Kopieren und Transformieren von Daten in Microsoft Fabric Warehouse mithilfe von Azure Data Factory oder Azure Synapse Analytics
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
In diesem Artikel wird beschrieben, wie Sie die Copy-Aktivität verwenden, um Daten aus und in Microsoft Fabric Warehouse zu kopieren. Um mehr zu lernen, lesen Sie den Einführungsartikel für Azure Data Factory oder Azure Synapse Analytics.
Unterstützte Funktionen
Dieser Microsoft Fabric Warehouse-Connector wird für die folgenden Funktionen unterstützt:
| Unterstützte Funktionen | IR | Verwalteter privater Endpunkt |
|---|---|---|
| Kopieraktivität (Quelle/Senke) | ① ② | ✓ |
| Zuordnungsdatenfluss (Quelle/Senke) | ① | ✓ |
| Lookup-Aktivität | ① ② | ✓ |
| GetMetadata-Aktivität | ① ② | ✓ |
| Skriptaktivität | ① ② | ✓ |
| Aktivität „Gespeicherte Prozedur“ | ① ② | ✓ |
① Azure Integration Runtime ② Selbstgehostete Integration Runtime
Erste Schritte
Sie können eines der folgenden Tools oder SDKs verwenden, um die Kopieraktivität mit einer Pipeline zu verwenden:
- Das Tool „Daten kopieren“
- Azure-Portal
- Das .NET SDK
- Das Python SDK
- Azure PowerShell
- Die REST-API
- Die Azure Resource Manager-Vorlage
Erstellen eines verknüpften Microsoft Fabric Warehouse-Diensts mithilfe der Benutzeroberfläche
Führen Sie die folgenden Schritte aus, um einen verknüpften Microsoft Fabric Warehouse-Dienst über die Benutzeroberfläche des Azure-Portals zu erstellen.
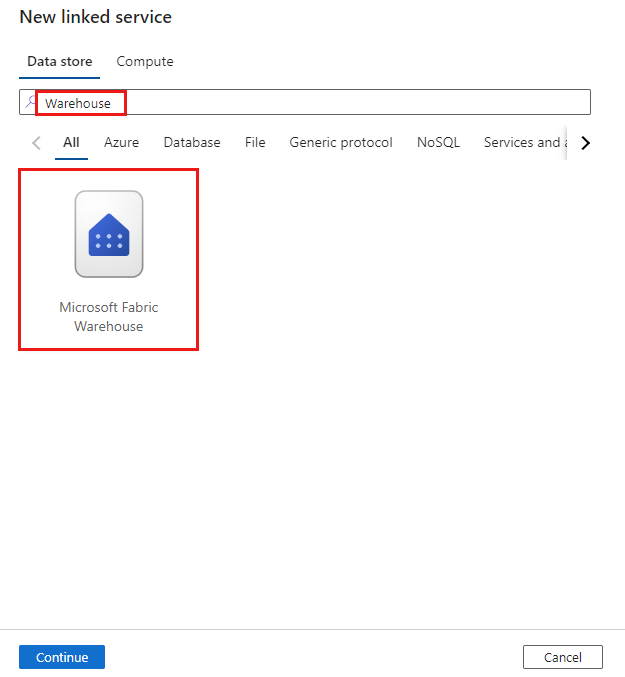
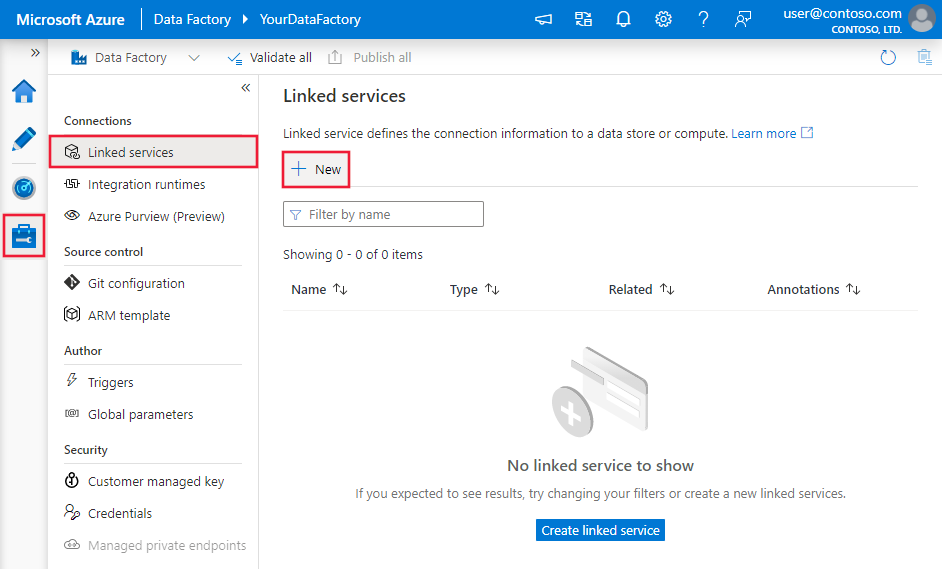
Navigieren Sie in Ihrem Azure Data Factory- oder Synapse-Arbeitsbereich zur Registerkarte Verwalten, und wählen Sie „Verknüpfte Dienste“ und anschließend „Neu“ aus:
Suchen Sie nach „Warehouse“, und wählen Sie den Connector aus.
Konfigurieren Sie die Dienstdetails, testen Sie die Verbindung, und erstellen Sie den neuen verknüpften Dienst.
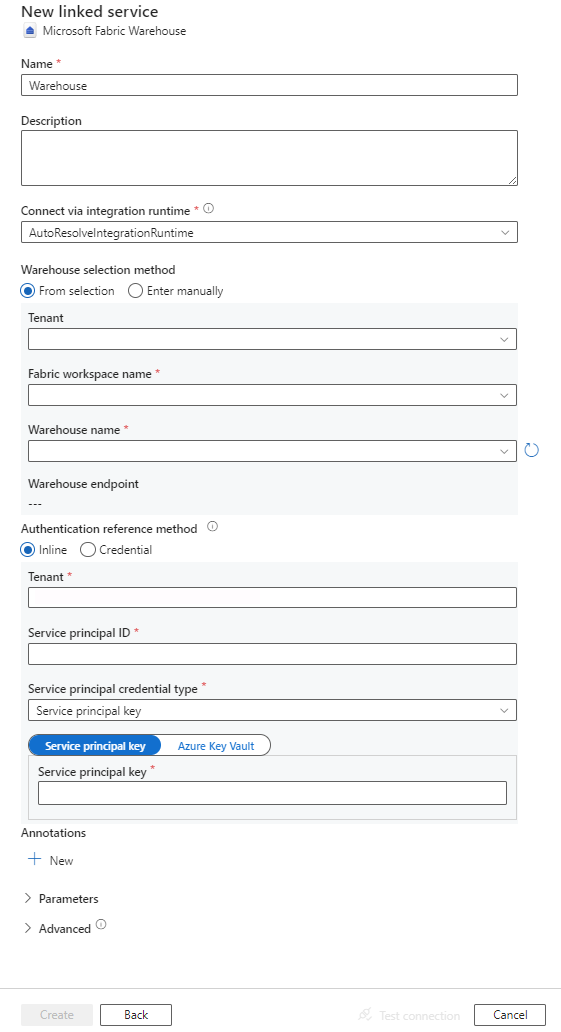
Details zur Connector-Konfiguration
Die folgenden Abschnitte enthalten Details zu Eigenschaften, die zum Definieren von speziellen Data Factory-Entitäten für Microsoft Fabric Warehouse verwendet werden.
Eigenschaften des verknüpften Diensts
Der Microsoft Fabric Warehouse-Connector unterstützt die folgenden Authentifizierungstypen. Weitere Informationen finden Sie in den entsprechenden Abschnitten:
Dienstprinzipalauthentifizierung
Zum Verwenden der Dienstprinzipalauthentifizierung führen Sie die folgenden Schritte aus.
Registrieren einer Anwendung bei der Microsoft Identity Platform und Hinzufügen eines geheimen Clientschlüssels. Notieren Sie sich anschließend die folgenden Werte, die Sie zum Definieren des verknüpften Diensts verwenden können:
- Anwendungs-ID (Client), d. h. die Dienstprinzipal-ID im verknüpften Dienst.
- Wert des geheimen Clientschlüssels, d. h. der Dienstprinzipalschlüssel im verknüpften Dienst.
- Mandanten-ID
Weisen Sie dem Dienstprinzipal mindestens die Rolle Mitwirkender im Microsoft Fabric-Arbeitsbereich zu. Führen Sie folgende Schritte aus:
Wechseln Sie zu Ihrem Microsoft Fabric-Arbeitsbereich, und wählen Sie auf der oberen Leiste Zugriff verwalten aus. Wählen Sie anschließend Personen oder Gruppen hinzufügen aus.
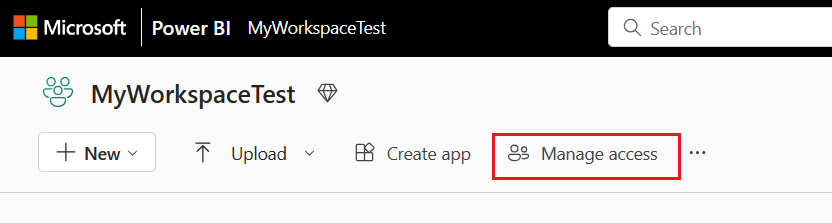
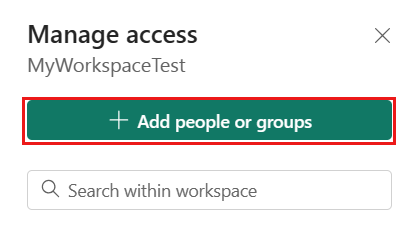
Geben Sie im Bereich Personen hinzufügen den Namen Ihres Dienstprinzipals ein, und wählen Sie Ihren Dienstprinzipal aus der Dropdownliste aus.
Geben Sie als Rolle Mitwirkender oder höher (Administrator, Mitglied) an, und wählen Sie dann Hinzufügen aus.
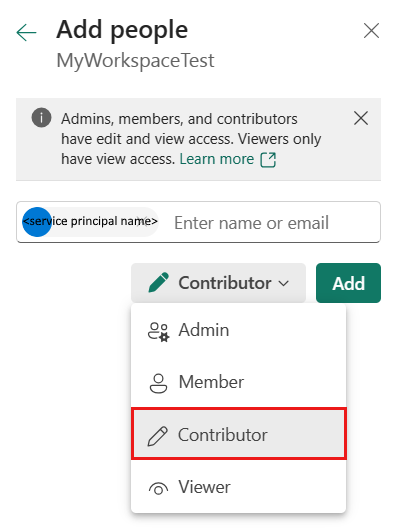
Ihr Dienstprinzipal wird im Bereich Zugriff verwalten angezeigt.
Diese Eigenschaften werden im verknüpften Dienst unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die type-Eigenschaft muss auf Warehouse festgelegt werden. | Ja |
| endpoint | Der Endpunkt des Microsoft Fabric Warehouse-Servers. | Ja |
| workspaceId | Die ID des Microsoft Fabric-Arbeitsbereichs | Ja |
| artifactId | Die Microsoft Fabric Warehouse-Objekt-ID. | Ja |
| tenant | Geben Sie die Mandanteninformationen (Domänenname oder Mandanten-ID) für Ihre Anwendung an. Diese können Sie abrufen, indem Sie im Azure-Portal mit der Maus auf den Bereich oben rechts zeigen. | Ja |
| servicePrincipalId | Geben Sie die Client-ID der Anwendung an. | Ja |
| servicePrincipalCredentialType | Die Art von Anmeldeinformationen, die für die Authentifizierung beim Dienstprinzipal verwendet werden. Gültige Werte sind ServicePrincipalKey und ServicePrincipalCert. | Ja |
| servicePrincipalCredential | Die Anmeldeinformationen für den Dienstprinzipal. Wenn Sie ServicePrincipalKey als Anmeldeinformationstyp verwenden, geben Sie den Wert des geheimen Clientschlüssels der Anwendung an. Markieren Sie dieses Feld als einen SecureString, um es sicher zu speichern, oder verweisen Sie auf ein in Azure Key Vault gespeichertes Geheimnis. Wenn Sie ServicePrincipalCert als Anmeldeinformationen verwenden, verweisen Sie auf ein Zertifikat in Azure Key Vault, und stellen Sie sicher, dass der Zertifikatsinhaltstyp PKCS #12 lautet. |
Ja |
| connectVia | Die Integration Runtime, die zum Herstellen einer Verbindung mit dem Datenspeicher verwendet werden soll. Sie können die Azure Integration Runtime oder eine selbstgehostete Integration Runtime verwenden (sofern sich Ihr Datenspeicher in einem privaten Netzwerk befindet). Wenn kein Wert angegeben ist, wird die standardmäßige Azure Integration Runtime verwendet. | Nein |
Beispiel: Verwenden der Dienstprinzipal-Schlüsselauthentifizierung
Sie können den Dienstprinzipalschlüssel auch in Azure Key Vault speichern.
{
"name": "MicrosoftFabricWarehouseLinkedService",
"properties": {
"type": "Warehouse",
"typeProperties": {
"endpoint": "<Microsoft Fabric Warehouse server endpoint>",
"workspaceId": "<Microsoft Fabric workspace ID>",
"artifactId": "<Microsoft Fabric Warehouse object ID>",
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalKey",
"servicePrincipalCredential": {
"type": "SecureString",
"value": "<service principal key>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Dataset-Eigenschaften
Eine vollständige Liste mit den Abschnitten und Eigenschaften, die zum Definieren von Datasets zur Verfügung stehen, finden Sie im Artikel zu Datasets.
Die folgenden Eigenschaften werden für das Microsoft Fabric Warehouse-Dataset unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die type-Eigenschaft des Datasets muss auf WarehouseTable festgelegt werden. | Ja |
| schema | Name des Schemas. | Quelle: Nein, Senke: Ja |
| table | Name der Tabelle/Ansicht. | Quelle: Nein, Senke: Ja |
Beispiel für Dataseteigenschaften
{
"name": "FabricWarehouseTableDataset",
"properties": {
"type": "WarehouseTable",
"linkedServiceName": {
"referenceName": "<Microsoft Fabric Warehouse linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring >
],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
Eigenschaften der Kopieraktivität
Eine vollständige Liste mit den Abschnitten und Eigenschaften zum Definieren von Aktivitäten finden Sie unter Konfigurationen für die Kopieraktivität und Pipelines und Aktivitäten. Dieser Abschnitt enthält eine Liste der Eigenschaften, die von der Microsoft Fabric Warehouse-Quelle und -Senke unterstützt werden.
Microsoft Fabric Warehouse als Quelle
Tipp
Weitere Informationen zum effizienten Laden von Daten aus Microsoft Fabric Warehouse mithilfe der Datenpartitionierung finden Sie unter Paralleles Kopieren aus Microsoft Fabric Warehouse.
Um Daten aus Microsoft Fabric Warehouse zu kopieren, legen Sie die type-Eigenschaft in der Quelle der Copy-Aktivität auf WarehouseSource fest. Die folgenden Eigenschaften werden im Abschnitt source der Kopieraktivität unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die type-Eigenschaft der Quelle der Copy-Aktivität muss auf WarehouseSource festgelegt werden. | Ja |
| sqlReaderQuery | Verwendet die benutzerdefinierte SQL-Abfrage zum Lesen von Daten. Beispiel: select * from MyTable. |
Nein |
| sqlReaderStoredProcedureName | Name der gespeicherten Prozedur, die Daten aus der Quelltabelle liest. Die letzte SQL-Anweisung muss eine SELECT-Anweisung in der gespeicherten Prozedur sein. | Nein |
| storedProcedureParameters | Parameter für die gespeicherte Prozedur. Zulässige Werte sind Namen oder Name-Wert-Paare. Die Namen und die Groß-/Kleinschreibung von Parametern müssen denen der Parameter der gespeicherten Prozedur entsprechen. |
No |
| queryTimeout | Gibt das Timeout für die Ausführung des Abfragebefehls an. Der Standardwert ist 120 Minuten. | No |
| isolationLevel | Gibt das Sperrverhalten für Transaktionen für die SQL-Quelle an. Der zulässige Wert ist Snapshot. Ohne Angabe wird die Standardisolationsstufe der Datenbank verwendet. Weitere Informationen finden Sie unter system.data.isolationlevel. | Nein |
| partitionOptions | Gibt die Datenpartitionierungsoptionen an, die zum Laden von Daten aus Microsoft Fabric Warehouse verwendet werden. Zulässige Werte sind None (Standardwert) und DynamicRange. Wenn eine Partitionsoption aktiviert ist (d. h. der Wert lautet nicht None), wird der Grad der Parallelität für das gleichzeitige Laden von Daten aus Microsoft Fabric Warehouse durch die Einstellung parallelCopies der Copy-Aktivität gesteuert. |
No |
| partitionSettings | Geben Sie die Gruppe der Einstellungen für die Datenpartitionierung an. Verwenden Sie diese Option, wenn die Partitionsoption nicht None lautet. |
Nein |
Unter partitionSettings: |
||
| partitionColumnName | Geben Sie den Namen der Quellspalte als integer- oder date/datetime-Typ (int, smallint, bigint, date, datetime2) an. Dieser wird von der Bereichspartitionierung für das parallele Kopieren verwendet. Ohne Angabe wird der Index oder der Primärschlüssel der Tabelle automatisch erkannt und als Partitionsspalte verwendet.Verwenden Sie diese Option, wenn die Partitionsoption DynamicRange lautet. Wenn Sie die Quelldaten mithilfe einer Abfrage abrufen, integrieren Sie ?DfDynamicRangePartitionCondition in die WHERE-Klausel. Ein Beispiel finden Sie im Abschnitt Paralleles Kopieren aus Microsoft Fabric Warehouse. |
No |
| partitionUpperBound | Der maximale Wert der Partitionsspalte für das Teilen des Partitionsbereichs. Dieser Wert wird zur Entscheidung über den Partitionssprung verwendet, nicht zum Filtern der Zeilen in der Tabelle. Alle Zeilen in der Tabelle oder im Abfrageergebnis werden partitioniert und kopiert. Wenn nicht angegeben, wird der Wert für die Kopieraktivität automatisch erkannt. Verwenden Sie diese Option, wenn die Partitionsoption DynamicRange lautet. Ein Beispiel finden Sie im Abschnitt Paralleles Kopieren aus Microsoft Fabric Warehouse. |
No |
| partitionLowerBound | Der minimale Wert der Partitionsspalte für das Teilen des Partitionsbereichs. Dieser Wert wird zur Entscheidung über den Partitionssprung verwendet, nicht zum Filtern der Zeilen in der Tabelle. Alle Zeilen in der Tabelle oder im Abfrageergebnis werden partitioniert und kopiert. Wenn nicht angegeben, wird der Wert für die Kopieraktivität automatisch erkannt. Verwenden Sie diese Option, wenn die Partitionsoption DynamicRange lautet. Ein Beispiel finden Sie im Abschnitt Paralleles Kopieren aus Microsoft Fabric Warehouse. |
Nein |
Hinweis
Wenn Sie zum Abrufen von Daten eine gespeicherte Prozedur in der Quelle verwenden und die gespeicherte Prozedur beim Übergeben eines anderen Parameterwerts ein anderes Schema zurückgibt, können beim Importieren eines Schemas über die Benutzeroberfläche oder beim Kopieren von Daten in Microsoft Fabric Warehouse mit der automatischen Tabellenerstellung Fehler oder unerwartete Ergebnisse auftreten.
Beispiel: Verwenden von SQL-Abfragen
"activities":[
{
"name": "CopyFromMicrosoftFabricWarehouse",
"type": "Copy",
"inputs": [
{
"referenceName": "<Microsoft Fabric Warehouse input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "WarehouseSource",
"sqlReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Beispiel: Verwenden von gespeicherten Prozeduren
"activities":[
{
"name": "CopyFromMicrosoftFabricWarehouse",
"type": "Copy",
"inputs": [
{
"referenceName": "<Microsoft Fabric Warehouse input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "WarehouseSource",
"sqlReaderStoredProcedureName": "CopyTestSrcStoredProcedureWithParameters",
"storedProcedureParameters": {
"stringData": { "value": "str3" },
"identifier": { "value": "$$Text.Format('{0:yyyy}', <datetime parameter>)", "type": "Int"}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Gespeicherte Beispielprozedur:
CREATE PROCEDURE CopyTestSrcStoredProcedureWithParameters
(
@stringData varchar(20),
@identifier int
)
AS
SET NOCOUNT ON;
BEGIN
select *
from dbo.UnitTestSrcTable
where dbo.UnitTestSrcTable.stringData != stringData
and dbo.UnitTestSrcTable.identifier != identifier
END
GO
Microsoft Fabric Warehouse als Senkentyp
Azure Data Factory- und Azure Synapse-Pipelines unterstützen die Verwendung der COPY-Anweisung zum Laden von Daten in Microsoft Fabric Warehouse.
Legen Sie zum Kopieren von Daten in Microsoft Fabric Warehouse den Senkentyp in der Copy-Aktivität auf WarehouseSink fest. Die folgenden Eigenschaften werden im Abschnitt sink der Kopieraktivität unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die type-Eigenschaft der Senke der Copy-Aktivität muss auf WarehouseSink festgelegt werden. | Ja |
| allowCopyCommand | Gibt an, ob die COPY-Anweisung zum Laden von Daten in Microsoft Fabric Warehouse verwendet wird. Einschränkungen und Details finden Sie im Abschnitt Verwenden der COPY-Anweisung zum Laden von Daten in Microsoft Fabric Warehouse. Der zulässige Wert ist True. |
Ja |
| copyCommandSettings | Eine Gruppe von Eigenschaften, die angegeben werden können, wenn die Eigenschaft allowCopyCommand auf TRUE festgelegt ist. |
No |
| writeBatchTimeout | Diese Eigenschaft gibt die Wartezeit für den Abschluss der Insert- und Upsert-Vorgänge und die gespeicherte Prozedur an, bevor ein Timeout auftritt. Zulässige Werte werden für den Zeitraum verwendet. Beispiel: „00:30:00“ für 30 Minuten. Wenn kein Wert festgelegt ist, wird für das Timeout der Standardwert „00:30:00“ verwendet. |
No |
| preCopyScript | Geben Sie eine SQL-Abfrage für die Copy-Aktivität an, die bei jeder Ausführung ausgeführt wird, bevor Daten in Microsoft Fabric Warehouse geschrieben werden. Sie können diese Eigenschaft nutzen, um vorab geladene Daten zu bereinigen. | Nein |
| tableOption | Gibt an, ob die Senkentabelle auf Basis des Quellschemas automatisch erstellt werden soll, wenn sie nicht vorhanden ist. Zulässige Werte: none (Standard), autoCreate. |
Nein |
| disableMetricsCollection | Der Dienst sammelt Metriken für die Leistungsoptimierung von Kopiervorgängen und für Empfehlungen, wodurch zusätzlicher Zugriff auf die Masterdatenbank ermöglicht wird. Wenn Sie sich wegen dieses Verhaltens Gedanken machen, geben Sie true an, um es zu deaktivieren. |
Nein (Standard = false) |
Beispiel: Microsoft Fabric Warehouse-Senke
"activities":[
{
"name": "CopyToMicrosoftFabricWarehouse",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Microsoft Fabric Warehouse output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "WarehouseSink",
"allowCopyCommand": true,
"tableOption": "autoCreate",
"disableMetricsCollection": false
}
}
}
]
Paralleles Kopieren aus Microsoft Fabric Warehouse
Der Microsoft Fabric Warehouse-Connector in der Copy-Aktivität verfügt über eine integrierte Datenpartitionierung zum parallelen Kopieren von Daten. Die Datenpartitionierungsoptionen befinden sich auf der Registerkarte Quelle der Kopieraktivität.
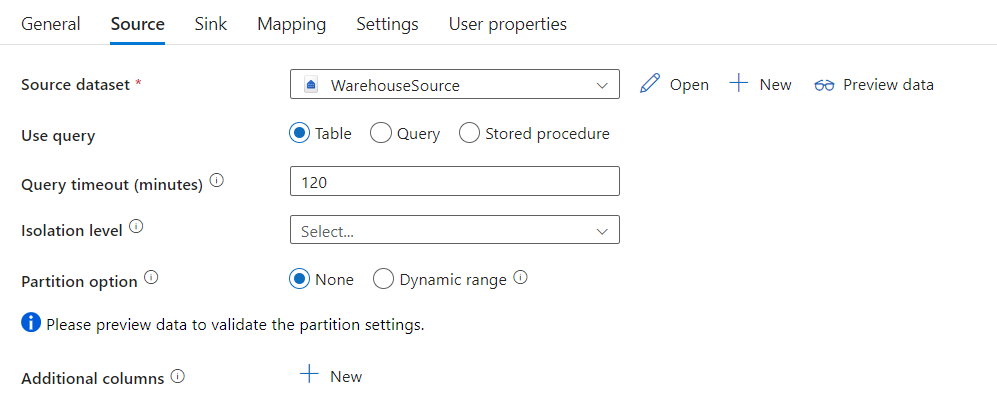
Wenn Sie das partitionierte Kopieren aktivieren, führt die Copy-Aktivität parallele Abfragen für Ihre Microsoft Fabric Warehouse-Quelle aus, um Daten nach Partitionen zu laden. Der Parallelitätsgrad wird über die Einstellung parallelCopies der Kopieraktivität gesteuert. Wenn Sie parallelCopies z. B. auf 4 festlegen, generiert der Dienst gleichzeitig vier Abfragen auf der Grundlage der von Ihnen angegebenen Partitionsoption und -einstellungen und führt sie aus, wobei jede Abfrage einen Teil der Daten aus Microsoft Fabric Warehouse abruft.
Es wird empfohlen, das parallele Kopieren mit Datenpartitionierung vor allem dann zu aktivieren, wenn Sie große Datenmengen aus Microsoft Fabric Warehouse laden. Im Anschluss finden Sie empfohlene Konfigurationen für verschiedene Szenarien. Beim Kopieren von Daten in einen dateibasierten Datenspeicher wird empfohlen, mehrere Dateien in einen Ordner zu schreiben (nur den Ordnernamen anzugeben). In diesem Fall ist die Leistung besser als beim Schreiben in eine einzelne Datei.
| Szenario | Empfohlene Einstellungen |
|---|---|
| Vollständiges Laden aus einer großen Tabelle mit einer integer- oder datetime-Spalte für die Datenpartitionierung | Partitionsoptionen: Dynamische Bereichspartitionierung Partitionsspalte (optional): Geben Sie die Spalte für die Datenpartitionierung an. Ohne Angabe wird der Index oder die Primärschlüsselspalte verwendet. Obergrenze der Partition und Untergrenze der Partition (optional): Geben Sie an, ob Sie den Partitionssprung bestimmen möchten. Dies dient nicht zum Filtern der Zeilen in der Tabelle, und alle Zeilen in der Tabelle werden partitioniert und kopiert. Wenn nicht angegeben, werden die Werte für die Kopieraktivität automatisch erkannt. Wenn Ihre Partitionsspalte "ID" beispielsweise einen Wertebereich von 1 bis 100 hat und Sie die untere Grenze auf 20 und die obere Grenze auf 80 und die Parallelkopie auf 4 setzen, ruft der Dienst Daten nach 4 Partitionen ab - IDs im Bereich <=20, [21, 50], [51, 80] bzw. >=81. |
| Laden einer großen Datenmenge unter Verwendung einer benutzerdefinierten Abfrage mit einer integer- oder date/datetime-Spalte für die Datenpartitionierung | Partitionsoptionen: Dynamische Bereichspartitionierung Abfrage: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>Partitionsspalte: Geben Sie die Spalte für die Datenpartitionierung an. Obergrenze der Partition und Untergrenze der Partition (optional): Geben Sie an, ob Sie den Partitionssprung bestimmen möchten. Dies dient nicht zum Filtern der Zeilen in der Tabelle, und alle Zeilen im Abfrageergebnis werden partitioniert und kopiert. Wenn nicht angegeben, wird der Wert für die Kopieraktivität automatisch erkannt. Wenn Ihre Partitionsspalte „ID“ beispielsweise einen Wertebereich von 1 bis 100 hat und Sie die untere Grenze auf 20, die obere Grenze auf 80 und die Parallelkopie auf 4 festlegen, ruft der Dienst Daten nach 4 Partitionen ab – IDs im Bereich <=20, [21, 50], [51, 80] bzw. >=81. Hier finden Sie weitere Beispiele für verschiedene Szenarien: 1. Abfrage der gesamten Tabelle: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition2. Abfrage aus einer Tabelle mit Spaltenauswahl und zusätzlichen Where-Klausel-Filtern: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>3. Abfragen mit Unterabfragen: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>4. Abfrage mit Partition in Unterabfrage: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Bewährte Methoden zum Laden von Daten mit Partitionierungsoption:
- Wählen Sie eine aussagekräftige Spalte als Partitionsspalte (wie Primärschlüssel oder eindeutiger Schlüssel), um Datenabweichungen zu vermeiden.
- Wenn Sie Azure Integration Runtime zum Kopieren von Daten verwenden, können Sie größere „Datenintegrationseinheiten (Data Integration Units, DIU)“ festlegen (> 4), um mehr Computingressourcen zu nutzen. Prüfen Sie dort die anwendbaren Szenarien.
- „Grad der Kopierparallelität“ steuert die Partitionsnummern. Ein zu großer Wert schadet manchmal der Leistung. Deshalb wird empfohlen, diesen Wert wie folgt festzulegen: (DIU oder Anzahl der selbstgehosteten IR-Knoten) × (2 bis 4).
- Beachten Sie, dass Microsoft Fabric Warehouse maximal 32 Abfragen gleichzeitig ausführen kann. Wenn Sie „Parallelitätsgrad für Kopiervorgänge“ auf einen zu hohen Wert festlegen, kann dies zu einem Warehouse-Drosselungsproblem führen.
Beispiel: Abfrage mit dynamischer Bereichspartition
"source": {
"type": "WarehouseSource",
"query": "SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Verwenden der COPY-Anweisung zum Laden von Daten in Microsoft Fabric Warehouse
Die Verwendung der COPY-Anweisung ist eine einfache und flexible Möglichkeit, um Daten mit hohem Durchsatz in Microsoft Fabric Warehouse zu laden. Weitere Informationen finden Sie unter Massenladen von Daten mit der COPY-Anweisung.
- Wenn sich Ihre Quelldaten in Azure Blob Storage oder Azure Data Lake Storage Gen2 befinden und das Format kompatibel mit der COPY-Anweisung ist, können Sie die COPY-Anweisung direkt über die Copy-Aktivität aufrufen, damit Microsoft Fabric Warehouse die Daten aus der Quelle pullen kann. Details finden Sie unter Direktes Kopieren mithilfe der COPY-Anweisung .
- Wenn der Speicher und das Format der Quelldaten von der COPY-Anweisung ursprünglich nicht unterstützt werden, können Sie stattdessen das Feature Gestaffeltes Kopieren mithilfe der COPY-Anweisung verwenden. Das Feature für gestaffeltes Kopieren bietet Ihnen auch einen höheren Durchsatz. Es konvertiert die Daten automatisch in ein mit der COPY-Anweisung kompatibles Format, speichert die Daten in Azure Blob Storage und ruft dann die COPY-Anweisung auf, um die Daten in Microsoft Fabric Warehouse zu laden.
Tipp
Bei Verwendung der COPY-Anweisung mit Azure Integration Runtime sind die effektiven Datenintegrationseinheiten (DIUs) immer auf 2 festgelegt. Die Optimierung der Datenintegrationseinheit (Data Integration Unit, DIU) hat keinen Einfluss auf die Leistung.
Direktes Kopieren mithilfe der COPY-Anweisung
Azure Blob Storage, Azure Data Lake Storage Gen1 und Azure Data Lake Storage Gen2 werden von der COPY-Anweisung von Microsoft Fabric Warehouse direkt unterstützt. Wenn Ihre Quelldaten die in diesem Abschnitt beschriebenen Kriterien erfüllen, können Sie Daten mithilfe der COPY-Anweisung direkt aus dem Quelldatenspeicher in Microsoft Fabric Warehouse kopieren. Andernfalls können Sie das gestaffelte Kopieren mithilfe der COPY-Anweisung verwenden. Der Dienst überprüft die Einstellungen und gibt bei der Ausführung der Copy-Aktivität einen Fehler aus, wenn die Kriterien nicht erfüllt werden.
Der mit der Quelle verknüpfte Dienst und das Format verfügen über die folgenden Typen und Authentifizierungsmethoden:
Unterstützter Quelldatenspeichertyp Unterstütztes Format Unterstützter Quellauthentifizierungstyp Azure-Blob Text mit Trennzeichen Kontoschlüsselauthentifizierung, SAS-Authentifizierung (Shared Access Signature) Parquet Kontoschlüsselauthentifizierung, SAS-Authentifizierung (Shared Access Signature) Azure Data Lake Storage Gen2 Text mit Trennzeichen
ParquetKontoschlüsselauthentifizierung, SAS-Authentifizierung (Shared Access Signature) Die Formateinstellungen lauten folgendermaßen:
- Bei Parquet:
compressionkann auf Keine Komprimierung, Snappy oderGZipfestgelegt werden. - Bei Text mit Trennzeichen:
rowDelimiterist explizit festgelegt auf einzelnes Zeichen oder \r\n. Der Standardwert wird nicht unterstützt.nullValuewird als Standardwert übernommen oder ist auf leere Zeichenfolge („“) festgelegt.encodingNamewird als Standardwert übernommen oder ist auf utf-8 oder utf-16 festgelegt.escapeCharmussquoteCharentsprechen und darf nicht leer sein.skipLineCountwird als Standardwert übernommen oder ist auf 0 festgelegt.compressionkann auf keine Komprimierung oderGZipfestgelegt werden.
- Bei Parquet:
Wenn es sich bei der Quelle um einen Ordner handelt, muss
recursivebeim Kopiervorgang auf „TRUE“ festgelegt sein, undwildcardFilenamemuss*oder*.*sein.wildcardFolderPath,wildcardFilename(anders als*oder*.*),modifiedDateTimeStart,modifiedDateTimeEnd,prefix,enablePartitionDiscoveryundadditionalColumnswerden nicht angegeben.
Die folgenden Einstellungen der COPY-Anweisung werden unter allowCopyCommand in der Kopieraktivität unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| defaultValues | Gibt die Standardwerte für jede Zielspalte in Microsoft Fabric Warehouse an. Die Standardwerte in der Eigenschaft überschreiben die in Data Warehouse festgelegte DEFAULT-Einschränkung, und die Identitätsspalte darf keinen Standardwert haben. | Nein |
| additionalOptions | Zusätzliche Optionen, die direkt in der WITH-Klausel der COPY-Anweisung an eine COPY-Anweisung von Microsoft Fabric Warehouse übergeben werden. Geben Sie den Wert so an, wie er gemäß den Anforderungen der COPY-Anweisung erforderlich ist. | Nein |
"activities":[
{
"name": "CopyFromAzureBlobToMicrosoftFabricWarehouseViaCOPY",
"type": "Copy",
"inputs": [
{
"referenceName": "ParquetDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "MicrosoftFabricWarehouseDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "ParquetSource",
"storeSettings":{
"type": "AzureBlobStorageReadSettings",
"recursive": true
}
},
"sink": {
"type": "WarehouseSink",
"allowCopyCommand": true,
"copyCommandSettings": {
"defaultValues": [
{
"columnName": "col_string",
"defaultValue": "DefaultStringValue"
}
],
"additionalOptions": {
"MAXERRORS": "10000",
"DATEFORMAT": "'ymd'"
}
}
},
"enableSkipIncompatibleRow": true
}
}
]
Gestaffeltes Kopieren mithilfe der COPY-Anweisung
Wenn Ihre Quelldaten nicht nativ mit der COPY-Anweisung kompatibel sind, können Sie die Daten über eine zwischengeschaltete Azure Blob- oder Azure Data Lake Storage Gen2-Instanz mit Staging kopieren (es kann nicht Azure Storage Premium sein). In diesem Fall konvertiert der Dienst die Daten automatisch, damit das Datenformat den Anforderungen der COPY-Anweisung entspricht. Anschließend ruft er die COPY-Anweisung auf, um Daten in Microsoft Fabric Warehouse zu laden. Abschließend werden Sie die temporären Daten im Speicher bereinigt. Ausführliche Informationen zum Kopieren von Daten mithilfe von Staging finden Sie unter Gestaffeltes Kopieren.
Um dieses Feature verwenden zu können, erstellen Sie einen mit Azure Blob Storage verknüpften Dienst oder einen mit Azure Data Lake Storage Gen2 verknüpften Dienst mit Authentifizierung per Kontoschlüssel oder systemverwalteter Identität, der auf das Azure Storage-Konto als Zwischenspeicher verweist.
Wichtig
- Wenn Sie die Authentifizierung per verwalteter Identität für den verknüpften Stagingdienst verwenden, machen Sie sich jeweils mit den erforderlichen Konfigurationen für Azure Blob und Azure Data Lake Storage Gen2 vertraut.
- Wenn Ihre Azure Storage-Staginginstanz mit einem VNET-Dienstendpunkt konfiguriert ist, müssen Sie die Authentifizierung per verwalteter Identität mit für das Speicherkonto aktivierter Option „Vertrauenswürdigen Microsoft-Diensten den Zugriff auf dieses Speicherkonto erlauben“ verwenden. Informationen hierzu finden Sie unter Auswirkungen der Verwendung von VNET-Dienstendpunkten mit Azure Storage.
Wichtig
Wenn Ihre Azure Storage-Staginginstanz mit verwaltetem privatem Endpunkt konfiguriert und die Speicherfirewall aktiviert ist, müssen Sie die Authentifizierung per verwalteter Identität verwenden und dem Speicherblob-Datenleser Berechtigungen für die Synapse SQL Server-Instanz gewähren, um sicherzustellen, dass er während des Ladens mit der COPY-Anweisung auf die bereitgestellten Dateien zugreifen kann.
"activities":[
{
"name": "CopyFromSQLServerToMicrosoftFabricWarehouseViaCOPYstatement",
"type": "Copy",
"inputs": [
{
"referenceName": "SQLServerDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "MicrosoftFabricWarehouseDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
},
"sink": {
"type": "WarehouseSink",
"allowCopyCommand": true
},
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
}
}
}
}
]
Eigenschaften von Mapping Data Flow
Beim Transformieren von Daten im Zuordnungsdatenfluss können Sie Tabellen in Microsoft Fabric Warehouse lesen und schreiben. Weitere Informationen finden Sie unter Quellentransformation und Senkentransformation in Zuordnungsdatenflüssen.
Microsoft Fabric Warehouse als Quelle
Spezifische Einstellungen für Microsoft Fabric Warehouse sind auf der Registerkarte „Quellenoptionen” der Quellentransformation verfügbar.
| Name | BESCHREIBUNG | Erforderlich | Zulässige Werte | Datenflussskript-Eigenschaft |
|---|---|---|---|---|
| Eingabe | Wählen Sie aus, ob Sie die Quelle auf eine Tabelle verweisen (Äquivalent von * aus Tabellenname auswählen), oder geben Sie eine benutzerdefinierte SQL-Abfrage ein, oder rufen Sie Daten aus einer gespeicherten Prozedur ab. Query (Abfrage): Wenn Sie im Eingabefeld „Abfrage“ auswählen, geben Sie eine SQL-Abfrage für die Quelle ein. Diese Einstellung überschreibt jede Tabelle, die Sie im Dataset ausgewählt haben. Order By-Klauseln werden hier nicht unterstützt. Sie können aber eine vollständige SELECT FROM-Anweisung festlegen. Sie können auch benutzerdefinierte Tabellenfunktionen verwenden. select * from udfGetData() ist eine benutzerdefinierte Funktion in SQL, die eine Tabelle zurückgibt. Diese Abfrage generiert eine Quelltabelle, die Sie in Ihrem Datenfluss verwenden können. Die Verwendung von Abfragen stellt auch eine gute Möglichkeit dar, um die Zeilen für Tests oder Suchvorgänge zu verringern. SQL-Beispiel: Select * from MyTable where customerId > 1000 and customerId < 2000 |
Ja | Tabelle oder Abfrage oder gespeicherte Prozedur | Format: „Table“ |
| Batchgröße | Geben Sie eine Batchgröße ein, um große Datenmengen in Leseblöcke zu segmentieren. In Datenflüssen wird diese Einstellung verwendet, um die Spark-Zwischenspeicherung in Spalten festzulegen. Dies ist ein Optionsfeld, in dem Spark-Standardwerte verwendet werden, wenn kein Wert eingegeben wurde. | No | Nummernwerte | batchSize: 1234 |
| Isolationsstufe | Der Standardwert für SQL-Quellen in Mapping Data Flow lautet „Lesen nicht zugesichert“. Sie können die Isolationsstufe hier in einen der folgenden Werte ändern:• Read Committed • Read Uncommitted • Repeatable Read • Serializable • None (Isolationsstufe ignorieren) | Ja | • Read Committed • Read Uncommitted • Repeatable Read • Serializable • None (Isolationsstufe ignorieren) | isolationLevel |
Hinweis
Lesezugriff über Staging wird nicht unterstützt. Eine CDC-Unterstützung ist für Microsoft Fabric Warehouse-Quellen derzeit nicht verfügbar.
Microsoft Fabric Warehouse als Senke
Spezifische Einstellungen für Microsoft Fabric Warehouse sind auf der Registerkarte „Einstellungen” der Senkentransformation verfügbar.
| Name | BESCHREIBUNG | Erforderlich | Zulässige Werte | Datenflussskript-Eigenschaft |
|---|---|---|---|---|
| Updatemethode | Bestimmt, welche Vorgänge für das Datenbankziel zulässig sind. Standardmäßig sind lediglich Einfügevorgänge zulässig. Wenn Sie für Zeilen Update-, Upsert- oder Löschvorgänge verwenden möchten, fügen Sie zunächst eine Transformation zur Änderung von Zeilen hinzu, um Zeilen für diese Aktionen zu kennzeichnen. Für Update-, Upsert- und Löschvorgänge muss mindestens eine Schlüsselspalte festgelegt werden, um die Zeile zu bestimmen, die geändert werden soll. | Ja | true oder false | einfügebares aktualisierbares upsertable-Update |
| Tabellenaktion | Bestimmt, ob die Zieltabelle vor dem Schreiben neu erstellt werden soll oder alle Zeilen aus der Zieltabelle entfernt werden sollen.• None: An der Tabelle wird keine Aktion ausgeführt. • Recreate: Die Tabelle wird gelöscht und neu erstellt. Erforderlich, wenn eine neue Tabelle dynamisch erstellt wird.• Truncate: Alle Zeilen aus der Zieltabelle werden entfernt. | No | None oder Recreate oder Truncate | Recreate: true Truncate: true |
| Staging aktivieren | Der Stagingspeicher wird unter Datenflussaktivität in Azure Data Factory konfiguriert. Wenn Sie die verwaltete Identitätsauthentifizierung für Ihren mit dem Speicher verknüpften Dienst verwenden, machen Sie sich mit den erforderlichen Konfigurationen für Azure Blob bzw. Azure Data Lake Storage Gen2 vertraut. Wenn Ihr Azure Storage mit dem VNet-Dienstendpunkt konfiguriert ist, müssen Sie die verwaltete Identitätsauthentifizierung mit der aktivierten Option "vertrauenswürdigen Microsoft-Dienst zulassen" für das Speicherkonto verwenden. Siehe Auswirkungen der Verwendung von VNET-Dienstendpunkten mit Azure Storage. | No | true oder false | stufend: true |
| Batchgröße | Steuert, wie viele Zeilen in die einzelnen Buckets geschrieben werden. Durch größere Batches werden zwar Komprimierung und Arbeitsspeicheroptimierung verbessert, beim Zwischenspeichern von Daten besteht aber die Gefahr, dass Ausnahmen wegen unzureichenden Arbeitsspeichers auftreten. | No | Nummernwerte | batchSize: 1234 |
| Verwenden des Senkenschemas | Standardmäßig wird eine temporäre Tabelle unter dem Sinkschema als Staging erstellt. Alternativ können Sie die Option Sinkschema verwenden deaktivieren, und stattdessen einen Schemanamen in Benutzer-DB-Schema verwenden angeben, unter dem Data Factory eine Stagingtabelle erstellt, um vorgelagerte Daten zu laden und diese automatisch nach Abschluss zu löschen. Stellen Sie sicher, dass Sie Tabellenberechtigungen in der Datenbank erstellen und die Berechtigung für das Schema ändern. | No | true oder false | stagingSchemaName |
| Pre- und Post-SQL-Skripts | Geben Sie mehrzeilige SQL-Skripts ein, die ausgeführt werden, bevor Daten in die Senkendatenbank geschrieben werden (Vorverarbeitung) und danach (Nachbearbeitung). | No | SQL-Skripts | preSQLs:['set IDENTITY_INSERT mytable ON'] postSQLs:['set IDENTITY_INSERT mytable OFF'], |
Fehlerzeilenbehandlung
Standardmäßig scheitert eine Datenflussausführung beim ersten erhaltenen Fehler. Sie können die Option Bei Fehler fortsetzen auswählen, die einen Abschluss des Datenflusses auch dann ermöglicht, wenn einzelne Zeilen Fehler aufweisen. Der Dienst bietet Ihnen verschiedene Optionen, mit denen Sie diese Fehlerzeilen behandeln können.
Transaktionscommit: Wählen Sie aus, ob Ihre Daten in einer einzelnen Transaktion oder in Batches geschrieben werden. Eine einzelne Transaktion führt zu einer besseren Leistung, und es werden keine geschriebenen Daten für andere sichtbar gemacht, bis die Transaktion abgeschlossen ist. Batchtransaktionen haben eine schlechtere Leistung, können aber für große Datasets verwendet werden.
Abgelehnte Daten ausgeben: Wenn diese Option aktiviert ist, können Sie die Fehlerzeilen in eine CSV-Datei in Azure Blob Storage oder ein Azure Data Lake Storage Gen2-Konto Ihrer Wahl ausgeben. Dadurch werden die Fehlerzeilen mit drei zusätzlichen Spalten geschrieben: dem SQL-Vorgang wie INSERT oder UPDATE, dem Datenfluss-Fehlercode und der Fehlermeldung für die Zeile.
Bericht bei Fehler als erfolgreich markieren: Wenn diese Option aktiviert ist, wird der Datenfluss als erfolgreich markiert, auch wenn Fehlerzeilen gefunden werden.
Hinweis
Für Microsoft Fabric Warehouse Linked Service lautet der unterstützte Authentifizierungstyp für den Dienstprinzipal "Key". "Zertifikat"-Authentifizierung wird nicht unterstützt.
Eigenschaften der Lookup-Aktivität
Ausführliche Informationen zu den Eigenschaften finden Sie unter Lookup-Aktivität.
Eigenschaften der GetMetadata-Aktivität
Ausführliche Informationen zu den Eigenschaften finden Sie unter GetMetadata-Aktivität.
Datentypzuordnung für Microsoft Fabric Warehouse
Beim Kopieren von Daten aus Microsoft Fabric Warehouse werden innerhalb des Diensts die folgenden Zuordnungen von Microsoft Fabric Warehouse-Datentypen zu Zwischendatentypen verwendet. Weitere Informationen dazu, wie die Kopieraktivität das Quellschema und den Datentyp zur Senke zuordnet, finden Sie unter Schema- und Datentypzuordnungen.
| Microsoft Fabric Warehouse-Datentyp | Data Factory-Zwischendatentyp |
|---|---|
| BIGINT | Int64 |
| BINARY | Byte[] |
| bit | Boolean |
| char | String, Char[] |
| date | Datetime |
| datetime2 | DateTime |
| Decimal | Decimal |
| FILESTREAM attribute (varbinary(max)) | Byte[] |
| Float | Double |
| int | Int32 |
| NUMERIC | Decimal |
| real | Single |
| smallint | Int16 |
| time | TimeSpan |
| UNIQUEIDENTIFIER | Guid |
| varbinary | Byte[] |
| varchar | String, Char[] |
Nächste Schritte
Eine Liste der Datenspeicher, die als Quelles und Senken für die Kopieraktivität unterstützt werden, finden Sie in Unterstützte Datenspeicher.