Forberede processer og data
Før du kan bruge funktionalitet i Process Mining i Power Automate effektivt, skal du forstå følgende:
- Datakrav.
- Hvor du kan hente logdata fra programmet.
- Hvordan du kan oprette forbindelse til en datakilde.
Her er en kort video om, hvordan du uploader data til brug med funktionalitet i Process Mining:
Datakrav
Hændelseslogge og aktivitetslogge er tabeller, der er gemt i dit system med poster, som dokumenterer, hvornår en hændelse eller aktivitet forekommer. Aktiviteter, du udfører i appen CRM (Customer Relationship Management), gemmes for eksempel som en hændelseslog i CRM-appen. Følgende felter skal udfyldes, før Process Mining kan analysere hændelseslog:
Sags-id
Sags-id'et skal repræsentere en forekomst af din proces og er ofte det objekt, som processen skal agere på. Det kan være et "patient-id" for indlæggelsesproces for en patient, et "ordre-id" for en proces til afsendelse af en ordre eller et "anmodnings-id" for en godkendelsesproces. Dette id skal være til stede for alle aktiviteter i loggen.
Aktivitetsnavn
Aktiviteter er trinnene i processen, og aktivitetsnavnene beskriver hvert trin. I en typisk godkendelsesproces kan aktivitetsnavnene være "send anmodning", "anmodning godkendt", "anmodning afvist" og "revider anmodning".
Starttidsstempel og sluttidsstempel
Tidsstempler angiver det nøjagtige tidspunkt, hvor en hændelse eller aktivitet fandt sted. Hændelseslogge har kun ét tidsstempel. Det angiver det tidspunkt, hvor en hændelse eller aktivitet indtraf i systemet. Aktivitetslogge har to tidsstempler: et starttidsstempel og et sluttidsstempel. De angiver start- og sluttidspunktet for hver hændelse eller aktivitet.
Du kan også udvide din analyse ved at indtage valgfrie attributtyper:
Ressource
En menneskelig eller teknisk ressource, der udfører en bestemt hændelse.
Attribut på hændelsesniveau
Yderligere analytisk attribut, der har en anden værdi pr. hændelse, f.eks. Afdeling, der udfører aktiviteten.
Attribut på sagsniveau (første hændelse)
Attributten på sagsniveau er en ekstra attribut, der ud fra et analytisk synspunkt anses for at have en enkelt værdi pr. sag (f.eks. Fakturabeløb i USD). Men den hændelseslog, der skal indtages, behøver ikke nødvendigvis at være overensstemmende ved at have samme værdi for den specifikke attribut for alle hændelser i hændelsesloggen. Det er f.eks. måske ikke muligt at sikre, når der bruges trinvis dataopdatering. Power Automate Process Mining indtager dataene, som de er, og lagrer alle værdier, der er angivet i hændelsesloggen, men bruger en mekanisme til fortolkning af attribut på sagsniveau til at arbejde med attributterne på sagsniveau.
Når attributten bruges til en bestemt funktion, som kræver værdier på hændelsesniveau (f.eks. filtrering på hændelsesniveau), bruger produktet med andre ord værdierne på hændelsesniveau. Når der er behov for en værdi på sagsniveau (f.eks. filter på sagsniveau og analyse af rodårsag), anvendes den fortolkede værdi, som hentes fra den kronologisk første hændelse i sagen.
Attribut på sagsniveau (sidste hændelse)
Det samme som attributten på sagsniveau (første hændelse), men når den fortolkes på sagsniveau, hentes værdien fra den kronologisk sidste hændelse i sagen.
Finansiel pr. hændelse
Fast omkostning/omsætning/numerisk værdi, der ændres pr. udført aktivitet, f.eks. omkostninger for kurerservice. Den økonomiske værdi beregnes som en sum (gennemsnit, minimum og maksimum) af de økonomiske værdier pr. hændelse.
Økonomisk pr. sag (første hændelse)
Attributten Finansiel pr. sag er en ekstra numerisk attribut, der ud fra et analytisk synspunkt anses for at have en enkelt værdi pr. sag (f.eks. Fakturabeløb i USD). Men den hændelseslog, der skal indtages, behøver ikke nødvendigvis at være overensstemmende ved at have samme værdi for den specifikke attribut for alle hændelser i hændelsesloggen. Det er f.eks. måske ikke muligt at sikre, når der bruges trinvis dataopdatering. Power Automate Process Mining indtager dataene, som de er, og gemmer alle de værdier, der er angivet i hændelsesloggen. Men der bruges en mekanisme kaldet fortolkning af attribut på sagsniveau til at arbejde med attributterne på sagsniveau.
Når attributten bruges til en bestemt funktion, som kræver værdier på hændelsesniveau (f.eks. filtrering på hændelsesniveau), bruger produktet med andre ord værdierne på hændelsesniveau. Når der er behov for en værdi på sagsniveau (f.eks. filter på sagsniveau og analyse af rodårsag), anvendes den fortolkede værdi, som hentes fra den kronologisk første hændelse i sagen.
Økonomisk pr. sag (sidste hændelse)
Det samme som Økonomisk pr. sag (første hændelse), men når den fortolkes på sagsniveau, hentes værdien fra den kronologisk sidste hændelse i sagen.
Hvor du kan hente logdata fra programmet
Funktionalitet i Process Mining skal bruge hændelseslogdata for at udføre procesforløb. Selvom mange tabeller, der findes i programmets database, indeholder dataenes aktuelle tilstand, indeholder de muligvis ikke en historisk oversigt over de hændelser, der er sket, som er det påkrævede hændelseslogformat. Heldigvis gemmes denne historikoversigt eller log ofte i en specifik tabel i mange større programmer. Denne oversigt gemmes for eksempel i tabellen Aktiviteter i mange Dynamics-programmer. Andre programmer, for eksempel SAP eller Salesforce, har lignende begreber, men navnet kan være forskelligt.
I disse tabeller, hvor der logføres historikoversigter, kan den datastruktur være kompleks. Det kan være nødvendigt at oprette forbindelse mellem logtabellen og andre tabeller i programdatabasen for at få bestemte id'er eller navne. Det er heller ikke alle de hændelser, du er interesseret i, der logføres. Det kan være nødvendigt at beslutte, hvilke hændelser der skal bevares eller filtreres ud. Hvis du har brug for hjælp, skal du kontakte det it-team, der administrerer dette program, for at få mere at vide.
Oprette forbindelse til en datakilde
Fordelen ved at oprette direkte forbindelse til en database er at holde procesrapporten opdateret med de seneste data fra datakilden.
Power Query understøtter en lang række connectorer, der gør det muligt for funktionalitet i Process Mining at oprette forbindelse til og importere data fra den tilsvarende datakilde. Almindelige connectorer omfatter Tekst/CSV, Microsoft Dataverse og SQL Server-databasen. Hvis du bruger et program som for eksempel SAP eller Salesforce, kan du muligvis oprette direkte forbindelse til disse datakilder via deres connectorer. Du kan finde oplysninger om understøttede connectorer, og hvordan du bruger dem, ved at gå til Connectorer i Power Query.
Afprøve funktionalitet i Process Mining med Tekst/CSV-connectoren
En nem måde at afprøve funktionalitet i Process Mining på, uanset hvor din datakilde er placeret, er ved hjælp af Tekst/CSV-connectoren. Du skal muligvis have hjælp fra din databaseadministrator til at at eksportere et lille eksempel fra hændelsesloggen som en CSV-fil. Når du har CSV-filen, kan du importere den til funktionalitet i Process Mining ved hjælp af følgende trin i skærmbilledet til valg af datakilde.
Bemærk
Du skal have OneDrive for Business for at kunne bruge Tekst/CSV-connectoren. Hvis du ikke har OneDrive for Business, skal du overveje at bruge Tom tabel i stedet for Tekst/CSV som i følgende trin 3. Du kan ikke importere så mange poster i Tom tabel.
Opret en proces på Process Mining-startsiden ved at vælge Start her.
Angiv et procesnavn, og vælg Opret.
Vælg Alle kategorier>Tekst/CSV på skærmbilledet Vælg datakilde.
Vælg Gennemse OneDrive. Det kan være nødvendigt at godkende.
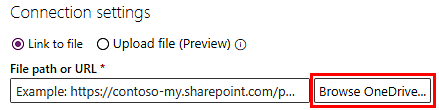
Overfør hændelsesloggen ved at vælge ikonet Upload øverst til højre og derefter vælge Filer.
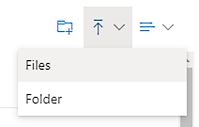
Upload hændelsesloggen, vælg filen på listen, og vælg derefter Åbn for at bruge den fil.
Brug af dataflow-connectoren
Dataflow-connectoren understøttes ikke i Microsoft Power Platform. Det eksisterende dataflow kan ikke bruges som en datakilde til Power Automate procesmining.
Bruge Dataverse-connectoren
Dataverse-connectoren understøttes ikke i Microsoft Power Platform. Du skal oprette forbindelse til den ved hjælp af OData-connectoren, hvilket kræver lidt flere trin.
Kontrollér, at du har adgang til Dataverse-miljøet.
Du skal bruge miljø-URL-adressen for det Dataverse-miljø, du forsøger at oprette forbindelse til. Normalt ser det sådan ud:
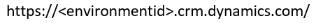
Du kan få mere at vide om, hvordan du finder URL-adressen, ved at gå til Søge efter URL-adressen til dit Dataverse-miljø.
På skærmen Power Query – Vælg datakilder skal du vælge OData.
Skriv api/data/v9.2 i slutningen af URL-adressen i tekstfeltet til URL-adressen, så den ser sådan ud:
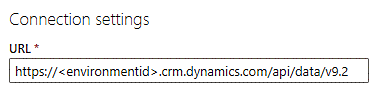
Vælg Organisationskonto i feltet Godkendelsestype under Forbindelseslegitimationsoplysninger.
Vælg Log på, og angiv dine legitimationsoplysninger.
Vælg Næste.
Udvid mappen OData. Du bør kunne se alle Dataverse-tabellerne i det pågældende miljø. Som et eksempel kaldes tabellen Aktiviteter for activitypointers.
Markér afkrydsningsfeltet ud for den tabel, du vil importere, og vælg derefter Næste.