Erstellen von KI-Agents im Code
In diesem Artikel wird gezeigt, wie Sie einen KI-Agent im Code mithilfe von MLflow-ChatModelerstellen. Azure Databricks nutzt MLflow-ChatModel, um die Kompatibilität mit Databricks AI-Agent-Features wie Auswertung, Ablaufverfolgung und Bereitstellung sicherzustellen.
Was ist ChatModel?
ChatModel ist eine MLflow-Klasse, die die Erstellung von Unterhaltungs-KI-Agenten vereinfacht. Es stellt eine standardisierte Schnittstelle zum Erstellen von Modellen bereit, die mit ChatCompletion-APIvon OpenAI kompatibel sind.
ChatModel erweitert das ChatCompletion-Schema von OpenAI. Mit diesem Ansatz können Sie die umfassende Kompatibilität mit Plattformen beibehalten, die den ChatCompletion-Standard unterstützen, und gleichzeitig ihre eigenen benutzerdefinierten Funktionen hinzufügen.
Mithilfe von ChatModelkönnen Entwickler Agents erstellen, die mit Databricks- und MLflow-Tools für die Agentnachverfolgung, -auswertung und -lebenszyklusverwaltung kompatibel sind, die für die Bereitstellung produktionsfähiger Modelle unerlässlich sind.
Siehe MLflow: Erste Schritte mit ChatModel.
Anforderungen
Databricks empfiehlt die Installation der neuesten Version des MLflow Python-Clients bei der Entwicklung von Agents.
Um Agents mithilfe des Ansatzes in diesem Artikel zu erstellen und bereitzustellen, müssen Sie die folgenden Anforderungen erfüllen:
- Installieren
databricks-agentsVersion 0.15.0 und höher - Installieren
mlflowVersion 2.20.0 und höher
%pip install -U -qqqq databricks-agents>=0.15.0 mlflow>=2.20.0
Erstellen eines ChatModel-Agents
Sie können Ihren Agent als Unterklasse von mlflow.pyfunc.ChatModelerstellen. Diese Methode bietet die folgenden Vorteile:
- Ermöglicht Ihnen das Schreiben von Agentcode, der mit dem ChatCompletion-Schema mit typierten Python-Klassen kompatibel ist.
- Bei der Protokollierung des Agents leitet MLflow automatisch eine mit der Chatvervollständigung kompatible Signatur ab, auch ohne
input_example. Dies vereinfacht das Registrieren und Bereitstellen des Agents. Weitere Informationen finden Sie unter Ableiten der Modellsignatur während der Protokollierung.
Der folgende Code wird am besten in einem Databricks-Notizbuch ausgeführt. Notebooks bieten eine praktische Umgebung zum Entwickeln, Testen und Iterieren Ihres Agents.
Die MyAgent Klasse erweitert mlflow.pyfunc.ChatModel, wobei die erforderliche predict-Methode implementiert wird. Dadurch wird die Kompatibilität mit Dem Mosaik AI Agent Framework sichergestellt.
Die Klasse enthält auch die optionalen Methoden _create_chat_completion_chunk und predict_stream zum Behandeln von Streamingausgaben.
from dataclasses import dataclass
from typing import Optional, Dict, List, Generator
from mlflow.pyfunc import ChatModel
from mlflow.types.llm import (
# Non-streaming helper classes
ChatCompletionRequest,
ChatCompletionResponse,
ChatCompletionChunk,
ChatMessage,
ChatChoice,
ChatParams,
# Helper classes for streaming agent output
ChatChoiceDelta,
ChatChunkChoice,
)
class MyAgent(ChatModel):
"""
Defines a custom agent that processes ChatCompletionRequests
and returns ChatCompletionResponses.
"""
def predict(self, context, messages: list[ChatMessage], params: ChatParams) -> ChatCompletionResponse:
last_user_question_text = messages[-1].content
response_message = ChatMessage(
role="assistant",
content=(
f"I will always echo back your last question. Your last question was: {last_user_question_text}. "
)
)
return ChatCompletionResponse(
choices=[ChatChoice(message=response_message)]
)
def _create_chat_completion_chunk(self, content) -> ChatCompletionChunk:
"""Helper for constructing a ChatCompletionChunk instance for wrapping streaming agent output"""
return ChatCompletionChunk(
choices=[ChatChunkChoice(
delta=ChatChoiceDelta(
role="assistant",
content=content
)
)]
)
def predict_stream(
self, context, messages: List[ChatMessage], params: ChatParams
) -> Generator[ChatCompletionChunk, None, None]:
last_user_question_text = messages[-1].content
yield self._create_chat_completion_chunk(f"Echoing back your last question, word by word.")
for word in last_user_question_text.split(" "):
yield self._create_chat_completion_chunk(word)
agent = MyAgent()
model_input = ChatCompletionRequest(
messages=[ChatMessage(role="user", content="What is Databricks?")]
)
response = agent.predict(context=None, model_input=model_input)
print(response)
Während die Agentklasse MyAgent in einem Notizbuch definiert ist, sollten Sie ein separates Treibernotizbuch erstellen. Das Treibernotizbuch protokolliert den Agenten im Modellregister und stellt ihn mithilfe von Model Serving bereit.
Diese Trennung folgt dem von Databricks empfohlenen Workflow für die Protokollierung von Modellen mithilfe der Modelle-aus-Code-Methodik von MLflow.
Beispiel: LangChain in ChatModel umhüllen
Wenn Sie über ein vorhandenes LangChain-Modell verfügen und es in andere Mosaik AI-Agent-Features integrieren möchten, können Sie es in einen MLflow-ChatModel umschließen, um die Kompatibilität sicherzustellen.
In diesem Beispielcode werden die folgenden Schritte ausgeführt, um eine LangChain zu umschließen, die als ChatModel ausgeführt werden kann:
- Verpacken Sie die endgültige Ausgabe von LangChain mit
mlflow.langchain.output_parsers.ChatCompletionOutputParser, um eine Ausgabesignatur für den Chatabschluss zu erstellen. - Die
LangchainAgentKlasse erweitertmlflow.pyfunc.ChatModelund implementiert zwei Schlüsselmethoden:predict: Behandelt synchrone Vorhersagen, indem die Kette aufgerufen und eine formatierte Antwort zurückgegeben wird.predict_stream: Behandelt Streamingvorhersagen, indem die Kette aufgerufen wird und Antwortabschnitte geliefert werden.
from mlflow.langchain.output_parsers import ChatCompletionOutputParser
from mlflow.pyfunc import ChatModel
from typing import Optional, Dict, List, Generator
from mlflow.types.llm import (
ChatCompletionResponse,
ChatCompletionChunk
)
chain = (
<your chain here>
| ChatCompletionOutputParser()
)
class LangchainAgent(ChatModel):
def _prepare_messages(self, messages: List[ChatMessage]):
return {"messages": [m.to_dict() for m in messages]}
def predict(
self, context, messages: List[ChatMessage], params: ChatParams
) -> ChatCompletionResponse:
question = self._prepare_messages(messages)
response_message = self.chain.invoke(question)
return ChatCompletionResponse.from_dict(response_message)
def predict_stream(
self, context, messages: List[ChatMessage], params: ChatParams
) -> Generator[ChatCompletionChunk, None, None]:
question = self._prepare_messages(messages)
for chunk in chain.stream(question):
yield ChatCompletionChunk.from_dict(chunk)
Verwenden von Parametern zum Konfigurieren des Agents
Im Agent Framework können Sie Parameter verwenden, um zu steuern, wie Agents ausgeführt werden. Auf diese Weise können Sie schnell durch unterschiedliche Merkmale Ihres Agents iterieren, ohne den Code zu ändern. Parameter sind Schlüsselwertpaare, die Sie in einem Python-Wörterbuch oder einer .yaml Datei definieren.
Um den Code zu konfigurieren, erstellen Sie eine ModelConfig, eine Reihe von Schlüsselwertparametern. ModelConfig ist entweder ein Python-Wörterbuch oder eine .yaml Datei. Sie können z. B. während der Entwicklung ein Wörterbuch verwenden und dann in eine .yaml Datei für die Produktionsbereitstellung und CI/CD konvertieren. Ausführliche Informationen zu ModelConfigfinden Sie in der MLflow-Dokumentation.
Nachfolgend finden Sie ein Beispiel ModelConfig.
llm_parameters:
max_tokens: 500
temperature: 0.01
model_serving_endpoint: databricks-dbrx-instruct
vector_search_index: ml.docs.databricks_docs_index
prompt_template: 'You are a hello world bot. Respond with a reply to the user''s
question that indicates your prompt template came from a YAML file. Your response
must use the word "YAML" somewhere. User''s question: {question}'
prompt_template_input_vars:
- question
Verwenden Sie eine der folgenden Optionen, um die Konfiguration aus Ihrem Code aufzurufen:
# Example for loading from a .yml file
config_file = "configs/hello_world_config.yml"
model_config = mlflow.models.ModelConfig(development_config=config_file)
# Example of using a dictionary
config_dict = {
"prompt_template": "You are a hello world bot. Respond with a reply to the user's question that is fun and interesting to the user. User's question: {question}",
"prompt_template_input_vars": ["question"],
"model_serving_endpoint": "databricks-dbrx-instruct",
"llm_parameters": {"temperature": 0.01, "max_tokens": 500},
}
model_config = mlflow.models.ModelConfig(development_config=config_dict)
# Use model_config.get() to retrieve a parameter value
value = model_config.get('sample_param')
Retriever-Schema festlegen
KI-Agents verwenden häufig Retriever, einen Agent-Tooltyp, der relevante Dokumente mithilfe eines Vector Search-Index findet und zurückgibt. Weitere Informationen zu Abrufern finden Sie unter Tools für unstrukturiertes Abrufen des KI-Agents.
Um sicherzustellen, dass Retriever ordnungsgemäß nachverfolgt werden, rufen Sie mlflow.models.set_retriever_schema auf, wenn Sie Ihren Agent im Code definieren. Verwenden Sie set_retriever_schema, um die Spaltennamen in der zurückgegebenen Tabelle den erwarteten Feldern von MLflow wie primary_key, text_columnund doc_urizuzuordnen.
# Define the retriever's schema by providing your column names
# These strings should be read from a config dictionary
mlflow.models.set_retriever_schema(
name="vector_search",
primary_key="chunk_id",
text_column="text_column",
doc_uri="doc_uri"
# other_columns=["column1", "column2"],
)
Hinweis
Die doc_uri Spalte ist besonders wichtig beim Auswerten der Leistung des Retrievers. doc_uri ist der Hauptbezeichner für Dokumente, die vom Abrufer zurückgegeben werden. Damit können Sie sie mit Auswertungssätzen für die Grundwahrheit vergleichen. Weitere Informationen finden Sie unter Auswertungssätze.
Sie können auch zusätzliche Spalten im Schema des Retrievers angeben, indem Sie eine Liste der Spaltennamen mit dem feld other_columns angeben.
Wenn Sie über mehrere Retriever verfügen, können Sie mehrere Schemas definieren, indem Sie eindeutige Namen für jedes Retriever-Schema verwenden.
Benutzerdefinierte Eingaben und Ausgaben
Einige Szenarien erfordern möglicherweise zusätzliche Agents-Eingaben, z. B. client_type und session_id, oder Ausgaben wie Abrufquellenlinks, die nicht in den Chatverlauf für zukünftige Interaktionen einbezogen werden sollten.
Für diese Szenarien unterstützt MLflow ChatModel nativ die Erweiterung von OpenAI-Chatabschlussanforderungen und -antworten mittels der Felder ChatParams und custom_input sowie custom_output.
In den folgenden Beispielen erfahren Sie, wie Sie benutzerdefinierte Eingaben und Ausgaben für PyFunc- und LangGraph-Agents erstellen.
Warnung
Die Überprüfungs-App „Agent Evaluation“ bietet derzeit keine Unterstützung für das Rendern von Ablaufverfolgungen für Agents mit zusätzlichen Eingabefeldern.
benutzerdefinierte PyFunc-Schemata
Die folgenden Notizbücher zeigen ein benutzerdefiniertes Schemabeispiel mit PyFunc.
Benutzerdefiniertes PyFunc-Schema-Agent-Notizbuch
Benutzerdefiniertes PyFunc-Schematreibernotebook
Benutzerdefinierte LangGraph-Schemas
Die folgenden Notizbücher zeigen ein benutzerdefiniertes Schemabeispiel mit LangGraph. Sie können die wrap_output-Funktion in den Notizbüchern ändern, um Informationen aus dem Nachrichtendatenstrom zu analysieren und zu extrahieren.
Benutzerdefiniertes Schema-Agent-Notizbuch für LangGraph
Benutzerdefiniertes LangGraph-Schematreibernotebook
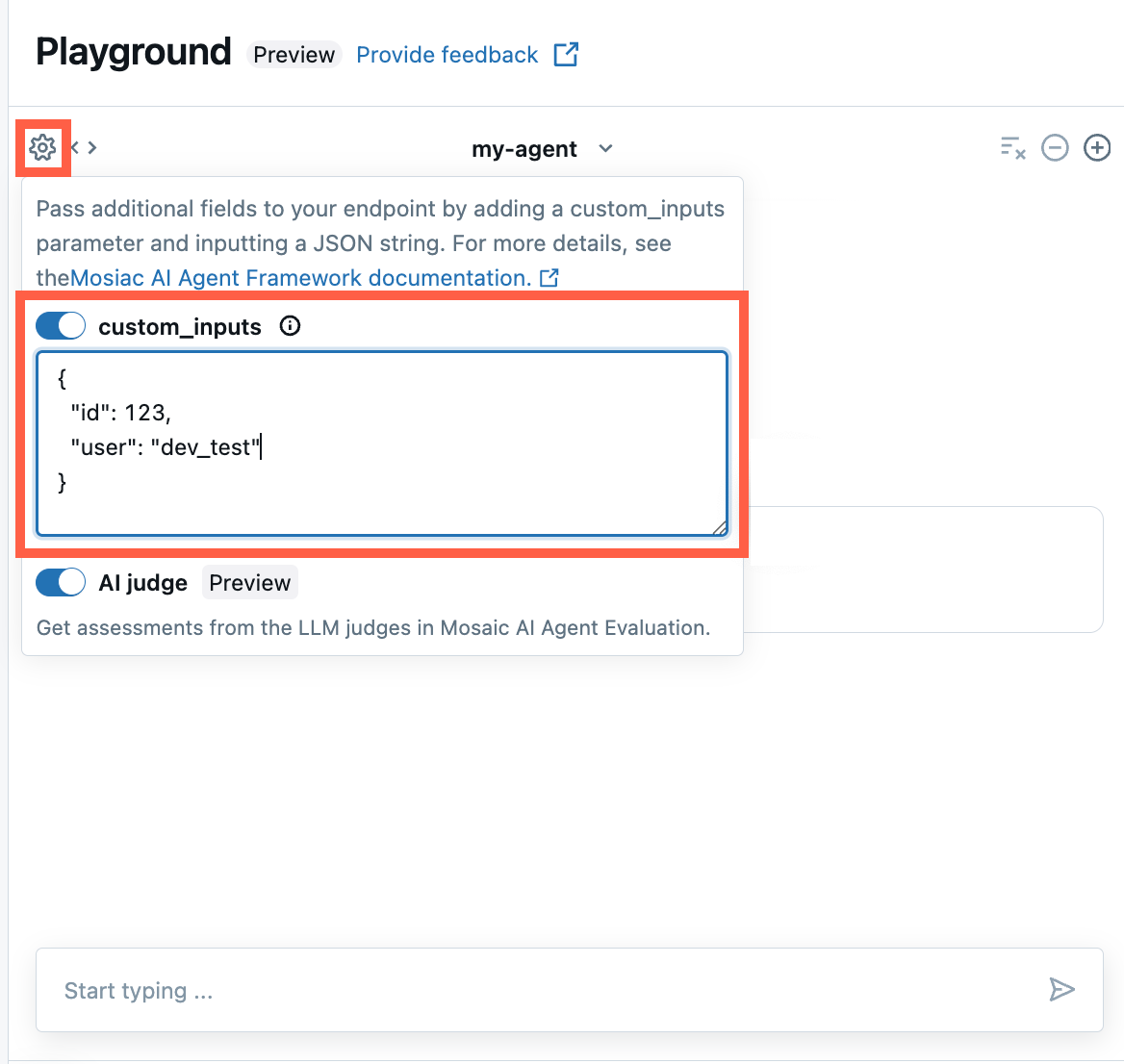
Bereitstellen von custom_inputs in der AI Playground- und Agent-Überprüfungs-App
Wenn Ihr Agent zusätzliche Eingaben mithilfe des Felds custom_inputs akzeptiert, können Sie diese Eingaben sowohl im AI Playground als auch in der Agent-Überprüfungs-Appmanuell bereitstellen.
Wählen Sie in der AI Playground- oder in der Agent Review-App das Zahnradsymbol
 aus.
aus.Aktivieren Sie custom_inputs.
Stellen Sie ein JSON-Objekt bereit, das dem definierten Eingabeschema Ihres Agents entspricht.
Streamingfehlerverteilung
Mosaic AI verteilt alle Fehler, die beim Streaming aufgetreten sind, mit dem letzten Token unter databricks_output.error. Es liegt bei dem aufrufenden Client, diesen Fehler ordnungsgemäß zu behandeln und anzuzeigen.
{
"delta": …,
"databricks_output": {
"trace": {...},
"error": {
"error_code": BAD_REQUEST,
"message": "TimeoutException: Tool XYZ failed to execute"
}
}
}
Beispiel-Notizbücher
Diese Notizbücher erstellen eine einfache "Hello, world"-Kette, um das Erstellen eines Agents in Databricks zu veranschaulichen. Im ersten Beispiel wird eine einfache Kette erstellt, und das zweite Beispielnotizbuch veranschaulicht, wie Sie Parameter verwenden, um Codeänderungen während der Entwicklung zu minimieren.