TripPin del 5 – sideinddeling
Dette selvstudium i flere dele dækker oprettelsen af en ny datakildeudvidelse til Power Query. Selvstudiet er beregnet til at blive udført sekventielt – hver lektion bygger på den connector, der blev oprettet i tidligere lektioner, og føjer trinvist nye funktioner til din connector.
I denne lektion skal du:
- Føj understøttelse af sideinddeling til connectoren
Mange rest-API'er returnerer data på "sider", hvilket kræver, at klienter foretager flere anmodninger for at sy resultaterne sammen. Selvom der er nogle almindelige konventioner for sideinddeling (f.eks . RFC 5988), varierer den generelt fra API til API. Heldigvis er TripPin en OData-tjeneste, og OData-standarden definerer en måde at udføre sideinddeling på ved hjælp af odata.nextLink-værdier, der returneres i brødteksten i svaret.
Funktionen var ikke sideorienteret for at forenkle tidligere gentagelser af connectorenTripPin.Feed. Den fortolkede blot det JSON, der blev returneret fra anmodningen, og formaterede den som en tabel. De, der kender OData-protokollen, har måske bemærket, at der blev foretaget mange forkerte antagelser om svarets format (f.eks. hvis der er et value felt, der indeholder en matrix af poster).
I denne lektion forbedrer du logikken for svarhåndtering ved at gøre den side opmærksom. Fremtidige selvstudier gør logikken for sidehåndtering mere robust og i stand til at håndtere flere svarformater (herunder fejl fra tjenesten).
Bemærk
Du behøver ikke at implementere din egen sideinddelingslogik med connectors, der er baseret på OData.Feed, da den håndterer det hele automatisk for dig.
Tjekliste til sideinddeling
Når du implementerer sideopdelingsunderstøttelse, skal du vide følgende om din API:
- Hvordan anmoder du om den næste side med data?
- Omfatter sideopdelingsmekanismen beregning af værdier, eller udtrækker du URL-adressen til den næste side fra svaret?
- Hvordan ved du, hvornår du skal stoppe sideopdelingen?
- Er der parametre relateret til sideinddeling, som du skal være opmærksom på? (f.eks. "sidestørrelse")
Svaret på disse spørgsmål påvirker den måde, du implementerer din sideinddelingslogik på. Selvom der er en vis mængde genbrug af kode på tværs af sideinddelingsimplementeringer (f.eks. brugen af Table.GenerateByPage, vil de fleste connectors ende med at kræve brugerdefineret logik.
Bemærk
Denne lektion indeholder sideinddelingslogik for en OData-tjeneste, som følger et bestemt format. Se dokumentationen til din API for at finde ud af, hvilke ændringer du skal foretage i din connector for at understøtte dens sideinddelingsformat.
Oversigt over OData-sideinddeling
OData-sideopdeling er baseret på nextLink-anmærkninger , der er indeholdt i svarets nyttedata. Værdien nextLink indeholder URL-adressen til den næste side med data. Du ved, om der er en anden side med data ved at søge efter et odata.nextLink felt i det yderste objekt i svaret. Hvis der ikke er noget odata.nextLink felt, har du læst alle dine data.
{
"odata.context": "...",
"odata.count": 37,
"value": [
{ },
{ },
{ }
],
"odata.nextLink": "...?$skiptoken=342r89"
}
Nogle OData-tjenester gør det muligt for klienter at angive en maksimal indstilling for sidestørrelse, men det er op til tjenesten, om den skal accepteres eller ej. Power Query bør kunne håndtere svar af enhver størrelse, så du ikke behøver at bekymre dig om at angive en indstilling for sidestørrelse – du kan understøtte det, som tjenesten kaster efter dig.
Du kan finde flere oplysninger om serverdrevet sideinddeling i OData-specifikationen.
Test trippin
Før du retter implementeringen af sideinddelingen, skal du bekræfte den aktuelle funktionsmåde for udvidelsen fra det forrige selvstudium. Følgende testforespørgsel henter tabellen Mennesker og tilføjer en indekskolonne for at få vist det aktuelle rækkeantal.
let
source = TripPin.Contents(),
data = source{[Name="People"]}[Data],
withRowCount = Table.AddIndexColumn(data, "Index")
in
withRowCount
Slå Fiddler til, og kør forespørgslen i Power Query SDK. Bemærk, at forespørgslen returnerer en tabel med otte rækker (indeks 0 til 7).
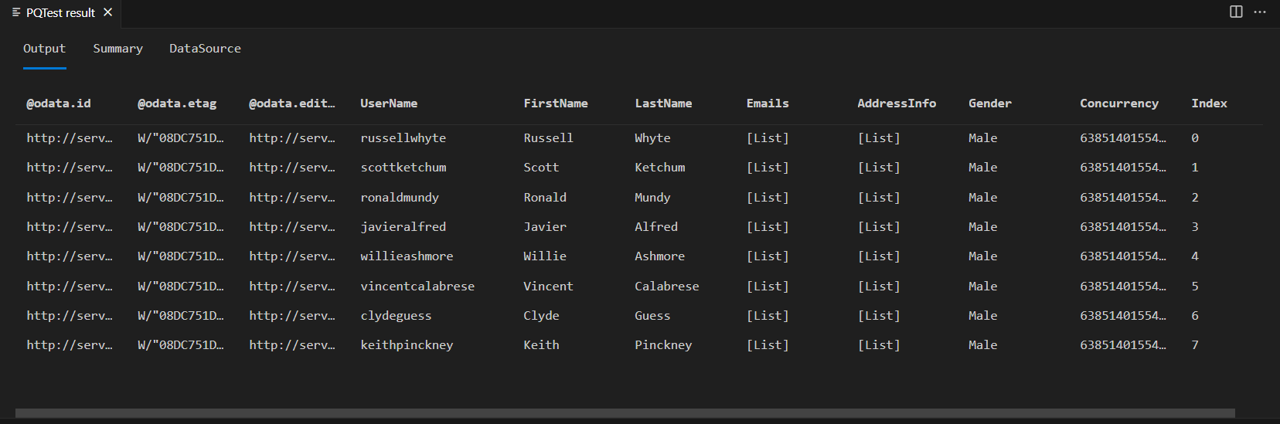
Hvis du ser på brødteksten i svaret fra fiddler, kan du se, at det faktisk indeholder et @odata.nextLink felt, hvilket angiver, at der er flere tilgængelige sider med data.
{
"@odata.context": "https://services.odata.org/V4/TripPinService/$metadata#People",
"@odata.nextLink": "https://services.odata.org/v4/TripPinService/People?%24skiptoken=8",
"value": [
{ },
{ },
{ }
]
}
Implementering af sideinddeling for TripPin
Du skal nu foretage følgende ændringer af din udvidelse:
- Importér den fælles
Table.GenerateByPagefunktion - Tilføj en
GetAllPagesByNextLinkfunktion, der brugerTable.GenerateByPagetil at fastklæbe alle sider sammen - Tilføj en
GetPagefunktion, der kan læse en enkelt side med data - Tilføj en
GetNextLinkfunktion for at udtrække den næste URL-adresse fra svaret - Opdater
TripPin.Feedfor at bruge de nye sidelæserfunktioner
Bemærk
Som tidligere nævnt i dette selvstudium varierer sideinddelingslogik mellem datakilder. Implementeringen her forsøger at opdele logikken i funktioner, der skal kunne genbruges for kilder, der bruger de næste links , der returneres i svaret.
Table.GenerateByPage
Hvis du vil kombinere de (potentielt) flere sider, der returneres af kilden, til en enkelt tabel, bruger Table.GenerateByPagevi . Denne funktion bruger som argument en getNextPage funktion, der skal gøre lige præcis, hvad dens navn antyder: hent den næste side med data. Table.GenerateByPage kalder gentagne gange funktionen getNextPage , hver gang den overføres, de resultater, der blev produceret, sidste gang den blev kaldt, indtil den vender tilbage for at signalere null , at der ikke er flere tilgængelige sider.
Da denne funktion ikke er en del af Power Querys standardbibliotek, skal du kopiere kildekoden til din .pq-fil.
Implementering af GetAllPagesByNextLink
Brødteksten i funktionen GetAllPagesByNextLink implementerer funktionsargumentet getNextPage for Table.GenerateByPage. Den kalder funktionen GetPage og henter URL-adressen for den næste side med data fra feltet NextLink i posten meta fra det forrige kald.
// Read all pages of data.
// After every page, we check the "NextLink" record on the metadata of the previous request.
// Table.GenerateByPage will keep asking for more pages until we return null.
GetAllPagesByNextLink = (url as text) as table =>
Table.GenerateByPage((previous) =>
let
// if previous is null, then this is our first page of data
nextLink = if (previous = null) then url else Value.Metadata(previous)[NextLink]?,
// if NextLink was set to null by the previous call, we know we have no more data
page = if (nextLink <> null) then GetPage(nextLink) else null
in
page
);
Implementering af GetPage
Din GetPage funktion bruger Web.Contents til at hente en enkelt side med data fra TripPin-tjenesten og konvertere svaret til en tabel. Svaret fra Web.Contents overføres til funktionen GetNextLink for at udtrække URL-adressen for den næste side og angive den i meta posten for den returnerede tabel (dataside).
Denne implementering er en lidt ændret version af opkaldet TripPin.Feed fra de forrige selvstudier.
GetPage = (url as text) as table =>
let
response = Web.Contents(url, [ Headers = DefaultRequestHeaders ]),
body = Json.Document(response),
nextLink = GetNextLink(body),
data = Table.FromRecords(body[value])
in
data meta [NextLink = nextLink];
Implementering af GetNextLink
Din GetNextLink funktion kontrollerer blot brødteksten i svaret for et @odata.nextLink felt og returnerer dets værdi.
// In this implementation, 'response' will be the parsed body of the response after the call to Json.Document.
// Look for the '@odata.nextLink' field and simply return null if it doesn't exist.
GetNextLink = (response) as nullable text => Record.FieldOrDefault(response, "@odata.nextLink");
Sætte det hele sammen
Det sidste trin til at implementere sideinddelingslogikken er at opdatere TripPin.Feed for at bruge de nye funktioner. I øjeblikket kalder du blot til GetAllPagesByNextLink, men i efterfølgende selvstudier tilføjer du nye funktioner (f.eks. gennemtvingelse af et skema og logik for forespørgselsparametre).
TripPin.Feed = (url as text) as table => GetAllPagesByNextLink(url);
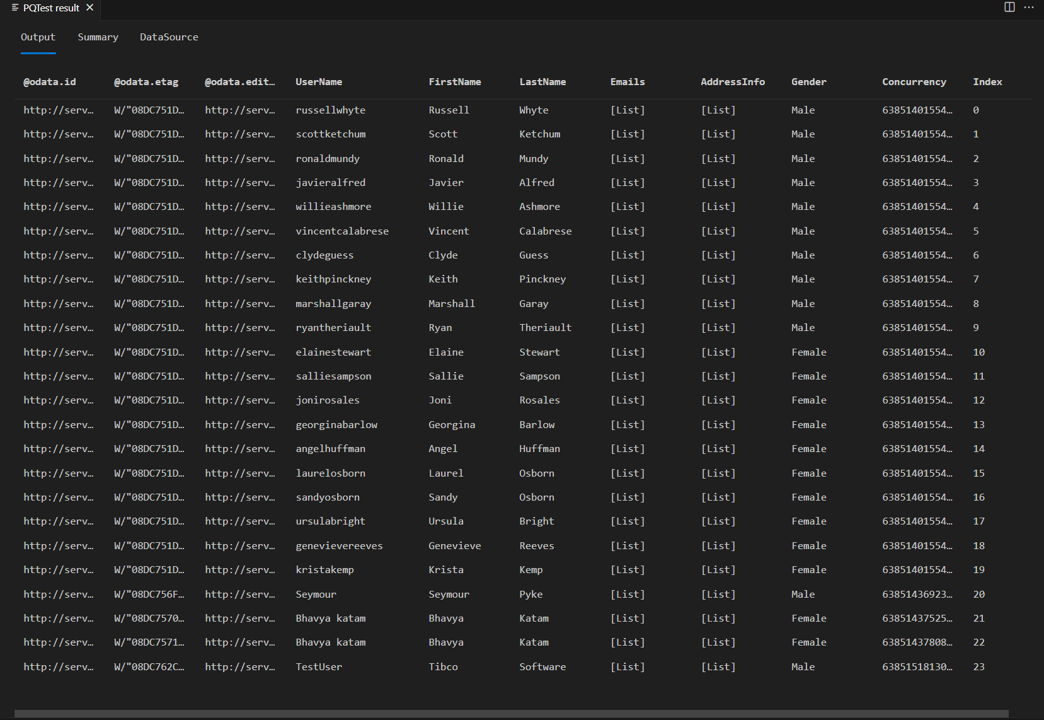
Hvis du kører den samme testforespørgsel igen tidligere i selvstudiet, kan du nu se sidelæseren i aktion. Du bør også se, at du har 24 rækker i svaret i stedet for otte.
Hvis du ser på anmodningerne i fiddler, bør du nu se separate anmodninger for hver side med data.
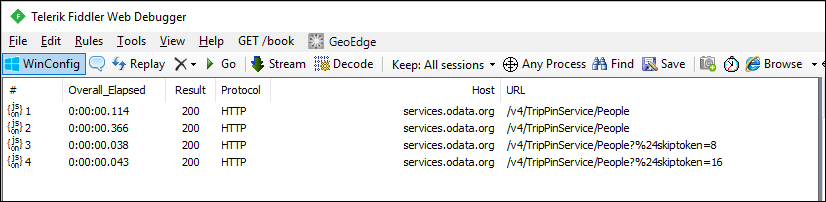
Bemærk
Du vil bemærke dubletanmodninger for den første side med data fra tjenesten, hvilket ikke er ideelt. Den ekstra anmodning er et resultat af funktionsmåden for M-programmets skemakontrol. Ignorer dette problem lige nu, og løs det i det næste selvstudium, hvor du skal anvende et eksplicit skema.
Konklusion
I denne lektion kan du se, hvordan du implementerer sideinddelingsunderstøttelse for en Rest API. Selvom logikken sandsynligvis varierer mellem API'er, bør det mønster, der er etableret her, kunne genbruges med mindre ændringer.
I den næste lektion skal du se på, hvordan du anvender et eksplicit skema på dine data ud over de enkle text og number datatyper, du får fra Json.Document.