Selvstudium: Indfødning af data i et lager
Gælder for:✅ Warehouse i Microsoft Fabric
I dette selvstudium kan du få mere at vide om, hvordan du indfødning af data fra Microsoft Azure Storage til et lager for at oprette tabeller.
Seddel
Dette selvstudium er en del af et end-to-end-scenarie. Hvis du vil fuldføre dette selvstudium, skal du først fuldføre disse selvstudier:
Indtag data
I denne opgave kan du få mere at vide om, hvordan du henter data til lageret for at oprette tabeller.
Sørg for, at det arbejdsområde, du oprettede i første selvstudium, er åbent.
I landingsruden for arbejdsområdet skal du vælge + Nyt element for at få vist en komplet liste over tilgængelige elementtyper.
På listen i afsnittet Hent data skal du vælge datapipeline elementtype.
I vinduet Ny pipeline skal du i feltet Navn angive
Load Customer Data.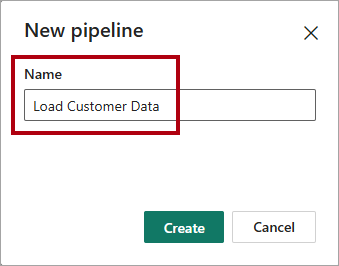
Hvis du vil klargøre pipelinen, skal du vælge Opret. Klargøringen er fuldført, når Opret en datapipeline landingsside vises.
På landingssiden for datapipelinen skal du vælge Pipelineaktivitet.

Vælg
Kopiér data inde fra afsnittet Flyt og transformér i menuen.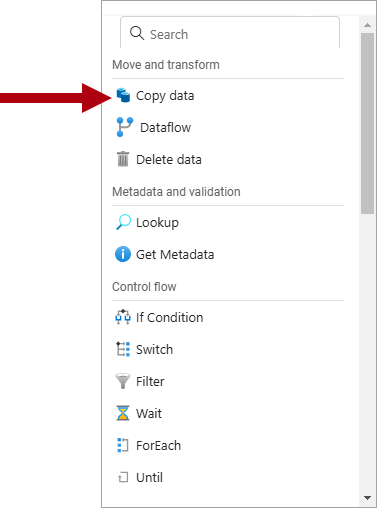
På pipelinedesignlærredet skal du vælge Kopiér data aktivitet.
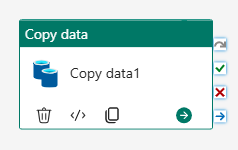
Hvis du vil konfigurere aktiviteten, skal du på siden Generelt i feltet Navn erstatte standardteksten med
CD Load dimension_customer.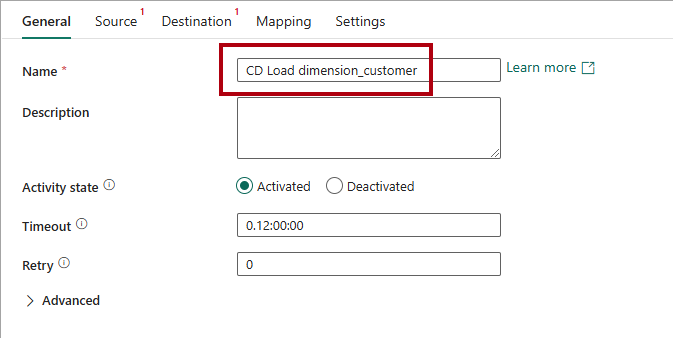
Vælg Flere på rullelisten Forbindelse på siden Kilde for at få vist alle de datakilder, du kan vælge imellem, herunder datakilder i OneLake-katalog.
Vælg + Ny for at oprette en ny datakilde.
Søg efter, og vælg derefter Azure Blobs.
Angiv
https://fabrictutorialdata.blob.core.windows.net/sampledata/i feltet Kontonavn eller URL-adresse på siden Opret forbindelse til datakilde .Bemærk, at rullelisten Forbindelsesnavn udfyldes automatisk, og at godkendelsestypen er angivet til Anonym.
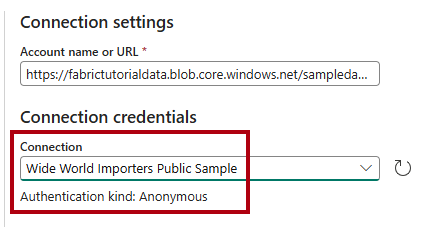
Vælg Opret forbindelse.
På siden Source skal du fuldføre følgende indstillinger for at få adgang til parquetfilerne i datakilden:
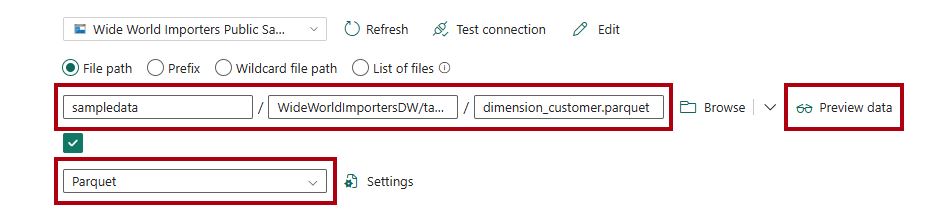
I felterne Filsti skal du skrive:
sti til fil – objektbeholder:
sampledataFilsti - mappe:
WideWorldImportersDW/tablesFilsti - Filnavn:
dimension_customer.parquet
Vælg
Parquet på rullelisten filformat .
Hvis du vil have vist dataene og teste, at der ikke er nogen fejl, skal du vælge Eksempeldata.
Vælg det
Wide World Importerslager på rullelisten Forbindelse på siden Destination.For tabelindstillingskal du vælge indstillingen Opret tabel automatisk.
Skriv
dboi det første tabelfelt .Skriv
dimension_customeri det andet felt.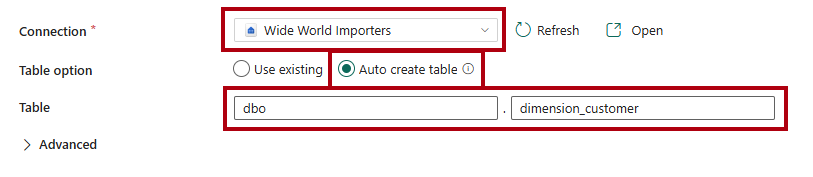
På båndet Hjem skal du vælge Kør.
I Gem og kør? dialogboks skal du vælge Gem og kør for at få pipelinen til at indlæse tabellen
dimension_customer.
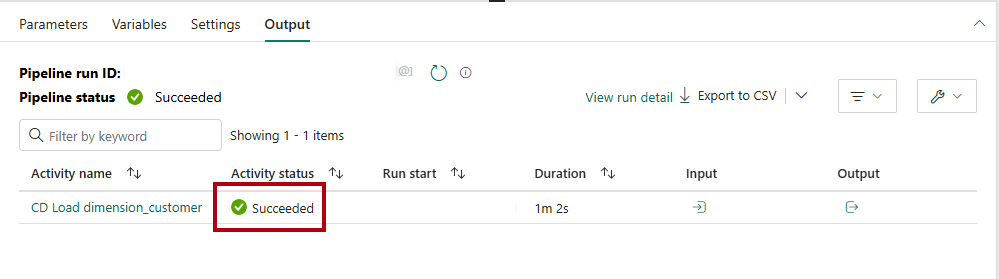
Hvis du vil overvåge status for kopiaktiviteten, skal du gennemse pipelinekørselsaktiviteterne på siden med Output (vent på, at den fuldføres med statussen Fuldført).