Zuweisen von Computeressourcen zu einer Gruppe
Wichtig
Dieses Feature befindet sich in der Public Preview.
In diesem Artikel wird erläutert, wie Sie eine Computeressource erstellen, die einer Gruppe mithilfe des zugriffsmodus Dedicated zugewiesen ist.
Der dedizierte Gruppenzugriffsmodus ermöglicht es Benutzern, die Betriebseffizienz eines Standardzugriffsmodusclusters zu erhalten und gleichzeitig sicher Sprachen und Workloads zu unterstützen, die nicht vom Standardzugriffsmodus unterstützt werden, wie z. B. Databricks Runtime für ML, Spark Machine Learning Library (MLlib), RDD-APIs und R.
Durch Aktivieren des dedizierten Gruppenclusters "Public Preview" hat Ihr Arbeitsbereich auch Zugriff auf die neue vereinfachte Compute-UI. Diese neue Benutzeroberfläche aktualisiert die Namen der Zugriffsmodi und vereinfacht die Berechnungseinstellungen. Weitere Informationen finden Sie unter Verwenden des einfachen Formulars zum Verwalten von Computeressourcen.
Anforderungen
So verwenden Sie den dedizierten Gruppenzugriffsmodus:
- Ein Arbeitsbereichsadmin muss die Preview Compute: Dedizierte Gruppencluster über die Benutzeroberfläche für Previews aktivieren. Weitere Informationen finden Sie unter Verwalten von Previews für Azure Databricks.
- Der Arbeitsbereich muss für den Unity-Katalog aktiviert sein.
- Sie müssen Databricks Runtime 15.4 oder höher verwenden.
- Die zugewiesene Gruppe muss über
CAN MANAGEBerechtigungen für einen Arbeitsbereichsordner verfügen, in dem Notizbücher, ML-Experimente und andere Arbeitsbereichsartefakte aufbewahrt werden können, die vom Gruppencluster verwendet werden.
Was ist der dedizierte Zugriffsmodus?
Der dedizierte Zugriffsmodus ist die neueste Version des Einzelbenutzerzugriffsmodus. Mit dediziertem Zugriff kann eine Computeressource einem einzelnen Benutzer oder einer einzelnen Gruppe zugewiesen werden, sodass der zugewiesene Benutzer nur Zugriff auf die Computeressource hat.
Wenn ein Benutzer mit einer Computeressource verbunden ist, die einer Gruppe (einem Gruppencluster) zugeordnet ist, werden die Berechtigungen des Benutzers automatisch auf die Berechtigungen der Gruppe herabgestrigen, sodass der Benutzer die Ressource sicher für die anderen Mitglieder der Gruppe freigeben kann.
Erstellen einer Computeressource, die einer Gruppe zugeordnet ist
- Wechseln Sie in Ihrem Azure Databricks-Arbeitsbereich zu Compute, und klicken Sie auf Compute erstellen.
- Erweitern Sie den Abschnitt Erweitert.
- Klicken Sie unter Access-Modusauf Manuell, und wählen Sie dann im Dropdownmenü Exklusiv (früher: Einzelbenutzer) aus.
- Wählen Sie im Feld einzelner Benutzer oder Gruppe die Gruppe aus, die Sie dieser Ressource zuweisen möchten.
- Konfigurieren Sie die anderen gewünschten Computeeinstellungen, und klicken Sie dann auf Erstellen.
Bewährte Methoden zum Verwalten von Gruppenclustern
Da Benutzerberechtigungen bei verwendung von Gruppenclustern auf die Gruppe festgelegt sind, empfiehlt Databricks, einen /Workspace/Groups/<groupName> Ordner für jede Gruppe zu erstellen, die Sie mit einem Gruppencluster verwenden möchten. Weisen Sie dann CAN MANAGE Berechtigungen für den Ordner der Gruppe zu. Auf diese Weise können Gruppen Berechtigungsfehler vermeiden. Alle Notizbücher und Arbeitsbereichsressourcen der Gruppe sollten im Gruppenordner verwaltet werden.
Sie müssen auch die folgenden Workloads so ändern, dass sie auf Gruppenclustern ausgeführt werden:
- MLflow: Stellen Sie sicher, dass Sie das Notizbuch aus dem Gruppenordner ausführen oder
mlflow.set_tracking_uri("/Workspace/Groups/<groupName>")ausführen. - AutoML: Legen Sie den optionalen Parameter
experiment_dirfür Ihre AutoML-Durchläufe auf“/Workspace/Groups/<groupName>”fest. dbutils.notebook.run: Stellen Sie sicher, dass die Gruppe für das ausgeführte Notebook über dieREAD-Berechtigung verfügt.
Beispielgruppenberechtigungen
Wenn Sie ein Datenobjekt mithilfe des Gruppenclusters erstellen, wird die Gruppe als Besitzer des Objekts zugewiesen.
Wenn Sie beispielsweise ein Notizbuch an einen Gruppencluster angefügt haben und den folgenden Befehl ausführen:
use catalog main;
create schema group_cluster_group_schema;
Führen Sie dann diese Abfrage aus, um den Besitzer des Schemas zu überprüfen:
describe schema group_cluster_group_schema;
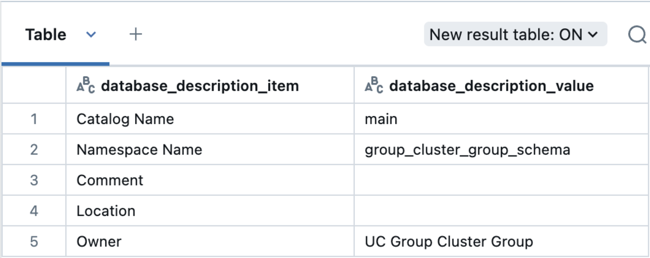
Überwachen der gruppenzugeordneten Computeaktivität
Es sind zwei Schlüsselidentitäten beteiligt, wenn ein Gruppencluster eine Workload ausführt:
- Der Benutzer, der die Workload auf dem Gruppencluster ausführt
- Die Gruppe, deren Berechtigungen zum Ausführen der tatsächlichen Workloadaktionen verwendet werden
Die Überwachungsprotokollsystemtabelle zeichnet diese Identitäten unter den folgenden Parametern auf:
identity_metadata.run_by: Der authentifizierende Benutzer, der die Aktion ausführtidentity_metadata.run_as: Die Autorisierungsgruppe, deren Berechtigungen für die Aktion verwendet werden.
Die folgende Beispielabfrage ruft die Identitätsmetadaten für eine Aktion ab, die mit dem Gruppencluster ausgeführt wird:
select action_name, event_time, user_identity.email, identity_metadata
from system.access.audit
where user_identity.email = "uc-group-cluster-group" AND service_name = "unityCatalog"
order by event_time desc limit 100;
In der Referenz zu Systemtabellen des Überwachungsprotokolls finden Sie weitere Beispielabfragen. Weitere Informationen finden Sie unter Referenz zu Systemtabellen des Überwachungsprotokolls.
Bekannte Probleme
- Arbeitsbereichsdateien und Ordner, die aus Gruppenclustern erstellt wurden, führen dazu, dass der zugewiesene Objektbesitzer
Unknownwird. Dies führt dazu, dass nachfolgende Vorgänge für diese Objekte, z. B.read,writeunddelete, aufgrund von Berechtigungsverweigerungsfehlern fehlschlagen.
Einschränkungen
Der dedizierte Gruppenzugriffsmodus Public Preview hat die folgenden bekannten Einschränkungen:
- Zeilensystemtabellen zeichnen nicht die
identity_metadata.run_as(die Autorisierungsgruppe) oderidentity_metadata.run_by(die authentifizierenden Benutzer)-Identitäten für Workloads auf, die auf einem Gruppencluster ausgeführt werden. - Überwachungsprotokolle, die an den Kundenspeicher übermittelt werden, zeichnen nicht die
identity_metadata.run_as(die Autorisierungsgruppe) oderidentity_metadata.run_by(die authentifizierenden Benutzer)-Identitäten für Workloads auf, die auf einem Gruppencluster ausgeführt werden. Sie müssen diesystem.access.auditTabelle verwenden, um die Identitätsmetadaten anzuzeigen. - Beim Anfügen an einen Gruppencluster filtert der Katalog-Explorer nicht nach Ressourcen, auf die nur für die Gruppe zugegriffen werden kann.
- Gruppenmanager, die keine Gruppenmitglieder sind, können keine Gruppencluster erstellen, bearbeiten oder löschen. Nur Arbeitsbereichsadministratoren und Gruppenmitglieder können dies tun.
- Wenn eine Gruppe umbenannt wird, müssen alle Berechnungsrichtlinien, die auf den Gruppennamen verweisen, manuell aktualisiert werden.
- Gruppencluster werden für Arbeitsbereiche mit deaktivierten ACLs (isWorkspaceAclsEnabled == false) aufgrund des inhärenten Mangels an Sicherheits- und Datenzugriffssteuerungen nicht unterstützt, wenn Arbeitsbereichs-ACLs deaktiviert sind.
- Der Befehl
%runverwendet derzeit die Berechtigungen des Benutzers anstelle der Berechtigungen der Gruppe, wenn er auf einem Gruppencluster ausgeführt wird. Alternativen wiedbutils.notebook.run()verwenden ordnungsgemäß die Berechtigungen der Gruppe.