Indfødning af eksempeldata, og opret objekter og data
Gælder for:✅SQL-database i Microsoft Fabric
Du kan indtaste data i SQL-databasen i Fabric ved hjælp af T-SQL-sætninger (Transact-SQL), og du kan også importere data til databasen ved hjælp af andre Microsoft Fabric-komponenter, f.eks. funktionen Dataflow Gen2 eller datapipelines. Til udvikling kan du oprette forbindelse til et hvilket som helst værktøj, der understøtter TDS-protokollen (Tabular Data Stream), f.eks. Visual Studio Code eller SQL Server Management Studio.
Hvis du vil starte dette afsnit, kan du bruge de SalesLT-eksempeldata, der er angivet som udgangspunkt.
Forudsætninger
- Fuldfør alle de forrige trin i dette selvstudium.
Åbn forespørgselseditoren på Fabric-portalen
Åbn den SQL-database i Fabric-databasen, du oprettede i det sidste selvstudium. Du kan finde den på navigationslinjen på Fabric-portalen eller ved at finde den i dit arbejdsområde til dette selvstudium.
Vælg knappen Eksempeldata . Det tager et øjeblik at udfylde din selvstudiedatabase med SalesLT-eksempeldataene .
Kontrollér området Meddelelser for at sikre, at importen er fuldført, før du fortsætter.
Meddelelser viser dig, når importen af eksempeldataene er fuldført. Din SQL-database i Fabric indeholder nu skemaet og de
SalesLTtilknyttede tabeller.

Brug SQL-databasen i SQL-editoren
Den webbaserede SQL-editor til SQL-databasen i Fabric indeholder en grundlæggende objektoversigt og grænseflade til udførelse af forespørgsler. En ny SQL-database i Fabric åbnes automatisk i SQL-editoren, og en eksisterende database kan åbnes i SQL-editoren ved at åbne den på Fabric-portalen.
Der er flere elementer på værktøjslinjen i webeditoren, herunder opdatering, indstillinger, en forespørgselshandling og muligheden for at få oplysninger om ydeevnen. Du skal bruge disse funktioner i hele dette selvstudium.
I databasevisningen skal du starte med at vælge Ny forespørgsel på ikonlinjen. Dette viser en forespørgselseditor, som har funktionen Copilot AI, som kan hjælpe dig med at skrive din kode. Copilot til SQL-databasen kan hjælpe dig med at afslutte en forespørgsel eller oprette en.
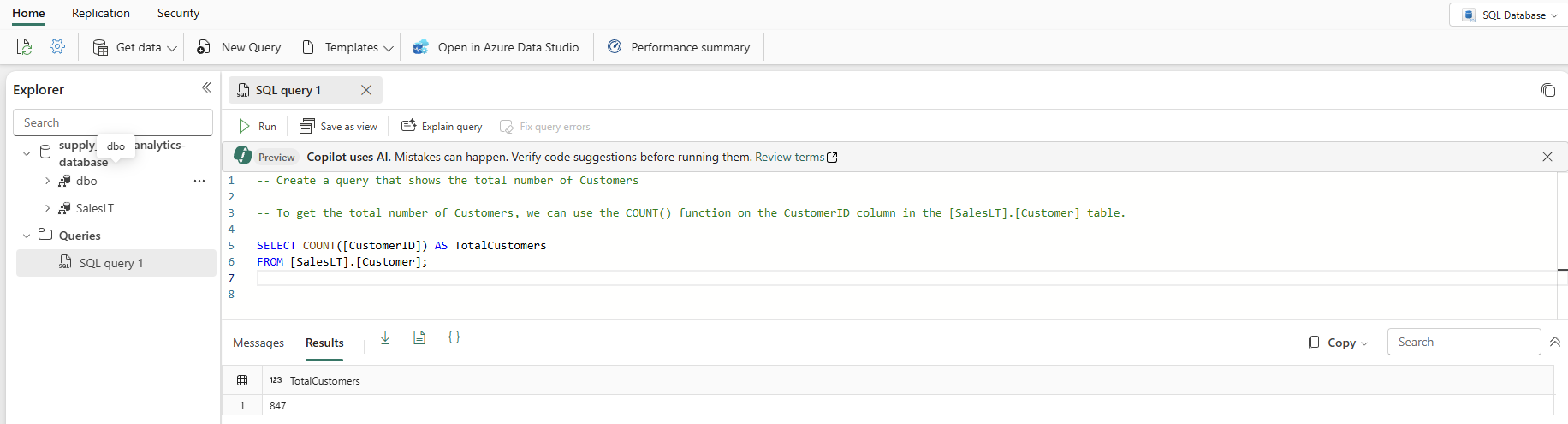
Skriv en T-SQL-kommentar øverst i forespørgslen, f.eks
-- Create a query that shows the total number of customers. og tryk på Enter. Du får et resultat, der ligner dette:
Hvis du trykker på tabulatortasten, implementeres den foreslåede kode:
Vælg Forklar forespørgsel på ikonlinjen i Forespørgselseditor for at indsætte kommentarer i din kode for at forklare hvert overordnede trin:

Bemærk
Copiloten gør sit bedste for at finde ud af din hensigt, men du skal altid kontrollere den kode, den opretter, før du kører den, og altid teste i et separat miljø fra produktionen.



I et produktionsmiljø kan du have data, der allerede er i et normaliseret format for daglige programhandlinger, som du har simuleret her med SalesLT-dataene . Når du opretter en forespørgsel, gemmes den automatisk i elementet Forespørgsler i ruden Stifinder . Du bør se din forespørgsel som "SQL-forespørgsel 1". Som standard nummererer systemet forespørgslerne, f.eks. "SQL-forespørgsel 1", men du kan vælge ellipsen ud for forespørgselsnavnet for at duplikere, omdøbe eller slette forespørgslen.
Indsæt data ved hjælp af Transact-SQL
Du er blevet bedt om at oprette nye objekter for at spore organisationens forsyningskæde, så du skal tilføje et sæt objekter til dit program. I dette eksempel skal du oprette et enkelt objekt i et nyt skema. Du kan tilføje flere tabeller for at normalisere programmet fuldt ud. Du kan tilføje flere data, f.eks. flere komponenter pr. produkt, få flere leverandøroplysninger osv. Senere i dette selvstudium kan du se, hvordan dataene spejles i SQL Analytics-slutpunktet, og hvordan du kan forespørge dataene med en GraphQL-API om automatisk at justere, efterhånden som objekterne tilføjes eller ændres.
I følgende trin bruges et T-SQL-script til at oprette et skema, en tabel og data til simulerede data til analyse af forsyningskæden.
Vælg knappen Ny forespørgsel på værktøjslinjen i SQL-databasen for at oprette en ny forespørgsel.
Indsæt følgende script i området Forespørgsel, og vælg Kør for at udføre det. Følgende T-SQL-script:
- Opretter et skema med navnet
SupplyChain. - Opretter en tabel med navnet
SupplyChain.Warehouse. - Udfylder tabellen
SupplyChain.Warehousemed nogle tilfældigt oprettede produktdata fraSalesLT.Product.
/* Create the Tutorial Schema called SupplyChain for all tutorial objects */ CREATE SCHEMA SupplyChain; GO /* Create a Warehouse table in the Tutorial Schema NOTE: This table is just a set of INT's as Keys, tertiary tables will be added later */ CREATE TABLE SupplyChain.Warehouse ( ProductID INT PRIMARY KEY -- ProductID to link to Products and Sales tables , ComponentID INT -- Component Identifier, for this tutorial we assume one per product, would normalize into more tables , SupplierID INT -- Supplier Identifier, would normalize into more tables , SupplierLocationID INT -- Supplier Location Identifier, would normalize into more tables , QuantityOnHand INT); -- Current amount of components in warehouse GO /* Insert data from the Products table into the Warehouse table. Generate other data for this tutorial */ INSERT INTO SupplyChain.Warehouse (ProductID, ComponentID, SupplierID, SupplierLocationID, QuantityOnHand) SELECT p.ProductID, ABS(CHECKSUM(NEWID())) % 10 + 1 AS ComponentID, ABS(CHECKSUM(NEWID())) % 10 + 1 AS SupplierID, ABS(CHECKSUM(NEWID())) % 10 + 1 AS SupplierLocationID, ABS(CHECKSUM(NEWID())) % 100 + 1 AS QuantityOnHand FROM [SalesLT].[Product] AS p; GODin SQL-database i Fabric-databasen indeholder nu lageroplysninger. Du skal bruge disse data på et senere trin i dette selvstudium.
- Opretter et skema med navnet
Du kan vælge disse tabeller i ruden Stifinder , og tabeldataene vises – det er ikke nødvendigt at skrive en forespørgsel for at se den.
Indsæt data ved hjælp af en Microsoft Fabric Pipeline
Du kan også importere data til og eksportere data fra din SQL-database i Fabric ved at bruge en Microsoft Fabric Data Pipeline. Datapipelines er et alternativ til at bruge kommandoer i stedet for at bruge en grafisk brugergrænseflade. En datapipeline er en logisk gruppering af aktiviteter, der tilsammen udfører en dataindtagelsesopgave. Pipelines giver dig mulighed for at administrere etl-aktiviteter (extract, transform and load) i stedet for at administrere hver enkelt.
Microsoft Fabric Pipelines kan indeholde et dataflow. Dataflow Gen2 bruger en Power Query-grænseflade, der giver dig mulighed for at udføre transformationer og andre handlinger på dataene. Du skal bruge denne grænseflade til at hente data fra Northwind Traders-virksomheden , som Contoso samarbejder med. De bruger i øjeblikket de samme leverandører, så du importerer deres data og viser navnene på disse leverandører ved hjælp af en visning, som du opretter i et andet trin i dette selvstudium.
For at komme i gang skal du åbne SQL-databasevisningen af eksempeldatabasen på Fabric-portalen, hvis den ikke allerede er.
Vælg knappen Hent data på menulinjen.
Vælg Nyt dataflow Gen2.
I Power Query-visningen skal du vælge knappen Hent data . Dette starter en guidet proces i stedet for at gå til et bestemt dataområde.
I søgefeltet i Vælg datakilde skal du få vist typen odata.
Vælg OData fra resultaterne for nye kilder .
I tekstfeltet URL-adresse i visningen Opret forbindelse til datakilde skal du skrive teksten:
https://services.odata.org/v4/northwind/northwind.svc/for Open Data feed for eksempeldatabasenNorthwind. Vælg knappen Næste for at fortsætte.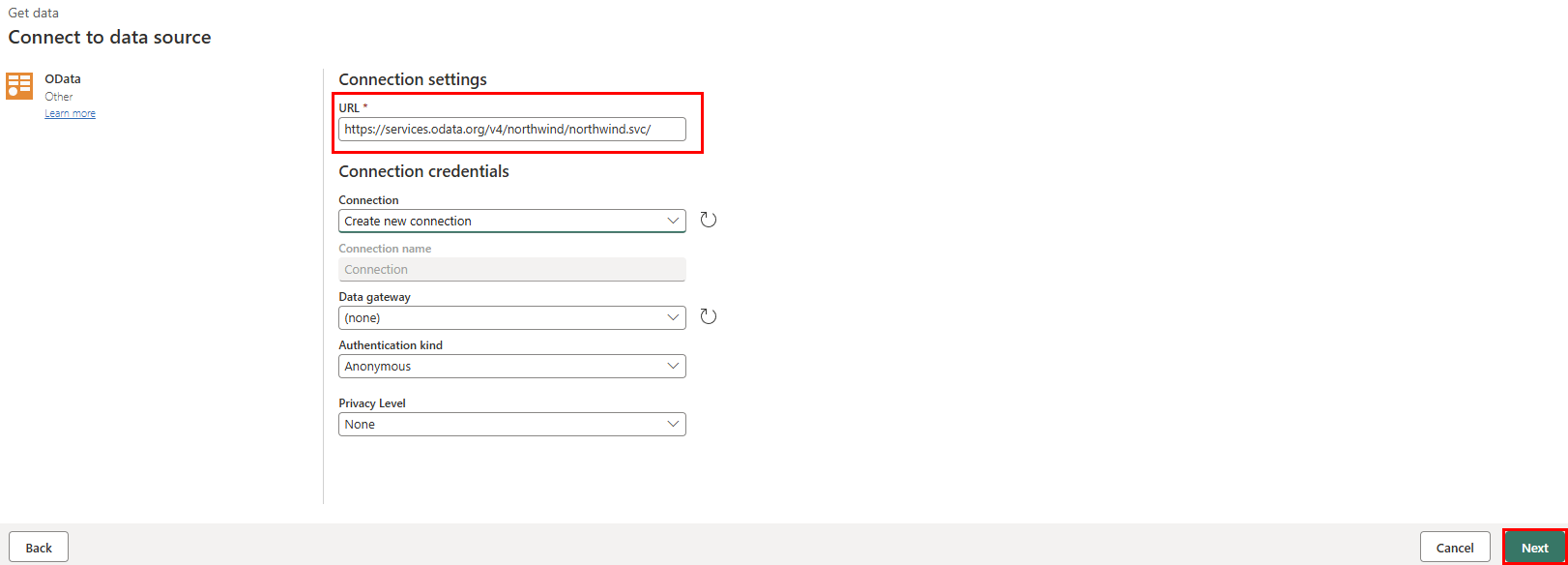
Rul ned til tabellen Suppliers fra OData-feedet, og markér afkrydsningsfeltet ud for det. Vælg derefter knappen Opret .
Vælg + nu plussymbolet ud for afsnittet Datadestination i Forespørgselsindstillinger, og vælg SQL-database på listen.
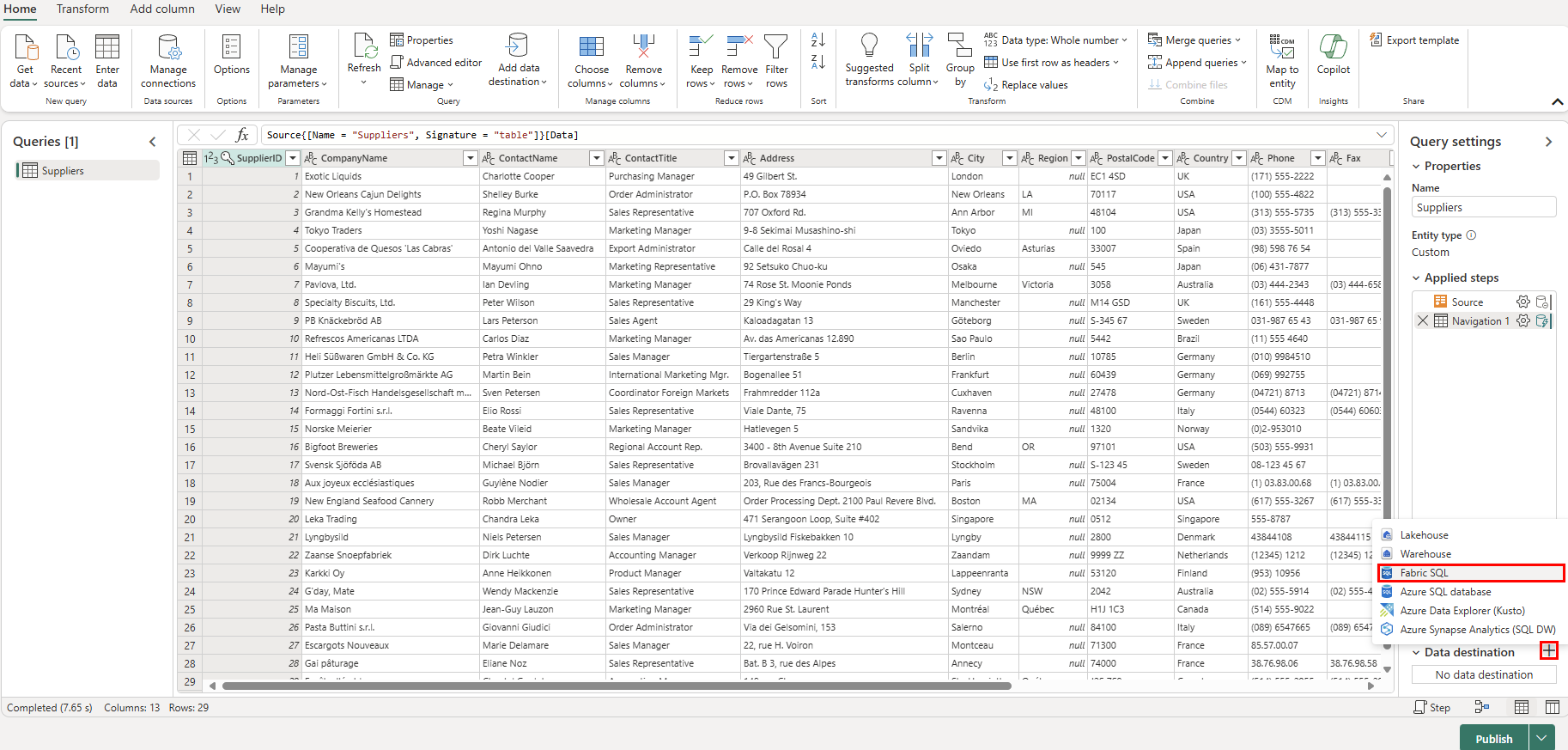
Kontrollér, at godkendelsestypen er angivet til Organisationskonto på siden Opret forbindelse til datadestination. Vælg Log på , og angiv dine legitimationsoplysninger til Microsoft Entra ID til databasen.
Når du har oprettet forbindelse, skal du vælge knappen Næste .
Vælg det arbejdsområdenavn, du oprettede i det første trin i dette selvstudium i afsnittet Vælg destinationsmål .
Vælg den database, der vises under den. Sørg for, at alternativknappen Ny tabel er valgt, og lad navnet på tabellen være Leverandører , og vælg knappen Næste .
Lad skyderen Brug automatiske indstillinger være angivet i visningen Vælg destinationsindstillinger , og vælg knappen Gem indstillinger .
Vælg knappen Publicer for at starte dataoverførslen.
Du vender tilbage til visningen Arbejdsområde, hvor du kan finde det nye dataflowelement.

Når kolonnen Opdateret viser den aktuelle dato og det aktuelle klokkeslæt, kan du vælge databasenavnet i Stifinder og derefter udvide skemaet
dbofor at få vist den nye tabel. (Du skal muligvis vælge Ikonet Opdater på værktøjslinjen.)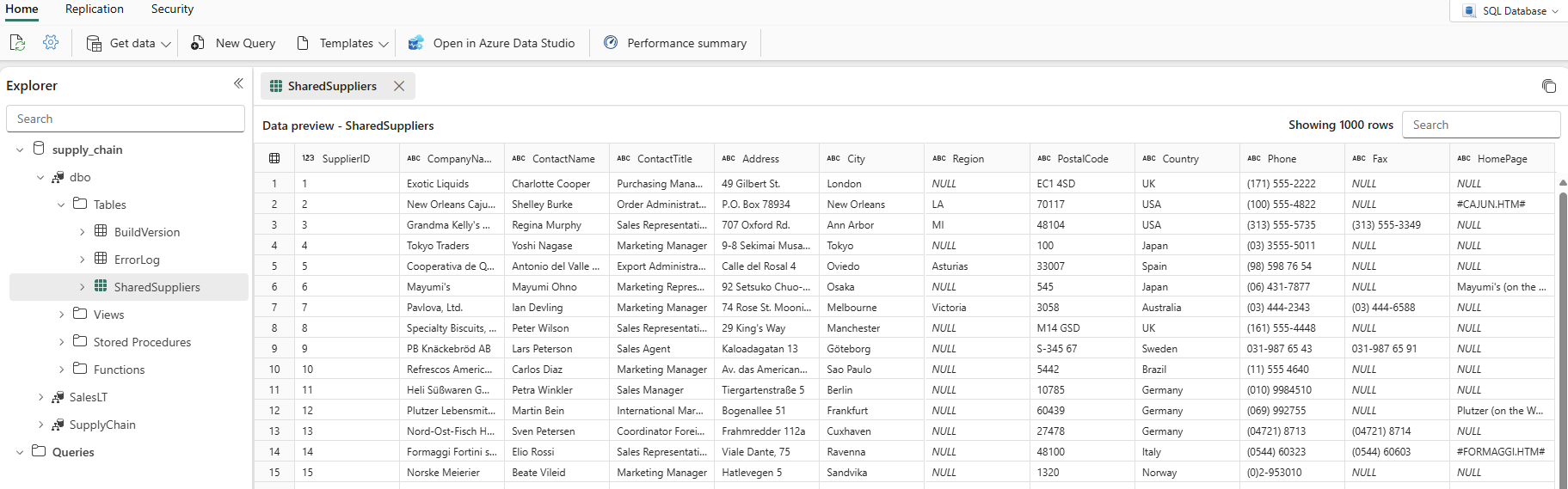




Dataene er nu indtaget i databasen. Du kan nu oprette en forespørgsel, der kombinerer dataene fra tabellen Suppliers ved hjælp af denne tertiære tabel. Det gør du senere i vores selvstudium.