Kopiere Dataverse-data til Azure SQL
Brug Azure Synapse Link til at knytte dine Microsoft Dataverse-data til Azure Synapse Analytics for at undersøge dine data og få hurtigere tid til indsigt. I denne artikel vises, hvordan du kører Azure Synapse-pipelines eller Azure Data Factory for at kopiere data fra Azure Data Lake Storage Gen2 til en Azure SQL Database, hvor trinvise opdateringer er aktiveret i Azure Synapse Link.
Bemærk
Azure Synapse Link for Microsoft Dataverse var tidligere kendt som Eksportér til data lake. Tjenesten blev omdøbt til maj 2021 og vil fortsat eksportere data til både Azure Data Lake og Azure Synapse Analytics. Skabelonen er en kodeprøve. Vi opfordrer dig til at bruge denne skabelon som vejledning til at teste funktionaliteten ved hentning af data fra Azure Data Lake Storage Gen2 til Azure SQL Database ved hjælp af den medfølgende pipeline.
Forudsætninger
- Azure Synapse Link for Dataverse. I denne vejledning antages det, at du allerede har opfyldt forudsætningerne for at oprette en Azure Synapse Link med Azure Data Lake. Flere oplysninger: Forudsætninger for en Azure Synapse Link for Dataverse med din Azure Data Lake
- Opret et Azure Synapse workspace eller Azure Data Factory under den samme Microsoft Entra-lejer som din Power Apps-lejer.
- Opret en Azure Synapse Link for Dataverse, hvor den trinvise mappeopdatering er aktiveret til at angive tidsintervallet. Flere oplysninger: Forespørg og analysér de trinvise opdateringer
- Microsoft.EventGrid-udbyderen skal registreres som udløser. Flere oplysninger: Azure Portal. Bemærk! Hvis du bruger denne funktion i Azure Synapse Analytics, skal du kontrollere, at dit abonnement også er registreret hos ressourceudbyderen af Data Factory. Ellers får du en fejlmeddelelse om, at oprettelsen af et "Hændelsesabonnement" ikke lykkedes.
- Opret en Azure SQL-database med egenskaben Tillad, at Azure-tjenester og -ressourcer får adgang til denne server aktiveret. Flere oplysninger: Hvad skal jeg vide, når jeg konfigurerer min Azure SQL Database (PaaS)?
- Opret og konfigurer en Azure-integrationskørsel. Flere oplysninger: Oprette Azure-integrationskørsel – Azure Data Factory & Azure Synapse
Vigtigt
Hvis du bruger skabelonen, kan det medføre ekstra omkostninger. Disse omkostninger er relateret til brugen af Azure Data Factory- eller Synapse-arbejdsområdepipelinen og faktureres månedligt. Omkostningerne ved at bruge pipelines afhænger primært af tidsintervallet for trinvis opdatering og dataenhederne. Hvis du vil planlægge og administrere omkostningerne ved at bruge denne funktion, skal du gå til: Overvåge omkostninger på pipelineniveau med omkostningsanalyse
Det er vigtigt at tage højde for disse ekstra omkostninger, når du beslutter dig for at bruge skabelonen, da de ikke er valgfrie og skal betales for at fortsætte med at bruge denne funktion.
Bruge løsningsskabelonen
- Gå til Azure-portalen, og åbn Azure Synapse workspace.
- Vælg Integrer > Gennemse galleri.
- Vælg Kopiér Dataverse-data til Azure SQL ved hjælp af Synapse Link fra integrationsgalleriet.
Konfigurere løsningsskabelonen
Opret en tilknyttet tjeneste til Azure Data Lake Storage Gen2, som er forbundet med Dataverse via den rette godkendelsestype. Det kan du gøre ved at vælge Test forbindelse for at validere forbindelsen og derefter vælge Opret.
På samme måde som i de foregående trin skal du oprette en tilknyttet tjeneste til Azure SQL Database, hvor Dataverse-data synkroniseres.
Vælg Brug denne skabelon, når Input er konfigureret.
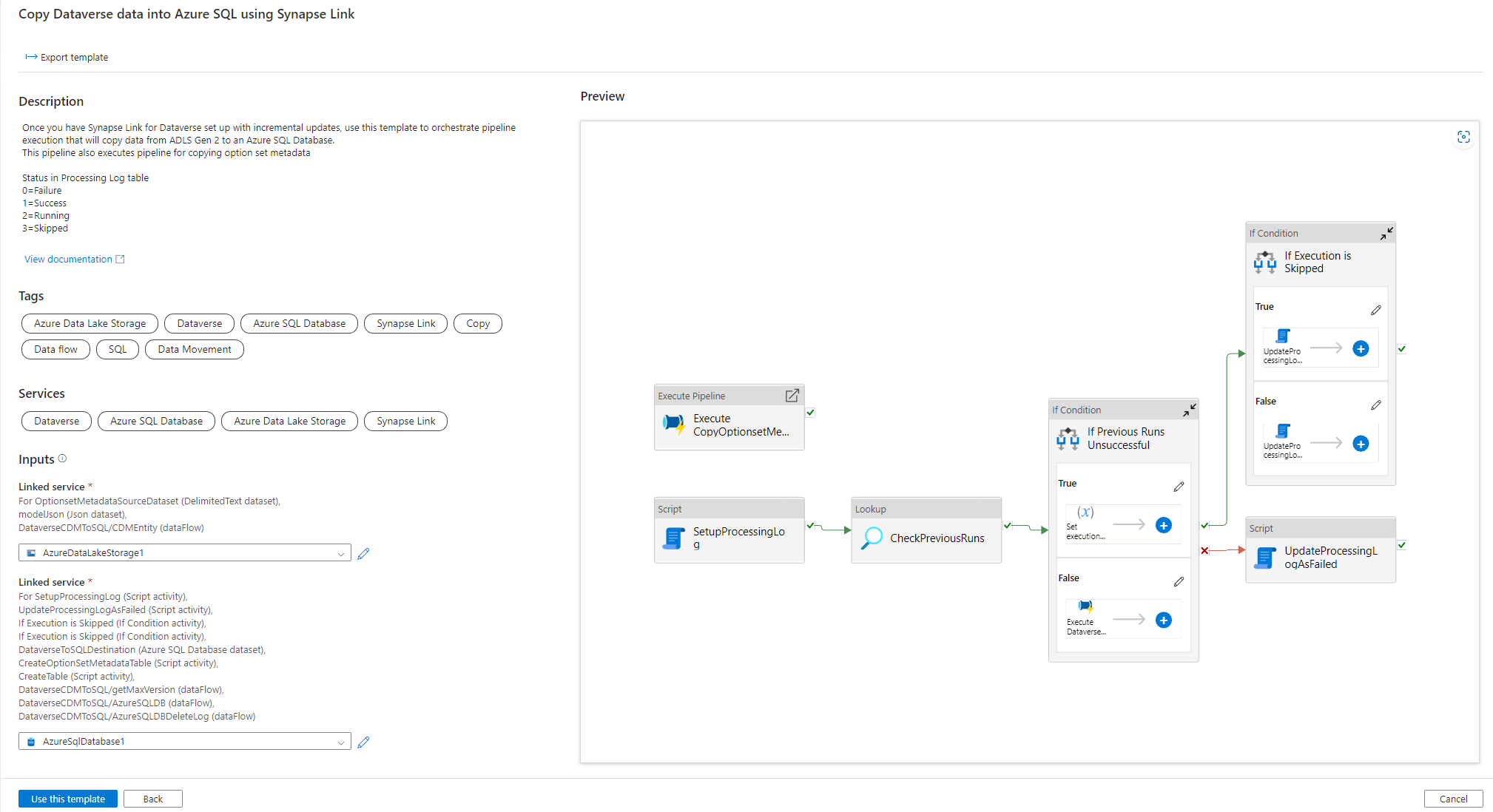
Nu kan der tilføjes en udløser for at automatisere denne pipeline, så pipelinen altid kan behandle filer, når trinvise opdateringer fuldføres jævnligt. Gå til Administrer > Udløser, og opret en udløser ved hjælp af følgende egenskaber:
- Navn: Angiv et navn til udløseren, f.eks triggerModelJson.
- Type: Lagerhændelser.
- Azure-abonnement: Vælg det abonnement, der har Azure Data Lake Storage Gen2.
- Navn på lagerkonto: Vælg det lager, der har Dataverse-data.
- Beholdernavn: Vælg den beholder, der oprettes af Azure Synapse Link.
- Blob-sti slutter med: /model.json
- Hændelse: Blob oprettet.
- Ignorer tomme blobs: Ja.
- Start udløser: Aktivér Start udløser ved oprettelse.
Vælg Fortsæt for at fortsætte til næste skærm.
På det næste skærmbillede valideres de matchende filer af udløseren. Vælg OK for at oprette udløseren.
Knyt udløseren til en pipeline. Gå til den pipeline, der er importeret tidligere, og vælg derefter Tilføj udløser > Ny/Rediger.
Vælg udløseren i det tidligere trin, og vælg derefter Fortsæt for at gå til det næste skærmbillede, hvor udløseren validerer de matchende filer.
Vælg Fortsæt for at fortsætte til næste skærm.
Angiv nedenstående parametre i sektionen Kørselsparameter for udløser, og vælg derefter OK.
- Beholder:
@split(triggerBody().folderPath,'/')[0] - Mappe:
@split(triggerBody().folderPath,'/')[1]
- Beholder:
Vælg Valider alle, når du har knyttet udløseren til pipelinen.
Når valideringen er gennemført, skal du vælge Publicer alle.
Hvis du vil publicere alle ændringer, skal du vælge Publicer.



Tilføje et filter for et hændelsesabonnement
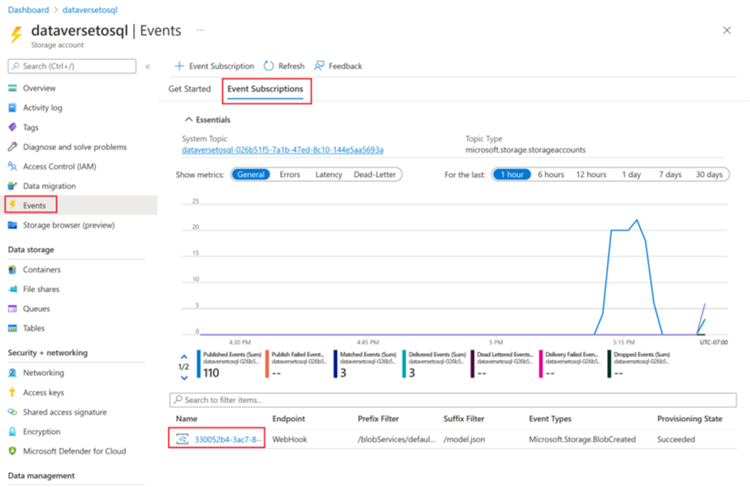
For at sikre, at udløseren kun aktiveres, når oprettelsen af model.json er fuldført, skal avancerede filtre opdateres for udløserens hændelsesabonnement. Der registreres en hændelse mod lagerkontoen, første gang udløseren køres.
Når en kørsel af udløseren er fuldført, skal du gå til lagerkontoen > Hændelser > Hændelsesabonnementer.
Vælg den hændelse, der er registreret for udløseren model.json.
Vælg fanen Filtre, og vælg derefter Tilføj nyt filter.
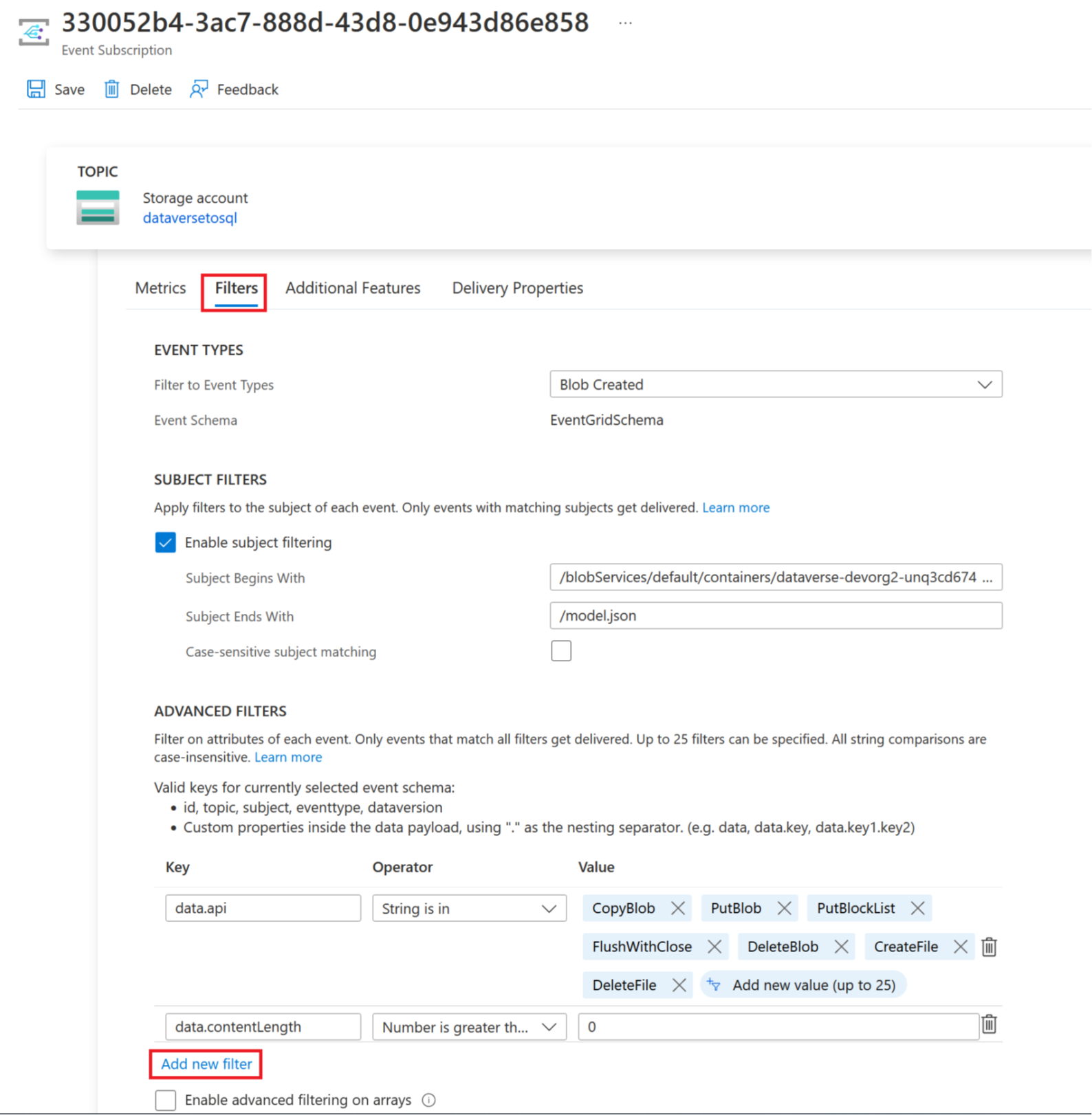
Opret filteret:
- Nøgle: emne
- Operator: Streng slutter ikke med
- Værdi: /blobs/model.json
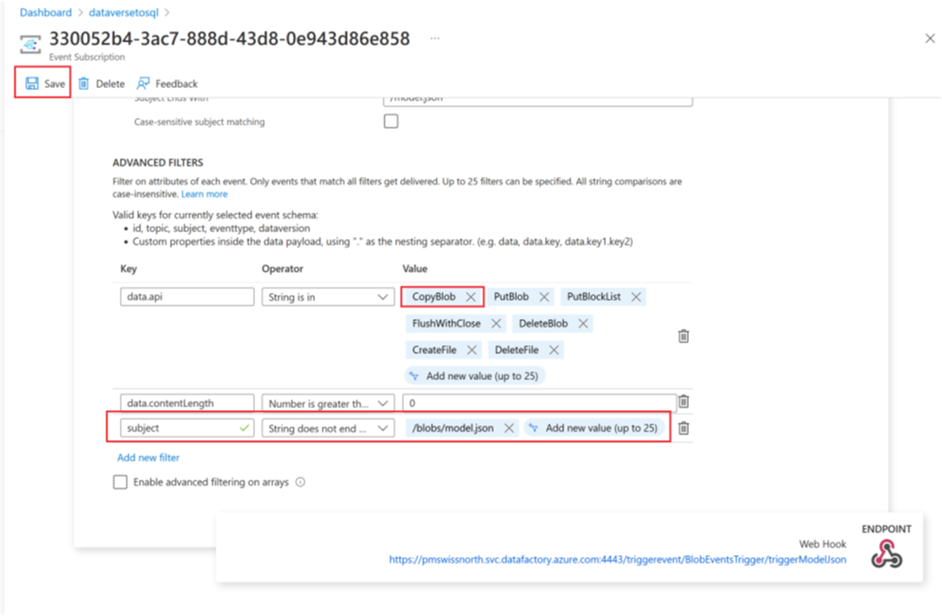
Fjern parameteren CopyBlob fra data.api-matrixen Value.
Vælg Gem for at udrulle det ekstra filter.
Se også
Blog: Annoncerer Azure Synapse Link for Dataverse
Bemærk
Kan du fortælle os om dine sprogpræferencer for dokumentation? Tag en kort undersøgelse. (bemærk, at denne undersøgelse er på engelsk)
Undersøgelsen tager ca. syv minutter. Der indsamles ingen personlige data (erklæring om beskyttelse af personlige oplysninger).