Scoring af model til maskinel indlæring med PREDICT i Microsoft Fabric
Microsoft Fabric giver brugerne mulighed for at anvende modeller til maskinel indlæring med den skalerbare PREDICT-funktion. Denne funktion understøtter batchscore i et hvilket som helst beregningsprogram. Brugerne kan generere batchforudsigelser direkte fra en Microsoft Fabric-notesbog eller fra elementsiden for en given ML-model.
I denne artikel lærer du, hvordan du anvender PREDICT ved selv at skrive kode eller ved hjælp af en guidet brugergrænsefladeoplevelse, der håndterer batchscore for dig.
Forudsætninger
Få et Microsoft Fabric-abonnement. Du kan også tilmelde dig en gratis Prøveversion af Microsoft Fabric.
Brug oplevelsesskifteren nederst til venstre på startsiden til at skifte til Fabric.

Begrænsninger
- Funktionen PREDICT understøttes i øjeblikket for dette begrænsede sæt ML-modelvarianter:
- Katboost
- Keras
- Lys GBM
- ONNX
- Profet
- Pytorch
- Sklearn
- Spark
- Statsmodeller
- TensorFlow
- XGBoost
- PREDICT kræver , at du gemmer ML-modeller i MLflow-formatet med deres signaturer udfyldt
- PREDICT understøtter ikke ML-modeller med input eller output med flere tensorer
Foretag et kald til PREDICT fra en notesbog
PREDICT understøtter MLflow-pakkede modeller i Microsoft Fabric-registreringsdatabasen. Hvis der findes en allerede oplært og registreret ML-model i dit arbejdsområde, kan du gå til trin 2. Hvis ikke, indeholder trin 1 eksempelkode, der guider dig gennem oplæring af en eksempel på logistisk regressionsmodel. Du kan bruge denne model til at generere batchforudsigelser i slutningen af proceduren.
Oplær en ML-model, og registrer den med MLflow. I det næste kodeeksempel bruges MLflow-API'en til at oprette et maskinel indlæringseksperiment og derefter starte en MLflow-kørsel for en logistisk regressionsmodel i scikit-learn. Modelversionen gemmes derefter og registreres i Microsoft Fabric-registreringsdatabasen. Besøg, hvordan du oplærer ML-modeller med scikit-learn-ressourcer for at få flere oplysninger om oplæringsmodeller og sporing af dine egne eksperimenter.
import mlflow import numpy as np from sklearn.linear_model import LogisticRegression from sklearn.datasets import load_diabetes from mlflow.models.signature import infer_signature mlflow.set_experiment("diabetes-demo") with mlflow.start_run() as run: lr = LogisticRegression() data = load_diabetes(as_frame=True) lr.fit(data.data, data.target) signature = infer_signature(data.data, data.target) mlflow.sklearn.log_model( lr, "diabetes-model", signature=signature, registered_model_name="diabetes-model" )Indlæs testdata som en Spark DataFrame. Hvis du vil generere batchforudsigelser med ml-modellen, der er oplært i det forrige trin, skal du bruge testdata i form af en Spark DataFrame. I følgende kode skal du erstatte den
testvariable værdi med dine egne data.# You can substitute "test" below with your own data test = spark.createDataFrame(data.frame.drop(['target'], axis=1))Opret et
MLFlowTransformerobjekt til indlæsning af ML-modellen til udledning. Hvis du vil oprette etMLFlowTransformerobjekt til oprettelse af batchforudsigelser, skal du udføre disse handlinger:- angiv de
testDataFrame-kolonner, du skal bruge som modelinput (i dette tilfælde dem alle) - vælg et navn til den nye outputkolonne (i dette tilfælde
predictions) - angiv det korrekte modelnavn og den korrekte modelversion til generering af disse forudsigelser.
Hvis du bruger din egen ML-model, skal du erstatte værdierne for inputkolonnerne, outputkolonnenavnet, modelnavnet og modelversionen.
from synapse.ml.predict import MLFlowTransformer # You can substitute values below for your own input columns, # output column name, model name, and model version model = MLFlowTransformer( inputCols=test.columns, outputCol='predictions', modelName='diabetes-model', modelVersion=1 )- angiv de
Generér forudsigelser ved hjælp af funktionen PREDICT. Hvis du vil aktivere funktionen PREDICT, skal du bruge Transformer-API'en, Spark SQL-API'en eller en Brugerdefineret PySpark-funktion (UDF). I følgende afsnit kan du se, hvordan du genererer batchforudsigelser med de testdata og ML-modellen, der er defineret i de forrige trin, ved hjælp af de forskellige metoder til at aktivere funktionen PREDICT.
FORUDSIG med Transformer-API'en
Denne kode aktiverer funktionen PREDICT med Transformer-API'en. Hvis du bruger din egen ML-model, skal du erstatte værdierne for modellen og teste data.
# You can substitute "model" and "test" below with values
# for your own model and test data
model.transform(test).show()
FORUDSIG med Spark SQL-API'en
Denne kode aktiverer funktionen PREDICT med Spark SQL-API'en. Hvis du bruger din egen ML-model, skal du erstatte værdierne for model_name, model_versionog features med modelnavnet, modelversionen og funktionskolonnerne.
Bemærk
Brug af Spark SQL-API'en til oprettelse af forudsigelse kræver stadig oprettelse af et MLFlowTransformer objekt (som vist i trin 3).
from pyspark.ml.feature import SQLTransformer
# You can substitute "model_name," "model_version," and "features"
# with values for your own model name, model version, and feature columns
model_name = 'diabetes-model'
model_version = 1
features = test.columns
sqlt = SQLTransformer().setStatement(
f"SELECT PREDICT('{model_name}/{model_version}', {','.join(features)}) as predictions FROM __THIS__")
# You can substitute "test" below with your own test data
sqlt.transform(test).show()
PREDICT med en brugerdefineret funktion
Denne kode aktiverer funktionen PREDICT med en PySpark UDF. Hvis du bruger din egen ML-model, skal du erstatte modellen og funktionerne med værdierne.
from pyspark.sql.functions import col, pandas_udf, udf, lit
# You can substitute "model" and "features" below with your own values
my_udf = model.to_udf()
features = test.columns
test.withColumn("PREDICT", my_udf(*[col(f) for f in features])).show()
Generér PREDICT-kode fra elementsiden for en ML-model
På elementsiden for en hvilken som helst ML-model kan du vælge en af disse indstillinger for at starte generering af batchforudsigelse for en bestemt modelversion med funktionen PREDICT:
- Kopiér en kodeskabelon til en notesbog, og tilpas selv parametrene
- Brug en guidet brugergrænsefladeoplevelse til at generere PREDICT-kode
Brug en guidet brugergrænsefladeoplevelse
Den guidede brugergrænsefladeoplevelse fører dig gennem disse trin:
- Vælg kildedataene til scoring
- Knyt dataene korrekt til input fra din ML-model
- Angiv destinationen for dine modeloutput
- Opret en notesbog, der bruger PREDICT til at generere og gemme forudsigelsesresultater
Hvis du vil bruge den guidede oplevelse,
Gå til elementsiden for en given ML-modelversion.
På rullelisten Anvend denne version skal du vælge Anvend denne model i guiden.

På trinnet "Vælg inputtabel" åbnes vinduet "Anvend ML-modelforudsigelser".
Vælg en inputtabel fra et lakehouse i dit aktuelle arbejdsområde.
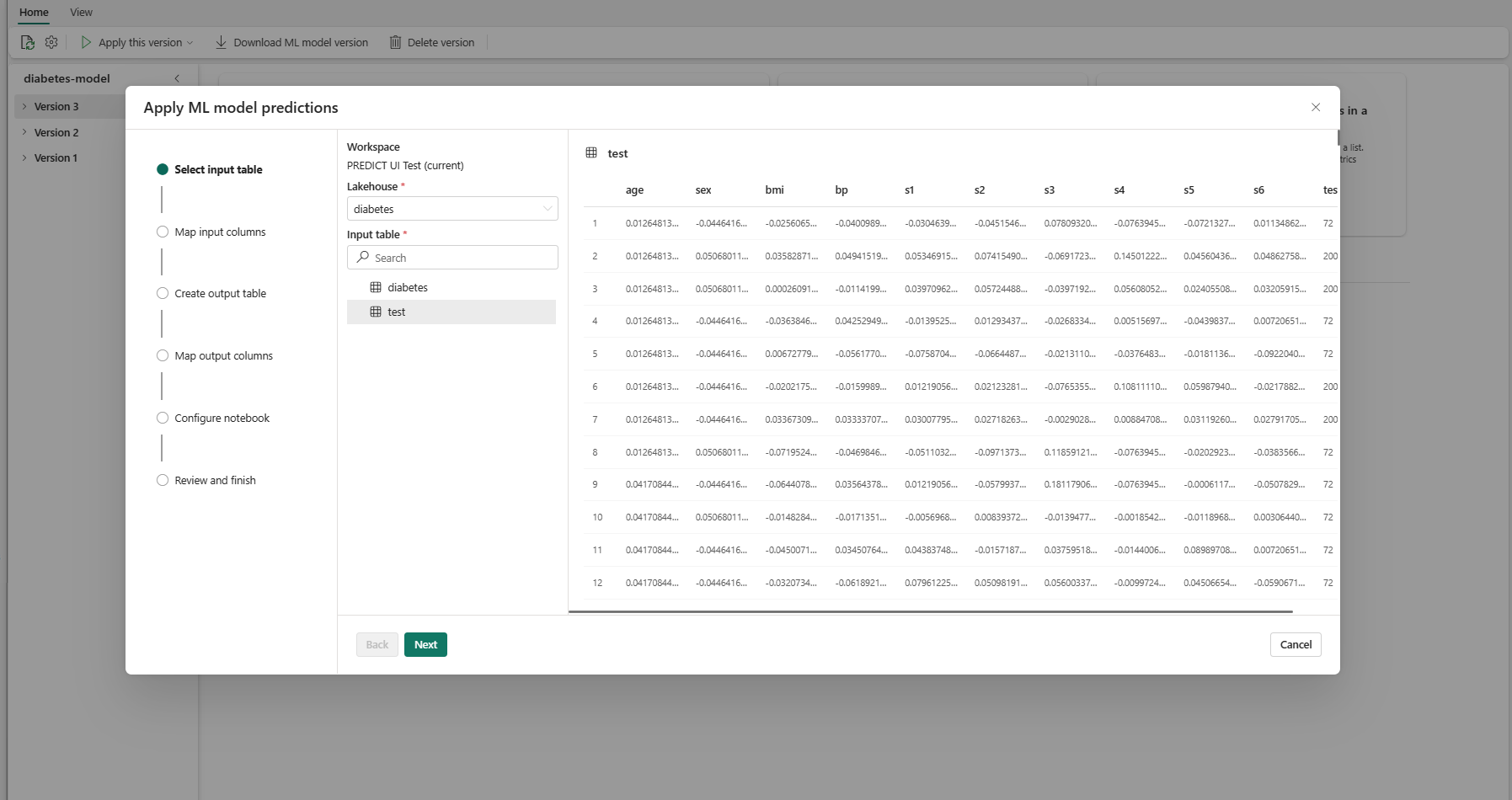
Vælg Næste for at gå til trinnet "Tilknyt inputkolonner".
Knyt kolonnenavne fra kildetabellen til ML-modellens inputfelter, som hentes fra modellens signatur. Du skal angive en inputkolonne for alle de påkrævede felter i modellen. Desuden skal datakilderne for kildekolonnen stemme overens med modellens forventede datatyper.
Tip
Guiden udfylder denne tilknytning på forhånd, hvis navnene på kolonnerne i inputtabellen stemmer overens med de kolonnenavne, der er logført i ML-modelsignaturen.
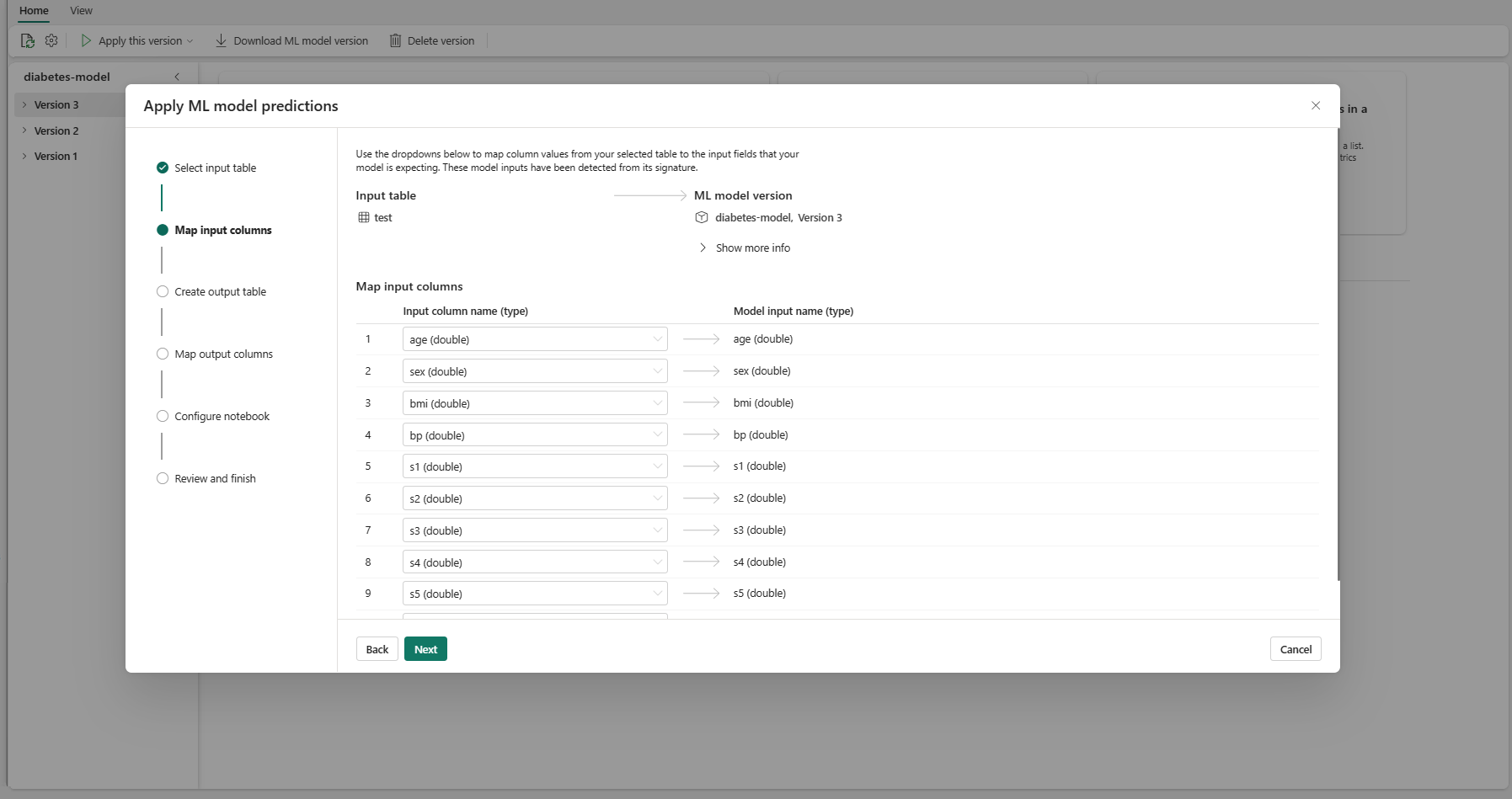
Vælg Næste for at gå til trinnet "Opret outputtabel".
Angiv et navn til en ny tabel i det valgte lakehouse i dit aktuelle arbejdsområde. I denne outputtabel gemmes inputværdierne for din ML-model, og forudsigelsesværdierne føjes til den pågældende tabel. Outputtabellen oprettes som standard i samme lakehouse som inputtabellen. Du kan ændre destination lakehouse.
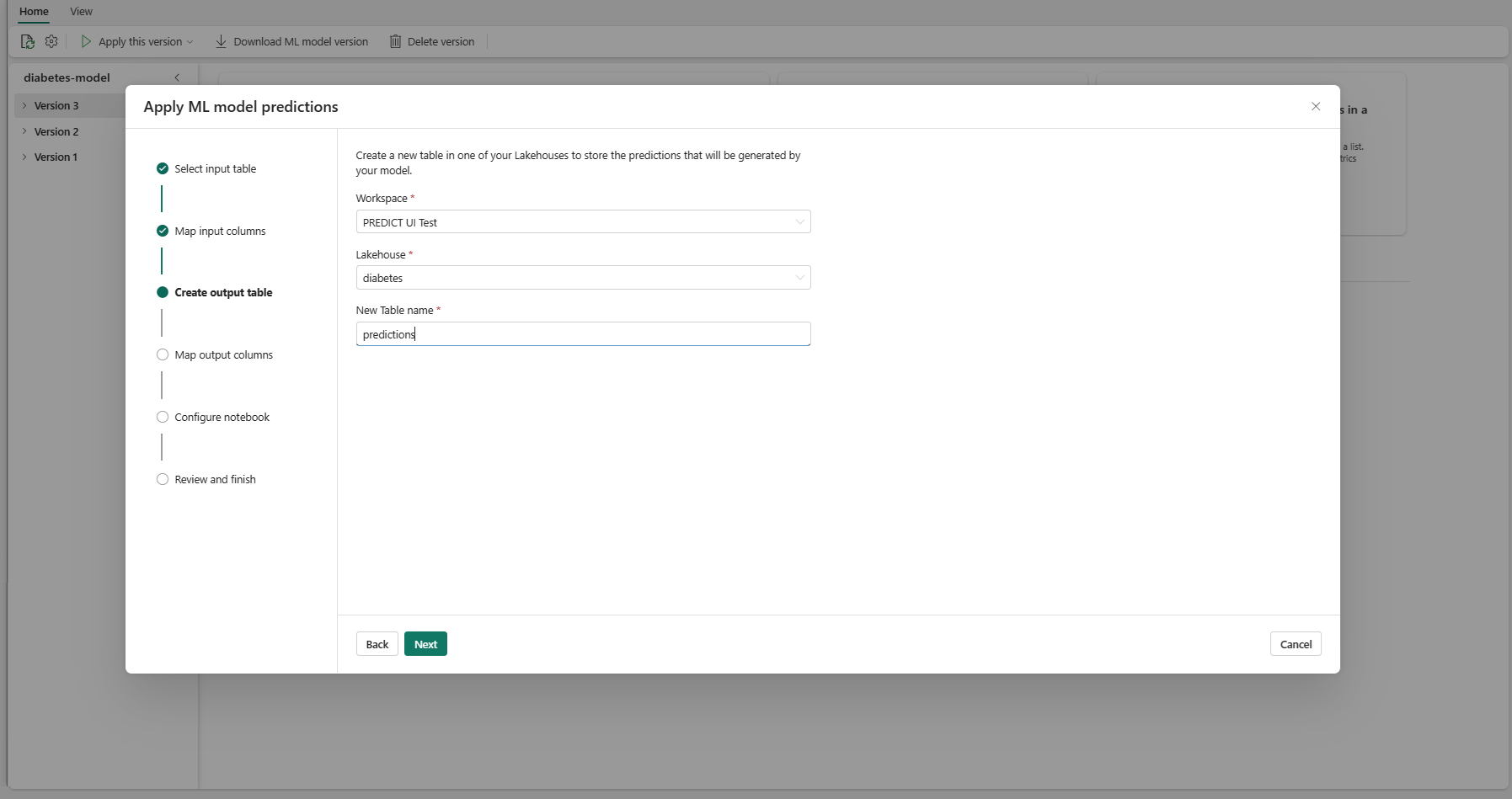
Vælg Næste for at gå til trinnet "Tilknyt outputkolonner".
Brug de angivne tekstfelter til at navngive kolonnerne i outputtabellen, der gemmer forudsigelserne for ML-modellen.
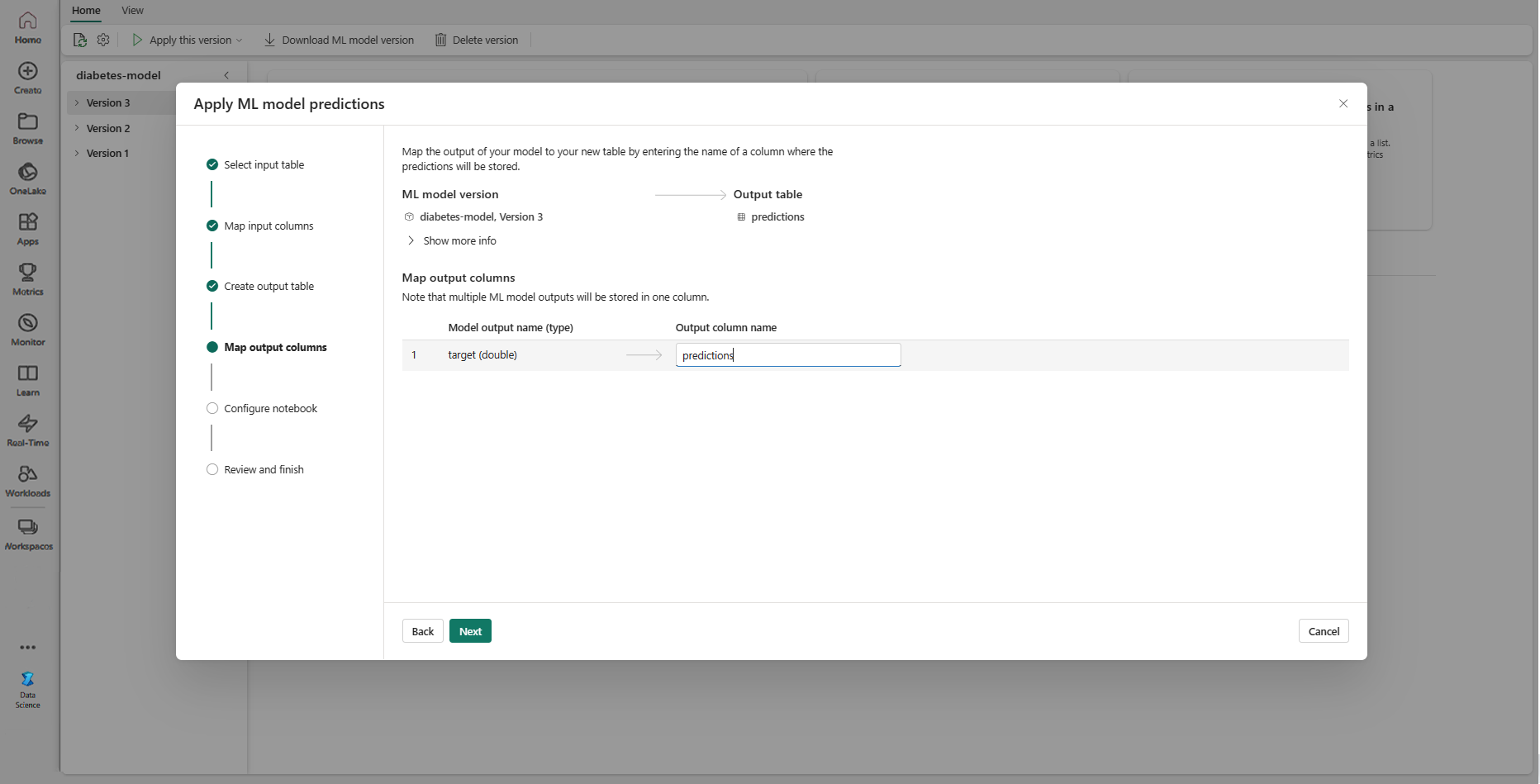
Vælg Næste for at gå til trinnet "Konfigurer notesbog".
Angiv et navn til en ny notesbog, der kører den genererede PREDICT-kode. Guiden viser et eksempel på den genererede kode på dette trin. Hvis du vil, kan du kopiere koden til udklipsholderen og indsætte den i en eksisterende notesbog.
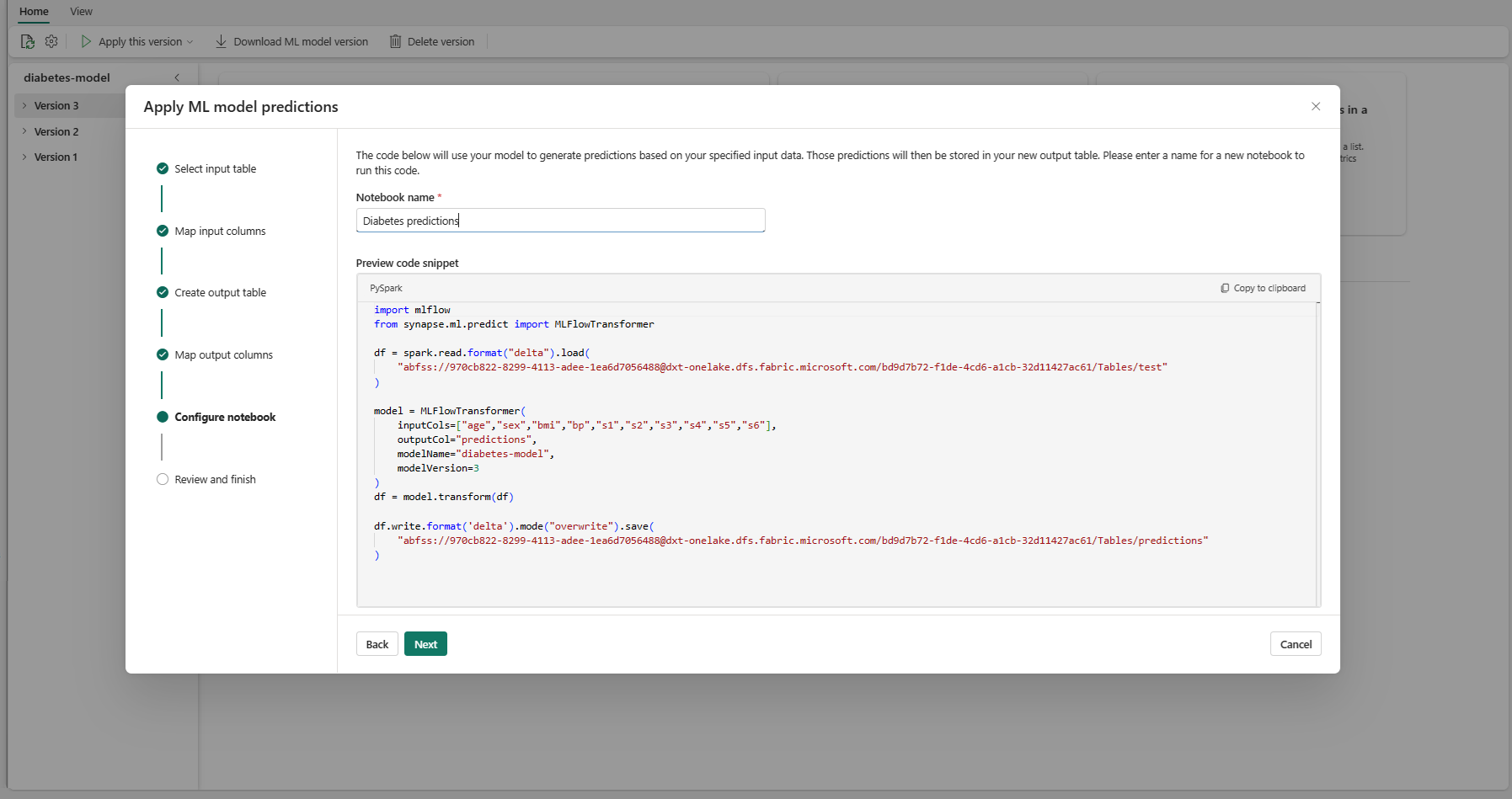
Vælg Næste for at gå til trinnet "Gennemse og afslut".
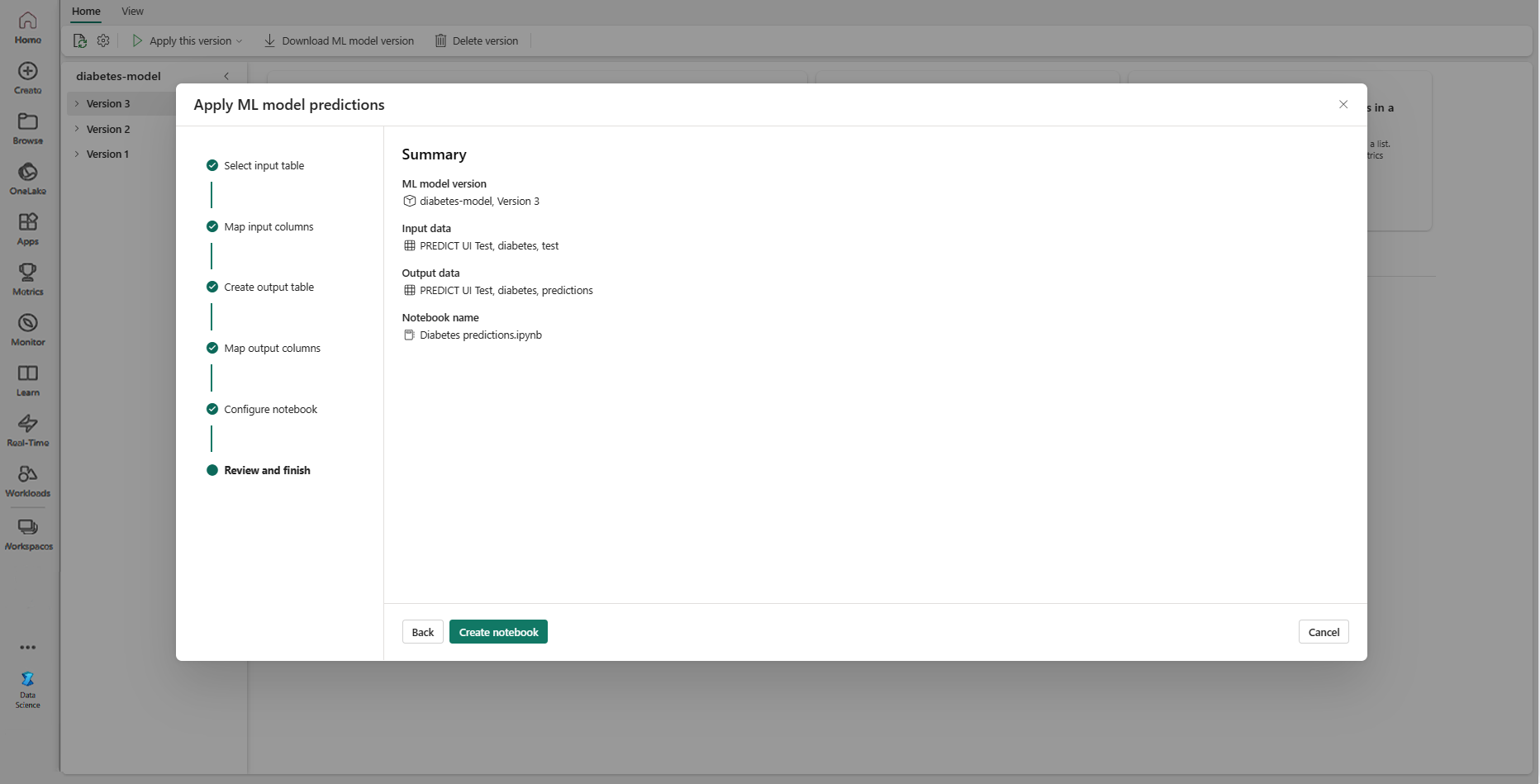
Gennemse oplysningerne på oversigtssiden, og vælg Opret notesbog for at føje den nye notesbog med den genererede kode til dit arbejdsområde. Du føres direkte til notesbogen, hvor du kan køre koden for at generere og gemme forudsigelser.







Brug en kodeskabelon, der kan tilpasses
Sådan bruges en kodeskabelon til generering af batchforudsigelser:
- Gå til elementsiden for en given ML-modelversion.
- Vælg Kopiér kode, der skal anvendes på rullelisten Anvend denne version . Med markeringen kan du kopiere en kodeskabelon, der kan tilpasses.
Du kan indsætte denne kodeskabelon i en notesbog for at generere batchforudsigelser med din ML-model. Hvis du vil køre kodeskabelonen, skal du manuelt erstatte følgende værdier:
-
<INPUT_TABLE>: Filstien til den tabel, der leverer input til ML-modellen -
<INPUT_COLS>: En matrix af kolonnenavne fra inputtabellen, der skal føjes til ML-modellen -
<OUTPUT_COLS>: Et navn til en ny kolonne i outputtabellen, der gemmer forudsigelser -
<MODEL_NAME>: Navnet på den ML-model, der skal bruges til at generere forudsigelser -
<MODEL_VERSION>: Den version af ML-modellen, der skal bruges til at generere forudsigelser -
<OUTPUT_TABLE>: Filstien til den tabel, der gemmer forudsigelserne

import mlflow
from synapse.ml.predict import MLFlowTransformer
df = spark.read.format("delta").load(
<INPUT_TABLE> # Your input table filepath here
)
model = MLFlowTransformer(
inputCols=<INPUT_COLS>, # Your input columns here
outputCol=<OUTPUT_COLS>, # Your new column name here
modelName=<MODEL_NAME>, # Your ML model name here
modelVersion=<MODEL_VERSION> # Your ML model version here
)
df = model.transform(df)
df.write.format('delta').mode("overwrite").save(
<OUTPUT_TABLE> # Your output table filepath here
)