Verwenden des Hive-Metastores mit Apache Spark-Cluster™
Wichtig
Azure HDInsight auf AKS wurde am 31. Januar 2025 eingestellt. Erfahren Sie mehr mit dieser Ankündigung.
Sie müssen Ihre Workloads zu Microsoft Fabric oder ein gleichwertiges Azure-Produkt migrieren, um eine abrupte Beendigung Ihrer Workloads zu vermeiden.
Wichtig
Dieses Feature befindet sich derzeit in der Vorschau. Die zusätzlichen Nutzungsbedingungen für Microsoft Azure Previews weitere rechtliche Bestimmungen enthalten, die für Azure-Features gelten, die in der Betaversion, in der Vorschau oder auf andere Weise noch nicht in die allgemeine Verfügbarkeit veröffentlicht werden. Informationen zu dieser spezifischen Vorschau finden Sie unter Azure HDInsight auf AKS-Vorschauinformationen. Für Fragen oder Vorschläge zu Funktionen senden Sie bitte eine Anfrage mit den Details an AskHDInsight und folgen Sie uns für weitere Updates zur Azure HDInsight Community.
Es ist wichtig, die Daten und den Metaspeicher über mehrere Dienste hinweg zu teilen. Einer der häufig verwendeten Metaspeicher im HIVE-Metaspeicher. HDInsight auf AKS ermöglicht Es Benutzern, eine Verbindung mit einem externen Metastore herzustellen. Dieser Schritt ermöglicht es den HDInsight-Benutzern, sich nahtlos mit anderen Diensten im Ökosystem zu verbinden.
Azure HDInsight auf AKS unterstützt benutzerdefinierte Metaspeicher, die für Produktionscluster empfohlen werden. Die wichtigsten Schritte sind
- Erstellen einer Azure SQL-Datenbank
- Einen Schlüsseltresor zum Speichern der Anmeldeinformationen erstellen
- Konfigurieren des Metastores beim Erstellen eines HDInsight auf AKS-Cluster mit Apache Spark™
- Verwenden Sie den externen Metastore (Zeigt Datenbanken an und führen Sie einen Auswahlgrenzwert von 1 aus).
Während Sie den Cluster erstellen, muss der HDInsight-Dienst eine Verbindung mit dem externen Metastore herstellen und Ihre Anmeldeinformationen überprüfen.
Erstellen einer Azure SQL-Datenbank
Erstellen oder verfügen Sie über eine vorhandene Azure SQL-Datenbank, bevor Sie einen benutzerdefinierten Hive-Metaspeicher für einen HDInsight-Cluster einrichten.
Anmerkung
Derzeit unterstützen wir nur azure SQL-Datenbank für HIVE-Metaspeicher. Aufgrund der Hive-Einschränkung wird das Zeichen "-" (Bindestrich) im Metastore-Datenbanknamen nicht unterstützt.
Erstellen Sie einen Schlüsseltresor zum Speichern der Anmeldeinformationen
Erstellen Sie einen Azure Key Vault.
Der Zweck des Key Vault besteht darin, Ihnen das SQL Server-Administratorkennwort zu speichern, das während der SQL-Datenbankerstellung festgelegt wurde. HDInsight auf der AKS-Plattform behandelt die Anmeldedaten nicht direkt. Daher ist es erforderlich, Ihre wichtigen Anmeldeinformationen in Azure Key Vault zu speichern. Erfahren Sie, wie Sie ein Azure Key Vaulterstellen.
Nach der Erstellung von Azure Key Vault die folgenden Rollen zuweisen
Objekt Rolle Bemerkungen Vom Benutzer zugewiesene verwaltete Identität(dieselbe UAMI, die vom HDInsight-Cluster verwendet wird) Key Vault Secrets-Benutzer Erfahren Sie, wie Sie UAMI Rolle zuweisen Benutzer(der ein Geheimnis in Azure Key Vault erstellt) Key Vault-Administrator Erfahren Sie, wie Sie die Rolle einem Benutzerzuweisen. Anmerkung
Ohne diese Rolle kann der Benutzer kein Geheimnis erstellen.
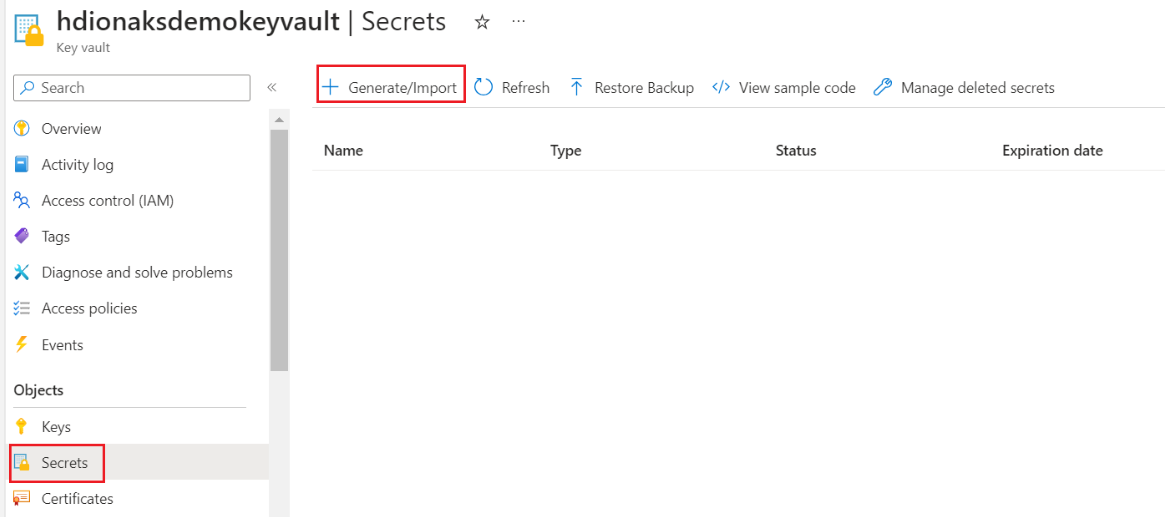
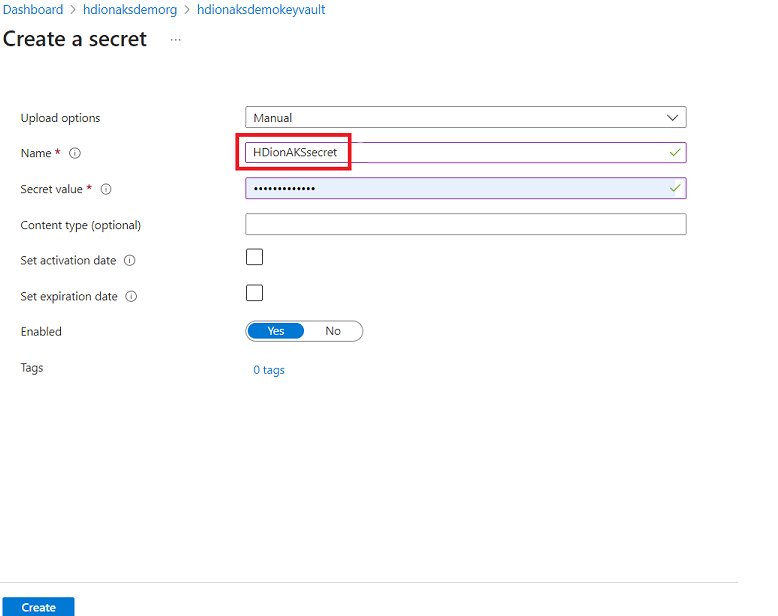
Ein geheimes erstellen
In diesem Schritt können Sie Ihr SQL Server-Administratorkennwort als geheimer Schlüssel im Azure Key Vault beibehalten. Fügen Sie Ihr Kennwort(dasselbe Kennwort wie im SQL DB für Administrator) im Feld "Wert" hinzu, während Sie einen geheimen Schlüssel hinzufügen.
Anmerkung
Achten Sie darauf, den geheimen Namen zu notieren, da Sie dies während der Clustererstellung benötigen.


Konfigurieren des Metastores beim Erstellen eines HDInsight Spark-Clusters
Navigieren Sie zu HDInsight im AKS-Clusterpool, um Cluster zu erstellen.

Aktivieren Sie den Schalter, um den externen Hive Metastore hinzuzufügen und die folgenden Details einzugeben.

Die restlichen Details sind gemäß den Clustererstellungsregeln für Apache Spark Cluster in HDInsight auf AKSauszufüllen.
Klicken Sie auf Überprüfen und Erstellen.
Anmerkung
- Der Lebenszyklus des Metastores ist nicht an einen Clusterlebenszyklus gebunden, sodass Sie Cluster erstellen und löschen können, ohne Metadaten zu verlieren. Metadaten wie Ihre Hive-Schemas bleiben auch nach dem Löschen und erneuten Erstellen des HDInsight-Clusters erhalten.
- Mit einem benutzerdefinierten Metaspeicher können Sie mehrere Cluster und Clustertypen an diesen Metaspeicher anfügen.



Arbeiten mit externem Metastore
Erstellen einer Tabelle
>> spark.sql("CREATE TABLE sampleTable (number Int, word String)")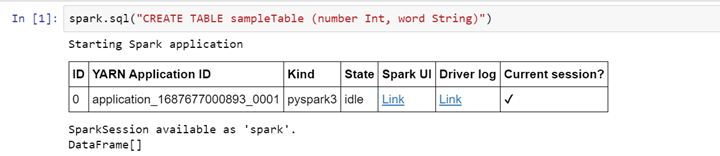
Hinzufügen von Daten zur Tabelle
>> spark.sql("INSERT INTO sampleTable VALUES (123, \"HDIonAKS\")");\
Lesen der Tabelle
>> spark.sql("select * from sampleTable").show()



Referenz
- Apache, Apache Spark, Spark und zugehörige Open Source-Projektnamen sind Marken der Apache Software Foundation (ASF).