Multivariat registrering af uregelmæssigheder
Du kan få generelle oplysninger om registrering af flerdimensionel uregelmæssigheder i realtidsintelligens under Multivariér registrering af uregelmæssigheder i Microsoft Fabric – oversigt. I dette selvstudium skal du bruge eksempeldata til at oplære en flerdimensionel model til registrering af uregelmæssigheder ved hjælp af Spark-programmet i en Python-notesbog. Du forudsiger derefter uregelmæssigheder ved at anvende den oplærte model på nye data ved hjælp af Eventhouse-programmet. De første par trin konfigurerer dine miljøer, og følgende trin oplærer modellen og forudsiger uregelmæssigheder.
Forudsætninger
- Et arbejdsområde med en Microsoft Fabric-aktiveret kapacitet
- Rolle som administrator, bidragyder eller medlemi arbejdsområdet. Dette tilladelsesniveau er nødvendigt for at oprette elementer, f.eks. et miljø.
- Et eventhouse i dit arbejdsområde med en database.
- Download eksempeldataene fra GitHub-lageret
- Download notesbogen fra GitHub-lageret
Del 1 – Aktivér OneLake-tilgængelighed
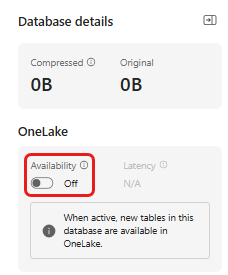
OneLake-tilgængelighed skal aktiveres, før du får data i Eventhouse. Dette trin er vigtigt, da det gør det muligt for de data, du indtager, at blive tilgængelige i OneLake. På et senere trin får du adgang til de samme data fra din Spark-notesbog for at oplære modellen.
Vælg det eventhouse, du har oprettet i forudsætningerne, i dit arbejdsområde. Vælg den database, hvor du vil gemme dataene.
I ruden Databaseoplysninger skal du slå knappen Tilgængelighed af OneLake til for at På.
Del 2 – Aktivér KQL Python-plug-in
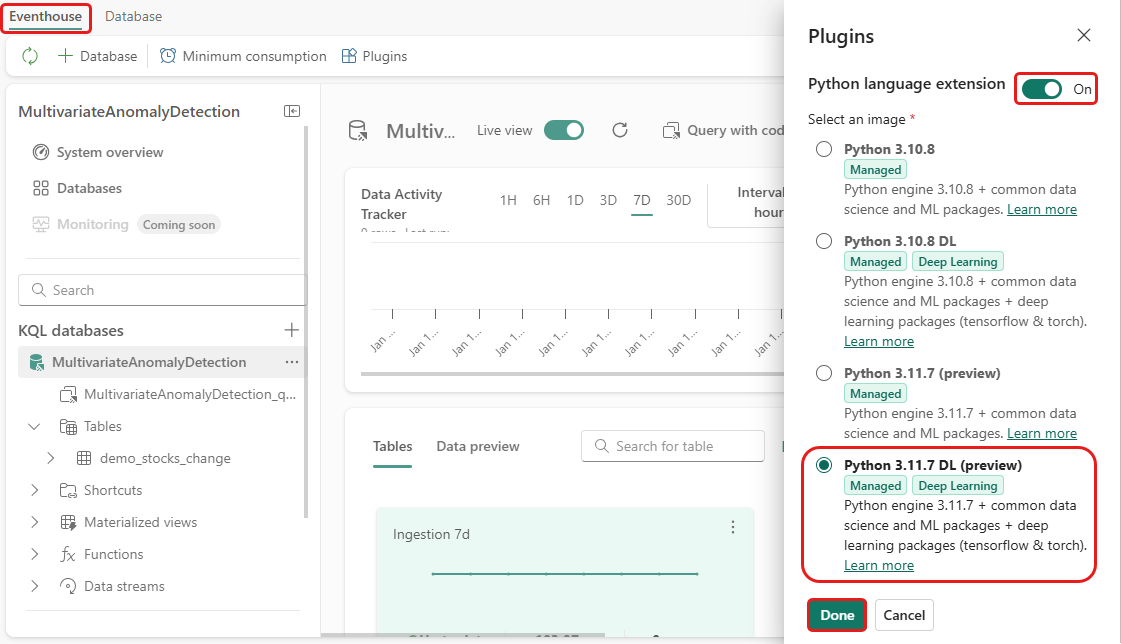
I dette trin skal du aktivere Python-plug-in'en i dit Eventhouse. Dette trin er påkrævet for at køre Python-koden for forudsagte uregelmæssigheder i KQL-forespørgselssættet. Det er vigtigt at vælge det korrekte billede, der indeholder pakken time-series-anomaly-detector.
På skærmen Eventhouse skal du vælge Eventhouse>Plugins på båndet.
I ruden Plug-ins skal du slå Python-sprogudvidelsen til Til.
Vælg Python 3.11.7 DL (prøveversion).
Vælg Udført.

Del 3 – Opret et Spark-miljø
I dette trin skal du oprette et Spark-miljø for at køre Python-notesbogen, der oplærer modellen til registrering af flerdimensionel uregelmæssigheder ved hjælp af Spark-programmet. Du kan få mere at vide om oprettelse af miljøer under Opret og administrer miljøer.
Vælg + Nyt element i dit arbejdsområde derefter Miljø.
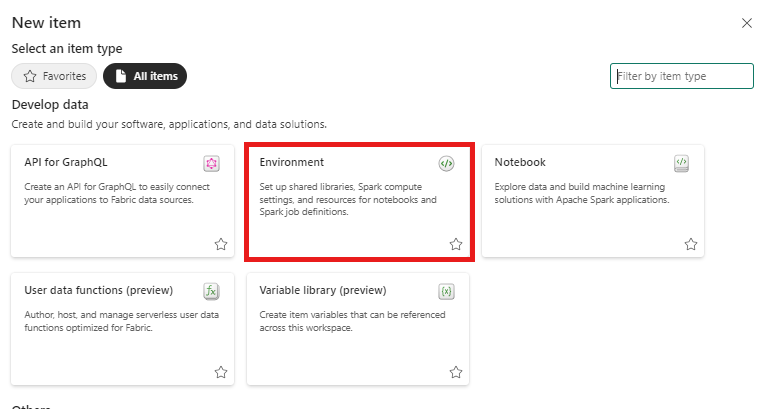
Angiv navnet MVAD_ENV for miljøet, og vælg derefter Opret.
Vælg Runtime>1.2 (Spark 3.4, Delta 2.4)på fanen Home i miljøet.
Under Biblioteker skal du vælge Offentlige biblioteker.
Vælg Tilføj fra PyPI.
Angiv time-series-anomaly-detector i søgefeltet. Versionen udfyldes automatisk med den nyeste version. Dette selvstudium blev oprettet i version 0.3.2.
Vælg Gem.

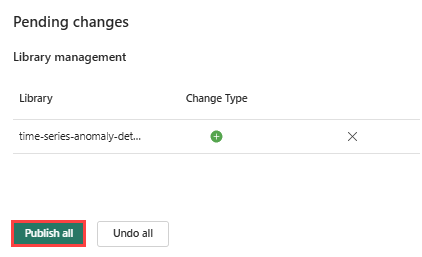
Vælg fanen Hjem i miljøet.
Vælg ikonet Publicer på båndet.

Vælg Publicer alle. Dette trin kan tage flere minutter at fuldføre.


Del 4 – Hent data i Eventhouse
Peg på den KQL-database, hvor du vil gemme dine data. Vælg menuen Flere [...]>Hent data>Lokal fil.
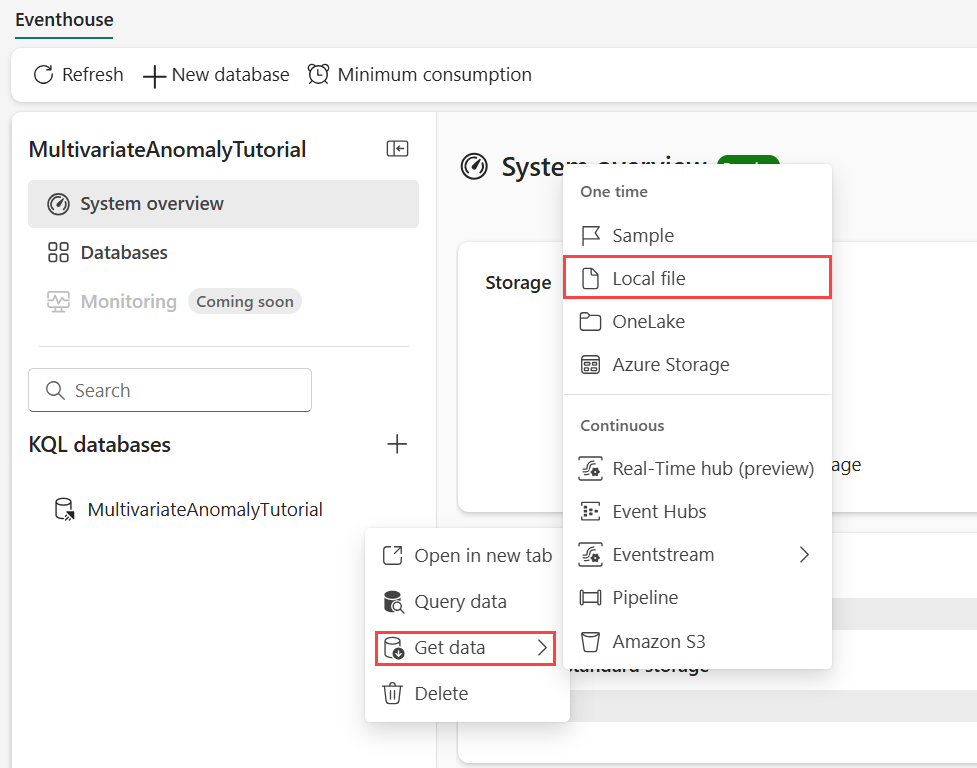
Vælg + Ny tabel , og angiv demo_stocks_change som tabelnavn.
I dialogboksen Upload data skal du vælge Søg efter filer og uploade den eksempeldatafil, der blev downloadet i Forudsætninger
Vælg Næste.
I afsnittet Undersøg data skal du skifte Første række er kolonneoverskrift til Til.
Vælg Udfør.
Når dataene uploades, skal du vælge Luk.
Del 5 – Kopiér OneLake-stien til tabellen
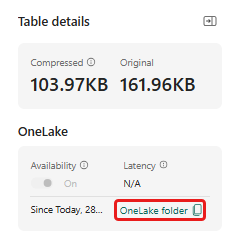
Sørg for at vælge tabellen demo_stocks_change . I ruden Tabeldetaljer skal du vælge OneLake-mappe for at kopiere OneLake-stien til udklipsholderen. Gem denne kopierede tekst i en teksteditor et sted, der skal bruges i et senere trin.
Del 6 – Forbered notesbogen
Vælg dit arbejdsområde.
Vælg Importér, Notesbog og derefter Fra denne computer.
Vælg Upload, og vælg den notesbog, du har downloadet, i forudsætningerne.
Når notesbogen er uploadet, kan du finde og åbne din notesbog fra dit arbejdsområde.
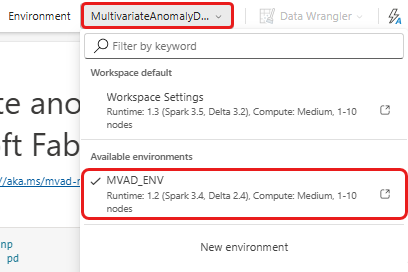
Vælg standardrullemenuen Arbejdsområde på det øverste bånd, og vælg det miljø, du oprettede i forrige trin.
Del 7 – Kør notesbogen
Importér standardpakker.
import numpy as np import pandas as pdSpark skal bruge en ABFSS URI for at oprette sikker forbindelse til OneLake-lageret, så det næste trin definerer denne funktion for at konvertere OneLake URI til ABFSS URI.
def convert_onelake_to_abfss(onelake_uri): if not onelake_uri.startswith('https://'): raise ValueError("Invalid OneLake URI. It should start with 'https://'.") uri_without_scheme = onelake_uri[8:] parts = uri_without_scheme.split('/') if len(parts) < 3: raise ValueError("Invalid OneLake URI format.") account_name = parts[0].split('.')[0] container_name = parts[1] path = '/'.join(parts[2:]) abfss_uri = f"abfss://{container_name}@{parts[0]}/{path}" return abfss_uriErstat pladsholderen OneLakeTableURI- med din OneLake URI, der er kopieret fra del 5– Kopiér OneLake-sti til tabellen for at indlæse demo_stocks_change tabel i en pandas-dataramme.
onelake_uri = "OneLakeTableURI" # Replace with your OneLake table URI abfss_uri = convert_onelake_to_abfss(onelake_uri) print(abfss_uri)df = spark.read.format('delta').load(abfss_uri) df = df.toPandas().set_index('Date') print(df.shape) df[:3]Kør følgende celler for at forberede trænings- og forudsigelsesdatarammerne.
Bemærk
De faktiske forudsigelser køres på data af Eventhouse i del 9 – Predict-anomalies-in-the-kql-queryset. Hvis du i et produktionsscenarie streamede data til hændelseshuset, ville forudsigelserne blive foretaget på de nye streamingdata. Med henblik på selvstudiet er datasættet opdelt efter dato i to afsnit til oplæring og forudsigelse. Dette er for at simulere historiske data og nye streamingdata.
features_cols = ['AAPL', 'AMZN', 'GOOG', 'MSFT', 'SPY'] cutoff_date = pd.to_datetime('2023-01-01')train_df = df[df.Date < cutoff_date] print(train_df.shape) train_df[:3]train_len = len(train_df) predict_len = len(df) - train_len print(f'Total samples: {len(df)}. Split to {train_len} for training, {predict_len} for testing')Kør cellerne for at oplære modellen, og gem den i registreringsdatabasen for Fabric MLflow-modeller.
import mlflow from anomaly_detector import MultivariateAnomalyDetector model = MultivariateAnomalyDetector()sliding_window = 200 param s = {"sliding_window": sliding_window}model.fit(train_df, params=params)with mlflow.start_run(): mlflow.log_params(params) mlflow.set_tag("Training Info", "MVAD on 5 Stocks Dataset") model_info = mlflow.pyfunc.log_model( python_model=model, artifact_path="mvad_artifacts", registered_model_name="mvad_5_stocks_model", )Kør følgende celle for at udtrække den registrerede modelsti, der skal bruges til forudsigelse, ved hjælp af Kusto Python-sandkassen.
mi = mlflow.search_registered_models(filter_string="name='mvad_5_stocks_model'")[0] model_abfss = mi.latest_versions[0].source print(model_abfss)Kopiér model-URI'en fra det sidste celleoutput til brug i et senere trin.
Del 8 – Konfigurer dit KQL-forespørgselssæt
Du kan få generelle oplysninger under Opret et KQL-forespørgselssæt.
- Vælg +Nyt element>KQL-forespørgselssæti dit arbejdsområde.
- Angiv navnet MultivariateAnomalyDetectionTutorial, og vælg derefter Opret.
- I vinduet OneLake-datahub skal du vælge den KQL-database, hvor du har gemt dataene.
- Vælg Opret forbindelse.
Del 9 – Forudsig uregelmæssigheder i KQL-forespørgselssættet
Kør følgende forespørgsel '.create-or-alter function' for at definere den
predict_fabric_mvad_fl()gemte funktion:.create-or-alter function with (folder = "Packages\\ML", docstring = "Predict MVAD model in Microsoft Fabric") predict_fabric_mvad_fl(samples:(*), features_cols:dynamic, artifacts_uri:string, trim_result:bool=false) { let s = artifacts_uri; let artifacts = bag_pack('MLmodel', strcat(s, '/MLmodel;impersonate'), 'conda.yaml', strcat(s, '/conda.yaml;impersonate'), 'requirements.txt', strcat(s, '/requirements.txt;impersonate'), 'python_env.yaml', strcat(s, '/python_env.yaml;impersonate'), 'python_model.pkl', strcat(s, '/python_model.pkl;impersonate')); let kwargs = bag_pack('features_cols', features_cols, 'trim_result', trim_result); let code = ```if 1: import os import shutil import mlflow model_dir = 'C:/Temp/mvad_model' model_data_dir = model_dir + '/data' os.mkdir(model_dir) shutil.move('C:/Temp/MLmodel', model_dir) shutil.move('C:/Temp/conda.yaml', model_dir) shutil.move('C:/Temp/requirements.txt', model_dir) shutil.move('C:/Temp/python_env.yaml', model_dir) shutil.move('C:/Temp/python_model.pkl', model_dir) features_cols = kargs["features_cols"] trim_result = kargs["trim_result"] test_data = df[features_cols] model = mlflow.pyfunc.load_model(model_dir) predictions = model.predict(test_data) predict_result = pd.DataFrame(predictions) samples_offset = len(df) - len(predict_result) # this model doesn't output predictions for the first sliding_window-1 samples if trim_result: # trim the prefix samples result = df[samples_offset:] result.iloc[:,-4:] = predict_result.iloc[:, 1:] # no need to copy 1st column which is the timestamp index else: result = df # output all samples result.iloc[samples_offset:,-4:] = predict_result.iloc[:, 1:] ```; samples | evaluate python(typeof(*), code, kwargs, external_artifacts=artifacts) }Kør følgende forudsigelsesforespørgsel, hvor outputmodel-URI'en erstattes med den URI, der blev kopieret i slutningen af trin 7.
Forespørgslen registrerer flerdimensionale uregelmæssigheder i de fem lagre baseret på den oplærte model og gengiver resultaterne som
anomalychart. De uregelmæssige punkter gengives på den første aktie (AAPL), selvom de repræsenterer flerdimensionelle uregelmæssigheder (med andre ord uregelmæssigheder i forbindelse med de fælles ændringer af de fem lagre på den specifikke dato).let cutoff_date=datetime(2023-01-01); let num_predictions=toscalar(demo_stocks_change | where Date >= cutoff_date | count); // number of latest points to predict let sliding_window=200; // should match the window that was set for model training let prefix_score_len = sliding_window/2+min_of(sliding_window/2, 200)-1; let num_samples = prefix_score_len + num_predictions; demo_stocks_change | top num_samples by Date desc | order by Date asc | extend is_anomaly=bool(false), score=real(null), severity=real(null), interpretation=dynamic(null) | invoke predict_fabric_mvad_fl(pack_array('AAPL', 'AMZN', 'GOOG', 'MSFT', 'SPY'), // NOTE: Update artifacts_uri to model path artifacts_uri='enter your model URI here', trim_result=true) | summarize Date=make_list(Date), AAPL=make_list(AAPL), AMZN=make_list(AMZN), GOOG=make_list(GOOG), MSFT=make_list(MSFT), SPY=make_list(SPY), anomaly=make_list(toint(is_anomaly)) | render anomalychart with(anomalycolumns=anomaly, title='Stock Price Changest in % with Anomalies')
Det resulterende anomalidiagram skal ligne følgende billede:

Fjerne ressourcer
Når du er færdig med selvstudiet, kan du slette de ressourcer, du har oprettet, for at undgå at påføre andre omkostninger. Følg disse trin for at slette ressourcerne:
- Gå til startsiden for dit arbejdsområde.
- Slet det miljø, der er oprettet i dette selvstudium.
- Slet den notesbog, der er oprettet i dette selvstudium.
- Slet det Eventhouse eller den database, der bruges i dette selvstudium.
- Slet det KQL-forespørgselssæt, der er oprettet i dette selvstudium.