Verwalten von Netzwerkrichtlinien für die Steuerung des serverlosen Ausgangs
Wichtig
Dieses Feature befindet sich in der Public Preview.
In diesem Dokument wird erläutert, wie Sie Netzwerkrichtlinien konfigurieren und verwalten, um ausgehende Netzwerkverbindungen von Ihren serverlosen Workloads in Azure Databricks zu steuern.
Berechtigungen für die Verwaltung von Netzwerkrichtlinien sind auf kontoadministratoren beschränkt. Siehe Einführung in die Azure Databricks-Verwaltung.
Zugreifen auf Netzwerkrichtlinien
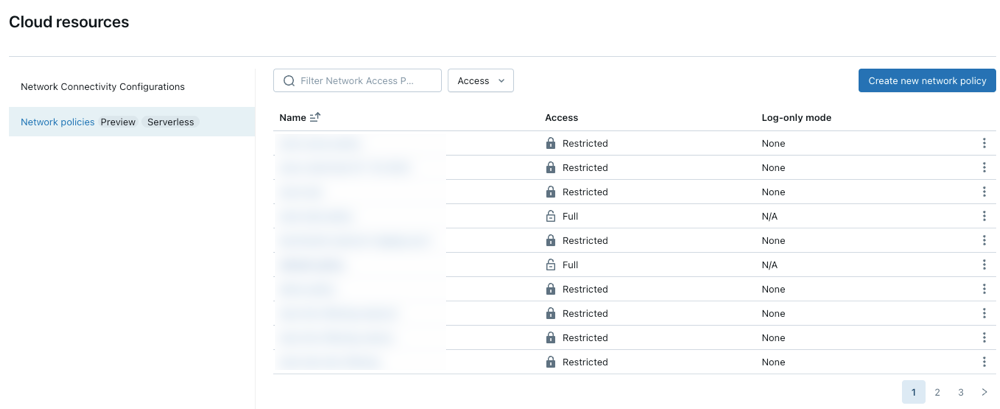
So erstellen, anzeigen und aktualisieren Sie Netzwerkrichtlinien in Ihrem Konto:
- Klicken Sie in der Kontokonsole auf Cloudressourcen.
- Klicken Sie auf die Registerkarte "Netzwerk ".
Erstellen einer neuen Netzwerkrichtlinie
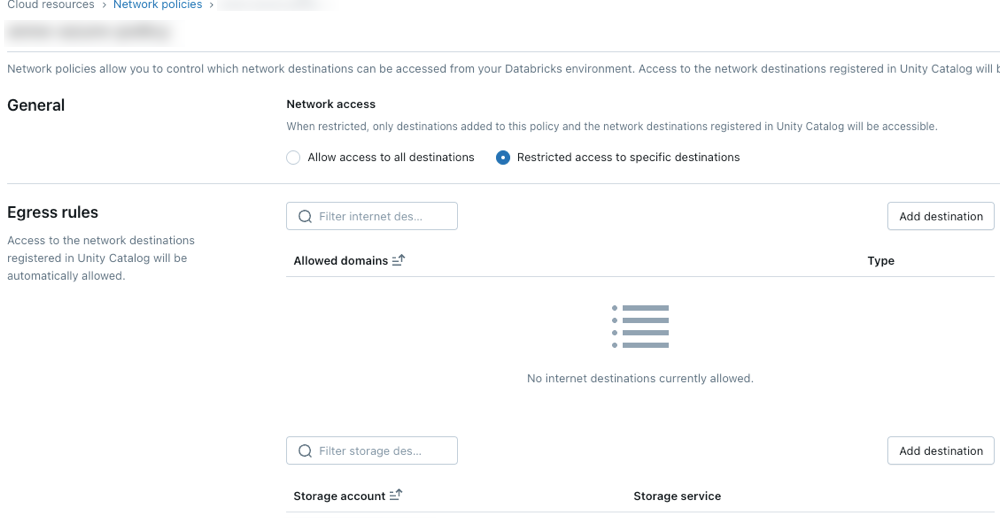
Klicken Sie auf Neue Netzwerkrichtlinieerstellen.
Wählen Sie einen Netzwerkzugriffsmodus aus:
- Vollzugriff: Uneingeschränkter ausgehender Internetzugriff. Wenn Sie "Vollzugriff" auswählen , bleibt der ausgehende Internetzugriff uneingeschränkt.
- Eingeschränkter Zugriff: Ausgehender Zugriff ist auf bestimmte Ziele beschränkt. Weitere Informationen finden Sie in der Übersicht über Netzwerkrichtlinien.
Konfigurieren von Netzwerkrichtlinien
In den folgenden Schritten werden optionale Einstellungen für den eingeschränkten Zugriffsmodus beschrieben.
Ausgangsregeln
Ziele, die über Unity Catalog-Speicherorte oder -Verbindungen konfiguriert sind, werden von der Richtlinie automatisch zugelassen.
Um serverlosem Computing Zugriff auf zusätzliche Domänen zu gewähren, klicken Sie über der Liste Zulässige Domänen auf Ziel hinzufügen.
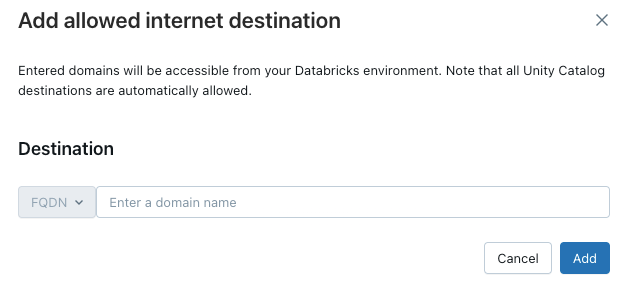
Der FQDN-Filter ermöglicht den Zugriff auf alle Domänen, die dieselbe IP-Adresse verwenden. Modellbereitstellungsendpunkte mit bereitgestelltem Durchsatz verhindern den Internetzugriff, wenn der Netzwerkzugriff auf „Eingeschränkt“ festgelegt ist. Die granulare Steuerung mit FQDN-Filterung wird jedoch nicht unterstützt.
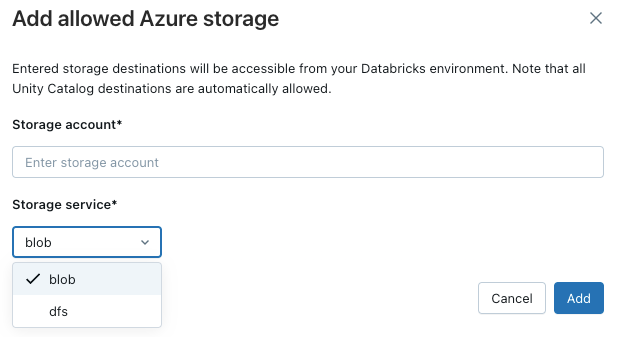
Um Ihrem Arbeitsbereich den Zugriff auf zusätzliche Azure-Speicherkonten zu ermöglichen, klicken Sie auf die Schaltfläche Ziel hinzufügen oberhalb der Liste Zulässigen Speicherkonten.
Hinweis
Die maximale Anzahl unterstützter Ziele beträgt 2000. Dazu gehören alle Unity Catalog-Speicherorte und -Verbindungen, auf die über den Arbeitsbereich zugegriffen werden kann, sowie Ziele, die explizit in der Richtlinie hinzugefügt werden.
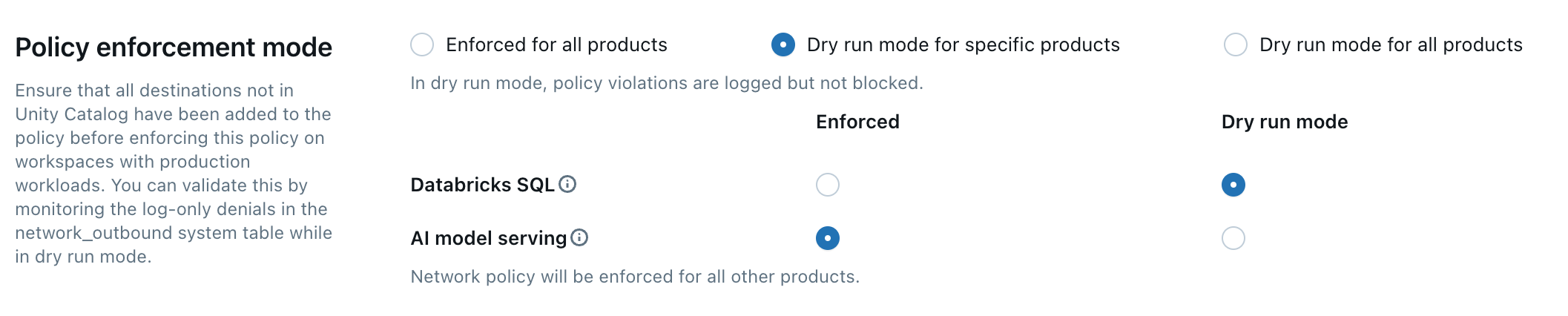
Durchsetzung von Richtlinien
Im Modus "Nur Protokoll" können Sie Die Richtlinienkonfiguration testen und ausgehende Verbindungen überwachen, ohne den Zugriff auf Ressourcen zu unterbrechen. Wenn der Trockenlaufmodus aktiviert ist, werden Anforderungen, die gegen die Richtlinie verstoßen, protokolliert, aber nicht blockiert. Sie können aus den folgenden Optionen auswählen:
Databricks SQL: Databricks SQL Warehouses arbeiten im Trockenlaufmodus.
KI-Modell, dasbedient: Das Modell, das Endpunkte bedient, wird im Trockenlaufmodus ausgeführt.
Alle Produkte: Alle Azure Databricks-Dienste arbeiten im Trockenlaufmodus, wobei alle anderen Auswahlen außer Kraft gesetzt werden.
Aktualisieren der Standardrichtlinie
Jedes Azure Databricks-Konto enthält eine Standardrichtlinie. Die Standardrichtlinie ist allen Arbeitsbereichen ohne explizite Netzwerkrichtlinienzuweisung zugeordnet, einschließlich neu erstellter Arbeitsbereiche. Sie können diese Richtlinie ändern, aber sie kann nicht gelöscht werden. Standardrichtlinien werden nur auf Arbeitsbereiche mit mindestens Premiumebene angewendet.
Zuordnen einer Netzwerkrichtlinie zu Arbeitsbereichen
Wenn Sie Ihre Standardrichtlinie mit zusätzlichen Konfigurationen aktualisiert haben, werden sie automatisch auf Arbeitsbereiche angewendet, die nicht über eine vorhandene Netzwerkrichtlinie verfügen. Ihr Arbeitsbereich muss sich in der Premium-Stufe befinden.
Gehen Sie wie folgt vor, um Ihren Arbeitsbereich einer anderen Richtlinie zuzuordnen:
- Wählen Sie einen Arbeitsbereich aus.
- Klicken Sie unter Netzwerkrichtlinie auf Netzwerkrichtlinie aktualisieren.
- Wählen Sie die gewünschte Netzwerkrichtlinie aus der Liste aus.
Anwenden von Netzwerkrichtlinienänderungen
Die meisten Netzwerkkonfigurationsupdates werden innerhalb von zehn Minuten automatisch an Ihre serverlose Berechnung verteilt. Dies umfasst:
- Hinzufügen eines neuen externen Unity-Katalogspeicherorts oder einer neuen Verbindung.
- Anfügen ihres Arbeitsbereichs an einen anderen Metaspeicher.
- Ändern der zulässigen Speicher- oder Internetziele.
Hinweis
Sie müssen die Berechnung neu starten, wenn Sie die Einstellung für den Internetzugriff oder den Trockenlaufmodus ändern.
Neustarten oder erneutes Bereitstellen von serverlosen Workloads
Sie müssen nur beim Wechseln des Internetzugriffsmodus oder beim Aktualisieren des Trockenlaufmodus aktualisieren.
Informationen zum Ermitteln des entsprechenden Neustartverfahrens finden Sie in der folgenden Liste nach Produkt:
- Databricks ML-Bereitstellung: Erneutes Bereitstellen Ihres ML-Bereitstellungsendpunkts. Weitere Informationen finden Sie unter Erstellen von benutzerdefinierten Modellbereitstellungsendpunkten.
- Delta-Livetabellen: Beenden Sie die Ausführung der Delta Live Tables-Pipeline, und starten Sie sie dann neu. Weitere Informationen finden Sie unter Ausführen eines Updates für eine Delta Live Tables-Pipeline.
- Serverless SQL Warehouse: Beenden und starten Sie das SQL-Lager neu. Siehe Verwalten eines SQL-Warehouses.
- Workflows: Netzwerkrichtlinienänderungen werden automatisch angewendet, wenn eine neue Auftragsausführung ausgelöst wird oder eine vorhandene Auftragsausführung neu gestartet wird.
- Notizbücher:
- Wenn Ihr Notizbuch nicht mit Spark interagiert, können Sie einen neuen serverlosen Cluster beenden und anfügen, um ihre Netzwerkkonfiguration zu aktualisieren, die auf Ihr Notizbuch angewendet wurde.
- Wenn Ihr Notizbuch mit Spark interagiert, wird die Serverlose Ressource aktualisiert und erkennt die Änderung automatisch. Das Wechseln des Zugriffsmodus und des Trockenlaufmodus kann bis zu 24 Stunden dauern, und es kann bis zu 10 Minuten dauern, bis andere Änderungen angewendet werden.
Überprüfen der Durchsetzung von Netzwerkrichtlinien
Sie können überprüfen, ob Ihre Netzwerkrichtlinie ordnungsgemäß erzwungen wird, indem Sie versuchen, auf eingeschränkte Ressourcen aus verschiedenen serverlosen Workloads zuzugreifen. Der Überprüfungsprozess variiert je nach serverlosem Produkt.
Überprüfen mit Delta Live-Tabellen
- Erstellen Sie ein Python-Notebook. Sie können das Beispielnotizbuch verwenden, das im Wikipedia-Python-Lernprogramm von Delta Live Tables bereitgestellt wird.
- Erstellen einer Delta Live Tables-Pipeline:
- Klicken Sie unter Datentechnik auf der Randleiste des Arbeitsbereichs auf Pipelines.
- Klicken Sie auf "Pipeline erstellen".
- Konfigurieren Sie die Pipeline mit den folgenden Einstellungen:
- Pipelinemodus: Serverless
- Quellcode: Wählen Sie das Notizbuch aus, das Sie erstellt haben.
- Speicheroptionen: Unity-Katalog. Wählen Sie Ihren gewünschten Katalog und Ihr gewünschtes Schema aus.
- Klicken Sie auf Erstellen.
- Führen Sie die Delta Live Tables-Pipeline aus.
- Klicken Sie auf der Pipelineseite auf "Start".
- Warten Sie, bis die Pipeline abgeschlossen ist.
- Überprüfen der Ergebnisse
- Vertrauenswürdiges Ziel: Die Pipeline sollte erfolgreich ausgeführt werden und Daten an das Ziel schreiben.
- Nicht vertrauenswürdiges Ziel: Fehler bei der Pipeline, die angeben, dass der Netzwerkzugriff blockiert ist.
Überprüfen mit Databricks SQL
- Erstellen Sie ein SQL Warehouse. Anweisungen finden Sie unter Erstellen eines SQL-Lagerlagers.
- Führen Sie eine Testabfrage im SQL-Editor aus, die versucht, auf eine Ressource zuzugreifen, die von Ihrer Netzwerkrichtlinie gesteuert wird.
- Überprüfen Sie die Ergebnisse:
- Vertrauenswürdiges Ziel: Die Abfrage sollte erfolgreich sein.
- Nicht vertrauenswürdiges Ziel: Die Abfrage sollte mit einem Netzwerkzugriffsfehler fehlschlagen.
Überprüfen mit Modellbereitstellung
Erstellen eines Testmodells
- Erstellen Sie in einem Python-Notizbuch ein Modell, das versucht, auf eine öffentliche Internetressource zuzugreifen, z. B. das Herunterladen einer Datei oder das Erstellen einer API-Anforderung.
- Führen Sie dieses Notizbuch aus, um ein Modell im Testarbeitsbereich zu generieren. Zum Beispiel:
import mlflow import mlflow.pyfunc import mlflow.sklearn import requests class DummyModel(mlflow.pyfunc.PythonModel): def load_context(self, context): pass def predict(self, _, model_input): first_row = model_input.iloc[0] try: response = requests.get(first_row['host']) except requests.exceptions.RequestException as e: # Return the error details as text return f"Error: An error occurred - {e}" return [response.status_code] with mlflow.start_run(run_name='internet-access-model'): wrappedModel = DummyModel() mlflow.pyfunc.log_model(artifact_path="internet_access_ml_model", python_model=wrappedModel, registered_model_name="internet-http-access")Erstellen eines Dienstendpunkts
- Wählen Sie in der Arbeitsbereichsnavigation machine Learning aus.
- Klicken Sie auf die Registerkarte "Portion ".
- Klicken Sie auf " Bereitstellungsendpunkt erstellen".
- Konfigurieren Sie den Endpunkt mit den folgenden Einstellungen:
- Dienstendpunktname: Geben Sie einen beschreibenden Namen an.
- Entitätsdetails: Modellregistrierungsmodell auswählen.
- Modell: Wählen Sie das Modell aus, das Sie im vorherigen Schritt erstellt haben.
- Klicken Sie auf Confirm (Bestätigen).
- Warten Sie, bis der Dienstendpunkt den Status "Bereit " erreicht.
Fragen Sie den Endpunkt ab.
- Verwenden Sie die Abfrageendpunktoption auf der Seite des bereitgestellten Endpunkts, um eine Testanforderung zu senden.
{"dataframe_records": [{"host": "https://www.google.com"}]}Überprüfen Sie das Ergebnis:
- Internetzugriff aktiviert: Die Abfrage sollte erfolgreich sein.
- Internetzugriff eingeschränkt: Die Abfrage sollte mit einem Netzwerkzugriffsfehler fehlschlagen.
Aktualisieren einer Netzwerkrichtlinie
Sie können eine Netzwerkrichtlinie jederzeit aktualisieren, nachdem sie erstellt wurde. So aktualisieren Sie eine Netzwerkrichtlinie:
- Ändern Sie auf der Detailseite der Netzwerkrichtlinie in Ihrer Kontokonsole die Richtlinie:
- Ändern Sie den Netzwerkzugriffsmodus.
- Aktivieren oder Deaktivieren des Trockenlaufmodus für bestimmte Dienste.
- Hinzufügen oder Entfernen von FQDN oder Speicherzielen.
- Klicke auf Aktualisieren.
- Weitere Informationen finden Sie unter Anwenden von Netzwerkrichtlinienänderungen, um zu überprüfen, ob die Updates auf vorhandene Workloads angewendet werden.
Überprüfen der Ablehnungsprotokolle
Die Ablehnungsprotokolle werden in der system.access.outbound_network Tabelle im Unity-Katalog gespeichert. Diese Protokolle verfolgen nach, wann ausgehende Netzwerkanforderungen verweigert werden. Um auf Denialprotokolle zuzugreifen, stellen Sie sicher, dass das Zugriffsschema im Unity-Katalog-Metastore aktiviert ist. Siehe Aktivieren von Systemtabellenschematas
Verwenden Sie eine SQL-Abfrage wie die folgende, um Denialereignisse anzuzeigen. Wenn Trockenlaufprotokolle aktiviert sind, gibt die Abfrage sowohl Denialprotokolle als auch Trockenlaufprotokolle zurück, die Sie mithilfe der spalte access_type unterscheiden können. Verweigerungsprotokolle weisen den Wert DROP auf, während für Probelaufprotokolle DRY_RUN_DENIAL angezeigt wird.
Im folgenden Beispiel werden Protokolle aus den letzten 2 Stunden abgerufen:
select * from system.access.outbound_network
where event_time >= current_timestamp() - interval 2 hour
sort by event_time desc
Ablehnungen werden nicht in der ausgehenden Netzwerksystemtabelle protokolliert, wenn eine Verbindung zu externen generativen KI-Modellen über das Mosaic AI-Gateway hergestellt wird. Weitere Informationen finden Sie unter Mosaic AI Gateway.
Hinweis
Es kann eine Latenz zwischen dem Zeitpunkt des Zugriffs und dem Auftreten der Verweigerungsprotokolle geben.
Einschränkungen
Konfiguration: Dieses Feature kann nur über die Kontokonsole konfiguriert werden. API-Unterstützung ist noch nicht verfügbar.
Artefakt-Uploadgröße: Bei Verwendung des internen Databricks Filesystems von MLflow mit dem
dbfs:/databricks/mlflow-tracking/<experiment_id>/<run_id>/artifacts/<artifactPath>Format sind Artefakteuploads auf 5 GB fürlog_artifact,log_artifactsundlog_modelAPIs beschränkt.Unterstützte Unity-Katalogverbindungen: Die folgenden Verbindungstypen werden unterstützt: MySQL, PostgreSQL, Snowflake, Redshift, Azure Synapse, SQL Server, Salesforce, BigQuery, Netsuite, Workday RaaS, Hive MetaStore und Salesforce Data Cloud.
Modellbereitstellung: Die Ausgangssteuerung gilt nicht beim Erstellen von Images für die Modellbereitstellung.
Azure Storage-Zugriff: Nur der Azure Blob Filesystem-Treiber für Azure Data Lake Storage wird unterstützt. Der Zugriff mithilfe des Azure Blob Storage-Treibers oder WASB-Treibers wird nicht unterstützt.