Oversigt over Analyse af rodårsag
Med Analyse af rodårsag (RCA) kan du finde skjulte forbindelser i dataene. Det hjælper dig f.eks. med at forstå, hvorfor det tager længere tid at fuldføre nogle sager end andre, eller hvorfor nogle sager bliver hængende i redigeringsarbejde, mens andre kører problemfrit. I RCA får du vist de vigtigste forskelle mellem disse sager.
Påkrævede data
RCA kan bruge alle dine attributter, metrikker og brugerdefinerede metrikker på sagsniveau til at finde forbindelser mellem dem og en metrik, du vælger.
Det bedste eksempel er at inkludere alle data, du kan, som attribut på sagsniveau, og lade RCA vælge, hvilken attribut der rent faktisk påvirker metrikværdien, og hvilken der ikke gør.
Sådan virker RCA
RCA-algoritmen beregner en træstruktur, hvor de enkelte noder opdeler datasæt i to mindre dele. Dette er baseret på én variabel, hvor den finder den bedste korrelation mellem variabelfordelingen og målmetrikken. Her kan du se de skjulte forbindelser i dataene. Her kan du se, hvilken kombination af attributter der har indflydelse på sagen på hvilken måde.
Sådan finder RCA den bedste opdeling
Først skal du oprette hundredvis til tusindvis af kombinationer af mulige opdelinger. Derefter forsøger vi at opdele dem hver for at finde ud af, hvor godt de rent faktisk deler datasættet i to dele. Vi beregner variansen af hovedmetrikværdien i hver del af opdelingen, og resultatet beregnes for hver opdeling med følgende beregning:
scoredel_x = variansvenstre * antal sagervenstre + varianshøjre * antal sagerhøjre
Derefter sorterer vi alle opdelinger efter denne score, og de bedste opdelinger tages fra starten med den laveste score. For den kategoriske hovedmetrikværdi (streng) beregnes Gini impurity i stedet for varighed.
RCA-eksempel
I dette eksempel vil vi se den grundlæggende årsag bag sagens varighed. I dataene har vi attributter på sagsniveau, leverandørland, leverandørby, materiale, samlet beløb og omkostningssted. Den gennemsnitlige sagsvarighed er 46 timer.
Når vi ser på hver enkelt værdi af hver attribut separat, kan vi se, at den største indflydelse på sagsvarigheden er, når leverandørby er Graz, der i gennemsnit øger sagens varighed med yderligere 15 timer. Fra denne indledende analyse kan vi se, at de andre attributter påvirker målmetrikværdien langt mindre. Men når vi beregner træmodellen, kan vi se, at ovenstående beregning er vildledende (som på følgende skærmbillede).
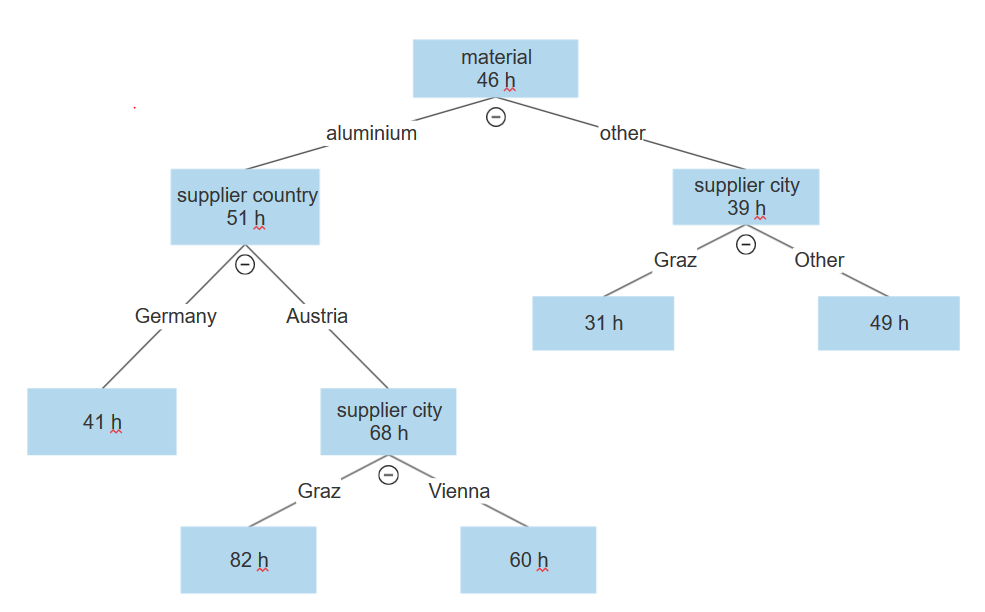
Træstrukturen ser således ud:
Den første opdeling er dataene langs variablen materiale. Dataene med aluminium er på den ene side, og alle andre materialer findes på den anden side.
Grenen aluminium opdeles yderligere efter leverandørland i Tyskland og Østrig.
Grenen Østrig fortsætter med en opdeling efter leverandørby med Graz på den ene side og Wien på den anden.
I noden Graz var den gennemsnitlige sag 36 timer langsommere end den samlede gennemsnitlige varighed på 46 timer.
I det samme træ kan vi se, at hvis vi har et andet materiale end aluminium, opdeles det også efter variablen leverandørby, hvor den ene side er Graz, og den anden side er Wien, München eller Frankfurt. Men her er værdierne modsat. Graz har meget bedre statistik end Wien eller en hvilken som helst tysk by, hvor den gennemsnitlige sag i Graz er 15 timer hurtigere end det samlede gennemsnit for alle sager.
Ud fra dette kan vi se, at de første statistiske data er misvisende, fordi Graz præsterer dårligt, når materialet er aluminium, men præsterer over gennemsnittet, når materialet er andet end aluminium, og det er stik modsat for andre byer.
Påvirkning af sagsvarighed tager kun højde for én værdi, og det kan være misvisende. RCA tager højde for kombinationer af dem for at give dig et bedre indblik i din proces.