Konfigurer lager og databaser
En del af udrulningsprocessen kræver ofte, at du opretter forbindelse til databaser eller lagertjenester. Denne forbindelse kan være nødvendig for at anvende et databaseskema, for at føje nogle referencedata til en databasetabel eller for at overføre nogle blobs. I dette undermodul får du mere at vide om, hvordan du kan udvide din pipeline til at arbejde med data- og lagertjenester.
Konfigurer dine databaser fra en pipeline
Mange databaser har skemaer, som repræsenterer strukturen af dataene i databasen. Det er ofte en god idé at anvende et skema på databasen fra din udrulningspipeline. Denne praksis hjælper med at sikre, at alt, hvad din løsning har brug for, udrulles sammen. Det sikrer også, at der vises en fejl i pipelinen, hvis der er et problem, når skemaet anvendes. Fejlen giver dig mulighed for at løse problemet og geninstallere.
Når du arbejder med Azure SQL, skal du anvende databaseskemaer ved at oprette forbindelse til databaseserveren og udføre kommandoer ved hjælp af SQL-scripts. Disse kommandoer er dataplanhandlinger. Pipelinen skal godkendes på databaseserveren og derefter udføre scripts. Azure Pipelines leverer den SqlAzureDacpacDeployment opgave, der kan oprette forbindelse til en Azure SQL-databaseserver og udføre kommandoer.
Nogle andre data- og lagertjenester behøver ikke at være konfigureret ved hjælp af en DATA Plane API. Når du f.eks. arbejder med Azure Cosmos DB, gemmer du dine data i en objektbeholder. Du kan konfigurere dine objektbeholdere ved hjælp af kontrolfladen direkte fra din Bicep-fil. På samme måde kan du udrulle og administrere de fleste aspekter af Azure Storage-blobobjektbeholdere i Bicep. I den næste øvelse får du vist et eksempel på, hvordan du opretter en blobobjektbeholder fra Bicep.
Tilføj data
Mange løsninger kræver, at der føjes referencedata til deres databaser eller lagerkonti, før de fungerer. Pipelines kan være et godt sted at tilføje disse data. Når pipelinen er kørt, er dit miljø fuldt konfigureret og klar til brug.
Det er også nyttigt at have eksempeldata i dine databaser, især til ikke-produktionsmiljøer. Eksempeldata hjælper testere og andre, der bruger disse miljøer, med at teste din løsning med det samme. Disse data kan omfatte eksempelprodukter eller ting som falske brugerkonti. Generelt vil du ikke føje disse data til dit produktionsmiljø.
Den fremgangsmåde, du bruger til at tilføje data, afhænger af den tjeneste, du bruger. For eksempel:
- Hvis du vil føje data til en Azure SQL-database, skal du udføre et script på samme måde som at konfigurere et skema.
- Hvis du vil indsætte data i en Azure Cosmos DB, skal du have adgang til api'en til dataplanet, hvilket kan kræve, at du skriver en brugerdefineret scriptkode.
- Hvis du vil uploade blobs til en Azure Storage-blobobjektbeholder, kan du bruge forskellige værktøjer fra pipelinescripts, herunder Kommandolinjeprogrammet AzCopy, Azure PowerShell eller Azure CLI. Hvert af disse værktøjer forstår, hvordan du godkender til Azure Storage på dine vegne, og hvordan du opretter forbindelse til dataplan-API'en for at uploade blobs.
Idempotens
En af egenskaberne ved udrulningspipelines og infrastruktur som kode er, at du skal kunne geninstallere gentagne gange uden negative bivirkninger. Når du f.eks. geninstallerer en tidligere udrullet Bicep-fil, sammenligner Azure Resource Manager den fil, du har sendt, med den eksisterende tilstand for dine Azure-ressourcer. Hvis der ikke er nogen ændringer, gør Resource Manager ikke noget. Muligheden for at udføre en handling igen gentagne gange kaldes idempotens. Det er en god idé at sikre, at dine scripts og andre pipelinetrin er idempotent.
Idempotens er især vigtig, når du interagerer med datatjenester, fordi de bevarer tilstanden. Forestil dig, at du indsætter en eksempelbruger i en databasetabel fra din pipeline. Hvis du ikke er forsigtig, oprettes der en ny eksempelbruger, hver gang du kører pipelinen. Dette resultat er sandsynligvis ikke det, du vil have.
Når du anvender skemaer på en Azure SQL-database, kan du bruge en datapakke, også kaldet en DACPAC-fil, til at installere dit skema. Din pipeline bygger en DACPAC-fil ud fra kildekode og opretter en pipelineartefakt på samme måde som med et program. Derefter publicerer udrulningsfasen i din pipeline DACPAC-filen til databasen:
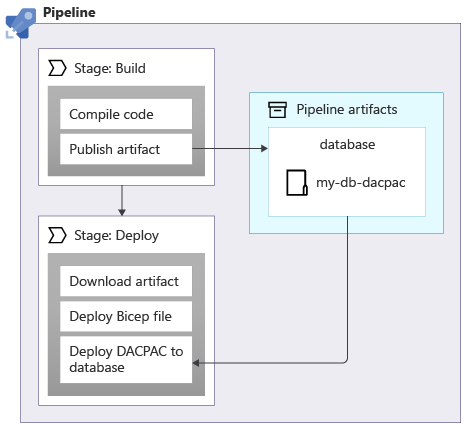
Når en DACPAC-fil installeres, fungerer den på en idempotent måde. Den sammenligner databasens destinationstilstand med den tilstand, der er defineret i pakken. I mange situationer betyder det, at du ikke behøver at skrive scripts, der følger princippet om idempotens, fordi værktøjet håndterer det for dig. Nogle af værktøjerne til Azure Cosmos DB og Azure Storage fungerer også korrekt.
Men når du opretter eksempeldata i en Azure SQL-database eller en anden lagertjeneste, der ikke automatisk fungerer på en idempotent måde. Det er en god idé at skrive dit script, så det kun opretter dataene, hvis de ikke allerede findes.
Det er også vigtigt at overveje, om du muligvis skal annullere udrulninger, f.eks. ved at køre en ældre version af en udrulningspipeline igen. Annullering af ændringer af dine data kan blive kompliceret, så overvej nøje, hvordan din løsning fungerer, hvis du har brug for at annullere.
Netværkssikkerhed
Nogle gange kan du anvende netværksbegrænsninger på nogle af dine Azure-ressourcer. Disse begrænsninger kan gennemtvinge regler om anmodninger, der er foretaget til dataplanet for en ressource, f.eks.:
- Denne databaseserver er kun tilgængelig fra en angivet liste over IP-adresser.
- Denne lagerkonto er kun tilgængelig fra ressourcer, der er udrullet i et bestemt virtuelt netværk.
Netværksbegrænsninger er almindelige for databaser, fordi det kan se ud til, at der ikke er behov for noget på internettet for at oprette forbindelse til en databaseserver.
Netværksbegrænsninger kan dog også gøre det svært for dine udrulningspipelines at arbejde med dine ressourcedataplaner. Når du bruger en Microsoft-hostet pipelineagent, kan ip-adressen ikke være let at kende på forhånd, og den kan tildeles fra en stor pulje af IP-adresser. Derudover kan Microsoft-hostede pipelineagenter ikke have forbindelse til dine egne virtuelle netværk.
Nogle af de Azure Pipelines-opgaver, der hjælper dig med at udføre dataplanhandlinger, kan løse disse problemer. Den SqlAzureDacpacDeployment opgave:
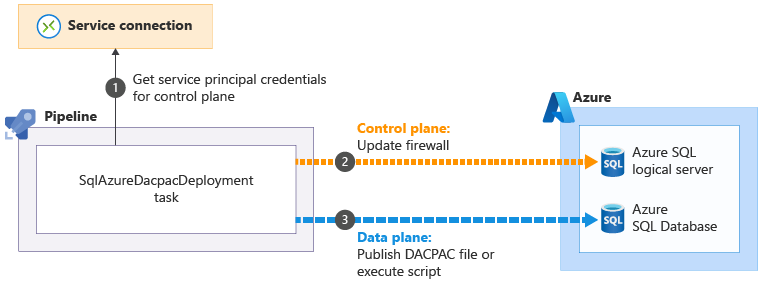
Når du bruger SqlAzureDacpacDeployment opgave til at arbejde med en logisk Azure SQL-server eller -database, bruger den din pipelines tjenesteprincipal til at oprette forbindelse til kontrolplanet for den logiske Azure SQL-server. Den opdaterer firewallen for at give pipelineagenten adgang til serveren fra ip-adressen
til at oprette forbindelse til kontrolplanet for den logiske Azure SQL-server. Den opdaterer firewallen for at give pipelineagenten adgang til serveren fra ip-adressen . Derefter kan den sende DACPAC-filen eller -scriptet til udførelse
. Derefter kan den sende DACPAC-filen eller -scriptet til udførelse . Opgaven fjerner derefter automatisk firewallreglen, når den er fuldført.
. Opgaven fjerner derefter automatisk firewallreglen, når den er fuldført.
I andre situationer er det ikke muligt at oprette disse typer undtagelser. I disse tilfælde kan du overveje at bruge en selvværts pipelineagent, som kører på en virtuel maskine eller en anden beregningsressource, som du styrer. Du kan derefter konfigurere denne agent, som du har brug for. Den kan bruge en kendt IP-adresse, eller den kan forbindes til dit eget virtuelle netværk. Vi diskuterer ikke selv hostede agenter i dette modul, men vi leverer links til flere oplysninger på siden Oversigt i slutningen af modulet.
Din udrulningspipeline
I den næste øvelse skal du opdatere din udrulningspipeline for at tilføje nye job for at bygge databasekomponenterne på dit websted, installere databasen og tilføje seeddata:
