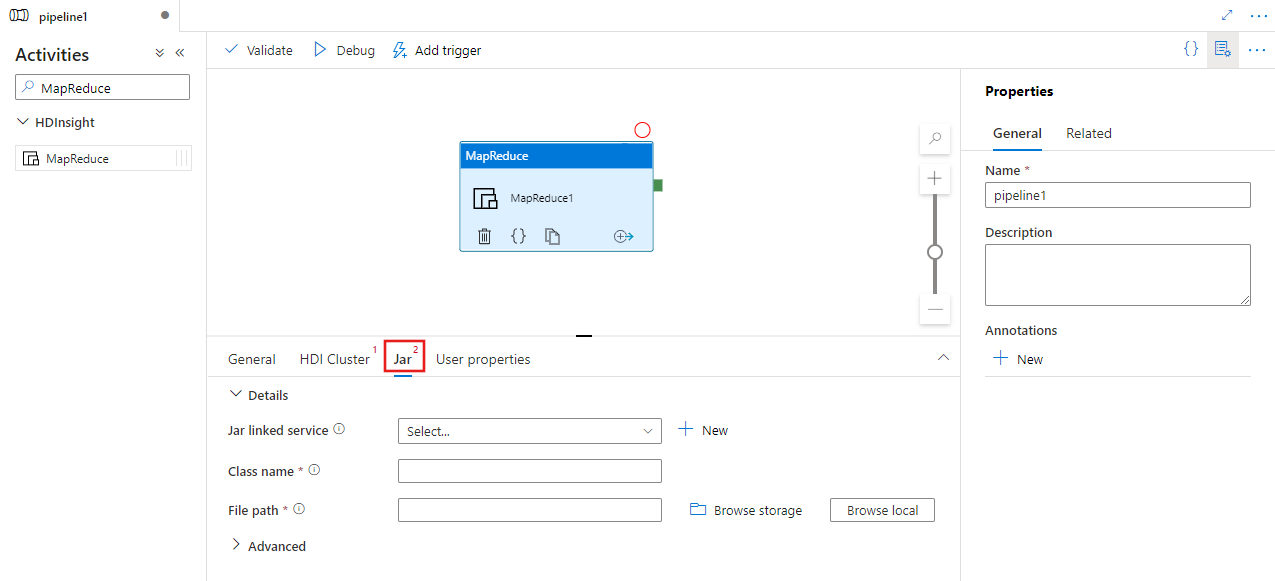
Wählen Sie die Registerkarte JAR aus, um einen neuen verknüpften JAR-Dienst für ein Azure Storage Konto auszuwählen oder zu erstellen, das Ihr Skript hosten soll. Geben Sie einen Klassennamen, der dort ausgeführt werden soll, und einen Dateipfad innerhalb des Speicherorts an. Sie können auch erweiterte Details konfigurieren, z. B. einen JAR-Bibliotheksspeicherort, eine Debugkonfiguration sowie Argumente und Parameter, die an das Skript übergeben werden sollen.
Syntax
{
"name": "Map Reduce Activity",
"description": "Description",
"type": "HDInsightMapReduce",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"className": "org.myorg.SampleClass",
"jarLinkedService": {
"referenceName": "MyAzureStorageLinkedService",
"type": "LinkedServiceReference"
},
"jarFilePath": "MyAzureStorage/jars/sample.jar",
"getDebugInfo": "Failure",
"arguments": [
"-SampleHadoopJobArgument1"
],
"defines": {
"param1": "param1Value"
}
}
}
Syntaxdetails
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| name | Der Name der Aktivität | Ja |
| description | Ein Text, der beschreibt, wofür die Aktivität verwendet wird. | Nein |
| type | Für die MapReduce-Aktivität ist der Aktivitätstyp „HDInsightMapReduce“. | Ja |
| linkedServiceName | Verweis auf den HDInsight-Cluster, der als verknüpfter Dienst registriert ist. Weitere Informationen zu diesem verknüpften Dienst finden Sie im Artikel Von Azure Data Factory unterstützten Compute-Umgebungen. | Ja |
| className | Name der Klasse, die ausgeführt werden soll | Ja |
| jarLinkedService | Verweis auf einen verknüpften Azure Storage-Dienst, der zum Speichern der JAR-Dateien verwendet wird. Hier werden nur die verknüpften Azure Blob Storage und ADLS Gen2 -Dienste unterstützt. Wenn Sie diesen verknüpften Dienst nicht angeben, wird der im verknüpften HDInsight-Dienst definierte verknüpfte Azure Storage-Dienst genutzt. | Nein |
| jarFilePath | Geben Sie den Pfad der JAR-Dateien an, die im Azure Storage-Speicher gespeichert sind, auf den „jarLinkedService“ verweist. Beim Dateinamen muss die Groß-/Kleinschreibung beachtet werden. | Ja |
| jarlibs | Zeichenfolgenarray des Pfads zu der JAR-Bibliotheksdateien, die in dem Auftrag referenziert wird, der in dem Azure Storage-Speicher gespeichert ist, der in „jarLinkedService“ definiert ist. Beim Dateinamen muss die Groß-/Kleinschreibung beachtet werden. | Nein |
| getDebugInfo | Gibt an, ob die Protokolldateien in den Azure Storage-Speicher kopiert werden, der vom HDInsight-Cluster verwendet (oder) von „jarLinkedService“ angegeben wird. Zulässige Werte: „None“, „Always“ oder „Failure“. Standardwert: Keine. | Nein |
| Argumente | Gibt ein Array von Argumenten für einen Hadoop-Auftrag an. Die Argumente werden als Befehlszeilenargumente an jeden Vorgang übergeben. | Nein |
| defines | Geben Sie Parameter als Schlüssel-Wert-Paare für Verweise innerhalb des Hive-Skripts an. | Nein |
Beispiel
Mit der HDInsight-Aktivität „MapReduce“ können Sie beliebige MapReduce-JAR-Dateien auf einem HDInsight-Cluster ausführen. In der folgenden JSON-Beispieldefinition einer Pipeline wird die HDInsight-Aktivität für die Ausführung einer Mahout-JAR-Datei konfiguriert.
{
"name": "MapReduce Activity for Mahout",
"description": "Custom MapReduce to generate Mahout result",
"type": "HDInsightMapReduce",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"className": "org.apache.mahout.cf.taste.hadoop.similarity.item.ItemSimilarityJob",
"jarLinkedService": {
"referenceName": "MyStorageLinkedService",
"type": "LinkedServiceReference"
},
"jarFilePath": "adfsamples/Mahout/jars/mahout-examples-0.9.0.2.2.7.1-34.jar",
"arguments": [
"-s",
"SIMILARITY_LOGLIKELIHOOD",
"--input",
"wasb://adfsamples@spestore.blob.core.windows.net/Mahout/input",
"--output",
"wasb://adfsamples@spestore.blob.core.windows.net/Mahout/output/",
"--maxSimilaritiesPerItem",
"500",
"--tempDir",
"wasb://adfsamples@spestore.blob.core.windows.net/Mahout/temp/mahout"
]
}
}
Sie können im Abschnitt arguments Argumente für das MapReduce-Programm angeben. Zur Laufzeit werden ein paar zusätzliche Argumente aus dem MapReduce-Framework angezeigt (z.B.: mapreduce.job.tags). Wenn Sie Ihre Argumente mit den MapReduce-Argumenten unterscheiden möchten, sollten Sie erwägen, sowohl die Option als auch den Wert als Argumente zu verwenden, wie im folgenden Beispiel gezeigt wird („-s“, „--input“, „--output“ usw. sind Optionen, auf die unmittelbar die Werte folgen).
Zugehöriger Inhalt
In den folgenden Artikeln erfahren Sie, wie Daten auf andere Weisen transformiert werden: