TripPin del 10 – Grundlæggende forespørgselsdelegering
Bemærk
Dette indhold refererer i øjeblikket til indhold fra en ældre implementering for logge i Visual Studio. Indholdet opdateres i den nærmeste fremtid, så det dækker det nye Power Query SDK i Visual Studio Code.
Dette selvstudium i flere dele dækker oprettelsen af en ny datakildeudvidelse til Power Query. Selvstudiet er beregnet til at blive udført sekventielt – hver lektion bygger på den connector, der blev oprettet i tidligere lektioner, og føjer trinvist nye funktioner til din connector.
I denne lektion skal du:
- Få mere at vide om de grundlæggende funktioner i forespørgselsdelegering
- Få mere at vide om funktionen Table.View
- Repliker OData-forespørgselsdelegeringshandlere for:
$top$skip$count$select$orderby
En af de effektive funktioner i M-sproget er muligheden for at overføre transformationsarbejde til en eller flere underliggende datakilder. Denne funktion kaldes forespørgselsdelegering (andre værktøjer/teknologier refererer også til lignende funktion som Prædikat-pushdown eller forespørgselsdelegering).
Når du opretter en brugerdefineret connector, der bruger en M-funktion med indbyggede funktioner til forespørgselsdelegering, f.eks . OData.Feed eller Odbc.DataSource, arver din connector automatisk denne funktion gratis.
I dette selvstudium replikeres den indbyggede funktionsmåde for forespørgselsdelegering for OData ved at implementere funktionshandlere for funktionen Table.View . Denne del af selvstudiet implementerer nogle af de nemmere handlere at implementere (dvs. dem, der ikke kræver udtryksudtryksparsing og tilstandssporing).
Hvis du vil vide mere om de forespørgselsfunktioner, som en OData-tjeneste kan tilbyde, skal du gå til URL-konventioner for OData v4.
Bemærk
Som tidligere nævnt leverer funktionen OData.Feed automatisk forespørgselsdelegeringsfunktioner. Da TripPin-serien behandler OData-tjenesten som en almindelig REST-API ved hjælp af Web.Contents i stedet for OData.Feed, skal du selv implementere forespørgselsdelegeringshandlerne. Til brug i den virkelige verden anbefaler vi, at du bruger OData.Feed , når det er muligt.
Gå til Oversigt over evaluering af forespørgsler og forespørgselsdelegering i Power Query for at få flere oplysninger om forespørgselsdelegering.
Brug af Table.View
Funktionen Table.View gør det muligt for en brugerdefineret connector at tilsidesætte standardtransformationshandlere for din datakilde. En implementering af Table.View giver en funktion til en eller flere af de understøttede handlere. Hvis en handler ikke er implementeret, eller returnerer en error under evaluering, vender M-programmet tilbage til standardhandleren.
Når en brugerdefineret connector bruger en funktion, der ikke understøtter implicit forespørgselsdelegering, f.eks . Web.Contents, udføres standardtransformationshandlere altid lokalt. Hvis den REST-API, du opretter forbindelse til, understøtter forespørgselsparametre som en del af forespørgslen, kan du i Table.View tilføje optimeringer, der gør det muligt at pushe transformationsarbejde til tjenesten.
Funktionen Table.View har følgende signatur:
Table.View(table as nullable table, handlers as record) as table
Din implementering ombryder din primære datakildefunktion. Der er to påkrævede handlere til Table.View:
GetType– returnerer det forventedetable typeaf forespørgselsresultatetGetRows– returnerer det faktisketableresultat af din datakildefunktion
Den nemmeste implementering ligner følgende eksempel:
TripPin.SuperSimpleView = (url as text, entity as text) as table =>
Table.View(null, [
GetType = () => Value.Type(GetRows()),
GetRows = () => GetEntity(url, entity)
]);
Opdater funktionen TripPinNavTable til at kalde TripPin.SuperSimpleView i stedet GetEntityfor :
withData = Table.AddColumn(rename, "Data", each TripPin.SuperSimpleView(url, [Name]), type table),
Hvis du kører enhedstestene igen, kan du se, at funktionens funktionsmåde ikke ændres. I dette tilfælde gennemgår table.View-implementeringen blot kaldet til GetEntity. Da du ikke har implementeret nogen transformationshandlere (endnu), forbliver den oprindelige url parameter urørt.
Indledende implementering af Table.View
Ovenstående implementering af Table.View er enkel, men ikke særlig nyttig. Følgende implementering bruges som din oprindelige plan – den implementerer ikke nogen foldningsfunktionalitet, men har det stillads, du skal bruge til at gøre det.
TripPin.View = (baseUrl as text, entity as text) as table =>
let
// Implementation of Table.View handlers.
//
// We wrap the record with Diagnostics.WrapHandlers() to get some automatic
// tracing if a handler returns an error.
//
View = (state as record) => Table.View(null, Diagnostics.WrapHandlers([
// Returns the table type returned by GetRows()
GetType = () => CalculateSchema(state),
// Called last - retrieves the data from the calculated URL
GetRows = () =>
let
finalSchema = CalculateSchema(state),
finalUrl = CalculateUrl(state),
result = TripPin.Feed(finalUrl, finalSchema),
appliedType = Table.ChangeType(result, finalSchema)
in
appliedType,
//
// Helper functions
//
// Retrieves the cached schema. If this is the first call
// to CalculateSchema, the table type is calculated based on
// the entity name that was passed into the function.
CalculateSchema = (state) as type =>
if (state[Schema]? = null) then
GetSchemaForEntity(entity)
else
state[Schema],
// Calculates the final URL based on the current state.
CalculateUrl = (state) as text =>
let
urlWithEntity = Uri.Combine(state[Url], state[Entity])
in
urlWithEntity
]))
in
View([Url = baseUrl, Entity = entity]);
Hvis du ser på kaldet til Table.View, kan du se en ekstra ombrydningsfunktion omkring posten – .Diagnostics.WrapHandlershandlers Denne hjælpefunktion findes i diagnosticeringsmodulet (som blev introduceret i lektionen til tilføjelse af diagnosticering ), og den giver dig en nyttig måde til automatisk at spore eventuelle fejl, der opstår af individuelle handlere.
Funktionerne GetType og GetRows opdateres for at gøre brug af to nye hjælpefunktioner –CalculateSchema og CalculateUrl. Lige nu er implementeringerne af disse funktioner ret ligetil – bemærk, at de indeholder dele af det, der tidligere blev udført af funktionen GetEntity .
Bemærk til sidst, at du definerer en intern funktion (View), der accepterer en state parameter.
Når du implementerer flere handlere, kalder de rekursivt den interne View funktion, opdateres og overføres, state mens de fortsætter.
Opdater funktionen TripPinNavTable igen, og udskift opkaldet til TripPin.SuperSimpleView med et kald til den nye TripPin.View funktion, og kør enhedstestene igen. Du kan ikke se nogen ny funktionalitet endnu, men du har nu en solid baseline til test.
Implementering af forespørgselsdelegering
Da M-programmet automatisk går tilbage til lokal behandling, når en forespørgsel ikke kan delegeres, skal du udføre nogle ekstra trin for at kontrollere, at dine Table.View-handlere fungerer korrekt.
Den manuelle måde at validere foldefunktionsmåden på er ved at se de URL-anmodninger, som dine enhedstest foretager ved hjælp af et værktøj som Fiddler. Alternativt kan du bruge den logføring af diagnosticering, du har føjet til, til at TripPin.Feed sende den fulde URL-adresse, der køres, hvilket bør omfatte parametrene for OData-forespørgselsstrengen, som dine handlere tilføjer.
En automatiseret måde at validere forespørgselsdelegering på er ved at tvinge udførelsen af enhedstesten til at mislykkes, hvis en forespørgsel ikke foldes helt. Det kan du gøre ved at åbne projektegenskaberne og angive Fejl ved foldningsfejl til sand. Når denne indstilling er aktiveret, medfører alle forespørgsler, der kræver lokal behandling, følgende fejl:
Vi kunne ikke folde udtrykket til kilden. Prøv et enklere udtryk.
Du kan teste dette ved at føje en ny Fact til din enhedstestfil, der indeholder en eller flere tabeltransformationer.
// Query folding tests
Fact("Fold $top 1 on Airlines",
#table( type table [AirlineCode = text, Name = text] , {{"AA", "American Airlines"}} ),
Table.FirstN(Airlines, 1)
)
Bemærk
Indstillingen Fejl ved foldningsfejl er en "alt eller intet"-tilgang. Hvis du vil teste forespørgsler, der ikke er designet til at folde som en del af dine enhedstests, skal du tilføje en betinget logik for at aktivere/deaktivere test i overensstemmelse hermed.
De resterende afsnit i dette selvstudium tilføjer hver især en ny Table.View-handler . Du bruger en TDD-tilgang (Test Driven Development), hvor du først tilføjer mislykkede enhedstest og derefter implementerer M-koden for at løse dem.
I følgende handlerafsnit beskrives den funktionalitet, der leveres af handleren, den tilsvarende forespørgselssyntaks for OData, enhedstestene og implementeringen. Ved hjælp af den stilladskode, der er beskrevet tidligere, kræver hver implementering af handleren to ændringer:
- Tilføjelse af handleren til Table.View , der opdaterer posten
state. - Ændring
CalculateUrlfor at hente værdierne frastateog føje til parametrene for URL-adressen og/eller forespørgselsstrengen.
Håndtering af Table.FirstN med OnTake
Handleren OnTake modtager en count parameter, som er det maksimale antal rækker, der kan hentes fra GetRows.
I OData-begreber kan du oversætte dette til forespørgselsparameteren $top .
Du kan bruge følgende enhedstest:
// Query folding tests
Fact("Fold $top 1 on Airlines",
#table( type table [AirlineCode = text, Name = text] , {{"AA", "American Airlines"}} ),
Table.FirstN(Airlines, 1)
),
Fact("Fold $top 0 on Airports",
#table( type table [Name = text, IataCode = text, Location = record] , {} ),
Table.FirstN(Airports, 0)
),
Begge disse test bruger Table.FirstN til at filtrere efter resultatsættet til det første X antal rækker. Hvis du kører disse test med Error on Folding Failure angivet til False (standarden), bør testene lykkes, men hvis du kører Fiddler (eller kontrollerer sporingslogfilerne), kan du se, at den anmodning, du sender, ikke indeholder nogen OData-forespørgselsparametre.
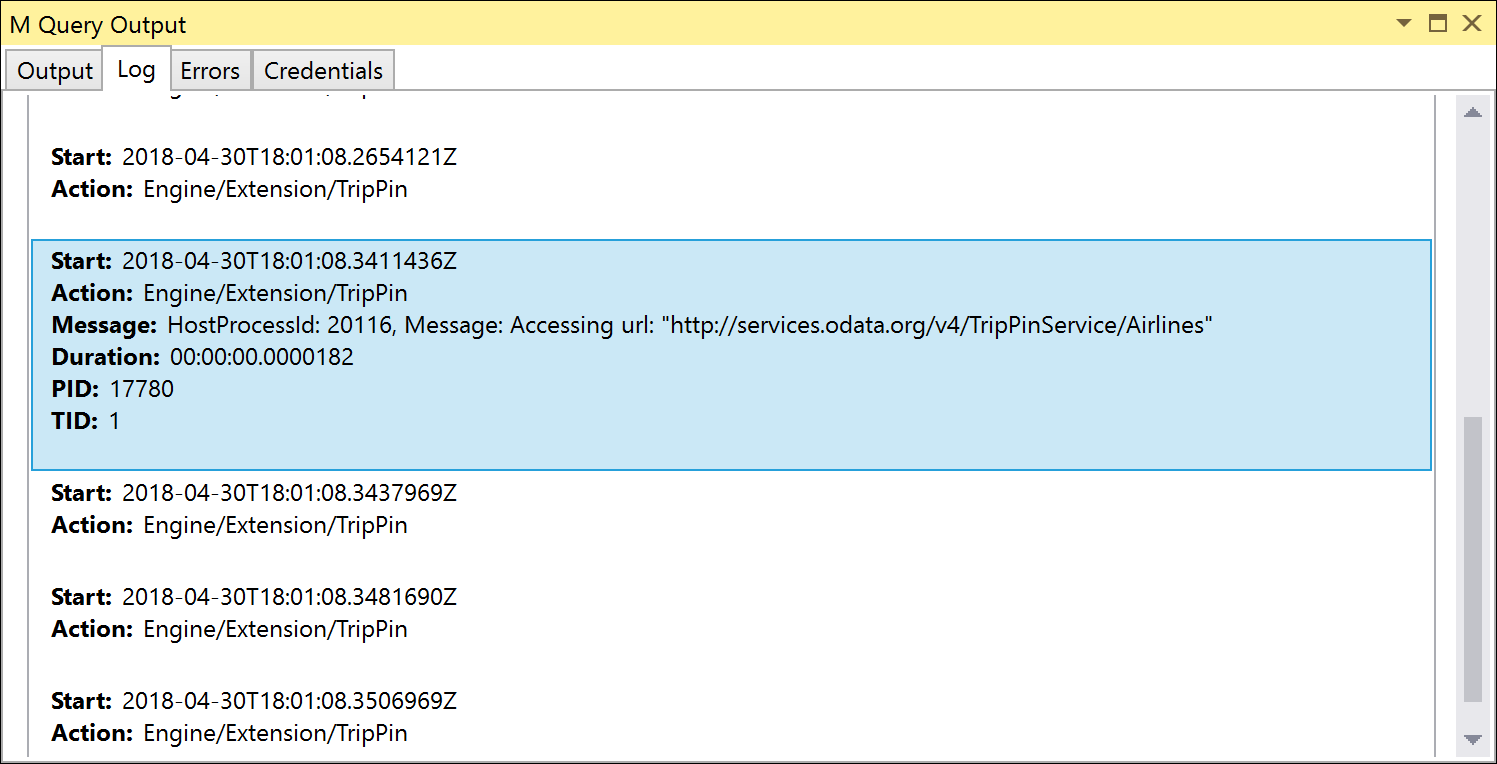
Hvis du angiver Error on Folding Failure to True, mislykkes testene med Please try a simpler expression. fejlen. Du kan løse denne fejl ved at definere den første Table.View-handler for OnTake.
Handleren OnTake ligner følgende kode:
OnTake = (count as number) =>
let
// Add a record with Top defined to our state
newState = state & [ Top = count ]
in
@View(newState),
Funktionen CalculateUrl opdateres for at udtrække værdien Top fra posten state og angive den rigtige parameter i forespørgselsstrengen.
// Calculates the final URL based on the current state.
CalculateUrl = (state) as text =>
let
urlWithEntity = Uri.Combine(state[Url], state[Entity]),
// Uri.BuildQueryString requires that all field values
// are text literals.
defaultQueryString = [],
// Check for Top defined in our state
qsWithTop =
if (state[Top]? <> null) then
// add a $top field to the query string record
defaultQueryString & [ #"$top" = Number.ToText(state[Top]) ]
else
defaultQueryString,
encodedQueryString = Uri.BuildQueryString(qsWithTop),
finalUrl = urlWithEntity & "?" & encodedQueryString
in
finalUrl
Hvis du kører enhedstestene igen, kan du se, at den URL-adresse, du får adgang til, nu indeholder $top parameteren. På grund af kodning af URL-adressen $top vises som %24top, men OData-tjenesten er smart nok til automatisk at konvertere den.
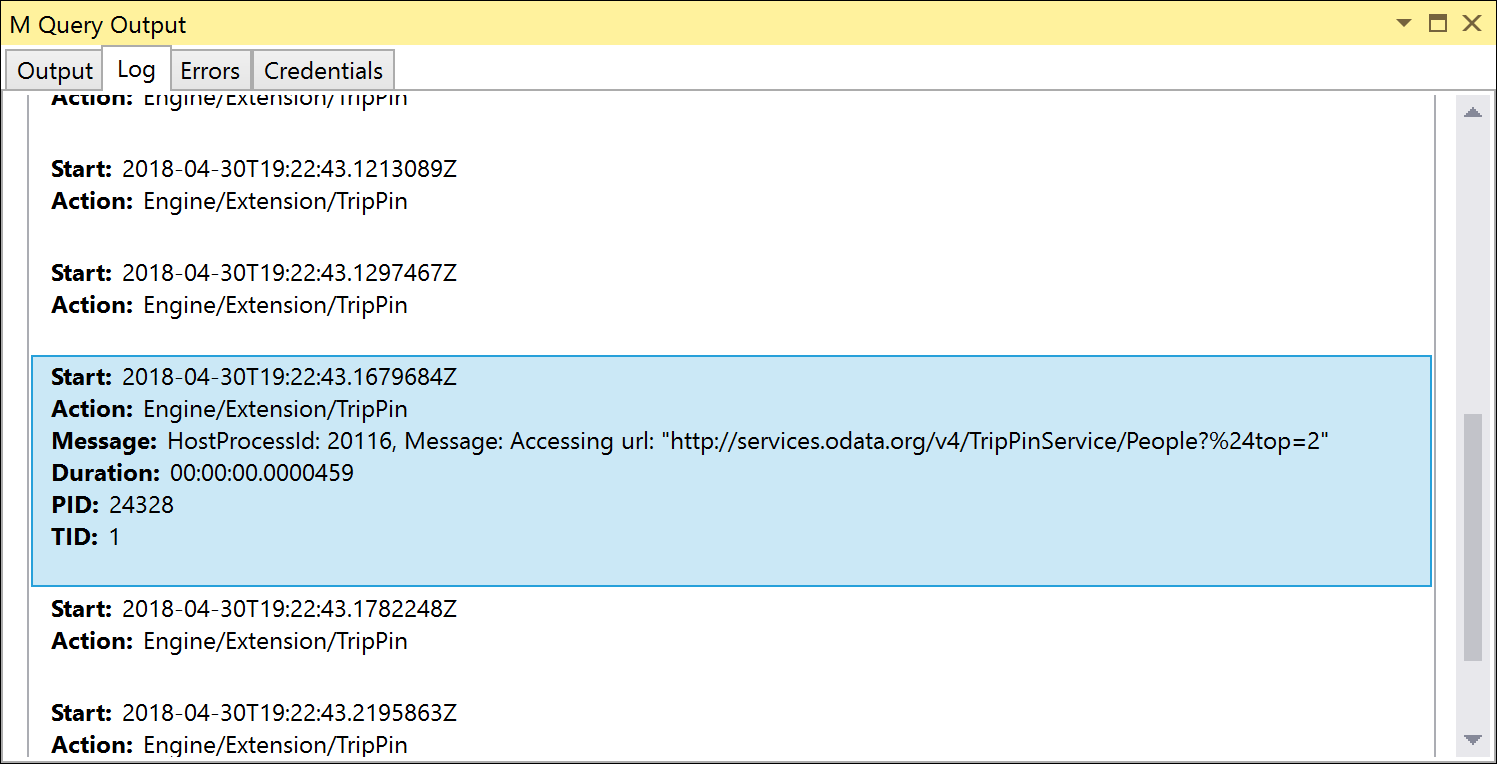
Håndtering af Table.Skip med OnSkip
Handleren OnSkip minder meget om OnTake. Den modtager en count parameter, som er antallet af rækker, der skal springes over fra resultatsættet. Denne handler oversætter pænt til forespørgselsparameteren OData $skip .
Enhedstests:
// OnSkip
Fact("Fold $skip 14 on Airlines",
#table( type table [AirlineCode = text, Name = text] , {{"EK", "Emirates"}} ),
Table.Skip(Airlines, 14)
),
Fact("Fold $skip 0 and $top 1",
#table( type table [AirlineCode = text, Name = text] , {{"AA", "American Airlines"}} ),
Table.FirstN(Table.Skip(Airlines, 0), 1)
),
Gennemførelsen:
// OnSkip - handles the Table.Skip transform.
// The count value should be >= 0.
OnSkip = (count as number) =>
let
newState = state & [ Skip = count ]
in
@View(newState),
Matchende opdateringer til CalculateUrl:
qsWithSkip =
if (state[Skip]? <> null) then
qsWithTop & [ #"$skip" = Number.ToText(state[Skip]) ]
else
qsWithTop,
Flere oplysninger: Table.Skip
Håndtering af Table.SelectColumns med OnSelectColumns
Handleren OnSelectColumns kaldes, når brugeren vælger eller fjerner kolonner fra resultatsættet. Handleren modtager en list af text værdierne, der repræsenterer en eller flere kolonner, der skal vælges.
I OData-begreber knyttes denne handling til forespørgselsindstillingen $select .
Fordelen ved at folde kolonnemarkering bliver synlig, når du arbejder med tabeller med mange kolonner. Operatoren $select fjerner ikke-markerede kolonner fra resultatsættet, hvilket resulterer i mere effektive forespørgsler.
Enhedstests:
// OnSelectColumns
Fact("Fold $select single column",
#table( type table [AirlineCode = text] , {{"AA"}} ),
Table.FirstN(Table.SelectColumns(Airlines, {"AirlineCode"}), 1)
),
Fact("Fold $select multiple column",
#table( type table [UserName = text, FirstName = text, LastName = text],{{"russellwhyte", "Russell", "Whyte"}}),
Table.FirstN(Table.SelectColumns(People, {"UserName", "FirstName", "LastName"}), 1)
),
Fact("Fold $select with ignore column",
#table( type table [AirlineCode = text] , {{"AA"}} ),
Table.FirstN(Table.SelectColumns(Airlines, {"AirlineCode", "DoesNotExist"}, MissingField.Ignore), 1)
),
De første to test vælger forskellige antal kolonner med Table.SelectColumns og inkluderer et Table.FirstN-kald for at forenkle testcasen.
Bemærk
Hvis testen blot returnerede kolonnenavnene (ved hjælp af Table.ColumnNames og ikke nogen data, sendes anmodningen til OData-tjenesten aldrig. Dette skyldes, at kaldet til GetType returnerer skemaet, som indeholder alle de oplysninger, som M-programmet skal bruge til at beregne resultatet.
Den tredje test bruger indstillingen MissingField.Ignore , som beder M-programmet om at ignorere de valgte kolonner, der ikke findes i resultatsættet. Handleren OnSelectColumns behøver ikke at bekymre sig om denne indstilling – M-programmet håndterer det automatisk (dvs. manglende kolonner er ikke inkluderet på columns listen).
Bemærk
Den anden indstilling for Table.SelectColumns, MissingField.UseNull, kræver en connector for at implementere handleren OnAddColumn . Dette gøres i en efterfølgende lektion.
Implementeringen af OnSelectColumns gør to ting:
- Føjer listen over markerede kolonner til
state. - Genberegner værdien,
Schemaså du kan angive den rigtige tabeltype.
OnSelectColumns = (columns as list) =>
let
// get the current schema
currentSchema = CalculateSchema(state),
// get the columns from the current schema (which is an M Type value)
rowRecordType = Type.RecordFields(Type.TableRow(currentSchema)),
existingColumns = Record.FieldNames(rowRecordType),
// calculate the new schema
columnsToRemove = List.Difference(existingColumns, columns),
updatedColumns = Record.RemoveFields(rowRecordType, columnsToRemove),
newSchema = type table (Type.ForRecord(updatedColumns, false))
in
@View(state &
[
SelectColumns = columns,
Schema = newSchema
]
),
CalculateUrl opdateres for at hente listen over kolonner fra tilstanden og kombinere dem (med en separator) for $select parameteren.
// Check for explicitly selected columns
qsWithSelect =
if (state[SelectColumns]? <> null) then
qsWithSkip & [ #"$select" = Text.Combine(state[SelectColumns], ",") ]
else
qsWithSkip,
Håndtering af Table.Sort med OnSort
Handleren OnSort modtager en liste over poster af typen:
type [ Name = text, Order = Int16.Type ]
Hver post indeholder et Name felt, der angiver navnet på kolonnen, og et Order felt, der er lig med Order.Ascending eller Order.Descending.
I OData-begreber knyttes denne handling til forespørgselsindstillingen $orderby .
$orderby Syntaksen har kolonnenavnet efterfulgt af asc eller desc for at angive stigende eller faldende rækkefølge. Når du sorterer efter flere kolonner, adskilles værdierne med et komma. Hvis parameteren columns indeholder mere end ét element, er det vigtigt at bevare den rækkefølge, de vises i.
Enhedstests:
// OnSort
Fact("Fold $orderby single column",
#table( type table [AirlineCode = text, Name = text], {{"TK", "Turkish Airlines"}}),
Table.FirstN(Table.Sort(Airlines, {{"AirlineCode", Order.Descending}}), 1)
),
Fact("Fold $orderby multiple column",
#table( type table [UserName = text], {{"javieralfred"}}),
Table.SelectColumns(Table.FirstN(Table.Sort(People, {{"LastName", Order.Ascending}, {"UserName", Order.Descending}}), 1), {"UserName"})
)
Gennemførelsen:
// OnSort - receives a list of records containing two fields:
// [Name] - the name of the column to sort on
// [Order] - equal to Order.Ascending or Order.Descending
// If there are multiple records, the sort order must be maintained.
//
// OData allows you to sort on columns that do not appear in the result
// set, so we do not have to validate that the sorted columns are in our
// existing schema.
OnSort = (order as list) =>
let
// This will convert the list of records to a list of text,
// where each entry is "<columnName> <asc|desc>"
sorting = List.Transform(order, (o) =>
let
column = o[Name],
order = o[Order],
orderText = if (order = Order.Ascending) then "asc" else "desc"
in
column & " " & orderText
),
orderBy = Text.Combine(sorting, ", ")
in
@View(state & [ OrderBy = orderBy ]),
Opdateringer til CalculateUrl:
qsWithOrderBy =
if (state[OrderBy]? <> null) then
qsWithSelect & [ #"$orderby" = state[OrderBy] ]
else
qsWithSelect,
Håndtering af Table.RowCount med GetRowCount
I modsætning til de andre forespørgselshandlere, du implementerer, returnerer handleren GetRowCount en enkelt værdi – det antal rækker, der forventes i resultatsættet. I en M-forespørgsel vil denne værdi typisk være resultatet af transformationen Table.RowCount .
Du har et par forskellige muligheder for, hvordan du håndterer denne værdi som en del af en OData-forespørgsel:
- Den $count forespørgselsparameter, som returnerer antallet som et separat felt i resultatsættet.
- Stisegmentet /$count, som kun returnerer det samlede antal som en skalarværdi.
Ulempen ved tilgangen med forespørgselsparameteren er, at du stadig skal sende hele forespørgslen til OData-tjenesten. Da antallet kommer indbygget igen som en del af resultatsættet, skal du behandle den første side med data fra resultatsættet. Selvom denne proces stadig er mere effektiv end at læse hele resultatsættet og tælle rækkerne, er det sandsynligvis stadig mere arbejde, end du vil.
Fordelen ved tilgangen for stisegmentet er, at du kun modtager en enkelt skalarværdi i resultatet. Denne fremgangsmåde gør hele handlingen meget mere effektiv. Som beskrevet i OData-specifikationen returnerer stisegmentet /$count dog en fejl, hvis du inkluderer andre forespørgselsparametre, f.eks $top . eller $skip, hvilket begrænser dets anvendelighed.
I dette selvstudium implementerede du handleren GetRowCount ved hjælp af tilgangen for stisegmentet. Hvis du vil undgå de fejl, du får, hvis andre forespørgselsparametre er inkluderet, har du søgt efter andre tilstandsværdier og returneret en "ikke-implementeret fejl" (...), hvis du har fundet nogen. Hvis der returneres en fejl fra en Table.View-handler , fortæller M-programmet, at handlingen ikke kan foldes, og den bør falde tilbage til standardhandleren i stedet (hvilket i dette tilfælde tæller det samlede antal rækker).
Tilføj først en enhedstest:
// GetRowCount
Fact("Fold $count", 15, Table.RowCount(Airlines)),
/$count Da stisegmentet returnerer en enkelt værdi (i almindeligt/tekstformat) i stedet for et JSON-resultatsæt, skal du også tilføje en ny intern funktion (TripPin.Scalar) for at foretage anmodningen og håndtere resultatet.
// Similar to TripPin.Feed, but is expecting back a scalar value.
// This function returns the value from the service as plain text.
TripPin.Scalar = (url as text) as text =>
let
_url = Diagnostics.LogValue("TripPin.Scalar url", url),
headers = DefaultRequestHeaders & [
#"Accept" = "text/plain"
],
response = Web.Contents(_url, [ Headers = headers ]),
toText = Text.FromBinary(response)
in
toText;
Implementeringen bruger derefter denne funktion (hvis der ikke findes andre forespørgselsparametre i state):
GetRowCount = () as number =>
if (Record.FieldCount(Record.RemoveFields(state, {"Url", "Entity", "Schema"}, MissingField.Ignore)) > 0) then
...
else
let
newState = state & [ RowCountOnly = true ],
finalUrl = CalculateUrl(newState),
value = TripPin.Scalar(finalUrl),
converted = Number.FromText(value)
in
converted,
Funktionen CalculateUrl opdateres, så den føjes /$count til URL-adressen, hvis feltet RowCountOnly er angivet i state.
// Check for $count. If all we want is a row count,
// then we add /$count to the path value (following the entity name).
urlWithRowCount =
if (state[RowCountOnly]? = true) then
urlWithEntity & "/$count"
else
urlWithEntity,
Den nye Table.RowCount enhedstest bør nu bestå.
Hvis du vil teste fallbackcasen, skal du tilføje endnu en test, der gennemtvinger fejlen.
Først skal du tilføje en hjælpemetode, der kontrollerer resultatet af en try handling for en foldningsfejl.
// Returns true if there is a folding error, or the original record (for logging purposes) if not.
Test.IsFoldingError = (tryResult as record) =>
if ( tryResult[HasError]? = true and tryResult[Error][Message] = "We couldn't fold the expression to the data source. Please try a simpler expression.") then
true
else
tryResult;
Tilføj derefter en test, der bruger både Table.RowCount og Table.FirstN til at gennemtvinge fejlen.
// test will fail if "Fail on Folding Error" is set to false
Fact("Fold $count + $top *error*", true, Test.IsFoldingError(try Table.RowCount(Table.FirstN(Airlines, 3)))),
En vigtig bemærkning her er, at denne test nu returnerer en fejl, hvis Error on Folding Error er angivet til false, fordi handlingen Table.RowCount vender tilbage til den lokale (standard)-handler. Kørsel af testene med Error on Folding Error angivet til true medfører Table.RowCount , at der opstår fejl, og gør det muligt for testen at lykkes.
Konklusion
Implementering af Table.View for din connector føjer en betydelig mængde kompleksitet til din kode. Da M-programmet kan behandle alle transformationer lokalt, muliggør tilføjelse af Table.View-handlere ikke nye scenarier for dine brugere, men resulterer i mere effektiv behandling (og muligvis gladere brugere). En af de største fordele ved , at Table.View-handlere er valgfrie, er, at det giver dig mulighed for trinvist at tilføje ny funktionalitet uden at påvirke bagudkompatibilitet for din connector.
For de fleste connectors er OnTake en vigtig (og grundlæggende) handler, der skal implementeres (hvilket oversættes til $top i OData), da den begrænser antallet af returnerede rækker. Power Query-oplevelsen udfører altid en OnTake række, 1000 når der vises prøveversioner i navigatoren og forespørgselseditoren, så brugerne kan se betydelige forbedringer af ydeevnen, når de arbejder med større datasæt.