Hent data fra Eventstream
I denne artikel lærer du, hvordan du henter data fra en eksisterende hændelsesstream til enten en ny eller eksisterende tabel.
Hvis du vil hente data fra en ny hændelsesstream, skal du se Hent data fra en ny hændelsesstream.
Forudsætninger
- Et arbejdsområde med en Microsoft Fabric-aktiveret -kapacitet
- En KQL-database med redigeringstilladelser
- En hændelsesstream med en datakilde
Kilde
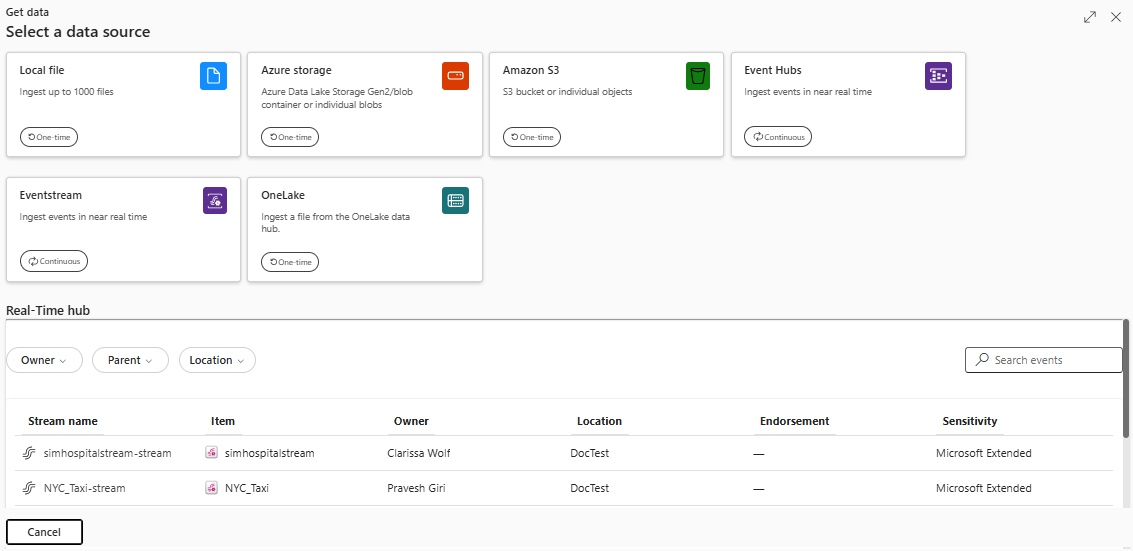
Hvis du vil hente data fra en hændelsesstream, skal du vælge eventstreamen som din datakilde. Du kan vælge en eksisterende hændelsesstream på følgende måder:
På det nederste bånd i din KQL-database skal du enten:
Vælg derefter Eventstream>Existing Eventstreamunder Continuousi rullemenuen Hent data .
Vælg Hent data, og vælg derefter Eventstreami vinduet Hent data .
Vælg Real-Time datahub>Eksisterende Eventstream-under Fortløbendei rullemenuen Hent data .

Konfigurere
Vælg en destinationstabel. Hvis du vil overføre data til en ny tabel, skal du vælge + Ny tabel og angive et tabelnavn.
Seddel
Tabelnavne kan indeholde op til 1024 tegn, herunder mellemrum, alfanumeriske tegn, bindestreger og understregningstegn. Specialtegn understøttes ikke.
Under Konfigurer datakildenskal du udfylde indstillingerne ved hjælp af oplysningerne i følgende tabel:
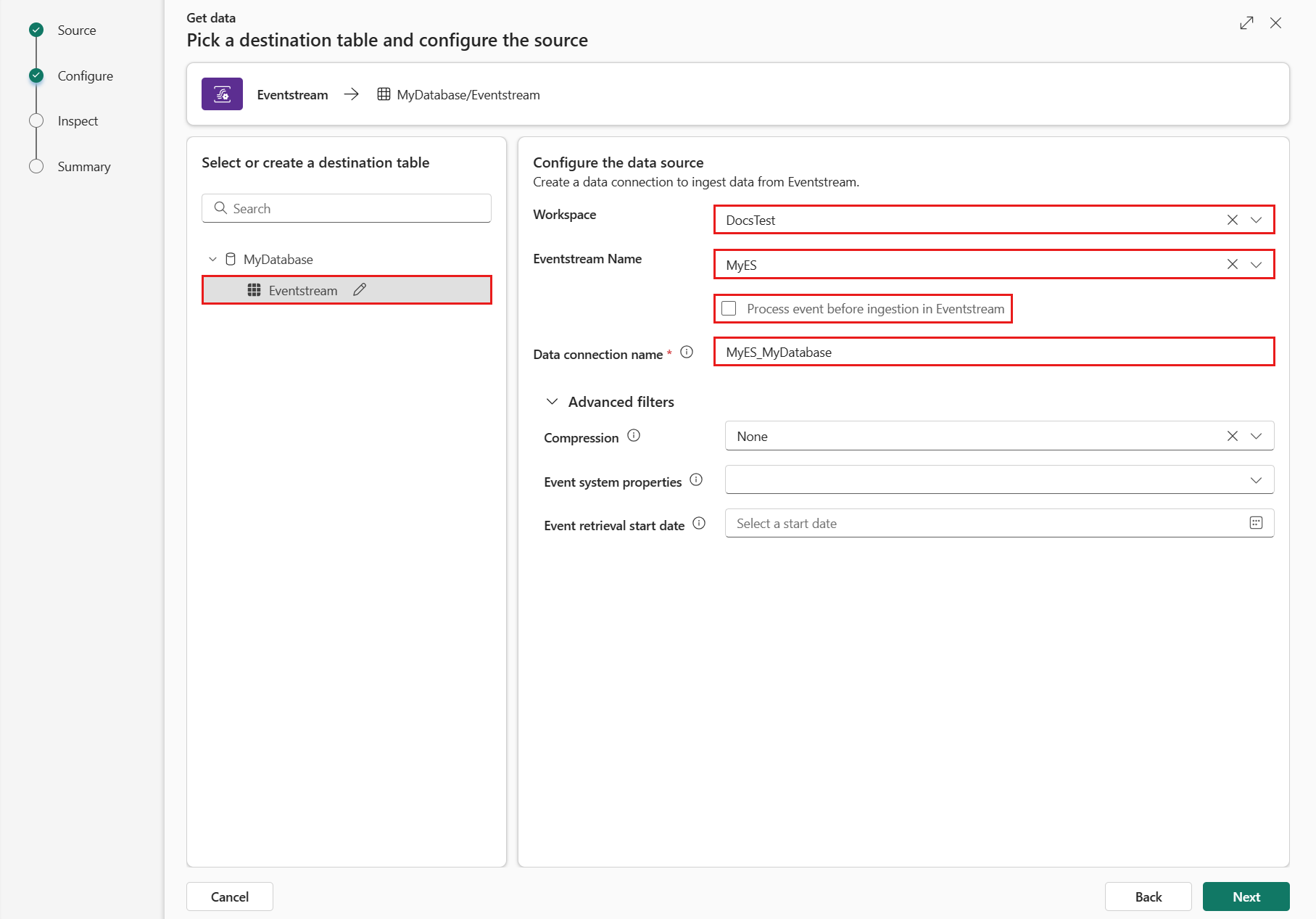
indstilling beskrivelse Arbejdsområde Placeringen af dit eventstream-arbejdsområde. Vælg et arbejdsområde på rullelisten. Navn på hændelsesstream Navnet på din eventstream. Vælg en hændelsesstream på rullelisten. Navn på dataforbindelse Det navn, der bruges til at referere til og administrere dataforbindelsen i dit arbejdsområde. Navnet på dataforbindelsen udfyldes automatisk. Du kan også angive et nyt navn. Navnet kan kun indeholde alfanumeriske tegn, tankestreger og priktegn og være op til 40 tegn lange. Behandl hændelse før indtagelse i Eventstream Denne indstilling giver dig mulighed for at konfigurere databehandling, før data overføres til destinationstabellen. Hvis indstillingen er valgt, fortsætter du dataindtagelsesprocessen i Eventstream. Du kan få flere oplysninger under Proceshændelse, før den indtages i Eventstream. Avancerede filtre Komprimering Datakomprimering af hændelserne, som kommer fra hændelseshubben. Indstillingerne er Ingen (standard) eller Gzip-komprimering. Egenskaber for hændelsessystem Hvis der er flere poster pr. hændelsesmeddelelse, føjes systemegenskaberne til den første. Du kan få flere oplysninger under egenskaber for hændelsessystemet . Startdato for hentning af hændelse Dataforbindelsen henter eksisterende hændelser, der er oprettet siden startdatoen for hentning af hændelse. Den kan kun hente hændelser, der bevares af hændelseshubben, baseret på dens opbevaringsperiode. Tidszonen er UTC. Hvis der ikke er angivet noget tidspunkt, er standardtidspunktet det tidspunkt, hvor dataforbindelsen oprettes. Vælg Næste

Behandl hændelse før indtagelse i Eventstream
Indstillingen Proceshændelse før indtagelse i Eventstream giver dig mulighed for at behandle dataene, før de indtages i destinationstabellen. Med denne indstilling fortsætter hent dataprocessen problemfrit i Eventstream, hvor oplysningerne om destinationstabellen og datakilden udfyldes automatisk.
Sådan behandles hændelsen før indtagelse i Eventstream:
Under fanen Konfigurer skal du vælge Behandl hændelse før indtagelse i Eventstream.
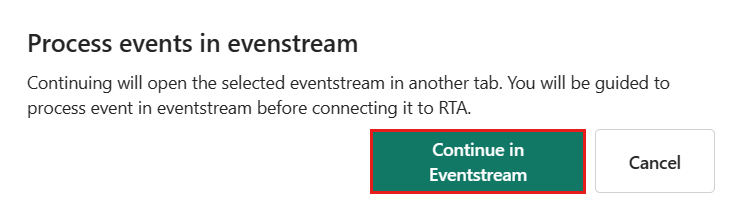
I dialogboksen Behandl hændelser i Eventstream skal du vælge Fortsæt i Eventstream.
Vigtig
Hvis du vælger Fortsæt i Eventstream afsluttes hent dataprocessen i Real-Time Intelligence og fortsætter i Eventstream, hvor oplysningerne om destinationstabellen og datakilden udfyldes automatisk.
I Eventstream skal du vælge destinationsnoden KQL-database, og i ruden KQL-database skal du kontrollere, at hændelsesbehandling før indtagelse er valgt, og at destinationsoplysningerne er korrekte.

Vælg Åbn hændelsesbehandler for at konfigurere databehandlingen, og vælg derefter Gem. Du kan få flere oplysninger i Behandl hændelsesdata med hændelsesbehandlereditoren.
Tilbage i ruden KQL-database skal du vælge Tilføj for at fuldføre konfiguration af KQL-database destinationsnode.
Kontrollér, at dataene er indtaget i destinationstabellen.


Seddel
Proceshændelsen før indtagelse i Eventstream-processen er fuldført, og de resterende trin i denne artikel er ikke påkrævet.
Inspicere
Fanen Inspect åbnes med et eksempel på dataene.
Hvis du vil fuldføre indtagelsesprocessen, skal du vælge Udfør.

Eventuelt:
- Vælg Kommandofremviser for at få vist og kopiere de automatiske kommandoer, der genereres fra dine input.
- Rediger det automatisk udledte dataformat ved at vælge det ønskede format på rullelisten. Data læses fra hændelseshubben i form af EventData objekter. Understøttede formater er CSV, JSON, PSV, SCsv, SOHsv TSV, TXT og TSVE.
- Rediger kolonner.
- Udforsk Avancerede indstillinger, der er baseret på datatypen.
Rediger kolonner
Seddel
- I forbindelse med tabelformater (CSV, TSV, PSV) kan du ikke tilknytte en kolonne to gange. Hvis du vil knytte til en eksisterende kolonne, skal du først slette den nye kolonne.
- Du kan ikke ændre en eksisterende kolonnetype. Hvis du forsøger at knytte til en kolonne med et andet format, kan du ende med at have tomme kolonner.
De ændringer, du kan foretage i en tabel, afhænger af følgende parametre:
- Tabeltype er ny eller eksisterende
- Tilknytningstypen er ny eller eksisterende
| Tabeltype | Tilknytningstype | Tilgængelige justeringer |
|---|---|---|
| Ny tabel | Ny tilknytning | Omdøb kolonne, skift datatype, skift datakilde, tilknytningstransformation, tilføj kolonne, slet kolonne |
| Eksisterende tabel | Ny tilknytning | Tilføj kolonne (hvor du derefter kan ændre datatype, omdøbe og opdatere) |
| Eksisterende tabel | Eksisterende tilknytning | ingen |

Tilknytning af transformationer
Nogle tilknytninger af dataformater (Parquet, JSON og Avro) understøtter enkle transformationer af indfødningstid. Hvis du vil anvende tilknytningstransformationer, skal du oprette eller opdatere en kolonne i vinduet Rediger kolonner.
Tilknytningstransformationer kan udføres på en kolonne af typen streng eller datetime, hvor kilden har datatypen int eller long. Understøttede tilknytningstransformationer er:
- DateTimeFromUnixSeconds
- DateTimeFromUnixMilliseconds
- DateTimeFromUnixMicroseconds
- DateTimeFromUnixNanoseconds
Avancerede indstillinger baseret på datatype
tabel (CSV, TSV, PSV):
Tabeldata indeholder ikke nødvendigvis de kolonnenavne, der bruges til at knytte kildedata til de eksisterende kolonner. Hvis du vil bruge den første række som kolonnenavne, skal du slå Første række er kolonneoverskrift.

JSON-:
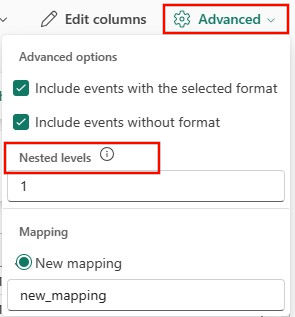
Hvis du vil bestemme kolonneopdelingen af JSON-data, skal du vælge Avancerede>Indlejrede niveauerfra 1 til 100.
Resumé
I vinduet Dataforberedelse er alle tre trin markeret med grønne markeringer, når dataindtagelse er fuldført. Du kan vælge et kort, der skal forespørges om, slippe de data, der er indtaget, eller se et dashboard med oversigten over indtagelse. Vælg Luk for at lukke vinduet.

Relateret indhold
- Hvis du vil administrere databasen, skal du se Administrer data
- Hvis du vil oprette, gemme og eksportere forespørgsler, skal du se Forespørgselsdata i et KQL-forespørgselssæt