Sådan får du adgang til spejlede Azure Cosmos DB-data i Lakehouse og notesbøger fra Microsoft Fabric (prøveversion)
I denne vejledning lærer du, hvordan du får adgang til spejlede Azure Cosmos DB-data i Lakehouse og notesbøger fra Microsoft Fabric (prøveversion).
Vigtigt
Spejling til Azure Cosmos DB er i øjeblikket en prøveversion. Produktionsarbejdsbelastninger understøttes ikke under prøveversionen. I øjeblikket understøttes kun Azure Cosmos DB for NoSQL-konti.
Forudsætninger
- En eksisterende Azure Cosmos DB til NoSQL-konto.
- Hvis du ikke har et Azure-abonnement, kan du prøve Azure Cosmos DB til NoSQL gratis.
- Hvis du har et eksisterende Azure-abonnement, skal du oprette en ny Azure Cosmos DB til NoSQL-konto.
- En eksisterende Fabric-kapacitet. Hvis du ikke har en eksisterende kapacitet, kan du starte en Fabric-prøveversion.
- Azure Cosmos DB for NoSQL-kontoen skal være konfigureret til Fabric-spejling. Du kan få flere oplysninger under Kontokrav.
Tip
I den offentlige prøveversion anbefales det at bruge en test- eller udviklingskopi af dine eksisterende Azure Cosmos DB-data, der hurtigt kan gendannes fra en sikkerhedskopi.
Konfigurer spejling og forudsætninger
Konfigurer spejling for Azure Cosmos DB for NoSQL-databasen. Hvis du er usikker på, hvordan du konfigurerer spejling, skal du se selvstudiet konfigurer spejlvendt database.
Opret en ny forbindelse og en spejlet database ved hjælp af legitimationsoplysningerne til din Azure Cosmos DB-konto.
Vent på, at replikeringen afslutter det første snapshot af data.
Få adgang til spejlede data i Lakehouse og notesbøger
Brug Lakehouse til yderligere at udvide antallet af værktøjer, du kan bruge til at analysere din Azure Cosmos DB for NoSQL-spejlede data. Her kan du bruge Lakehouse til at oprette en Spark-notesbog til at forespørge dine data.
Gå til stofportalens hjem igen.
Vælg Opret i navigationsmenuen.
Vælg Opret, find sektionen Dataudvikler ing, og vælg derefter Lakehouse.
Angiv et navn til Lakehouse, og vælg derefter Opret.
Vælg nu Hent data og derefter Ny genvej. Vælg Microsoft OneLake på listen over genvejsindstillinger.
Vælg den spejlede Azure Cosmos DB til NoSQL-database på listen over spejlede databaser i dit Fabric-arbejdsområde. Vælg de tabeller, der skal bruges sammen med Lakehouse, vælg Næste, og vælg derefter Opret.
Åbn genvejsmenuen for tabellen i Lakehouse, og vælg Ny eller eksisterende notesbog.
En ny notesbog åbnes automatisk og indlæser en dataramme ved hjælp af
SELECT LIMIT 1000.Kør forespørgsler, f.eks
SELECT *. ved hjælp af Spark.df = spark.sql("SELECT * FROM Lakehouse.OrdersDB_customers LIMIT 1000") display(df)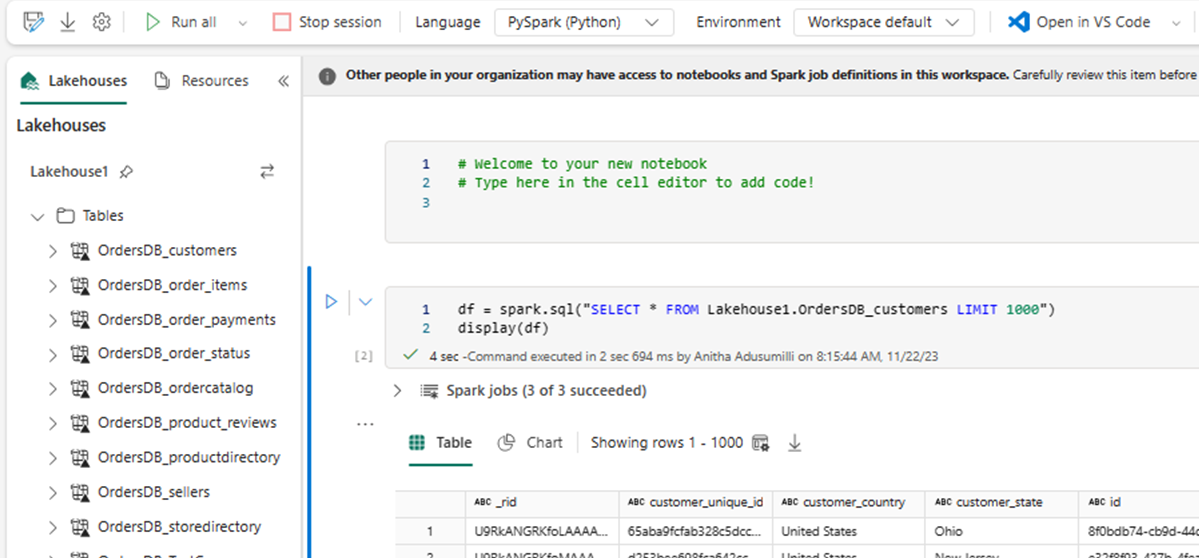
Bemærk
I dette eksempel antages navnet på tabellen. Brug din egen tabel, når du skriver din Spark-forespørgsel.

Skriv tilbage ved hjælp af Spark
Endelig kan du bruge Spark- og Python-kode til at skrive data tilbage til din azure Cosmos DB-kildekonto fra notesbøger i Fabric. Det kan være en god idé at gøre dette for at skrive analyseresultater tilbage til Cosmos DB, som derefter kan bruge som serveringsplan til OLTP-programmer.
Opret fire kodeceller i notesbogen.
Først skal du forespørge om dine spejlede data.
fMirror = spark.sql("SELECT * FROM Lakehouse1.OrdersDB_ordercatalog")Tip
Tabelnavnene i disse eksempelkodeblokke forudsætter et bestemt dataskema. Du er velkommen til at erstatte dette med dine egne tabel- og kolonnenavne.
Transformér og aggreger nu dataene.
dfCDB = dfMirror.filter(dfMirror.categoryId.isNotNull()).groupBy("categoryId").agg(max("price").alias("max_price"), max("id").alias("id"))Konfigurer derefter Spark til at skrive tilbage til din Azure Cosmos DB for NoSQL-konto ved hjælp af dine legitimationsoplysninger, databasenavn og objektbeholdernavn.
writeConfig = { "spark.cosmos.accountEndpoint" : "https://xxxx.documents.azure.com:443/", "spark.cosmos.accountKey" : "xxxx", "spark.cosmos.database" : "xxxx", "spark.cosmos.container" : "xxxx" }Til sidst skal du bruge Spark til at skrive tilbage til kildedatabasen.
dfCDB.write.mode("APPEND").format("cosmos.oltp").options(**writeConfig).save()Kør alle kodecellerne.
Vigtigt
Skrivehandlinger til Azure Cosmos DB bruger anmodningsenheder (RU'er).