Brug Iceberg-tabeller med OneLake
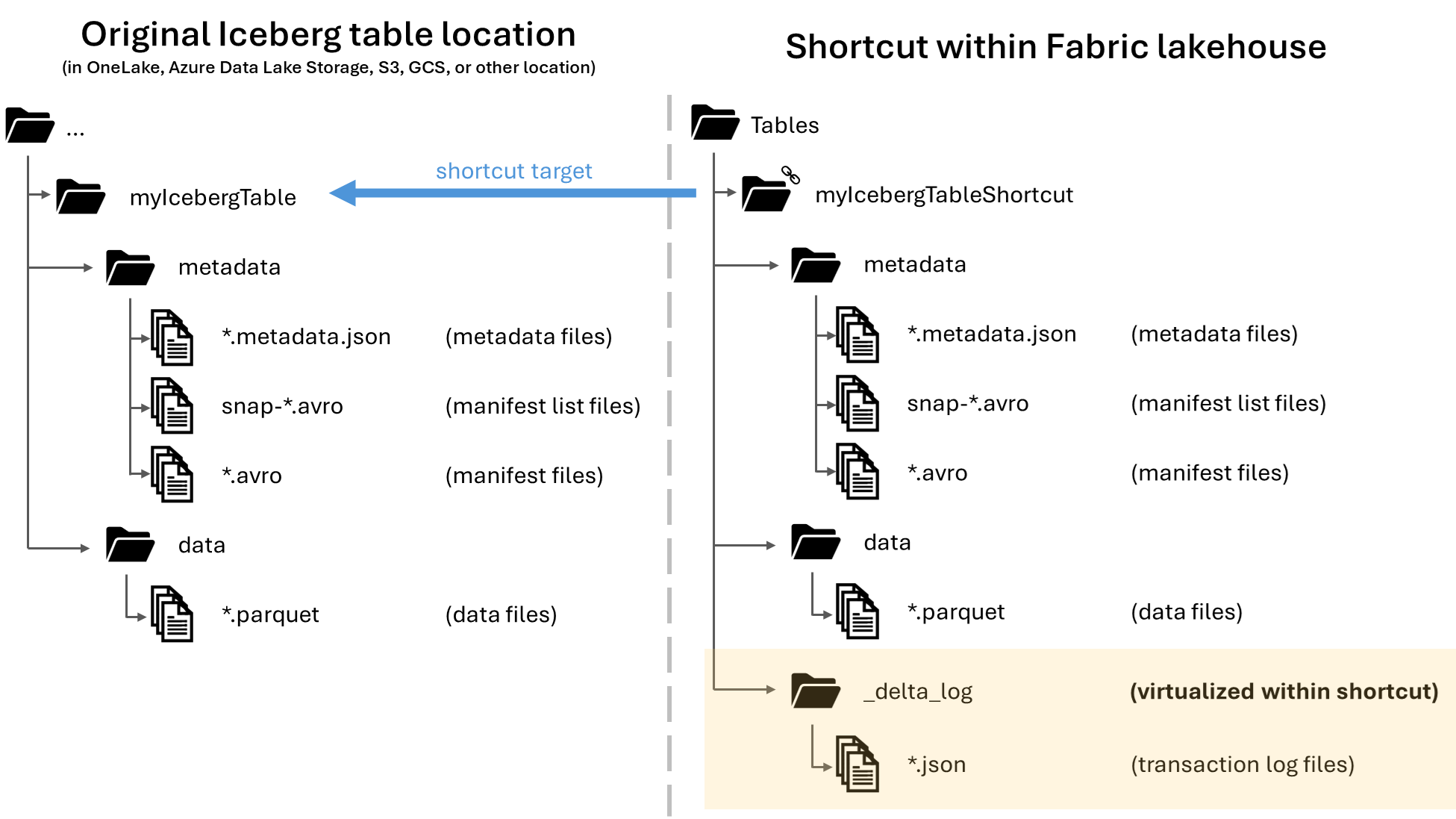
I Microsoft OneLake kan du oprette genveje til dine Apache Iceberg-tabeller, så de kan bruges på tværs af de mange forskellige Fabric-arbejdsbelastninger. Denne funktionalitet er gjort mulig via en funktion kaldet metadatavirtualisering, som gør det muligt at fortolke Iceberg-tabeller som Delta Lake-tabeller fra genvejens perspektiv. Når du opretter en genvej til en Iceberg-tabelmappe, genererer OneLake automatisk de tilsvarende Delta Lake-metadata (Delta-loggen) for den pågældende tabel, hvilket gør Delta Lake-metadataene tilgængelige via genvejen.
Vigtigt
Denne funktion er en prøveversion.
Selvom denne artikel indeholder vejledning til skrivning af Iceberg-tabeller fra Snowflake til OneLake, er denne funktion beregnet til at fungere sammen med alle Iceberg-tabeller med Parquet-datafiler.
Opret en tabelgenvej til en Iceberg-tabel
Hvis du allerede har en Iceberg-tabel på en lagerplacering, der understøttes af OneLake-genveje, skal du følge disse trin for at oprette en genvej og få din Iceberg-tabel vist med Delta Lake-formatet.
Find dit isbjergbord. Find ud af, hvor din Iceberg-tabel er gemt, hvilket kan være i Azure Data Lake Storage, OneLake, Amazon S3, Google Cloud Storage eller en S3-kompatibel lagertjeneste.
Bemærk
Hvis du bruger Snowflake og ikke er sikker på, hvor din Iceberg-tabel er gemt, kan du køre følgende sætning for at se placeringen af din Iceberg-tabel.
SELECT SYSTEM$GET_ICEBERG_TABLE_INFORMATION('<table_name>');Kørsel af denne sætning returnerer en sti til metadatafilen for Tabellen Iceberg. Denne sti fortæller dig, hvilken lagerkonto der indeholder tabellen Iceberg. Her er f.eks. de relevante oplysninger for at finde stien til en Iceberg-tabel, der er gemt i Azure Data Lake Storage:
{"metadataLocation":"azure://<storage_account_path>/<path_within_storage>/<table_name>/metadata/00001-389700a2-977f-47a2-9f5f-7fd80a0d41b2.metadata.json","status":"success"}Din Iceberg-tabelmappe skal indeholde en
metadatamappe, som indeholder mindst én fil, der ender i.metadata.json.Opret en ny genvej i området Tabeller i et ikke-skemaaktiveret lakehouse i dit Fabric-lakehouse.
Bemærk
Hvis du kan se skemaer, f.eks
dbo. under mappen Tabeller i lakehouse, er lakehouse'et skemaaktiveret og er endnu ikke kompatibelt med denne funktion.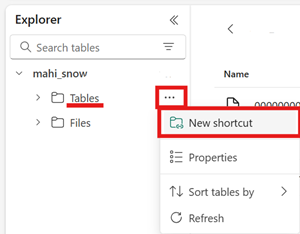
Vælg mappen Iceberg-tabel for genvejens destinationssti. Tabellen Iceberg indeholder mapperne
metadataogdata.Når genvejen er oprettet, bør du automatisk se denne tabel afspejlet som en Delta Lake-tabel i dit lakehouse, så du kan bruge den i hele Fabric.
Hvis din nye genvej til tabellen Iceberg ikke vises som en brugbar tabel, skal du se afsnittet Fejlfinding .
Skriv et iceberg-bord til OneLake ved hjælp af Snowflake
Hvis du bruger Snowflake på Azure, kan du skrive Iceberg-tabeller til OneLake ved at følge disse trin:
Sørg for, at din Fabric-kapacitet er på samme Azure-placering som din Snowflake-forekomst.
Identificer placeringen af den Fabric-kapacitet, der er knyttet til dit Fabric-lakehouse. Åbn indstillingerne for det Fabric-arbejdsområde, der indeholder dit lakehouse.
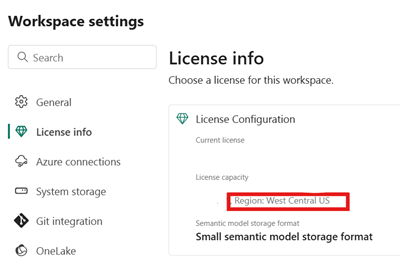
I nederste venstre hjørne af din Snowflake på Azure-kontogrænseflade skal du kontrollere Azure-området for Snowflake-kontoen.
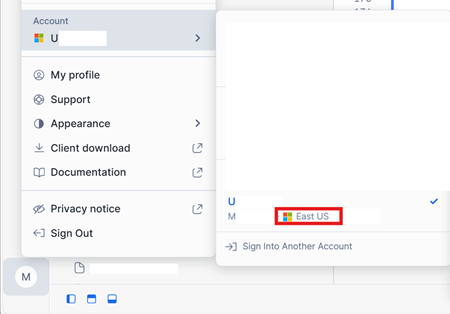
Hvis disse områder er forskellige, skal du bruge en anden Fabric-kapacitet i det samme område som din Snowflake-konto.
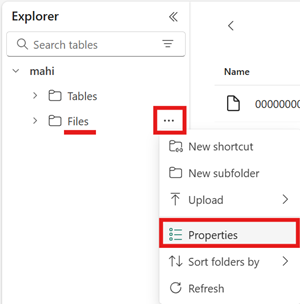
Åbn menuen for området Filer i dit lakehouse, vælg Egenskaber, og kopiér URL-adressen (HTTPS-stien) for den pågældende mappe.
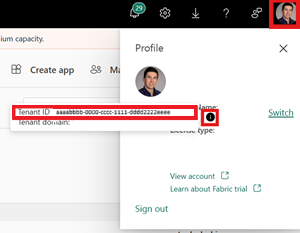
Identificer dit Fabric-lejer-id. Vælg din brugerprofil i øverste højre hjørne af brugergrænsefladen i Fabric, og hold markøren over infoboblen ud for dit lejernavn. Kopiér lejer-id'et.
I Snowflake skal du konfigurere din
EXTERNAL VOLUMEved hjælp af stien til mappen Filer i dit lakehouse. Du kan finde flere oplysninger om konfiguration af eksterne Snowflake-diskenheder her.Bemærk
Snowflake kræver, at URL-skemaet er
azure://, så sørg for at skiftehttps://tilazure://.CREATE OR REPLACE EXTERNAL VOLUME onelake_exvol STORAGE_LOCATIONS = ( ( NAME = 'onelake_exvol' STORAGE_PROVIDER = 'AZURE' STORAGE_BASE_URL = 'azure://<path_to_Files>/icebergtables' AZURE_TENANT_ID = '<Tenant_ID>' ) );I dette eksempel gemmes alle tabeller, der er oprettet ved hjælp af denne eksterne diskenhed, i Fabric lakehouse i mappen
Files/icebergtables.Nu, hvor din eksterne diskenhed er oprettet, skal du køre følgende kommando for at hente URL-adressen til samtykket og navnet på det program, som Snowflake bruger til at skrive til OneLake. Dette program bruges af en hvilken som helst anden ekstern diskenhed på din Snowflake-konto.
DESC EXTERNAL VOLUME onelake_exvol;Outputtet af denne kommando returnerer
AZURE_CONSENT_URLegenskaberne ogAZURE_MULTI_TENANT_APP_NAME. Notér begge værdier. Navnet på Azure Multitenant-appen ser ud som<name>_<number>, men du behøver kun at hente delen<name>.Åbn URL-adressen til samtykke fra det forrige trin på en ny browserfane. Hvis du vil fortsætte, skal du give samtykke til de påkrævede programtilladelser, hvis du bliver bedt om det.
Tilbage i Fabric skal du åbne dit arbejdsområde og vælge Administrer adgang og derefter Tilføje personer eller grupper. Tildel det program, der bruges af din eksterne Snowflake-diskenhed, de tilladelser, der er nødvendige for at skrive data til lakehouses i dit arbejdsområde. Vi anbefaler, at du tildeler rollen Bidragyder .
Tilbage i Snowflake kan du bruge din nye eksterne diskenhed til at oprette et Iceberg-bord.
CREATE OR REPLACE ICEBERG TABLE MYDATABASE.PUBLIC.Inventory ( InventoryId int, ItemName STRING ) EXTERNAL_VOLUME = 'onelake_exvol' CATALOG = 'SNOWFLAKE' BASE_LOCATION = 'Inventory/';Med denne sætning oprettes der en ny Iceberg-tabelmappe med navnet Inventory i den mappesti, der er defineret i den eksterne diskenhed.
Føj nogle data til din Iceberg-tabel.
INSERT INTO MYDATABASE.PUBLIC.Inventory VALUES (123456,'Amatriciana');Endelig kan du i området Tabeller i samme lakehouse oprette en OneLake-genvej til din Iceberg-tabel. Gennem denne genvej vises din Iceberg-tabel som en Delta Lake-tabel til forbrug på tværs af Fabric-arbejdsbelastninger.
Fejlfinding
Følgende tip kan hjælpe med at sikre, at dine Iceberg-tabeller er kompatible med denne funktion:
Kontrollér mappestrukturen i din Iceberg-tabel
Åbn din Iceberg-mappe i dit foretrukne lageroversigtsværktøj, og kontrollér mappelisten for din Iceberg-mappe på den oprindelige placering. Du bør kunne se en mappestruktur som følgende eksempel.
../
|-- MyIcebergTable123/
|-- data/
|-- snow_A5WYPKGO_2o_APgwTeNOAxg_0_1_002.parquet
|-- snow_A5WYPKGO_2o_AAIBON_h9Rc_0_1_003.parquet
|-- metadata/
|-- 00000-1bdf7d4c-dc90-488e-9dd9-2e44de30a465.metadata.json
|-- 00001-08bf3227-b5d2-40e2-a8c7-2934ea97e6da.metadata.json
|-- 00002-0f6303de-382e-4ebc-b9ed-6195bd0fb0e7.metadata.json
|-- 1730313479898000000-Kws8nlgCX2QxoDHYHm4uMQ.avro
|-- 1730313479898000000-OdsKRrRogW_PVK9njHIqAA.avro
|-- snap-1730313479898000000-9029d7a2-b3cc-46af-96c1-ac92356e93e9.avro
|-- snap-1730313479898000000-913546ba-bb04-4c8e-81be-342b0cbc5b50.avro
Hvis du ikke kan se metadatamappen, eller hvis du ikke kan se filer med de udvidelser, der vises i dette eksempel, har du muligvis ikke en korrekt oprettet Iceberg-tabel.
Kontrollér konverteringsloggen
Når en Iceberg-tabel virtualiseres som en Delta Lake-tabel, kan du finde en mappe med navnet _delta_log/ i genvejsmappen. Denne mappe indeholder Delta Lake-formatets metadata (Delta-logfilen) efter vellykket konvertering.
Denne mappe indeholder latest_conversion_log.txt også filen, som indeholder oplysninger om den senest forsøgte konvertering.
Hvis du vil se indholdet af denne fil, når du har oprettet genvejen, skal du åbne menuen for genvejen til tabellen Iceberg under Området Tabeller i lakehouse og vælge Vis filer.
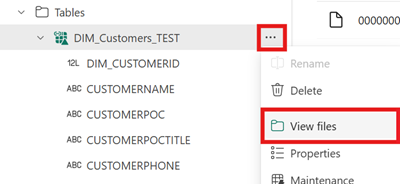
Du bør se en struktur som følgende eksempel:
Tables/
|-- MyIcebergTable123/
|-- data/
|-- <data files>
|-- metadata/
|-- <metadata files>
|-- _delta_log/ <-- Virtual folder. This folder doesn't exist in the original location.
|-- 00000000000000000000.json
|-- latest_conversion_log.txt <-- Conversion log with latest success/failure details.
Åbn konverteringslogfilen for at se den seneste konverteringstid eller oplysninger om fejl. Hvis du ikke kan se en konverteringslogfil, blev konverteringen ikke forsøgt.
Hvis konverteringen ikke blev forsøgt
Hvis du ikke kan se en konverteringslogfil, blev konverteringen ikke forsøgt. Her er to almindelige årsager til, at konvertering ikke forsøges:
Genvejen blev ikke oprettet på det rigtige sted.
Hvis en genvej til en Iceberg-tabel skal konverteres til Delta Lake-formatet, skal genvejen placeres direkte under mappen Tabeller i et lakehouse, der ikke er skemaaktiveret. Du bør ikke placere genvejen i sektionen Filer eller under en anden mappe, hvis tabellen skal virtualiseres automatisk som en Delta Lake-tabel.
Genvejens destinationssti er ikke stien til mappen Iceberg.
Når du opretter genvejen, må den mappesti, du vælger på destinationslagerplaceringen, kun være mappen med tabellen Iceberg. Denne mappe indeholder mapperne
metadataogdata.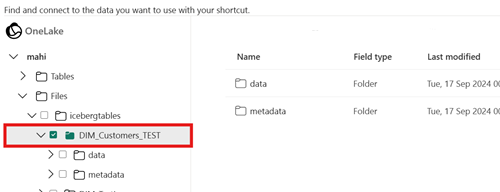
Begrænsninger og overvejelser
Vær opmærksom på følgende midlertidige begrænsninger, når du bruger denne funktion:
Understøttede datatyper
Følgende Iceberg-kolonnedatatyper knyttes til deres tilsvarende Delta Lake-typer ved hjælp af denne funktion.
Isbjergkolonnetype Kolonnetype for Delta Lake Kommentarer intintegerlonglongSe Problem med typebredde. floatfloatdoubledoubleSe Problem med typebredde. decimal(P, S)decimal(P, S)Se Problem med typebredde. booleanbooleandatedatetimestamptimestamp_ntzIceberg-datatypen timestampindeholder ikke tidszoneoplysninger. Deltatimestamp_ntzLake-typen understøttes ikke fuldt ud på tværs af Fabric-arbejdsbelastninger. Vi anbefaler, at du bruger tidsstempler med inkluderede tidszoner.timestamptztimestampHvis du vil bruge denne type i Snowflake, skal du angive timestamp_ltzsom kolonnetype under oprettelse af Iceberg-tabel. Du kan finde flere oplysninger om Iceberg-datatyper, der understøttes i Snowflake, her.stringstringbinarybinaryProblem med typebredde
Hvis du bruger Snowflake til at skrive din Iceberg-tabel, og tabellen indeholder kolonnetyper
INT64,doubleellerDecimalmed præcision >= 10, kan den resulterende virtuelle Delta Lake-tabel muligvis ikke forbruges af alle Fabric-motorer. Du kan få vist fejl som f.eks.:Parquet column cannot be converted in file ... Column: [ColumnA], Expected: decimal(18,4), Found: INT32.Vi arbejder på at løse problemet.
Løsning: Hvis du bruger brugergrænsefladen til eksempelvisning af Lakehouse-tabellen og ser dette problem, kan du løse denne fejl ved at skifte til SQL Endpoint-visningen (øverste højre hjørne, vælge Lakehouse-visning, skifte til SQL Endpoint) og få vist tabellen derfra. Hvis du derefter skifter tilbage til Visningen Lakehouse, vises eksempelvisningen af tabellen korrekt.
Hvis du kører en Spark-notesbog eller et spark-job og støder på dette problem, kan du løse denne fejl ved at angive
spark.sql.parquet.enableVectorizedReaderSpark-konfigurationen tilfalse. Her er et eksempel på kommandoen PySpark, der skal køres i en Spark-notesbog:spark.conf.set("spark.sql.parquet.enableVectorizedReader","false")Metadatalageret for iceberg-tabellen er ikke bærbart
Metadatafilerne i en Iceberg-tabel refererer til hinanden ved hjælp af absolutte stireferencer. Hvis du kopierer eller flytter en Iceberg-tabels mappeindhold til en anden placering uden at omskrive Iceberg-metadatafilerne, bliver tabellen ulæselig for Iceberg-læsere, herunder denne OneLake-funktion.
Løsning:
Hvis du har brug for at flytte din Iceberg-tabel til et andet sted for at bruge denne funktion, skal du bruge det værktøj, der oprindeligt skrev tabellen Iceberg, til at skrive en ny Iceberg-tabel på den ønskede placering.
Isbjergtabeller skal være dybere end rodniveau
Iceberg-tabelmappen i lageret skal være placeret i en mappe, der er dybere end bucket- eller objektbeholderniveau. Iceberg-tabeller, der er gemt direkte i rodmappen i en bucket eller objektbeholder, virtualiseres muligvis ikke til Delta Lake-formatet.
Vi arbejder på en forbedring for at fjerne dette krav.
Løsning:
Sørg for, at alle Iceberg-tabeller er gemt i en mappe, der er dybere end rodmappen for en bucket eller objektbeholder.
Iceberg-tabelmapper må kun indeholde ét sæt metadatafiler
Hvis du slipper og genskaber en Iceberg-tabel i Snowflake, ryddes metadatafilerne ikke op. Denne funktionsmåde understøttes af
UNDROPfunktionen i Snowflake. Men da genvejen peger direkte på en mappe, og mappen nu indeholder flere sæt metadatafiler, kan vi ikke konvertere tabellen, før du fjerner den gamle tabels metadatafiler.Konvertering forsøges i øjeblikket i dette scenarie, hvilket kan resultere i, at gamle tabelindholds- og skemaoplysninger vises i den virtualiserede Delta Lake-tabel.
Vi arbejder på en løsning, hvor konverteringen mislykkes, hvis der findes mere end ét sæt metadatafiler i mappen med metadata i tabellen Iceberg.
Løsning:
Sådan sikrer du, at den konverterede tabel afspejler den korrekte version af tabellen:
- Sørg for, at du ikke gemmer mere end én Iceberg-tabel i den samme mappe.
- Ryd op i indholdet af en Iceberg-tabelmappe, når du har droppet den, før du opretter tabellen igen.
Metadataændringer afspejles ikke med det samme
Hvis du foretager metadataændringer i din Iceberg-tabel, f.eks. tilføjelse af en kolonne, sletning af en kolonne, omdøbning af en kolonne eller ændring af en kolonnetype, gendannes tabellen muligvis ikke, før der er foretaget en dataændring, f.eks. tilføjelse af en række med data.
Vi arbejder på en rettelse, der henter den korrekte seneste metadatafil, der indeholder den seneste ændring af metadata.
Løsning:
Når skemaændringen er foretaget i din Iceberg-tabel, skal du tilføje en række med data eller foretage andre ændringer af dataene. Efter denne ændring bør du kunne opdatere og se den nyeste visning af tabellen i Fabric.
Skemaaktiverede arbejdsområder understøttes endnu ikke
Hvis du opretter en Iceberg-genvej i et skemaaktiveret lakehouse, sker der ikke konvertering for genvejen.
Vi arbejder på en forbedring for at fjerne denne begrænsning.
Løsning:
Brug et ikke-skemaaktiveret lakehouse med denne funktion. Du kan konfigurere denne indstilling under oprettelse af lakehouse.
Begrænsning af områdetilgængelighed
Funktionen er endnu ikke tilgængelig i følgende områder:
- Det centrale Qatar
- Det vestlige Norge
Løsning:
Arbejdsområder, der er knyttet til Fabric-kapaciteter i andre områder, kan bruge denne funktion. Se den komplette liste over områder, hvor Microsoft Fabric er tilgængelig.
Private links understøttes ikke
Denne funktion understøttes i øjeblikket ikke for lejere eller arbejdsområder, der har private links aktiveret.
Vi arbejder på en forbedring for at fjerne denne begrænsning.
Begrænsning af tabelstørrelse
Vi har en midlertidig begrænsning på størrelsen af den Iceberg-tabel, der understøttes af denne funktion. Det maksimale understøttede antal Parquet-datafiler er omkring 5.000 datafiler eller ca. 1 milliard rækker, uanset hvilken grænse der opstår først.
Vi arbejder på en forbedring for at fjerne denne begrænsning.
OneLake-genveje skal være af samme område
Vi har en midlertidig begrænsning på brugen af denne funktion med genveje, der peger på OneLake-placeringer: Genvejens målplacering skal være i det samme område som selve genvejen.
Vi arbejder på en forbedring for at fjerne dette krav.
Løsning:
Hvis du har en OneLake-genvej til et Iceberg-bord i et andet lakehouse, skal du sørge for, at det andet lakehouse er knyttet til en kapacitet i samme område.
lejerkontakt, der giver ekstern adgang
Vi har en midlertidig begrænsning, der kræver, at "Brugere kan få adgang til data, der er gemt i OneLake med apps uden for Fabric", lejerindstilling skal aktiveres.
Hvis denne lejerindstilling er deaktiveret, lykkes virtualiseringen af Iceberg-tabeller til Delta Lake-formatet ikke.
Løsning:
Få din Fabric-lejeradministrator til at aktivere "Brugere kan få adgang til data, der er gemt i OneLake med apps uden for Fabric" lejerindstilling, hvis det er muligt.
Iceberg-tabeller skal være kopiering ved skrivning (ikke flet ved læsning)
Iceberg-tabeller skal i øjeblikket være kopi-ved-skriv-. Det betyder, at de ikke kan indeholde slettefiler eller være flettede.
Snowflake producerer i øjeblikket kopi-on-write Iceberg tabeller, men andre Iceberg forfattere kan følge en anden tilgang.
Vi arbejder på at understøtte flet ved læsning Iceberg-tabeller.
Relateret indhold
- Få mere at vide om Fabric- og OneLake-sikkerhed.
- Få mere at vide om OneLake-genveje.