Optimieren von Quellen
Für jede Quelle – mit Ausnahme von Azure SQL-Datenbank – lautet die Empfehlung, die Option Aktuelle Partitionierung verwenden ausgewählt zu lassen. Beim Lesen von allen anderen Quellsystemen werden Daten von Datenflüssen je nach Größe automatisch gleichmäßig partitioniert. Für ca. 128 MB an Daten wird jeweils eine neue Partition erstellt. Wenn die Datengröße zunimmt, steigt die Anzahl von Partitionen.
Alle benutzerdefinierten Partitionierungen werden durchgeführt, nachdem die Daten von Spark eingelesen wurden. Dies wirkt sich negativ auf die Leistung Ihres Datenflusses aus. Da die Daten beim Lesen gleichmäßig partitioniert werden, wird dies nicht empfohlen, es sei denn, Sie verstehen zuerst die Form und Kardinalität Ihrer Daten.
Hinweis
Die Lesegeschwindigkeiten können aufgrund des Durchsatzes Ihres Quellsystems begrenzt sein.
Azure SQL-Datenbank-Quellen
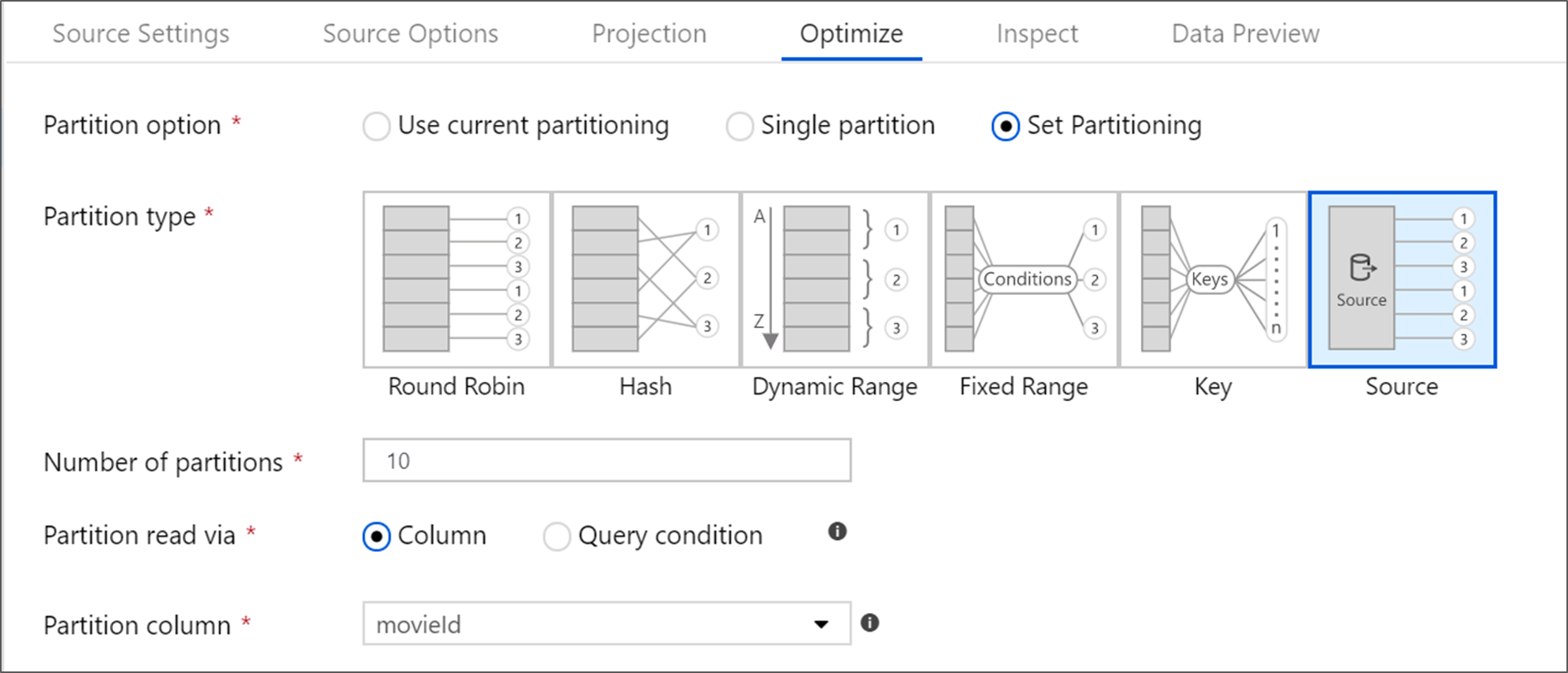
Azure SQL-Datenbank verfügt über eine eindeutige Partitionierungsoption, die die Bezeichnung „Quellpartitionierung“ hat. Durch das Aktivieren der Quellpartitionierung können Sie Ihre Lesedauer für Azure SQL-Datenbank verbessern, indem Sie auf dem Quellsystem parallele Verbindungen aktivieren. Geben Sie die Anzahl von Partitionen und die Partitionierung Ihrer Daten an. Verwenden Sie eine Partitionsspalte mit hoher Kardinalität. Sie können auch eine Abfrage eingeben, die zum Partitionierungsschema Ihrer Quelltabelle passt.
Tipp
Bei der Quellpartitionierung ist der E/A-Vorgang von SQL Server der Engpass. Das Hinzufügen von zu vielen Partitionen kann dazu führen, dass die Quelldatenbank vollständig ausgelastet ist. Im Allgemeinen sind bei Verwendung dieser Option vier oder fünf Partitionen ideal.
Isolationsstufe
Die Isolationsstufe des Lesevorgangs auf einem Azure SQL-Quellsystem wirkt sich auf die Leistung aus. Wenn Sie die Option „Lesen ohne Commit“ auswählen, ergibt sich die schnellste Leistung, und Datenbanksperren werden verhindert. Weitere Informationen zu SQL-Isolationsstufen finden Sie unter Grundlegendes zu Isolationsstufen.
Lesen per Abfrage
Sie können Lesevorgänge aus Azure SQL-Datenbank durchführen, indem Sie eine Tabelle oder SQL-Abfrage verwenden. Wenn Sie eine SQL-Abfrage ausführen, muss diese abgeschlossen werden, bevor die Transformation gestartet werden kann. SQL-Abfragen können nützlich sein, um einen Pushdown für Vorgänge durchzuführen, damit diese dann ggf. schneller ausgeführt werden, und um die Menge der von einer SQL Server-Instanz gelesenen Daten zu reduzieren, z. B. SELECT-, WHERE- und JOIN-Anweisungen. Bei einem Pushdown von Vorgängen ist es nicht mehr möglich, die Herkunft und Leistung der Transformationen nachzuverfolgen, bevor die Daten in den Datenfluss gelangen.
Azure Synapse Analytics-Quellen
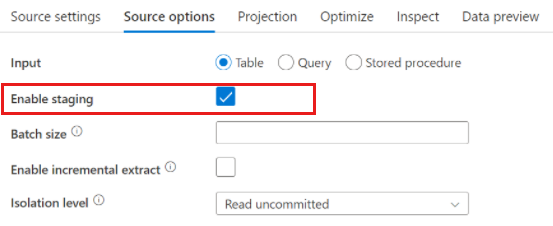
Bei Verwendung von Azure Synapse Analytics ist in den Quelloptionen die Einstellung Staging aktivieren vorhanden. Dadurch kann der Dienst per Staging aus Synapse lesen. Dies verbessert die Leseleistung erheblich, da sehr leistungsstarke Funktionen zum Massenladen verwendet werden, wie z. B. CETAS- und COPY-Befehle. Beim Aktivieren von Staging müssen Sie in den Einstellungen für Datenflussaktivitäten einen Azure Blob Storage- oder Azure Data Lake Storage Gen2-Stagingspeicherort angeben.
Dateibasierte Quellen
Parquet im Vergleich zum mit durch Trennzeichen getrennten Text
Für Datenflüsse werden zwar verschiedene Dateitypen unterstützt, zum Erzielen von optimalen Lese- und Schreibzeiten wird aber das native Spark-Format „Parquet“ empfohlen.
Wenn Sie den gleichen Datenfluss für mehrere Dateien ausführen, empfehlen wir Ihnen, die Daten aus einem Ordner zu lesen, Platzhalterpfade zu verwenden oder die Daten aus einer Liste mit Dateien zu lesen. Mit nur einer Datenfluss-Aktivitätsausführung können Ihre gesamten Dateien als Batch verarbeitet werden. Weitere Informationen zum Konfigurieren dieser Einstellungen finden Sie in der Dokumentation zum Azure Blob Storage-Connector im Abschnitt Quellentransformation.
Vermeiden Sie nach Möglichkeit die Verwendung der For-Each-Aktivität, um Datenflüsse für mehrere Dateien auszuführen. Dies führt dazu, dass bei jeder Iteration des For-Each-Vorgangs ein eigener Spark-Cluster gestartet wird. Häufig ist dies nicht nötig, und diese Vorgehensweise kann teuer werden.
Inline-Datasets im Vergleich zu freigegebenen Datasets
ADF- und Synapse-Datasets sind freigegebene Ressourcen in Ihren Werken und Arbeitsbereichen. Wenn Sie jedoch eine große Anzahl von Quellordnern und -dateien mit durch Trennzeichen getrenntem Text und JSON-Quellen lesen, können Sie die Leistung der Erkennung von Datenflussdateien verbessern, indem Sie die Option „Vom Benutzer projiziertes Schema“ im Dialogfeld „Optionen – Projektion | Schema“ aktivieren. Diese Option deaktiviert die standardmäßige automatische Schemaerkennung von ADF und verbessert die Leistung der Dateierkennung erheblich. Bevor Sie diese Option festlegen, müssen Sie die Projektion importieren, damit ADF über ein vorhandenes Schema für die Projektion verfügt. Diese Option funktioniert nicht mit Schemaabweichung.
Zugehöriger Inhalt
- Übersicht über die Datenflussleistung
- Optimieren von Senken
- Optimieren von Transformationen
- Verwenden von Datenflüssen in Pipelines
Lesen Sie die folgenden Artikel zu Datenflüssen in Bezug auf die Leistung: