CI/CD til spejlede databaser i Fabric (prøveversion)
I denne artikel forklares det, hvordan Git-integrations- og udrulningspipelines fungerer for spejlede databaser i Microsoft Fabric. Få mere at vide om, hvordan du konfigurerer en forbindelse til dit lager, administrerer dine spejlede databaser via Git og udruller dem på tværs af forskellige miljøer.
Seddel
Denne CI/CD-instruktion gælder ikke for spejlede databaser fra Azure Databricks.
Git-integration af spejlet database
Fra indstillingerne for dit arbejdsområde kan du nemt konfigurere en forbindelse til dit lager for at bekræfte og synkronisere ændringer. Hvis du vil konfigurere forbindelsen, skal du se Artiklen Kom i gang med Git-integration.
Når du har oprettet forbindelse, viser arbejdsområdet oplysninger om versionsstyring, der giver dig mulighed for at få vist den forbundne forgrening, status for hvert element i forgreningen og tidspunktet for den seneste synkronisering.
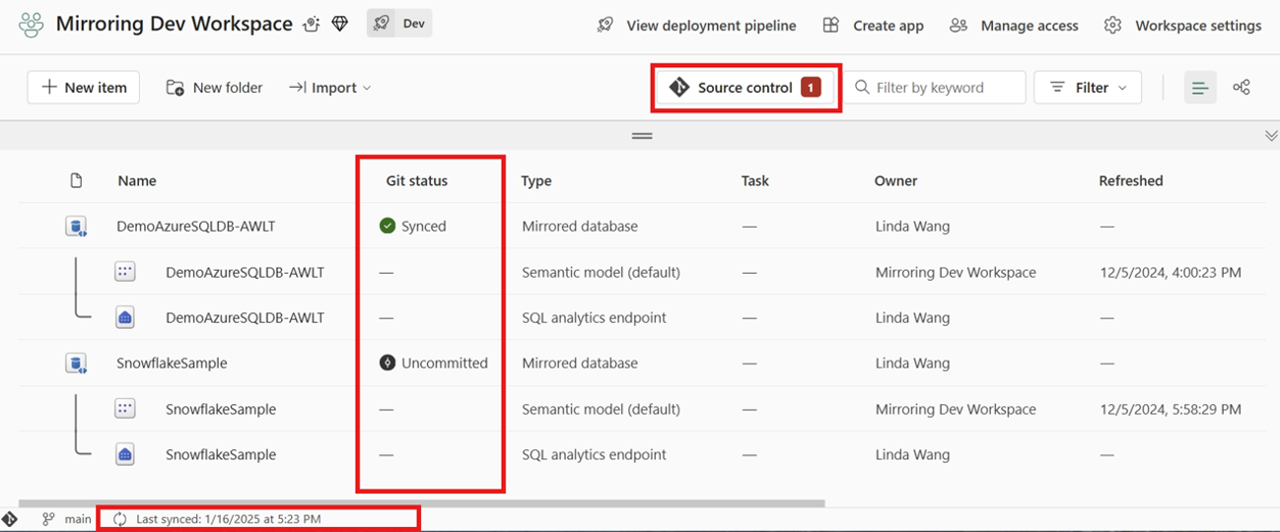
Du kan bekræfte ændringer af den spejlede database i Git eller opdatere arbejdsområdet fra Git ved at klikke på Versionskontrolelement.
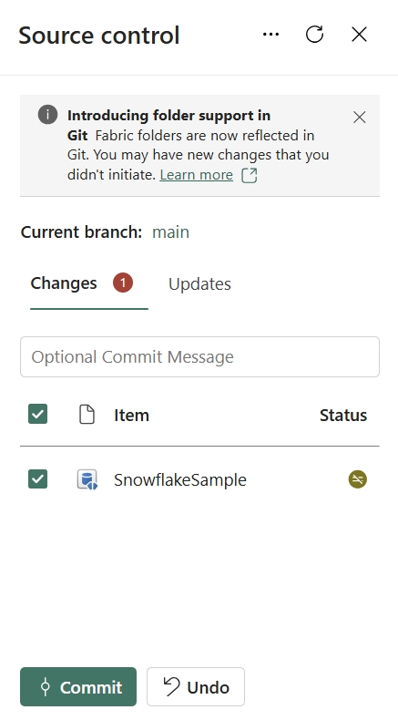
Spejlvendt databaserepræsentation i Git
Når du sender det spejlede databaseelement til Git-lageret, oprettes der en mappe for hvert element med navnet {display name}.MirroredDatabase. Den indeholder to filer:
-
mirroring.jsonfil, som er definitionen af den spejlede database. Få mere at vide om definition af spejlede databaseelement -
.platformfil, der genereres automatisk af systemet. Få mere at vide fra systemfil.
Seddel
Det er kun det spejlede databaseelement, der spores i Git. SQL Analytics-slutpunktet, standard semantisk model og andre underordnede elementer (f.eks. oprettede visninger) spores ikke.
Spejlet database i udrulningspipelines
Du kan bruge Fabric-udrulningspipeline til at udrulle din spejlede database på tværs af forskellige miljøer, f.eks. udvikling, test og produktion. Og du kan bruge udrulningsregler til at tilpasse kildedatabaserne, så de afspejles.
Udfør følgende trin for at installere den spejlede database ved hjælp af udrulningspipeline:
Opret en udrulningspipeline i Kom i gang med udrulningspipelines.
Tildel arbejdsområder til forskellige faser i henhold til dine udrulningsmål.
Vælg, få vist og sammenlign elementer, herunder spejlvendt database mellem forskellige faser.
Vælg Installér for at installere den spejlede database på tværs af faserne. Du får måske vist en advarsel om, at elementet (SQL Analytics-slutpunktet) ikke understøttes, ignoreres og fortsættes.
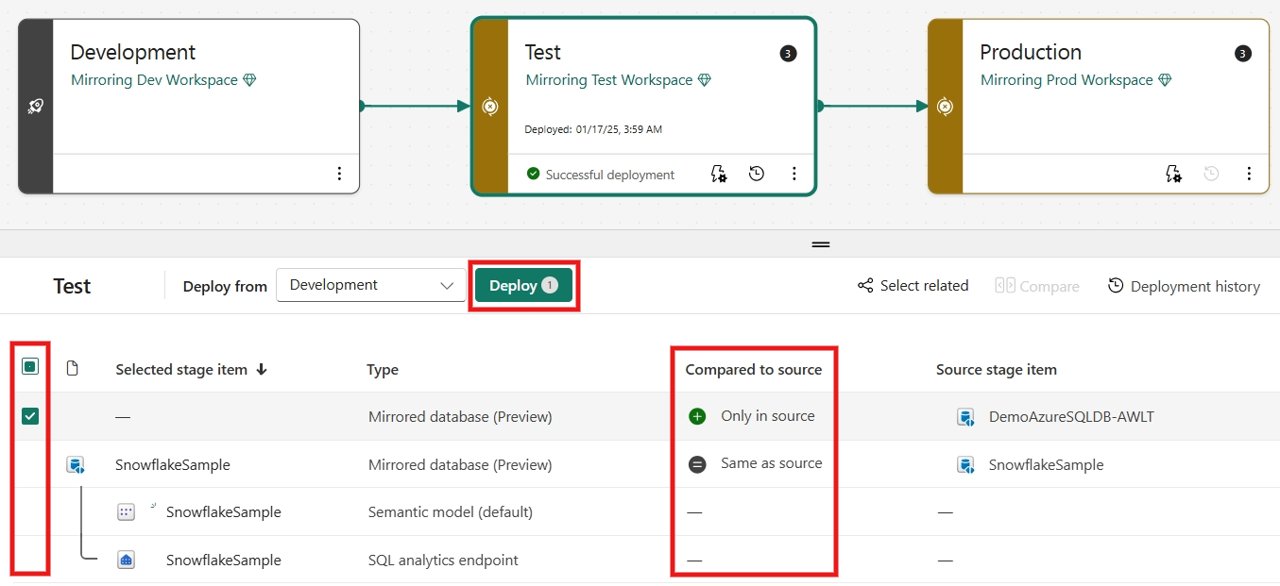
(Valgfrit) Hvis du vil spejle en anden kildedatabase i forhold til den forrige fase, skal du vælge Installationsregler for at oprette installationsregler, der for en installationsproces. Indtastning af installationsregler er på destinationsfasen for en udrulningsproces.

Fabric understøtter parameterisering af kildedatabasen for hvert spejlede databaseelement, når der installeres med udrulningsregler. Vælg den tilsvarende spejlede database –> Datakilderegler –> + Tilføj regel, angiv destinationsforbindelses-id'et og eventuelt databasen, hvis det er relevant for kildedatabasetypen. Du kan finde forbindelses-id'et fra Administrer forbindelser og gateways –> finde den oprettede forbindelse fra listen –> Indstillinger –> feltet Forbindelses-id.
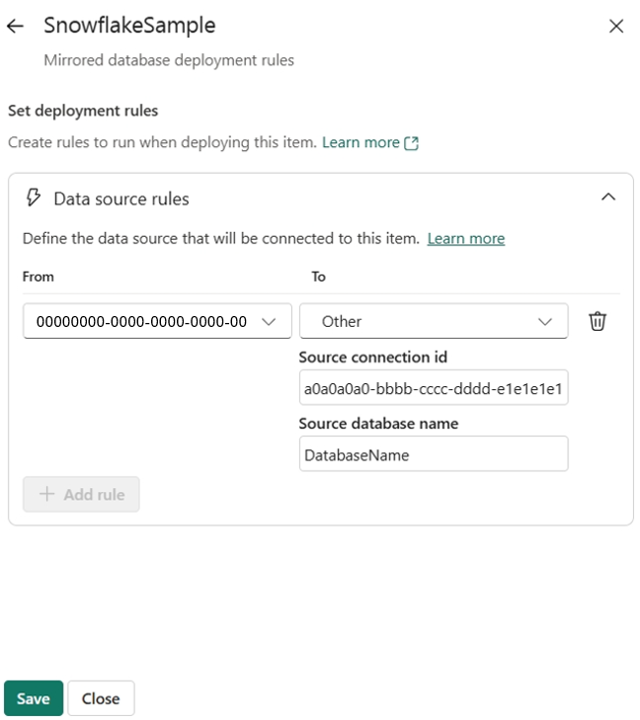
Når du har oprettet udrulningsreglerne, skal du installere de spejlede databaser med de nyligt oprettede regler fra kildefasen til den destinationsfase, hvor reglerne blev oprettet. Dine regler træder ikke i kraft, før du udruller den spejlede database fra kilden til destinationsfasen.
Overvåg installationsstatussen fra installationshistorik.
Vigtig
Den spejlede database startes ikke efter installationen. Du skal starte det manuelt eller via API.
Seddel
Underordnede elementer som oprettede visninger udrulles i øjeblikket ikke på tværs af faser.