Ausführen eines Databricks-Notebooks mit der Databricks-Notebook-Aktivität in Azure Data Factory
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
In diesem Tutorial verwenden Sie das Azure-Portal, um eine Azure Data Factory-Pipeline zu erstellen, die ein Databricks-Notebook für den Cluster mit den Databricks-Aufträgen ausführt. Außerdem übergibt sie während der Ausführung Azure Data Factory-Parameter an das Databricks-Notebook.
In diesem Tutorial führen Sie die folgenden Schritte aus:
Erstellen einer Data Factory.
Erstellen einer Pipeline mit Databricks-Notebook-Aktivität
Auslösen einer Pipelineausführung
Überwachen der Pipelineausführung.
Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
Hinweis
Ausführliche Informationen zur Verwendung der Databricks-Notebookaktivität, einschließlich der Verwendung von Bibliotheken und des Übergebens von Ein- und Ausgabeparametern, finden Sie in der Dokumentation zur Databricks-Notebookaktivität.
Voraussetzungen
- Azure Databricks-Arbeitsbereich Erstellen Sie einen Databricks-Arbeitsbereich, oder verwenden Sie einen vorhandenen Arbeitsbereich. Sie erstellen ein Python-Notebook in Ihrem Azure Databricks-Arbeitsbereich. Anschließend führen Sie das Notebook aus und übergeben Parameter mit Azure Data Factory.
Erstellen einer Data Factory
Starten Sie den Webbrowser Microsoft Edge oder Google Chrome. Die Data Factory-Benutzeroberfläche wird zurzeit nur in den Webbrowsern Microsoft Edge und Google Chrome unterstützt.
Wählen Sie im Azure-Portalmenü die Option Ressource erstellen und dann Integration und Data Factory aus.
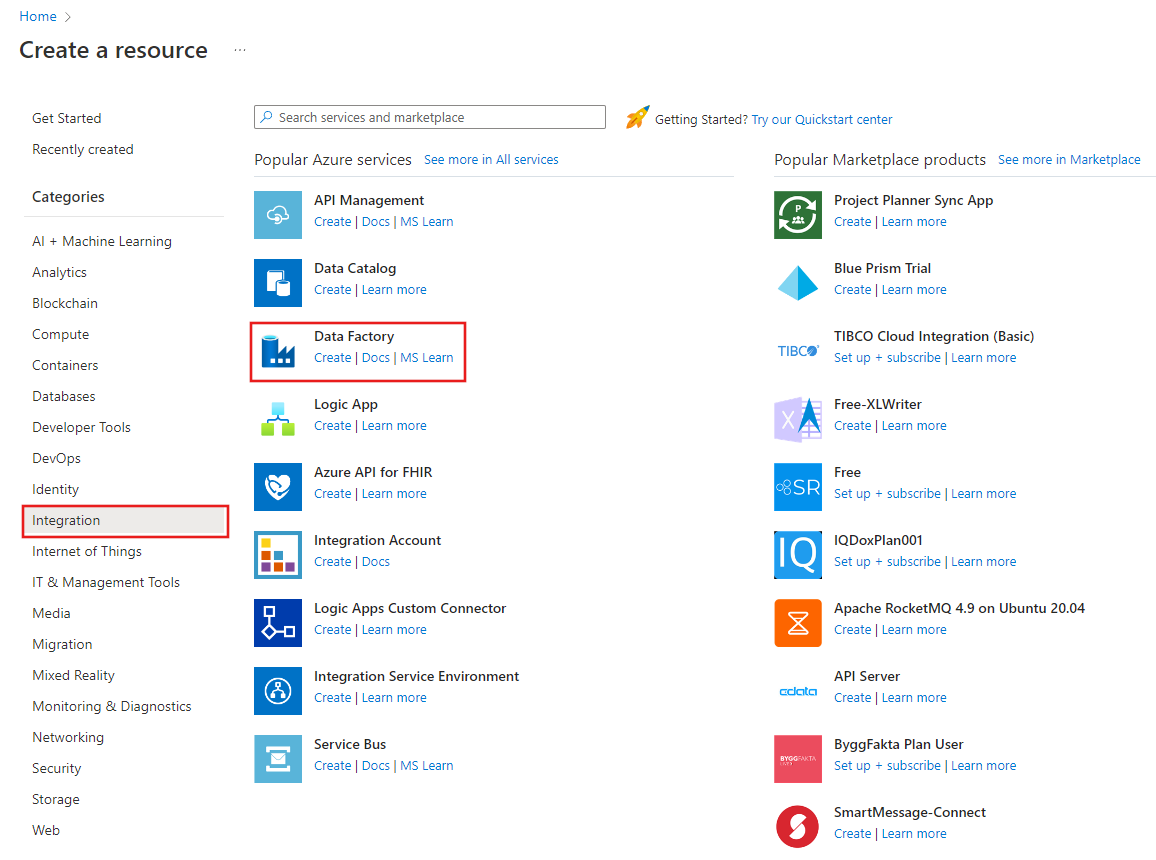
Wählen Sie auf der Seite Data Factory erstellen auf der Registerkarte Grundlagen Ihr Azure-Abonnement aus, in dem Sie die Data Factory erstellen möchten.
Führen Sie unter Ressourcengruppe einen der folgenden Schritte aus:
Wählen Sie in der Dropdownliste eine vorhandene Ressourcengruppe aus.
Wählen Sie Neu erstellen aus, und geben Sie den Namen einer neuen Ressourcengruppe ein.
Weitere Informationen über Ressourcengruppen finden Sie unter Verwenden von Ressourcengruppen zum Verwalten von Azure-Ressourcen.
Wählen Sie unter Region den Standort für die Data Factory aus.
In der Liste werden nur Standorte angezeigt, die von Data Factory unterstützt werden und an denen Ihre Azure Data Factory-Metadaten gespeichert werden. Die von Data Factory verwendeten zugeordneten Datenspeicher (z. B. Azure Storage und Azure SQL-Datenbank) und Computedienste (z. B. Azure HDInsight) können in anderen Regionen ausgeführt werden.
Geben Sie unter Name den Namen ADFTutorialDataFactory ein.
Der Name der Azure Data Factory muss global eindeutigsein. Sollte der folgende Fehler auftreten, ändern Sie den Namen der Data Factory. (Verwenden Sie beispielsweise <IhrName>ADFTutorialDataFactory.) Benennungsregeln für Data Factory-Artefakte finden Sie im Artikel Azure Data Factory – Benennungsregeln.
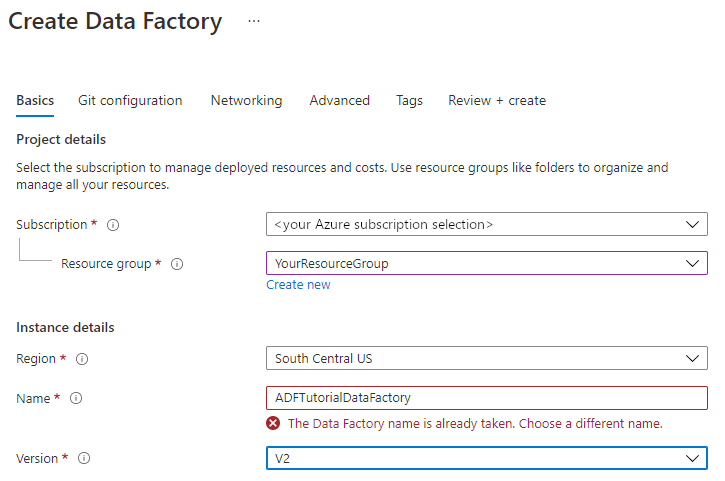
Wählen Sie V2 als Version aus.
Klicken Sie auf Weiter: Git-Konfiguration, und aktivieren Sie das Kontrollkästchen Git später konfigurieren.
Wählen Sie Überprüfen und erstellen und nach erfolgreicher Prüfung Erstellen aus.
Wählen Sie nach der Erstellung Zu Ressource wechseln aus, um zur Seite Data Factory zu navigieren. Wählen Sie die Kachel Azure Data Factory Studio öffnen aus, um die Anwendung für die Azure Data Factory-Benutzeroberfläche (User Interface, UI) auf einer separaten Registerkarte des Browsers zu starten.
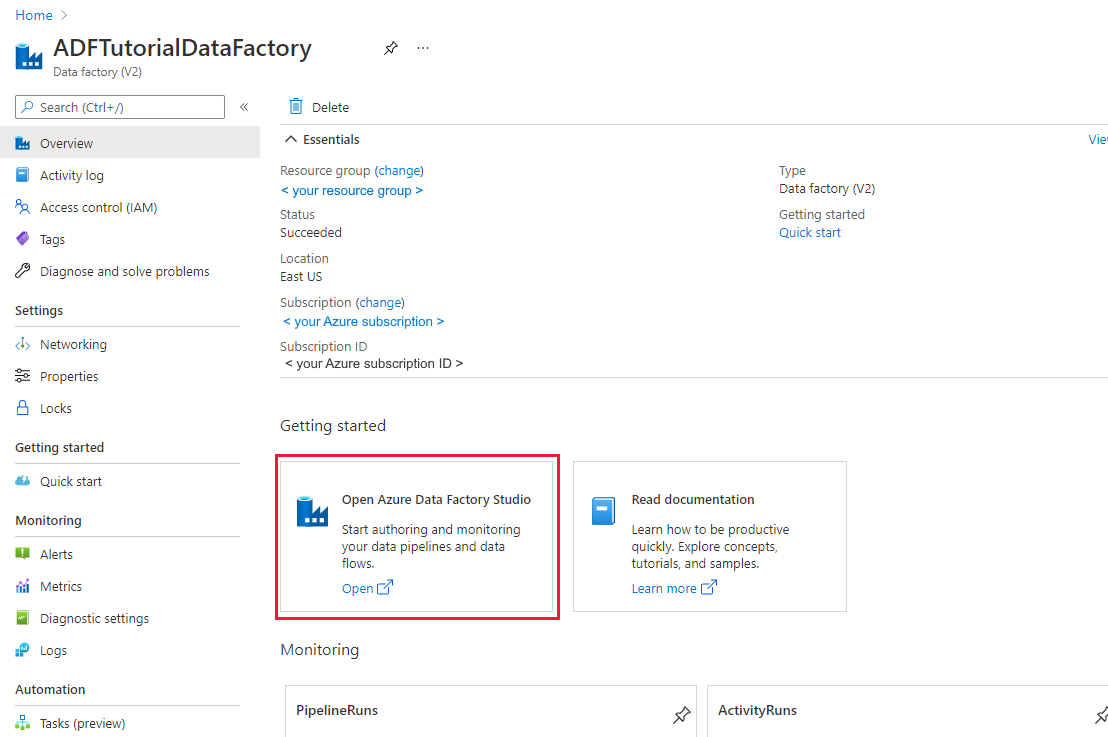
Erstellen von verknüpften Diensten
In diesem Abschnitt erstellen Sie einen verknüpften Databricks-Dienst. Dieser verknüpfte Dienst enthält die Verbindungsinformationen für den Databricks-Cluster:
Erstellen eines verknüpften Azure Databricks-Diensts
Wechseln Sie auf der Startseite im linken Bereich zur Registerkarte Verwalten.
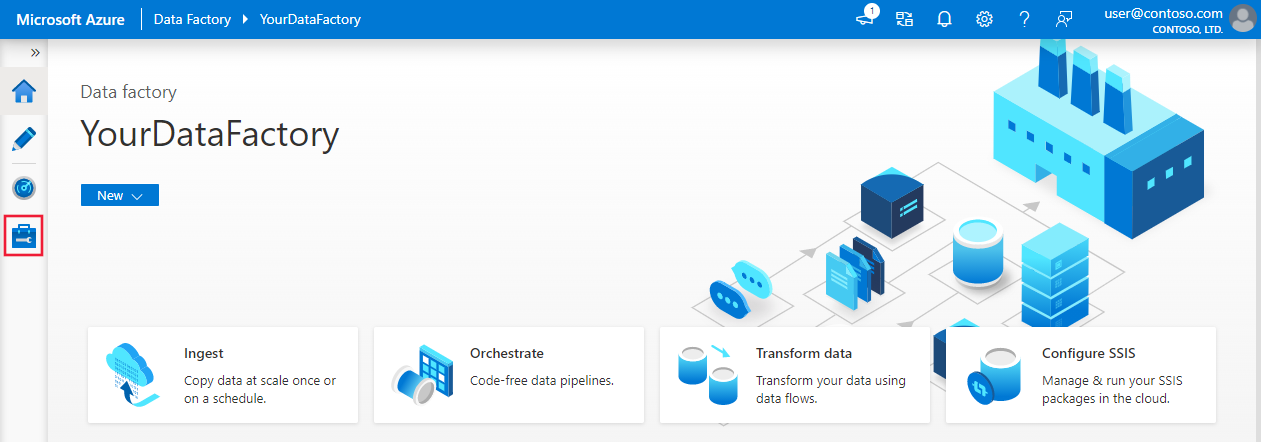
Wählen Sie unter Verbindungen die Option Verknüpfte Dienste und dann + Neu aus.
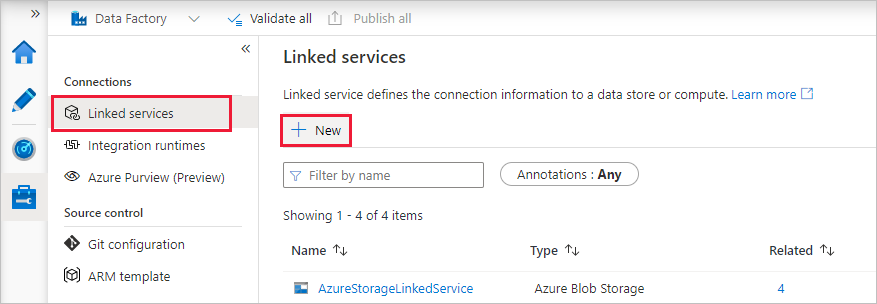
Wählen Sie im Fenster New Linked Service (Neuer verknüpfter Dienst) die Option Compute>Azure Databricks und dann Weiter.

Führen Sie im Fenster Neuer verknüpfter Dienst die folgenden Schritte aus:
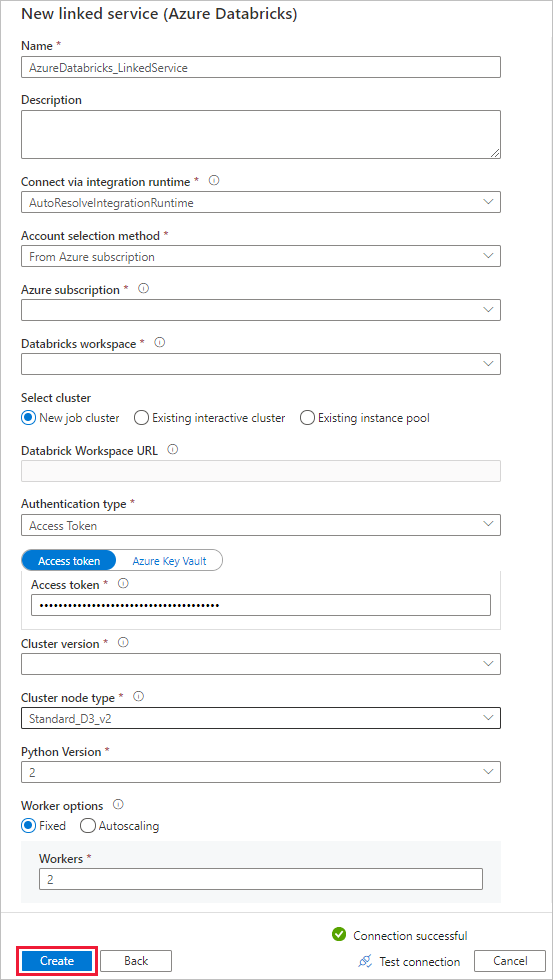
Geben Sie unter Name den Namen AzureDatabricks_LinkedService ein.
Wählen Sie den richtigen Databricks-Arbeitsbereich aus, in dem Sie Ihr Notebook ausführen möchten.
Wählen Sie unter Cluster auswählen die Option Neuer Auftragscluster aus.
Für Databricks-Arbeitsbereichs-URL sollten die Informationen automatisch aufgefüllt werden.
Wenn Sie für den AuthentifizierungstypZugriffstoken auswählen, generieren Sie es am Azure Databricks-Arbeitsplatz. Die Schritte finden Sie hier. Weisen Sie für die Verwaltete Dienstidentität und die benutzerseitig zugewiesene verwaltete Identität beiden Identitäten im Menü Zugriffssteuerung der Azure Databricks-Ressource die Rolle Mitwirkender.
Wählen Sie unter Clusterversion die Version aus, die Sie verwenden möchten.
Wählen Sie für dieses Tutorial unter General Purpose (HDD) (Universell (HDD)) für Cluster node type (Clusterknotentyp) die Option Standard_D3_v2.
Geben Sie für Workers die Zahl 2 ein.
Klicken Sie auf Erstellen.
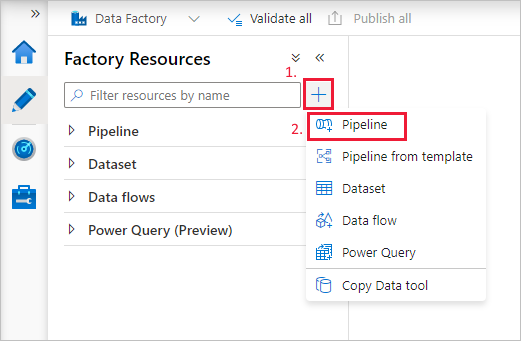
Erstellen einer Pipeline
Wählen Sie die Schaltfläche + (Pluszeichen) und dann im Menü die Option Pipeline aus.
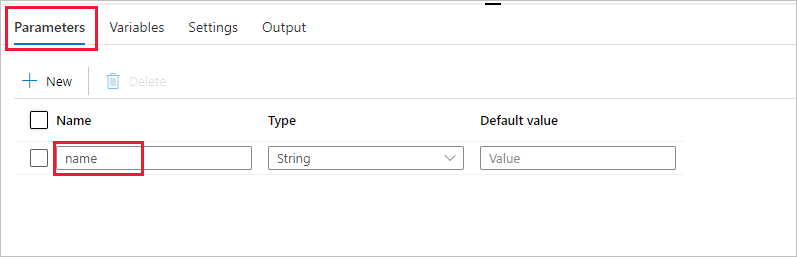
Erstellen Sie einen Parameter für die Verwendung in der Pipeline. Diesen Parameter übergeben Sie später an die Databricks-Notebook-Aktivität. Wählen Sie in der leeren Pipeline die Registerkarte Parameter und dann + Neu aus, und geben Sie als Namen name ein.
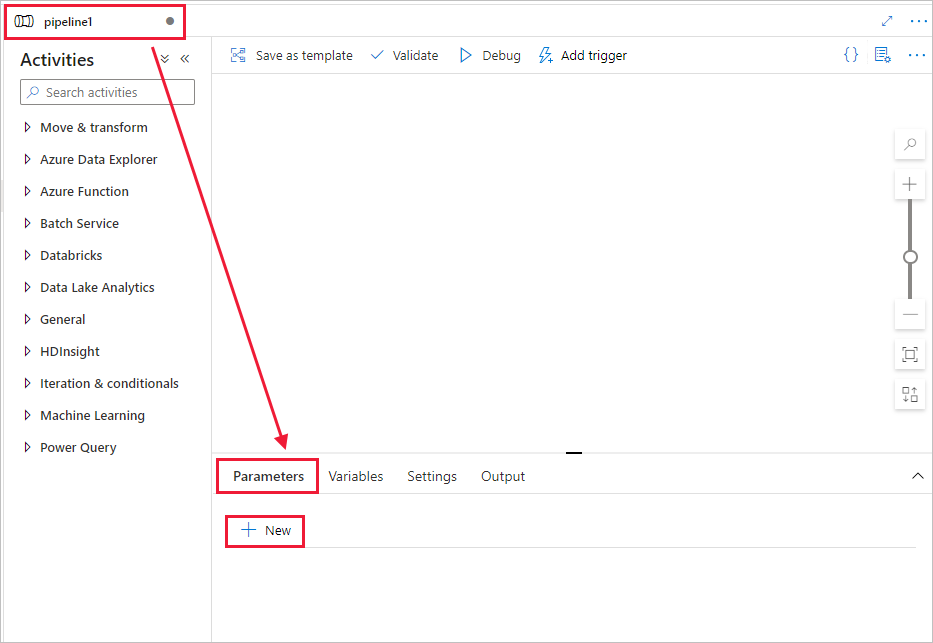
Erweitern Sie in der Toolbox Aktivitäten die Option Databricks. Ziehen Sie die Notebook-Aktivität aus der Toolbox Aktivitäten auf die Oberfläche des Pipeline-Designers.
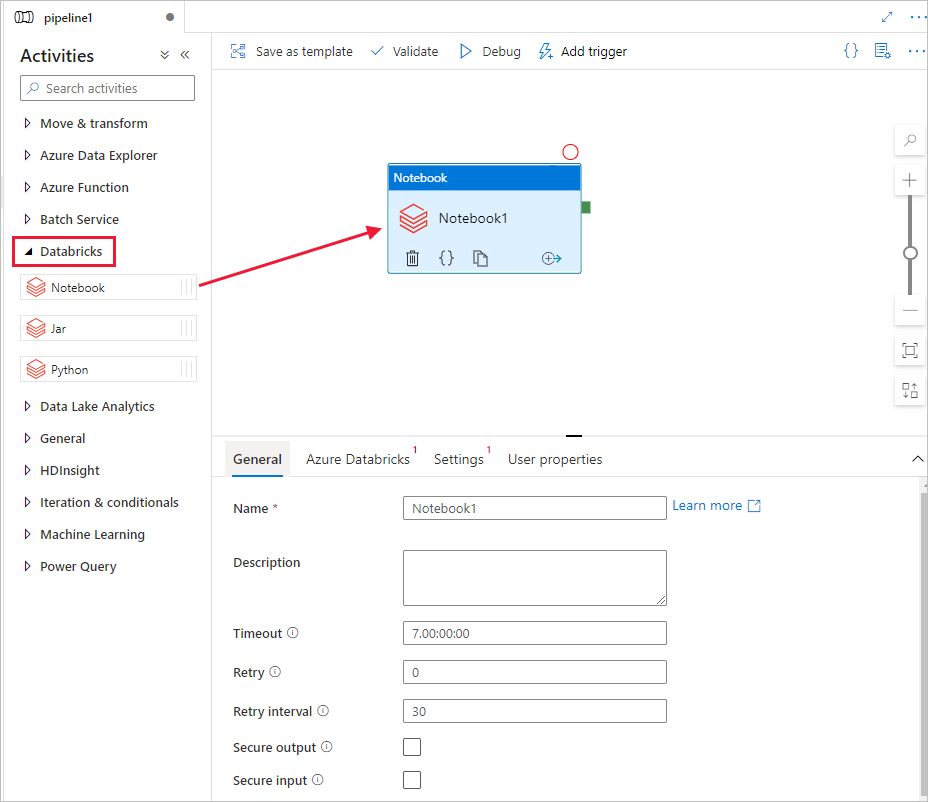
Führen Sie in den Eigenschaften im unteren Bereich des Fensters für das Databricks-Notebook die folgenden Schritte aus:
Wechseln Sie zur Registerkarte Azure Databricks.
Wählen Sie AzureDatabricks_LinkedService aus (wie oben erstellt).
Wechseln Sie zur Registerkarte Einstellungen.
Wählen Sie einen Notebook-Pfad für Databricks aus. Wir erstellen ein Notebook und geben den Pfad hier an. Sie erhalten den Notebook-Pfad, indem Sie die nächsten Schritte ausführen.
Starten Sie Ihren Azure Databricks-Arbeitsbereich.
Erstellen Sie im Arbeitsbereich unter Neuer Ordner einen neuen Ordner, und geben Sie ihm den Namen adftutorial.
Erstellen Sie ein neues Notebook, und benennen Sie es mit mynotebook. Klicken Sie mit der rechten Maustaste auf den Ordner adftutorial, und wählen Sie Erstellen aus.
Fügen Sie im neu erstellten Notebook „mynotebook“ den folgenden Code hinzu:
# Creating widgets for leveraging parameters, and printing the parameters dbutils.widgets.text("input", "","") y = dbutils.widgets.get("input") print ("Param -\'input':") print (y)Der Notebook-Pfad lautet hier /adftutorial/mynotebook.
Wechseln Sie zurück zum Erstellungstool für die Data Factory-Benutzeroberfläche. Navigieren Sie unter der Aktivität Notebook1 zur Registerkarte Einstellungen.
a. Fügen Sie der Notebook-Aktivität einen Parameter hinzu. Verwenden Sie den Parameter, den Sie der Pipeline zuvor hinzugefügt haben.
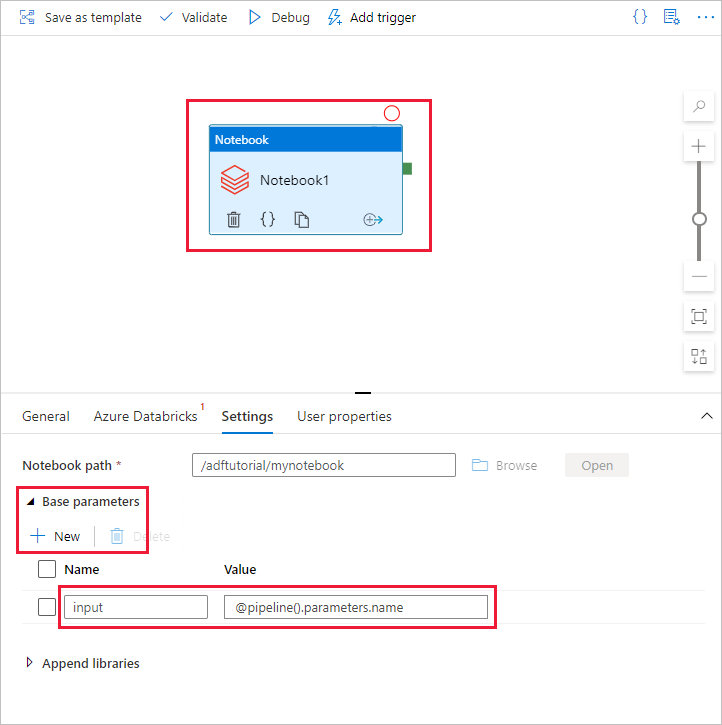
b. Geben Sie dem Parameter den Namen input, und geben Sie den Wert als Ausdruck pipeline().parameters.name an.
Wählen Sie zum Überprüfen der Pipeline in der Symbolleiste die Schaltfläche Überprüfen. Wählen Sie die Schaltfläche Schließen aus, um das Überprüfungsfenster zu schließen.
Wählen Sie Alle veröffentlichen aus. Die Data Factory-Benutzeroberfläche veröffentlicht Entitäten (verknüpfte Dienste und Pipeline) für den Azure Data Factory-Dienst.
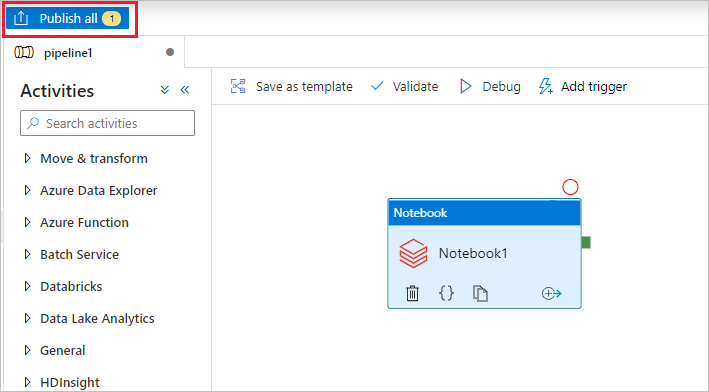
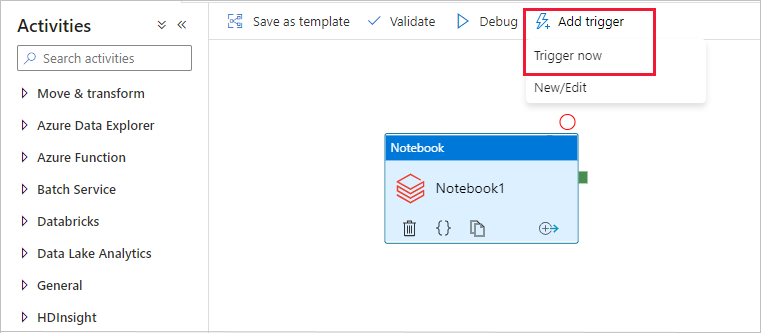
Auslösen einer Pipelineausführung
Wählen Sie auf der Symbolleiste die Option Trigger hinzufügen und dann Trigger now (Jetzt auslösen) aus.
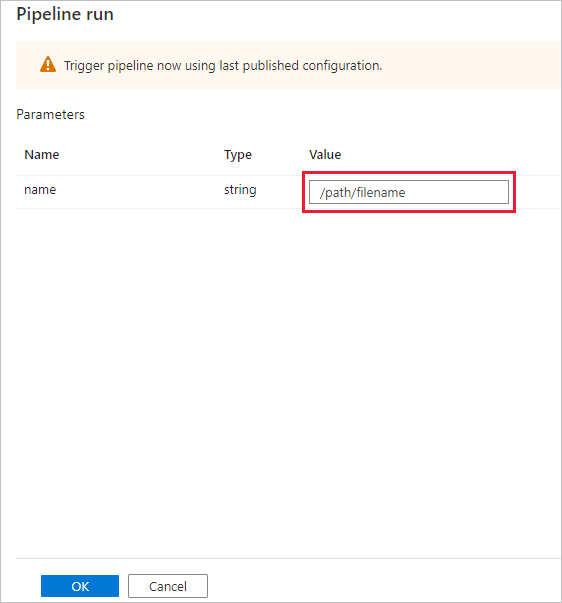
Im Dialogfeld Pipelineausführung wird nach dem Parameter name gefragt. Verwenden Sie hier /path/filename als Parameter. Klicken Sie auf OK.
Überwachen der Pipelineausführung
Wechseln Sie zur Registerkarte Überwachen. Vergewissern Sie sich, dass eine Pipelineausführung angezeigt wird. Die Erstellung eines Databricks-Auftragsclusters, in dem das Notebook ausgeführt wird, dauert ca. fünf bis acht Minuten.
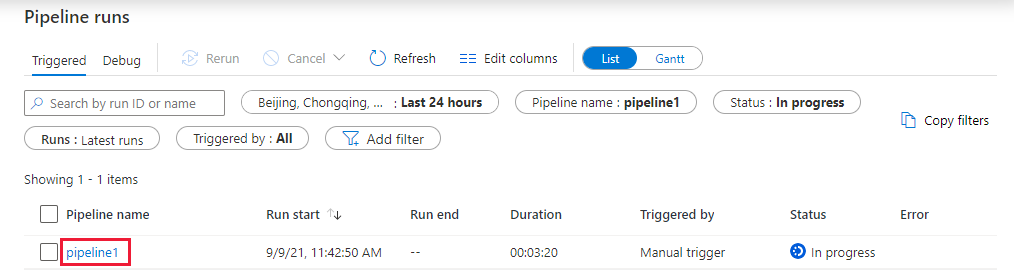
Wählen Sie von Zeit zu Zeit die Option Aktualisieren, um den Status der Pipelineausführung zu überprüfen.
Wenn Sie die der Pipelineausführung zugeordneten Aktivitätsausführungen anzeigen möchten, wählen Sie unter der Spalte Pipelinename den Link pipeline1 aus.
Wählen Sie auf der Seite Aktivitätsausführungen in der Spalte Aktivitätsname die Option Ausgabe aus, um die Ausgabe der einzelnen Aktivitäten anzuzeigen. Im Bereich Ausgabe finden Sie den Link zu Databricks-Protokollen, um ausführlichere Spark-Protokolle zu erhalten.
Sie können zur Ansicht „Pipelineausführungen“ zurückkehren, indem Sie im Breadcrumbmenü oben den Link Alle Pipelineausführungen auswählen.
Überprüfen der Ausgabe
Sie können sich beim Azure Databricks-Arbeitsbereich anmelden und zu Auftragsausführungen navigieren. Unter Auftrag wird der Status „Ausstehende Ausführung“, „Wird ausgeführt“ oder „Beendet“ angezeigt.
Sie können den Auftragsnamen auswählen, um weitere Details anzuzeigen. Bei einer erfolgreichen Ausführung können Sie die übergebenen Parameter und die Ausgabe des Python-Notebooks überprüfen.
Zusammenfassung
Die Pipeline in diesem Beispiel löst eine Databricks-Notebook-Aktivität aus und übergibt einen Parameter. Sie haben Folgendes gelernt:
Erstellen einer Data Factory.
Erstellen einer Pipeline, für die die Databricks-Notebook-Aktivität verwendet wird
Auslösen einer Pipelineausführung
Überwachen der Pipelineausführung.