Erstellen von Ausdrücken im Zuordnungsdatenfluss
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Im Zuordnungsdatenfluss werden viele Transformationseigenschaften als Ausdrücke eingegeben. Diese Ausdrücke bestehen aus Spaltenwerten, Parametern, Funktionen, Operatoren und Literalen, die zur Laufzeit zu einem Spark-Datentyp ausgewertet werden. Die Zuordnung von Datenflüssen verfügt über eine dedizierte Funktion, die Sie bei der Erstellung dieser Ausdrücke unterstützen soll, den so genannten Ausdrucks-Generator. Der Ausdrucks-Generator nutzt die IntelliSense-Codevervollständigung für Hervorhebung, Syntaxüberprüfung und automatische Vervollständigung und soll Ihnen das Erstellen von Datenflüssen erleichtern. In diesem Artikel wird erläutert, wie Sie den Ausdrucks-Generator verwenden, um Ihre Geschäftslogik effektiv zu erstellen.
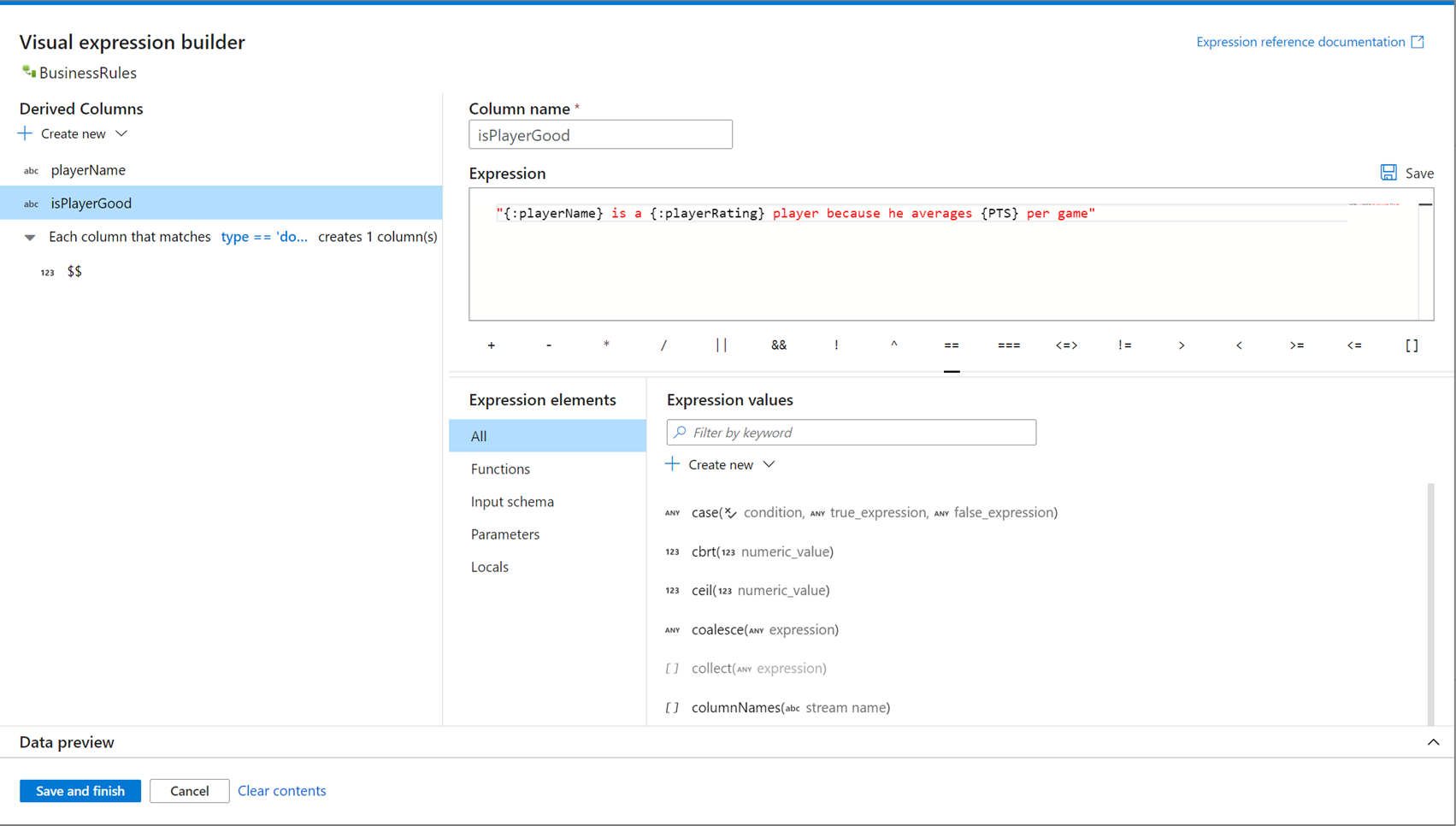
Öffnen des Ausdrucks-Generators
Der Ausdrucks-Generator kann auf verschiedene Weise geöffnet werden. Diese hängen jeweils vom Kontext der Datenflusstransformation ab. Der häufigste Anwendungsfall ist eine Transformation wie eine abgeleitete Spalte und ein Aggregat, bei denen Benutzer Spalten mithilfe der Ausdruckssprache für Datenflüsse erstellen oder aktualisieren. Sie können den Ausdrucks-Generator öffnen, indem Sie über der Spaltenliste Ausdrucks-Generator öffnen auswählen. Sie können auch auf einen Spaltenkontext klicken und den Ausdrucks-Generator direkt für diesen Ausdruck öffnen.
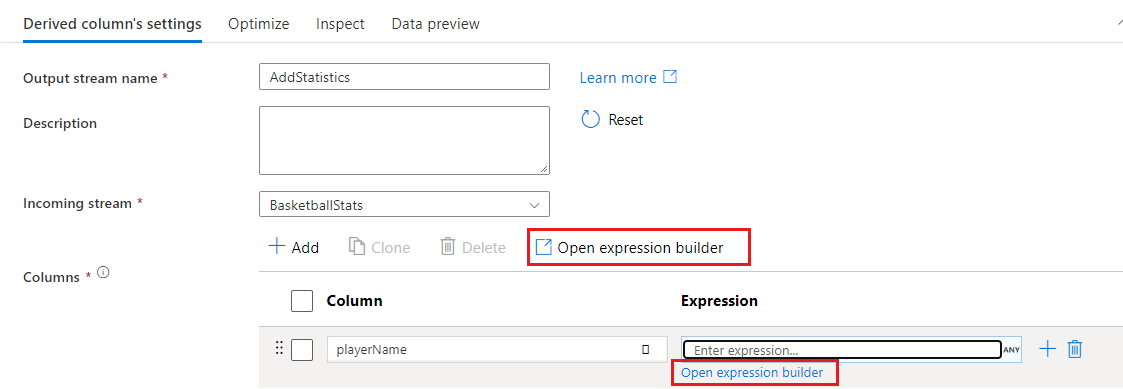
Bei einigen Transformationen wie Filtern wird der Ausdrucks-Generator durch Klicken auf ein blaues Ausdruckstextfeld geöffnet.
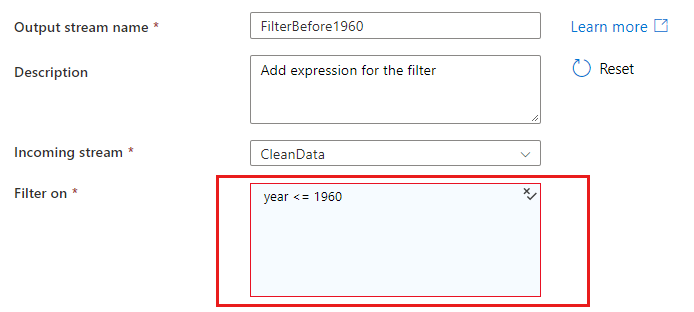
Wenn Sie in einer Übereinstimmungs- oder Gruppieren nach-Bedingung auf Spalten verweisen, kann ein Ausdruck Werte aus Spalten extrahieren. Wählen Sie zum Erstellen eines Ausdrucks die Option Berechnete Spalte aus.

In Fällen, in denen ein Ausdruck oder ein Literalwert gültige Eingaben sind, können Sie mit Dynamischen Inhalt hinzufügen einen Ausdruck erstellen, der zu einem Literalwert ausgewertet wird.

Elemente eines Ausdrucks
Bei Zuordnungsdatenflüssen können Ausdrücke aus Spaltenwerten, Parametern, Funktionen, lokalen Variablen, Operatoren und Literalwerten bestehen. Diese Ausdrücke müssen als Spark-Datentyp wie Zeichenfolge, boolescher Wert oder ganze Zahl ausgewertet werden können.
Functions
Zuordnungsdatenflüsse verfügen über integrierte Funktionen und Operatoren, die in Ausdrücken verwendet werden können. Eine Liste der verfügbaren Funktionen finden Sie in der Sprachreferenz zu Zuordnungsdatenflüssen.
Benutzerdefinierte Funktionen (Vorschau)
Zuordnungsdatenflüsse unterstützen die Erstellung und Verwendung von benutzerdefinierten Funktionen. Informationen zum Erstellen und Verwenden von benutzerdefinierten Funktionen finden Sie unter Benutzerdefinierte Funktionen (Vorschau) im Zuordnungsdatenfluss.
Angeben von Arrayindizes
Verwenden Sie bei Spalten oder Funktionen, die Arraytypen zurückgeben, eckige Klammern ([]), um auf ein bestimmtes Element zuzugreifen. Wenn der Index nicht vorhanden ist, wird der Ausdruck als NULL ausgewertet.
Wichtig
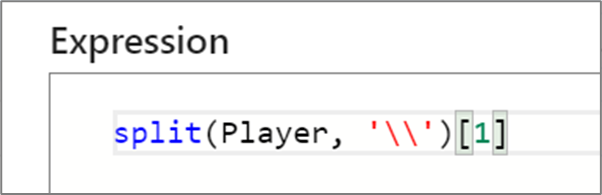
Bei der Zuordnung von Datenflüssen haben Arrays die Basis 1, d. h., das erste Element hat den Index 1. Beispielsweise greifen Sie mit myArray[1] auf das erste Element eines Arrays mit dem Namen „myArray“ zu.
Eingabeschema
Wenn der Datenfluss in einer seiner Quellen ein definiertes Schema verwendet, können Sie in vielen Ausdrücken anhand des Namens auf eine Spalte verweisen. Wenn Sie die Schemaabweichung verwenden, können Sie mit den Funktionen byName() oder byNames() explizit auf Spalten verweisen oder mithilfe von Spaltenmustern Übereinstimmungen auswählen.
Spaltennamen mit Sonderzeichen
Wenn Sie Spaltennamen mit Sonder- oder Leerzeichen haben, setzen Sie den Namen in geschweifte Klammern, um darauf in einem Ausdruck zu verweisen.
{[dbo].this_is my complex name$$$}
Parameter
Parameter sind Werte, die von einer Pipeline zur Laufzeit an einen Datenfluss übergeben werden. Um auf einen Parameter zu verweisen, klicken Sie entweder in der Ansicht Ausdruckselemente auf den Parameter, oder verweisen Sie darauf mit einem Dollarzeichen vor seinem Namen. Beispielsweise wird mit $parameter1 auf einen Parameter mit dem Namen „parameter1“ verwiesen. Weitere Informationen finden Sie unter Parametrisieren von Zuordnungsdatenflüssen.
Zwischengespeicherte Suche
Eine zwischengespeicherte Suche ermöglicht die Inlinesuche der Ausgabe einer zwischengespeicherten Senke. Für jede Senke stehen zwei Funktionen zur Verfügung: lookup() und outputs(). Die Syntax zum Verweisen auf diese Funktionen lautet cacheSinkName#functionName(). Weitere Informationen finden Sie unter Cachesenken.
lookup() akzeptiert die übereinstimmenden Spalten in der aktuellen Transformation als Parameter und gibt eine komplexe Spalte zurück. Diese entspricht der Zeile mit den übereinstimmenden Schlüsselspalten in der Cachesenke. Die zurückgegebene komplexe Spalte enthält eine untergeordnete Spalte für jede zugeordnete Spalte in der Cachesenke. Ein Beispiel: Sie verfügen über eine Fehlercode-Cachesenke errorCodeCache, die eine Schlüsselspalte mit Codeübereinstimmung und eine Spalte namens Message aufweist. Ein Aufruf von errorCodeCache#lookup(errorCode).Message würde die Meldung zurückgeben, die dem übergebenen Code entspricht.
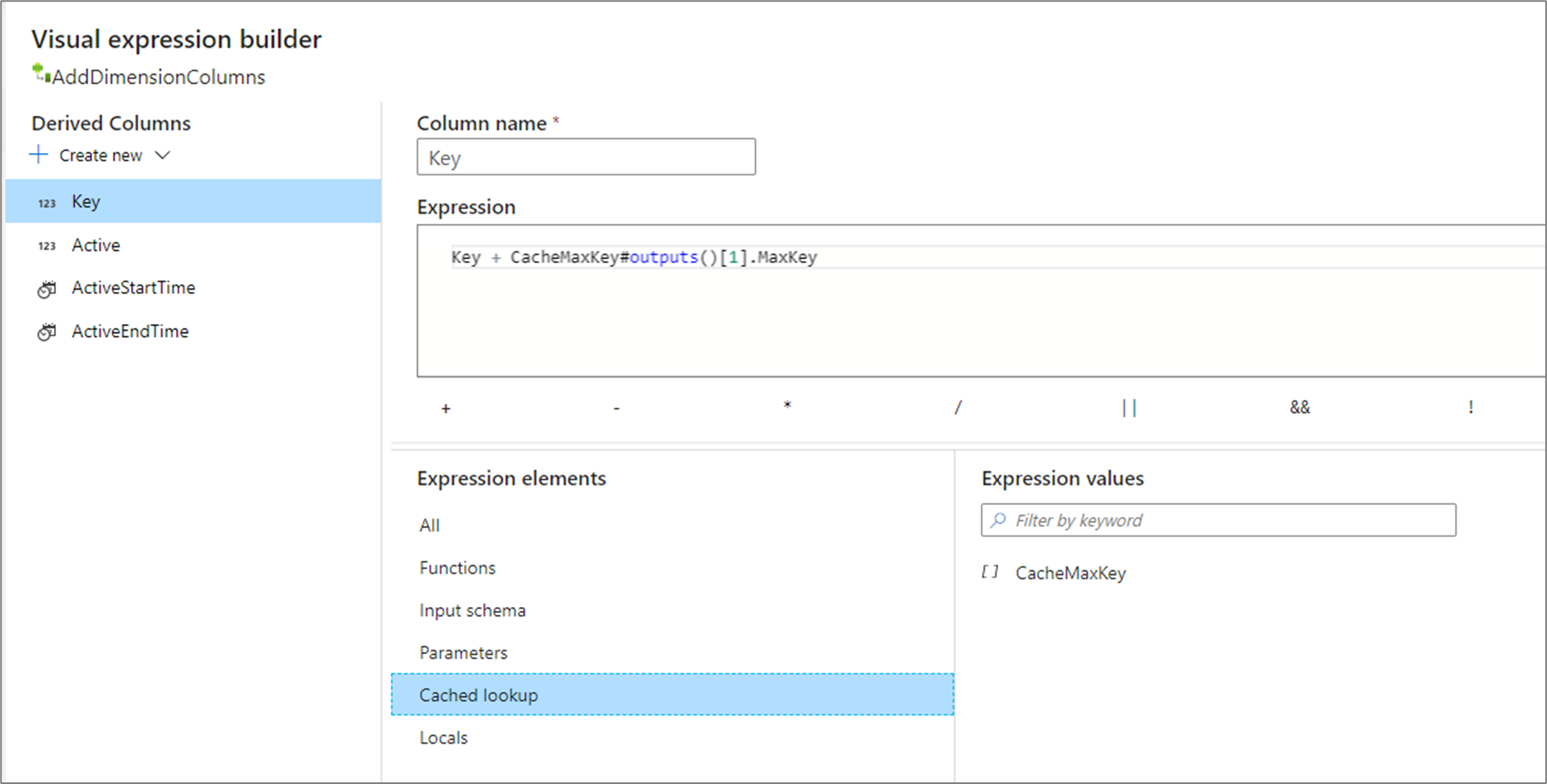
outputs() akzeptiert keine Parameter und gibt die gesamte Cachesenke als Array komplexer Spalten zurück. Ein Aufruf ist nicht möglich, wenn Schlüsselspalten in der Senke angegeben sind. Dieser Vorgang sollte nur dann verwendet werden, wenn die Cachesenke nur einige wenige Zeilen enthält. Ein gängiger Anwendungsfall ist das Anfügen des Maximalwerts eines Schlüssels, der inkrementell erhöht wird. Wenn die zwischengespeicherte aggregierte Einzelzeile CacheMaxKey die Spalte MaxKey enthält, können Sie durch Aufruf von CacheMaxKey#outputs()[1].MaxKey auf den ersten Wert verweisen.
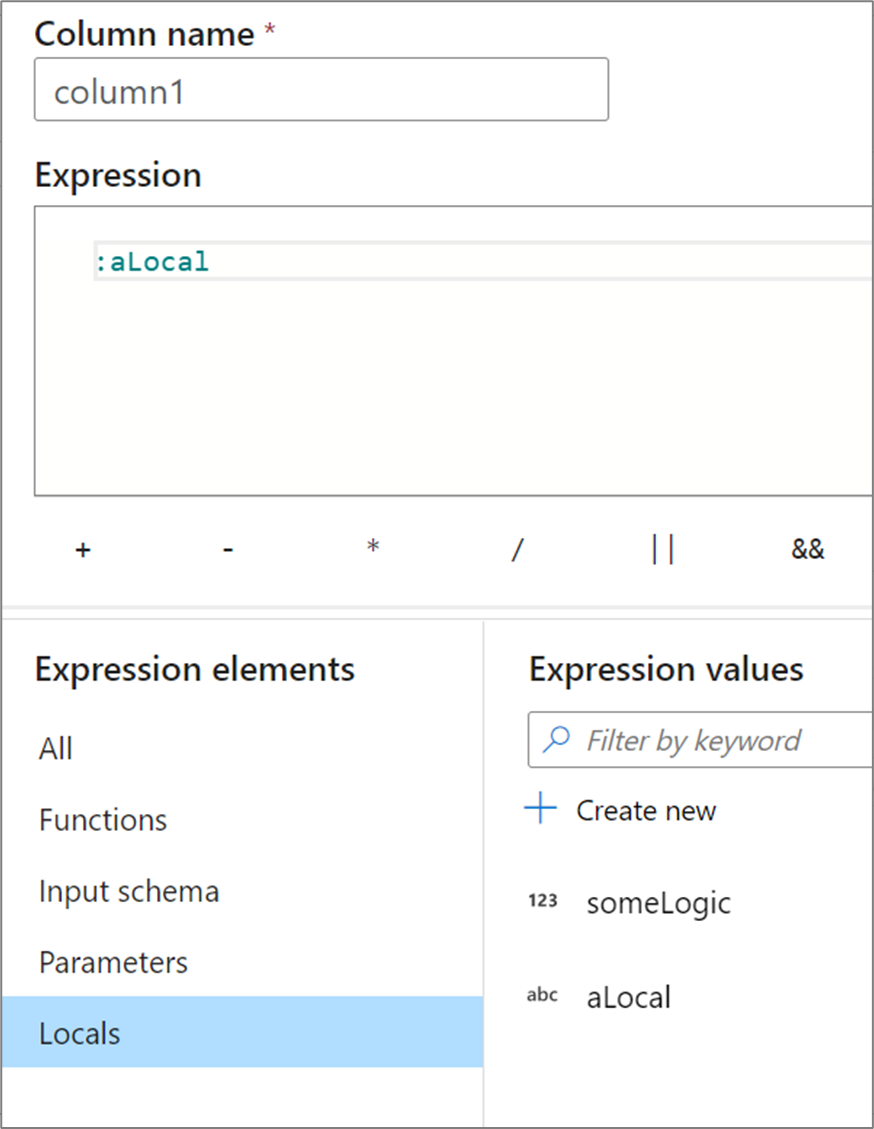
Locals
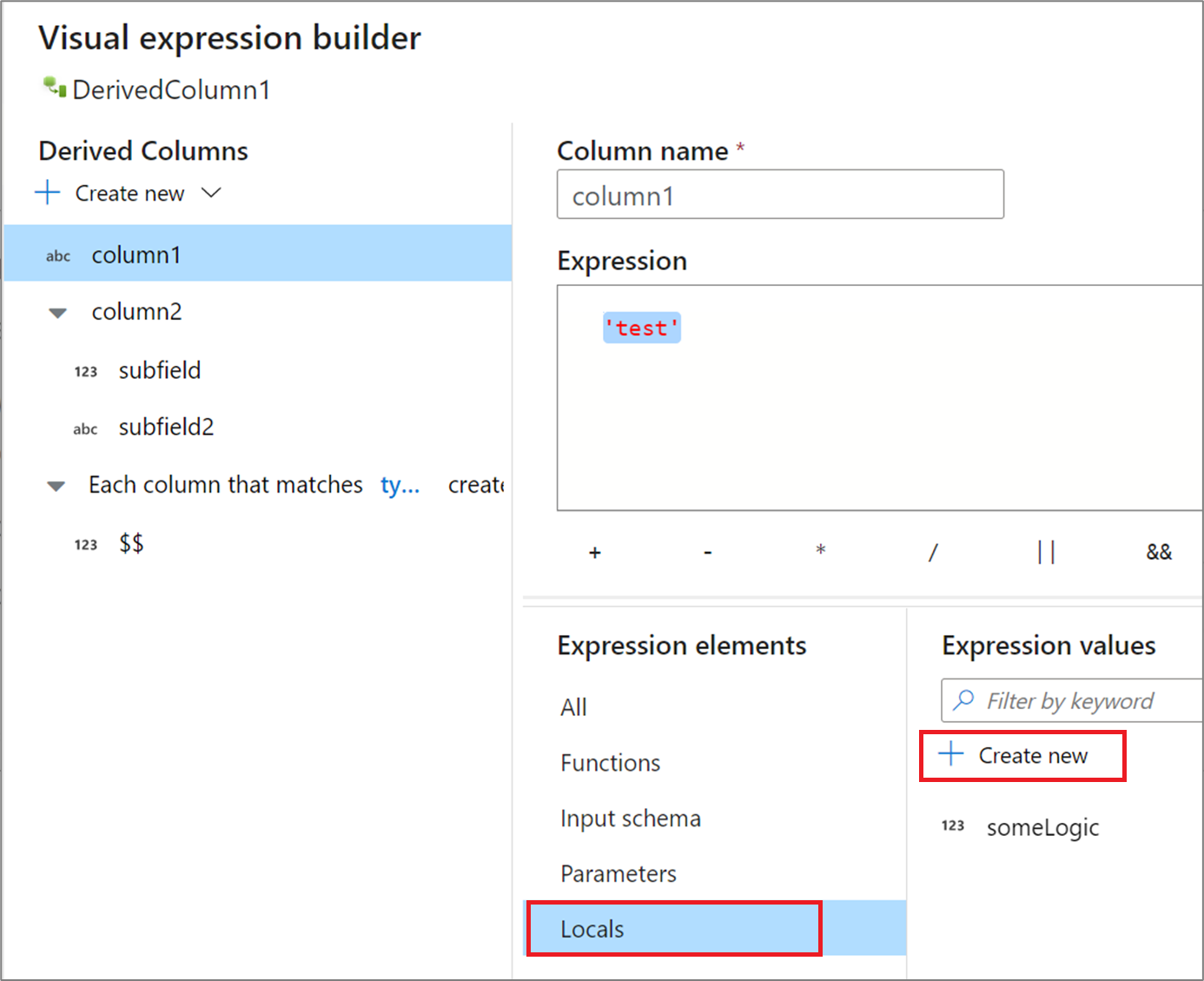
Wenn Sie Ihre Logik für mehrere Spalten gemeinsam nutzen oder aufteilen möchten, können Sie eine lokale Variable erstellen. Dabei handelt es sich um einen Satz von Logik, der nicht in die folgende Transformation weitergeleitet wird. Lokale Variablen können im Ausdrucks-Generator erstellt werden, indem Sie zu Ausdruckselemente wechseln und Lokale auswählen. Erstellen Sie eine neue Lokale, indem Sie Neu erstellen auswählen.
Lokale Variablen können auf ein beliebiges Ausdruckselement verweisen. Dies schließt Funktionen, Eingabeschemas, Parameter und andere lokale Variablen ein. Wenn auf andere lokale Variablen verwiesen wird, ist die Reihenfolge wichtig, weil sich die referenzierte lokale Variable „über“ der aktuellen befinden muss.
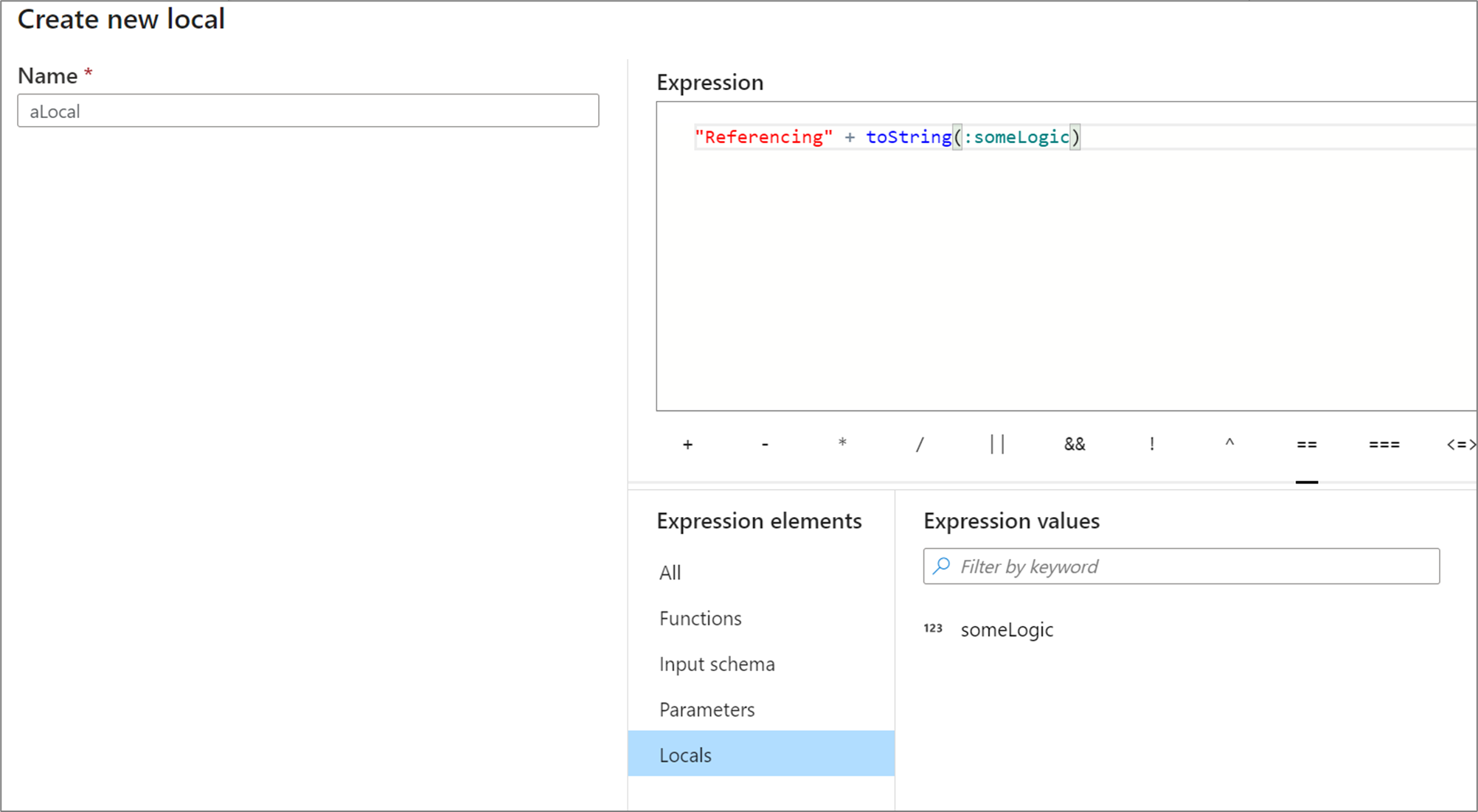
Wenn Sie auf eine lokale Variable in einer Transformation verweisen möchten, klicken Sie entweder in der Ansicht Ausdruckselemente auf die lokale Variable, oder verweisen Sie mit einem Doppelpunkt vor ihrem Namen darauf. Beispielsweise wird auf eine lokale Variable mit dem Namen „local1“ durch :local1 verwiesen. Um eine lokale Definition zu bearbeiten, zeigen Sie in der Ansicht „Ausdruckselemente“ mit der Maus darauf, und klicken Sie auf das Stiftsymbol.
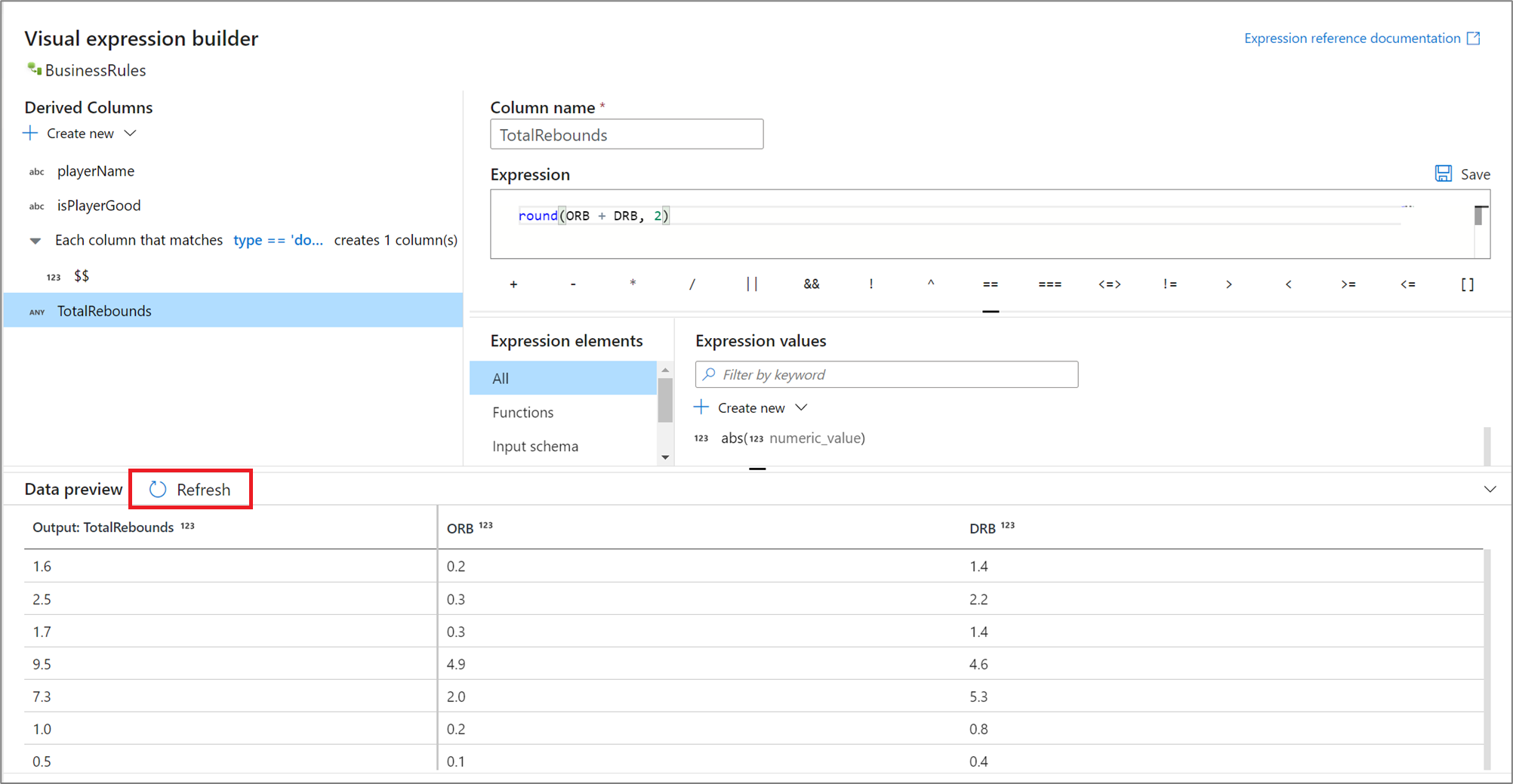
Vorschau von Ausdrucksergebnissen
Wenn debug mode aktiviert ist, können Sie mithilfe des Debugclusters interaktiv eine Vorschau des Werts anzeigen, den der Ausdruck ergibt. Wählen Sie neben der Datenvorschau Aktualisieren aus, um die Ergebnisse der Datenvorschau zu aktualisieren. Es wird die Ausgabe für jede Zeile entsprechend den Eingabespalten angezeigt.
Zeichenfolgeninterpolierung
Wenn Sie lange Zeichenfolgen erstellen, die Ausdruckselemente verwenden, verwenden Sie die Zeichenfolgeninterpolation, um problemlos eine komplexe Zeichenfolgenlogik zu erstellen. Durch die Zeichenfolgeninterpolation wird eine übermäßige Verkettung von Zeichenfolgen vermieden, wenn Parameter in Abfragezeichenfolgen einbezogen werden. Verwenden Sie doppelte Anführungszeichen, um Literalzeichenfolgen in Ausdrücke einzuschließen. Sie können Ausdrucksfunktionen, Spalten und Parameter einbeziehen. Wenn Sie eine Ausdruckssyntax verwenden möchten, schließen Sie sie in geschweifte Klammern ein.
Einige Beispiele für Zeichenfolgeninterpolation:
"My favorite movie is {iif(instr(title,', The')>0,"The {split(title,', The')[1]}",title)}""select * from {$tablename} where orderyear > {$year}""Total cost with sales tax is {round(totalcost * 1.08,2)}""{:playerName} is a {:playerRating} player"
Hinweis
Bei Verwendung der Syntax für Zeichenfolgeninterpolation in SQL-Quellabfragen muss die Abfragezeichenfolge in einer einzigen Zeile (ohne ‚/n‘) stehen.
Kommentieren von Ausdrücken
Fügen Sie Ihren Ausdrücken Kommentare hinzu. Verwenden Sie dabei eine einzeilige oder eine mehrzeilige Kommentarsyntax.
Die folgenden Beispiele stellen gültige Kommentare dar:
/* This is my comment *//* This is amulti-line comment */
Wenn Sie einen Kommentar am Anfang des Ausdrucks einfügen, wird er im Transformationstextfeld angezeigt und dokumentiert Ihre Transformationsausdrücke.

Reguläre Ausdrücke
Viele Ausdruckssprachfunktionen verwenden die reguläre Ausdruckssyntax. Wenn Sie Funktionen mit regulären Ausdrücken verwenden, versucht der Ausdrucks-Generator, den umgekehrten Schrägstrich (\) als Escapezeichensequenz zu interpretieren. Wenn Sie in Ihrem regulären Ausdruck umgekehrte Schrägstriche verwenden, schließen Sie entweder den gesamten regulären Ausdruck in Backticks (`) ein, oder verwenden Sie einen doppelten umgekehrten Schrägstrich.
Ein Beispiel mit Backticks:
regex_replace('100 and 200', `(\d+)`, 'digits')
Ein Beispiel mit doppelten umgekehrten Schrägstrichen:
regex_replace('100 and 200', '(\\d+)', 'digits')
Tastenkombinationen
Im Folgenden finden Sie eine Liste der Tastenkombination, die im Ausdrucks-Generator unterstützt werden. Beim Erstellen von Ausdrücken sind die meisten IntelliSense-Tastenkombinationen verfügbar.
- STRG+K, STRG+C: Gesamte Zeile auskommentieren
- STRG+K, STRG+U: Auskommentierung aufheben
- F1: Befehle der Editor-Hilfe anzeigen
- ALT+NACH-UNTEN-TASTE: Aktuelle Zeile nach unten verschieben
- ALT+NACH-OBEN-TASTE: Aktuelle Zeile nach oben verschieben
- STRG+LEERTASTE: Kontexthilfe anzeigen
Häufig verwendete Ausdrücke
Konvertieren in Datumsangaben oder Zeitstempel
Wenn Sie Zeichenfolgenliterale in Ihre Zeitstempelausgabe einbeziehen möchten, schließen Sie die Konvertierung in toString() ein.
toString(toTimestamp('12/31/2016T00:12:00', 'MM/dd/yyyy\'T\'HH:mm:ss'), 'MM/dd /yyyy\'T\'HH:mm:ss')
Wenn Sie Millisekunden von einer Epoche in ein Datum oder einen Zeitstempel konvertieren möchten, verwenden Sie toTimestamp(<number of milliseconds>). Wenn die Zeit in Sekunden angezeigt wird, multiplizieren Sie den Wert mit 1.000.
toTimestamp(1574127407*1000l)
Das nachgestellte „l“ am Ende des vorstehenden Ausdrucks gibt eine Konvertierung in einen long-Datentyp als inline-Syntax an.
Zeit aus Epochen- oder Unix-Zeit finden
toLong( currentTimestamp() - toTimestamp('1970-01-01 00:00:00.000', 'yyyy-MM-dd HH:mm:ss.SSS') ) * 1000l
Auswertung der Datenflusszeit
Der Datenfluss wird millisekundengenau verarbeitet. Für 2018-07-31T20:00:00.2170000 wird in der Ausgabe 2018-07-31T20:00:00.217 angezeigt. Im Portal für den Dienst wird der Zeitstempel in der aktuellen Browsereinstellung angezeigt. Dadurch wird „217“ unter Umständen entfernt. Wenn Sie den Datenfluss jedoch vollständig ausführen, wird „217“ (der Teil im Millisekundenbereich) ebenfalls verarbeitet. Sie können „toString(myDateTimeColumn)“ als Ausdruck verwenden und Daten mit vollständiger Genauigkeit in der Vorschau anzeigen. Verarbeiten Sie datetime für alle praktischen Zwecke als datetime und nicht als Zeichenfolge.
Zugehöriger Inhalt
Mit dem Erstellen von Datentransformationsausdrücken beginnen.