Opret et lakehouse til Direct Lake
I denne artikel beskrives det, hvordan du opretter et lakehouse, opretter en Delta-tabel i lakehouse og derefter opretter en grundlæggende semantisk model for lakehouse i et Microsoft Fabric-arbejdsområde.
Før du begynder at oprette et lakehouse til Direct Lake, skal du læse oversigt over Direct Lake.
Opret et lakehouse
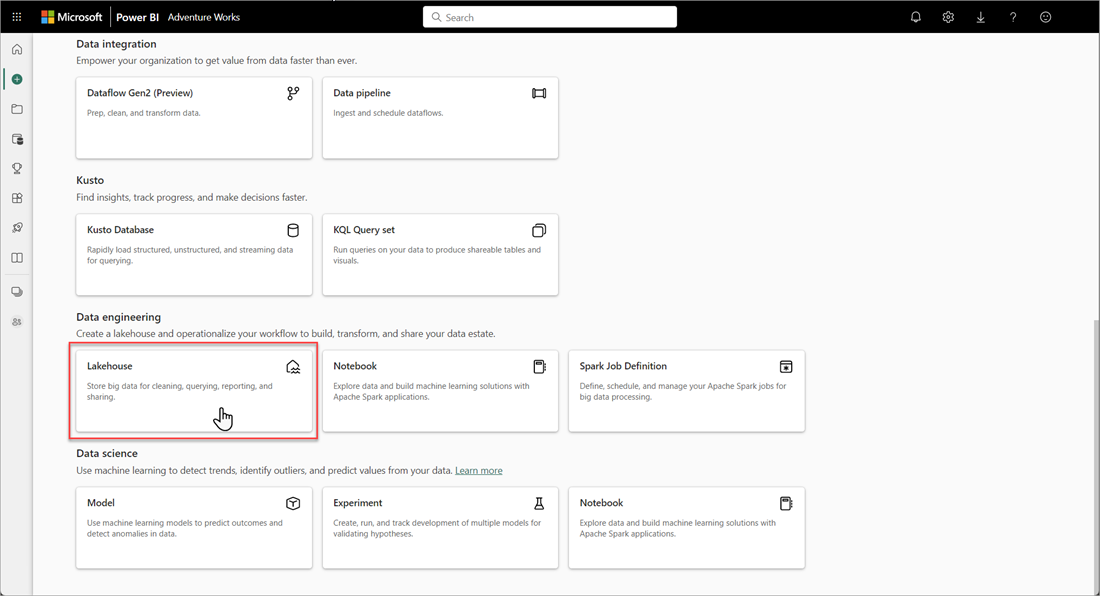
Vælg Nye>flere indstillinger i dit Microsoft Fabric-arbejdsområde, og vælg derefter feltet Lakehouse i Dataudvikler ing.
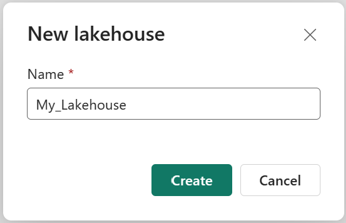
Angiv et navn i dialogboksen Ny lakehouse , og vælg derefter Opret. Navnet kan kun indeholde alfanumeriske tegn og understregningstegn.
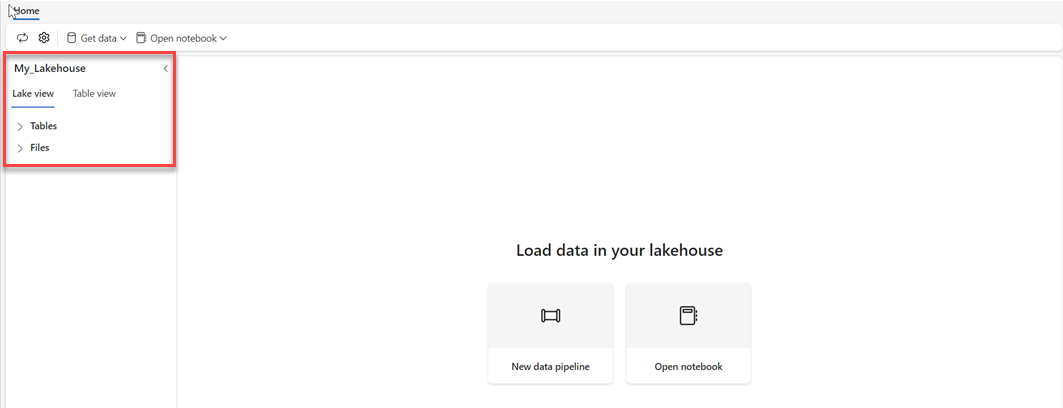
Kontrollér, at det nye lakehouse er oprettet og åbnes.
Opret en Delta-tabel i lakehouse
Når du har oprettet et nyt lakehouse, skal du derefter oprette mindst én Delta-tabel, så Direct Lake kan få adgang til nogle data. Direct Lake kan læse parquetformaterede filer, men for at opnå den bedste ydeevne er det bedst at komprimere dataene ved hjælp af VORDER-komprimeringsmetoden. VORDER komprimerer dataene ved hjælp af Power BI-programmets oprindelige komprimeringsalgoritme. På denne måde kan programmet indlæse dataene i hukommelsen så hurtigt som muligt.
Der er flere muligheder for at indlæse data i et lakehouse, herunder datapipelines og scripts. Følgende trin bruger PySpark til at føje en Delta-tabel til et lakehouse baseret på et Azure Open Dataset:
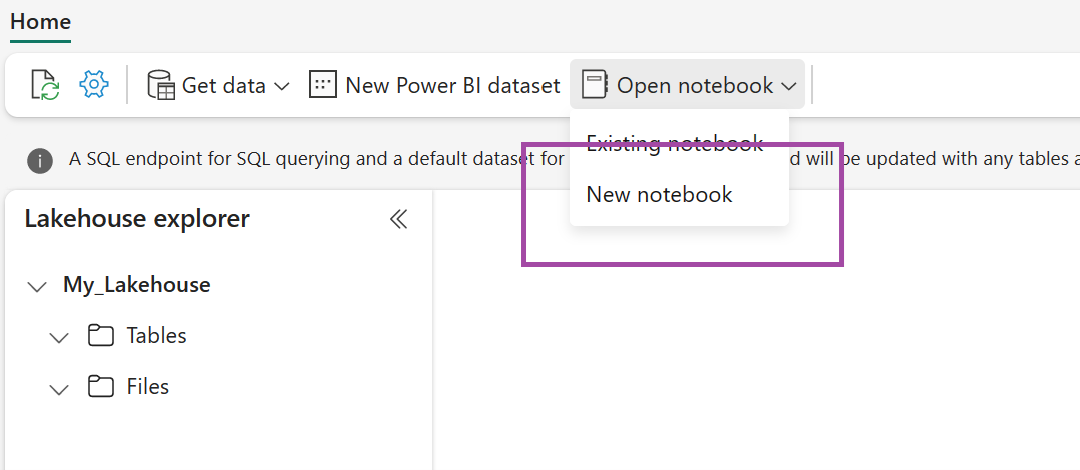
Vælg Åbn notesbog i det nyoprettede lakehouse, og vælg derefter Ny notesbog.
Kopiér og indsæt følgende kodestykke i den første kodecelle for at give SPARK adgang til den åbne model, og tryk derefter på Skift + Enter for at køre koden.
# Azure storage access info blob_account_name = "azureopendatastorage" blob_container_name = "holidaydatacontainer" blob_relative_path = "Processed" blob_sas_token = r"" # Allow SPARK to read from Blob remotely wasbs_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path) spark.conf.set( 'fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token) print('Remote blob path: ' + wasbs_path)Kontrollér, at koden returnerer en ekstern blobsti.
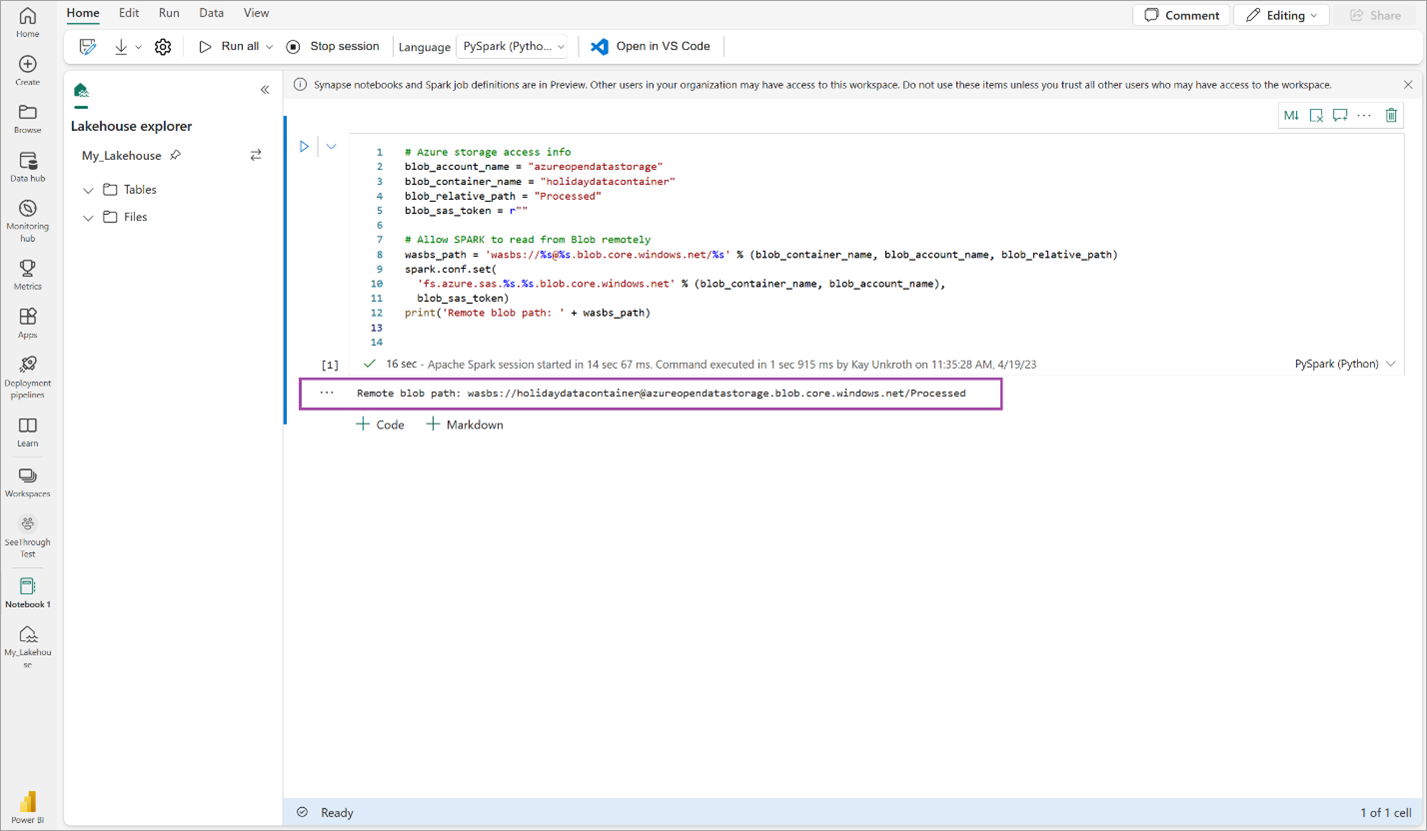
Kopiér og indsæt følgende kode i den næste celle, og tryk derefter på Skift + Enter.
# Read Parquet file into a DataFrame. df = spark.read.parquet(wasbs_path) print(df.printSchema())Kontrollér, at koden returnerer DataFrame-skemaet.
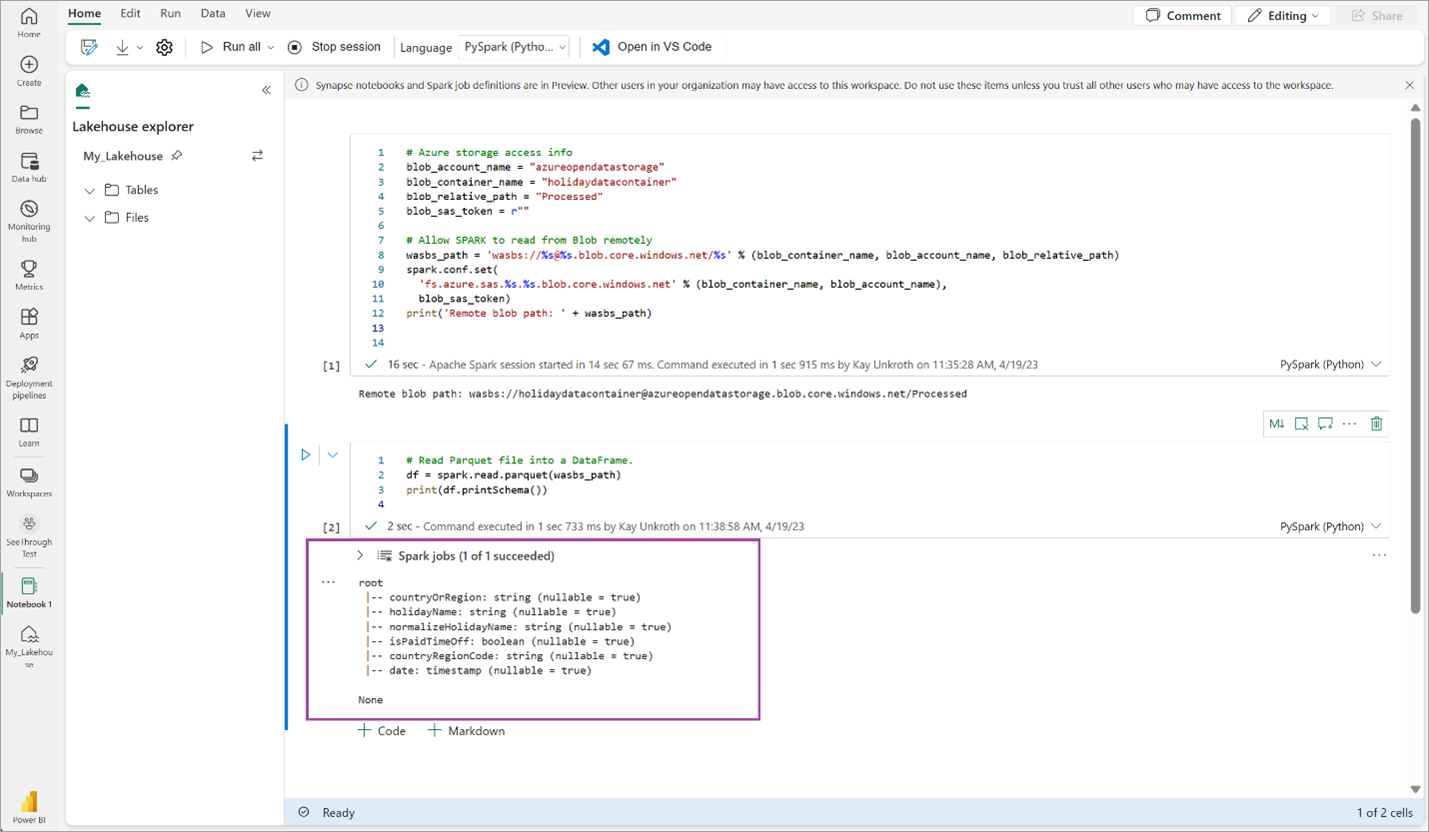
Kopiér og indsæt følgende linjer i den næste celle, og tryk derefter på Skift + Enter. Den første instruktion aktiverer VORDER-komprimeringsmetoden, og den næste instruktion gemmer DataFrame som en Delta-tabel i lakehouse.
# Save as delta table spark.conf.set("spark.sql.parquet.vorder.enabled", "true") df.write.format("delta").saveAsTable("holidays")Kontrollér, at alle SPARK-job er fuldført. Udvid listen over SPARK-job for at få vist flere oplysninger.
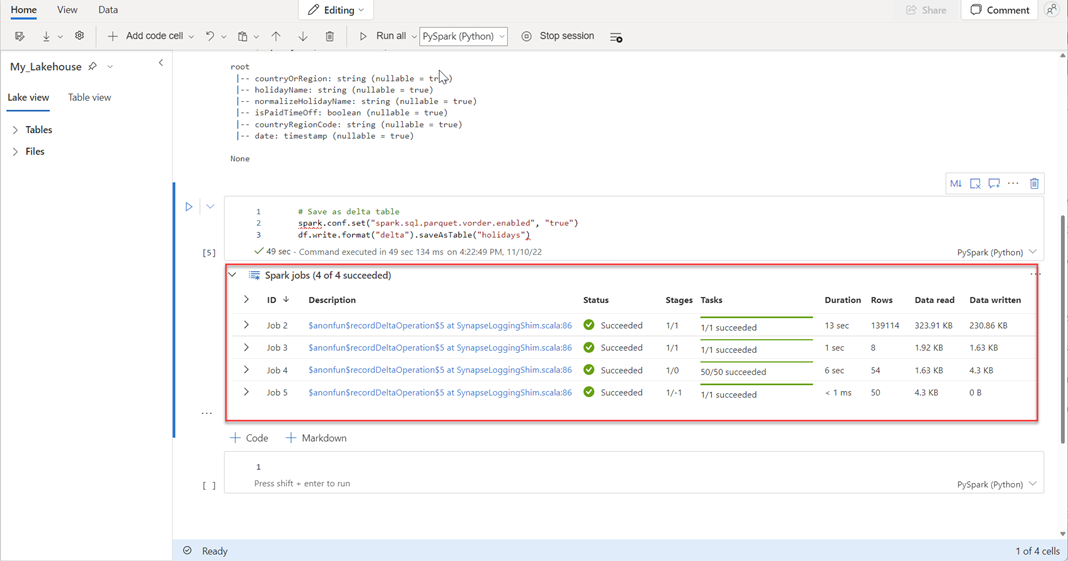
Hvis du vil kontrollere, at en tabel er oprettet, skal du vælge ellipsen (...) i øverste venstre område ud for Tabeller og derefter vælge Opdater og derefter udvide noden Tabeller.
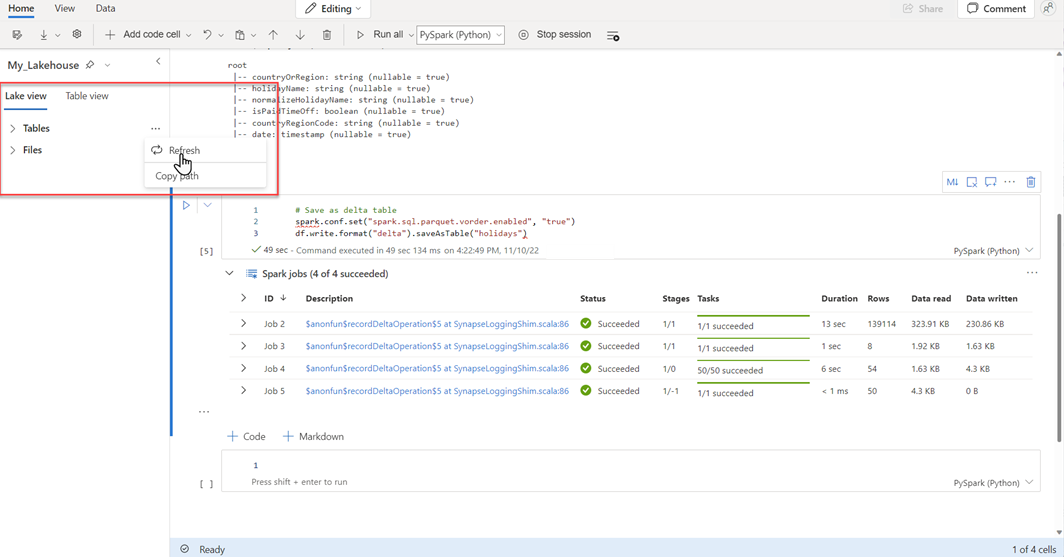
Ved hjælp af enten den samme metode som ovenfor eller andre understøttede metoder kan du tilføje flere Delta-tabeller for de data, du vil analysere.
Opret en grundlæggende Direct Lake-model til dit lakehouse
Vælg Ny semantisk model i dit lakehouse, og vælg derefter de tabeller, der skal medtages, i dialogboksen.
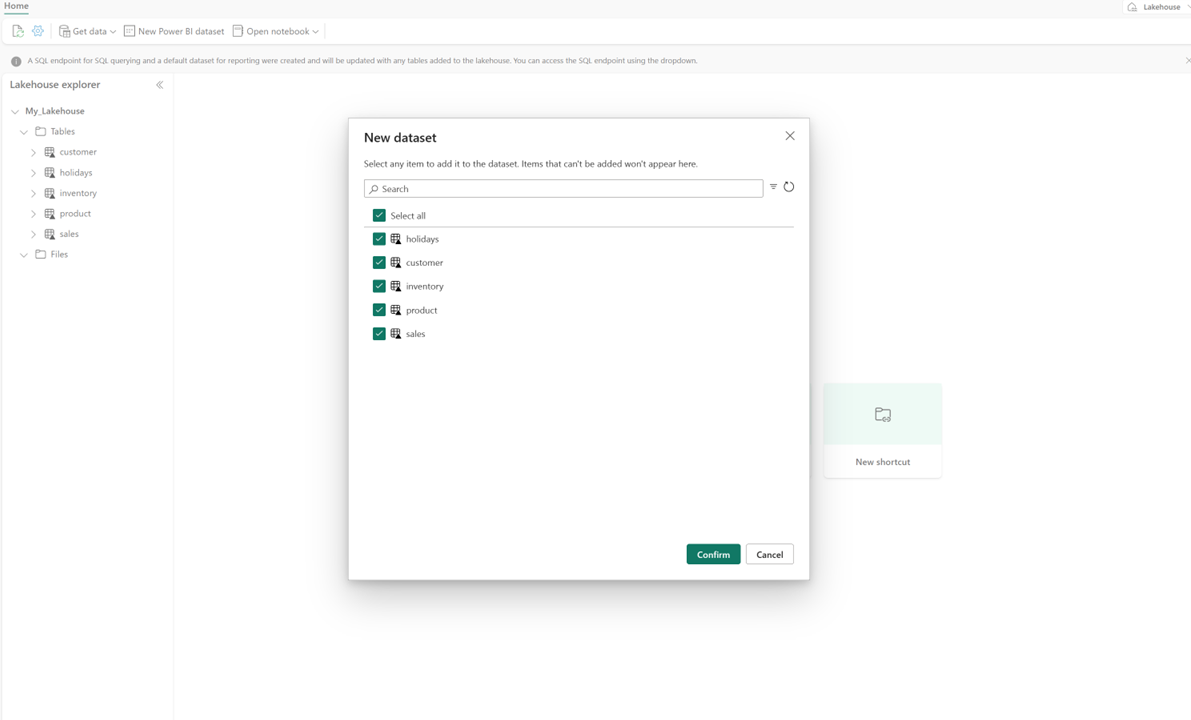
Vælg Bekræft for at generere Direct Lake-modellen. Modellen gemmes automatisk i arbejdsområdet baseret på navnet på dit lakehouse og åbner derefter modellen.
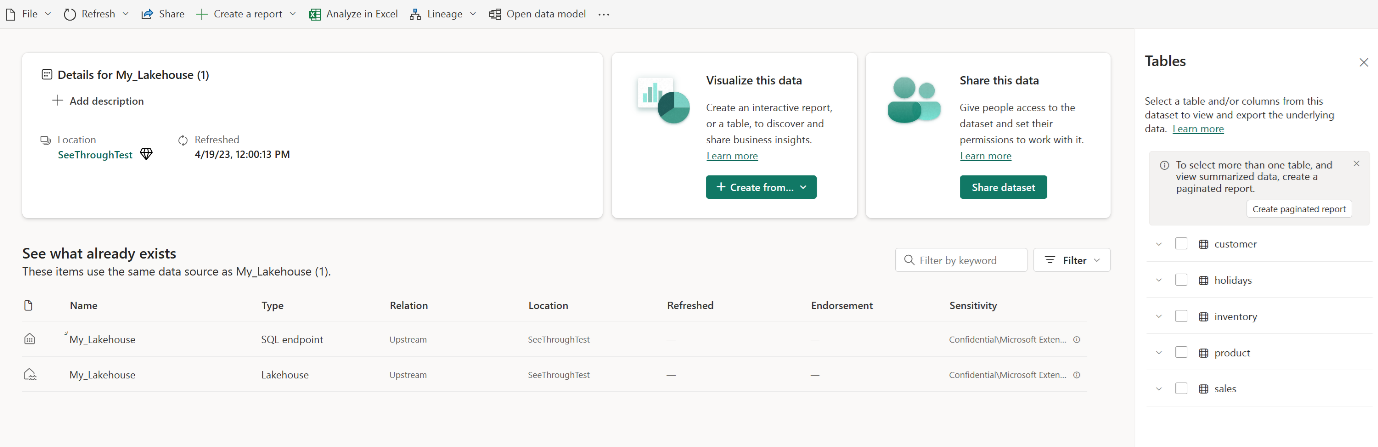
Vælg Åbn datamodel for at åbne webmodelleringsoplevelsen, hvor du kan tilføje tabelrelationer og DAX-målinger.
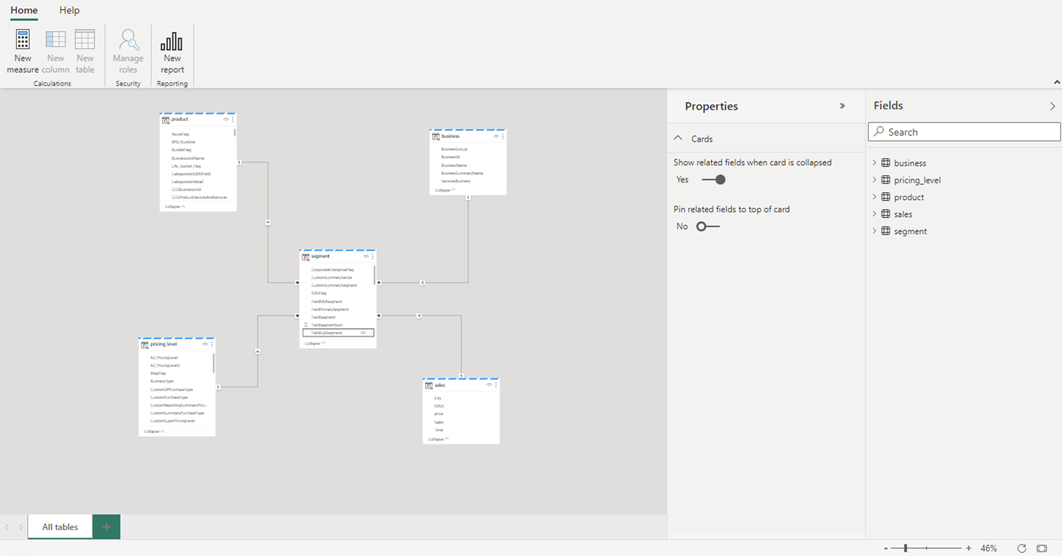
Når du er færdig med at tilføje relationer og DAX-målinger, kan du oprette rapporter, oprette en sammensat model og forespørge modellen via XMLA-slutpunkter på stort set samme måde som enhver anden model.