Planlægning af din migrering fra Azure Data Factory
Microsoft Fabric er Microsofts SaaS-dataanalyseprodukt, der samler alle Microsofts markedsledende analyseprodukter i en enkelt brugeroplevelse. Fabric Data Factory leverer orkestrering af arbejdsprocesser, dataflytning, datareplikering og datatransformation i stor skala med lignende funktioner, der findes i Azure Data Factory (ADF). Hvis du har eksisterende ADF-investeringer, som du vil modernisere til Fabric Data Factory, er dette dokument nyttigt for at hjælpe dig med at forstå migreringsovervejelser, strategier og tilgange.
Overførsel fra Azure PaaS ETL/DI-tjenesterne ADF & Synapse-pipelines og dataflows kan give flere vigtige fordele:
- Nye integrerede pipelinefunktioner, herunder mail- og Teams-aktiviteter, gør det nemt at distribuere meddelelser under udførelse af pipelinen.
- Indbyggede funktioner til kontinuerlig integration og levering (CI/CD) (udrulningspipelines) kræver ikke ekstern integration med Git-lagre.
- Integration af arbejdsområder med din OneLake-datasø gør det nemt at administrere enkeltruder med glas.
- Det er nemt at opdatere dine semantiske datamodeller i Fabric med en fuldt integreret pipelineaktivitet.
Microsoft Fabric er en integreret platform til både selvbetjeningsdata og it-administrerede virksomhedsdata. Med eksponentiel vækst i datamængder og kompleksitet kræver Fabric-kunder virksomhedsløsninger, der skalerer, er sikre, nemme at administrere og tilgængelige for alle brugere på tværs af de største organisationer.
I de seneste år har Microsoft investeret en betydelig indsats for at levere skalerbare cloudfunktioner til Premium. Med henblik herpå giver Data Factory i Fabric øjeblikkeligt et stort økosystem af dataintegrationsudviklere og løsninger til dataintegration, der blev bygget i årtier for at anvende det fulde sæt funktioner og funktioner, der går langt ud over sammenlignelige funktioner, der er tilgængelige i tidligere generationer.
Kunderne spørger naturligvis, om der er mulighed for at konsolidere ved at hoste deres løsninger til dataintegration i Fabric. Almindelige spørgsmål omfatter:
- Er al den funktionalitet, vi er afhængige af, arbejdet i Fabric-pipelines?
- Hvilke funktioner er kun tilgængelige i Fabric-pipelines?
- Hvordan overfører vi eksisterende pipelines til Fabric-pipelines?
- Hvad er Microsofts oversigt over dataindtagelse i virksomheder?
Platformforskelle
Når du migrerer en hel ADF-forekomst, er der mange vigtige forskelle at overveje mellem ADF og Data Factory i Fabric, hvilket bliver vigtigt, når du migrerer til Fabric. Vi udforsker flere af disse vigtige forskelle i dette afsnit.
Hvis du vil have en mere detaljeret forståelse af den funktionelle tilknytning af funktionsforskelle mellem Azure Data Factory og Fabric Data Factory, skal du se Sammenlign datafabrik i Fabric og Azure Data Factory.
Kørsel af integration
I ADF er integrations runtimes (IR'er) konfigurationsobjekter, der repræsenterer beregning, der bruges af ADF til at fuldføre din databehandling. Disse konfigurationsegenskaber omfatter Azure-område til størrelser af cloudberegning og dataflow i Spark. Andre IR-typer omfatter selv hostede IR'er til dataforbindelse i det lokale miljø, SSIS-IR'er til kørsel af SQL Server Integration Services-pakker og Vnet-aktiverede cloud-IR'er.
Microsoft Fabric er et SaaS-produkt (software-as-a-service), mens ADF er et PaaS-produkt (platform-as-a-service). Det, denne skelnen betyder med hensyn til integrationskørsler, er, at du ikke behøver at konfigurere noget for at bruge pipelines eller dataflow i Fabric, da standarden er at bruge cloudbaseret beregning i det område, hvor dine Fabric-kapaciteter er placeret. SSIS-IR'er findes ikke i Fabric, og til dataforbindelser i det lokale miljø bruger du en Fabric-specifik komponent, der kaldes datagateway i det lokale miljø (OPDG). Og til virtuelle netværksbaserede forbindelser til sikre netværk kan du bruge Virtual Network Data Gateway i Fabric.
Når du migrerer fra ADF til Fabric, behøver du ikke at overføre azure-id'er (cloud) på det offentlige netværk. Du skal genoprette dine SHIR'er som OPDG'er og virtuelle netværk aktiverede Azure IR'er som Virtual Network Data Gateways.
Rørledninger
Pipelines er den grundlæggende komponent i ADF, som bruges til den primære arbejdsproces og orkestrering af dine ADF-processer til dataflytning, datatransformation og procesorkestrering. Pipelines i Fabric Data Factory er næsten identiske med ADF, men med ekstra komponenter, der passer til SaaS-modellen baseret på Power BI-brønden. Denne lighed omfatter oprindelige aktiviteter for mails, Teams og semantiske modelopdateringer.
JSON-definitionen af pipelines i Fabric Data Factory adskiller sig lidt fra ADF på grund af forskelle i programmodellen mellem de to produkter. På grund af denne forskel er det ikke muligt at kopiere/indsætte pipeline-JSON, importere/eksportere pipelines eller pege på et ADF Git-lager.
Når du genopbygger dine ADF-pipelines som Fabric-pipelines, bruger du stort set de samme arbejdsprocesmodeller og færdigheder, som du brugte i ADF. Den primære overvejelse har at gøre med Linked Services og Datasæt, som er begreber i ADF, der ikke findes i Fabric.
Sammenkædede tjenester
I ADF definerer Linked Services de forbindelsesegenskaber, der er nødvendige for at oprette forbindelse til dine datalagre til dataflytning, datatransformation og databehandlingsaktiviteter. I Fabric skal du genskabe disse definitioner som Forbindelser, der er egenskaber for dine aktiviteter, f.eks. Kopiér og Dataflow.
Datasæt
Datasæt definerer formen, placeringen og indholdet af dine data i ADF, men findes ikke som enheder i Fabric. Hvis du vil definere dataegenskaber som datatyper, kolonner, mapper, tabeller osv. i Fabric Data Factory-pipelines, skal du definere disse egenskaber indbygget i pipelineaktiviteter og i det Connection-objekt, der tidligere refereres til i afsnittet Linked Service.
Dataflow
I Data Factory for Fabric refererer udtrykket dataflow til de kodefrie datatransformationsaktiviteter, mens den samme funktion i ADF kaldes dataflows. Fabric Data Factory-dataflow har en brugergrænseflade, der er baseret på Power Query, som bruges i ADF Power Query-aktiviteten. Den beregning, der bruges til at udføre dataflow i Fabric, er et oprindeligt udførelsesprogram, der kan skaleres ud til datatransformation i stor skala ved hjælp af det nye Fabric Data Warehouse-beregningsprogram.
I ADF er dataflow bygget på Synapse Spark-infrastrukturen og defineret ved hjælp af en brugergrænseflade til konstruktion, der bruger et underliggende domænespecifikt sprog (DSL), der kaldes dataflowscript. Dette definitionssprog adskiller sig betydeligt fra de Power Query-baserede dataflow i Fabric, der bruger et definitionssprog, der kaldes M- til at definere deres funktionsmåde. På grund af disse forskelle i brugergrænseflader, sprog og kørselsprogrammer er Fabric dataflows og ADF-dataflow ikke kompatible, og du skal genskabe dine ADF-dataflows som Fabric dataflow, når du opgraderer dine løsninger til Fabric.
Udløser
Udløsere signal ADF til at udføre en pipeline baseret på en væg-ur tidsplan, tumbling vindue tid udsnit, fil-baserede hændelser, eller brugerdefinerede hændelser. Disse funktioner er ens i Fabric, selvom den underliggende implementering er anderledes.
I Fabric findes udløsere kun som et pipelinekoncept. Den større struktur, som pipelinen udløser brug i Fabric, kaldes Data Activator, som er et hændelses- og advarselsundersystem i realtidsintelligensfunktionerne i Fabric.
Fabric Data Activator har beskeder, der kan bruges til at oprette filhændelses- og brugerdefinerede hændelsesudløsere. Mens tidsplanudløsere er en separat enhed i Fabric, der kaldes tidsplaner. Disse tidsplaner er på platformniveau i Fabric og er ikke specifikke for pipelines. De kaldes heller ikke udløsere i Fabric.
Hvis du vil migrere dine udløsere fra ADF til Fabric, skal du overveje at genopbygge dine tidsplanudløsere blot som tidsplaner, der er egenskaber for dine Fabric-pipelines. Og for alle andre udløsertyper skal du bruge knappen Udløsere i Fabric-pipelinen eller bruge Data activator oprindeligt i Fabric.
Fejlfinding
Fejlfindingspipelines er enklere i Fabric end i ADF. Denne enkelhed skyldes, at Fabric Data Factory-pipelines ikke har et separat begreb om fejlfindingstilstand, som du finder i ADF-pipelines og dataflows. Når du bygger din pipeline, er du i stedet altid i interaktiv tilstand. Hvis du vil teste og foretage fejlfinding af dine pipelines, skal du kun vælge afspilningsknappen på værktøjslinjen Pipelineeditor, når du er klar i din udviklingscyklus. Pipelines i Fabric omfatter ikke fejlfinding, før trinvist fejlfindingsmønster interaktivt. I stedet bruger du aktivitetstilstanden i Fabric og angiver kun de aktiviteter, du vil teste som aktive, mens du angiver alle andre aktiviteter til inaktive for at opnå de samme test- og fejlfindingsmønstre. Se følgende video, der gennemgår, hvordan du opnår denne fejlfindingsoplevelse i Fabric.
Skift datahentning
Change Data Capture (CDC) i ADF er en prøveversionsfunktion, der gør det nemt at flytte data hurtigt trinvist ved at anvende CDC-funktioner på kildesiden i dine datalagre. Hvis du vil overføre dine CDC-artefakter til Fabric Data Factory, skal du genskabe disse artefakter som Kopiér job elementer i dit Fabric-arbejdsområde. Denne funktion indeholder lignende funktioner til trinvis dataflytning med en brugervenlig brugergrænseflade uden at kræve en pipeline, ligesom i ADF CDC. Du kan få flere oplysninger i Kopiér job til Data Factory i Fabric.
Azure Synapse-link
Selvom synapse-pipelinebrugerne ikke er tilgængelige i ADF, bruger de ofte Azure Synapse Link til at replikere data fra SQL-databaser til deres data lake i en nøglefærdig tilgang. I Fabric genskaber du Azure Synapse Link-artefakterne som spejlingselementer i dit arbejdsområde. Du kan få flere oplysninger under Fabric -databasespejling.
SQL Server Integration Services (SSIS)
SSIS er det lokale dataintegrations- og ETL-værktøj, som Microsoft leveres med SQL Server. I ADF kan du løfte og flytte dine SSIS-pakker til skyen ved hjælp af ADF SSIS IR. I Fabric har vi ikke begrebet IR, så denne funktionalitet er ikke mulig i dag. Vi arbejder dog på at muliggøre udførelse af SSIS-pakke oprindeligt fra Fabric, som vi håber at bringe til produktet snart. I mellemtiden er den bedste måde at udføre SSIS-pakker i cloudmiljøet med Fabric Data Factory på at starte en SSIS IR på din ADF-fabrik og derefter aktivere en ADF-pipeline for at kalde dine SSIS-pakker. Du kan fjernkalde en ADF-pipeline fra dine Fabric-pipelines ved hjælp af den aktiverede pipelineaktivitet, der er beskrevet i følgende afsnit.
Aktivér pipelineaktivitet
En almindelig aktivitet, der bruges i ADF-pipelines, er den Udfør pipelineaktivitet som giver dig mulighed for at kalde en anden pipeline på din fabrik. I Fabric har vi forbedret denne aktivitet som pipelineaktiviteten Invoke. Se dokumentationen til Invoke-pipelineaktivitet.
Denne aktivitet er nyttig til migreringsscenarier, hvor du har mange ADF-pipelines, der bruger ADF-specifikke funktioner, f.eks. Tilknytning af dataflow eller SSIS. Du kan vedligeholde disse pipelines as-is i ADF- eller endda Synapse-pipelines og derefter kalde pipelinen indbygget fra din nye Fabric Data Factory-pipeline ved hjælp af Aktivér pipelineaktivitet og pege på fjernfabrikspipelinen.
Eksempel på overførselsscenarier
Følgende scenarier er almindelige migreringsscenarier, som du kan støde på, når du migrerer fra ADF til Fabric Data Factory.
Scenarie 1: ADF-pipelines og dataflow
De primære use cases til migreringer på fabrikker er baseret på modernisering af dit ETL-miljø fra ADF-fabrikken PaaS-modellen til den nye Fabric SaaS-model. De primære fabrikselementer, der skal overføres, er pipelines og dataflows. Der er flere grundlæggende fabrikselementer, som du skal planlægge til migrering uden for disse to elementer på øverste niveau: sammenkædede tjenester, integrationskørsler, datasæt og udløsere.
- Linkede tjenester skal oprettes igen i Fabric som forbindelser i dine pipelineaktiviteter.
- Datasæt findes ikke i Factory. Egenskaberne for dine datasæt repræsenteres som egenskaber i pipelineaktiviteter, f.eks. Kopiér eller Opslag, mens Forbindelser indeholder andre datasætegenskaber.
- Integrationskørsler findes ikke i Fabric. Dine selv hostede IR'er kan dog genoprettes ved hjælp af OPDG (On-Premises Data Gateways) i Fabric og Azure Virtual Network IR som administrerede virtuelle netværksgateways i Fabric.
- Disse ADF-pipelineaktiviteter er ikke inkluderet i Fabric Data Factory:
- Data Lake Analytics (U-SQL) – Denne funktion er en forældet Azure-tjeneste.
- Valideringsaktivitet – Valideringsaktiviteten i ADF er en hjælpeaktivitet, som du nemt kan genopbygge i dine Fabric-pipelines ved hjælp af en Hent metadata-aktivitet, en pipelineløkke og en If-aktivitet.
- Power Query – I Fabric bygges alle dataflow ved hjælp af Brugergrænsefladen i Power Query, så du kan blot kopiere og indsætte din M-kode fra dine ADF Power Query-aktiviteter og bygge dem som dataflow i Fabric.
- Hvis du bruger en af de ADF-pipelinefunktioner, der ikke findes i Fabric Data Factory, kan du bruge Aktivér pipelineaktivitet i Fabric til at kalde dine eksisterende pipelines i ADF.
- Følgende ADF-pipelineaktiviteter kombineres til en enkelt aktivitet:
- Azure Databricks-aktiviteter (Notesbog, Jar, Python)
- Azure HDInsight (Hive, Pig, MapReduce, Spark, Streaming)
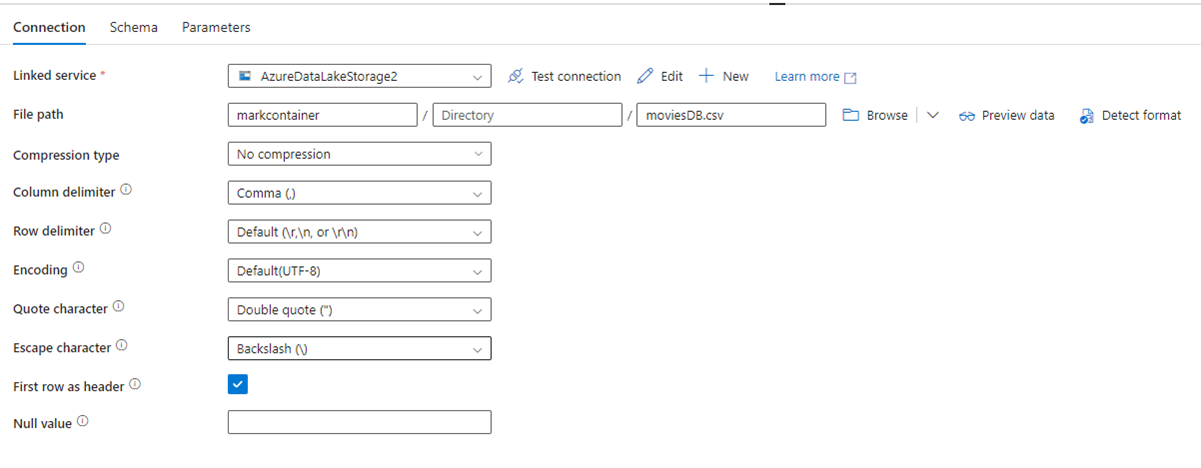
På følgende billede vises konfigurationssiden for ADF-datasættet med filstien og komprimeringsindstillingerne:
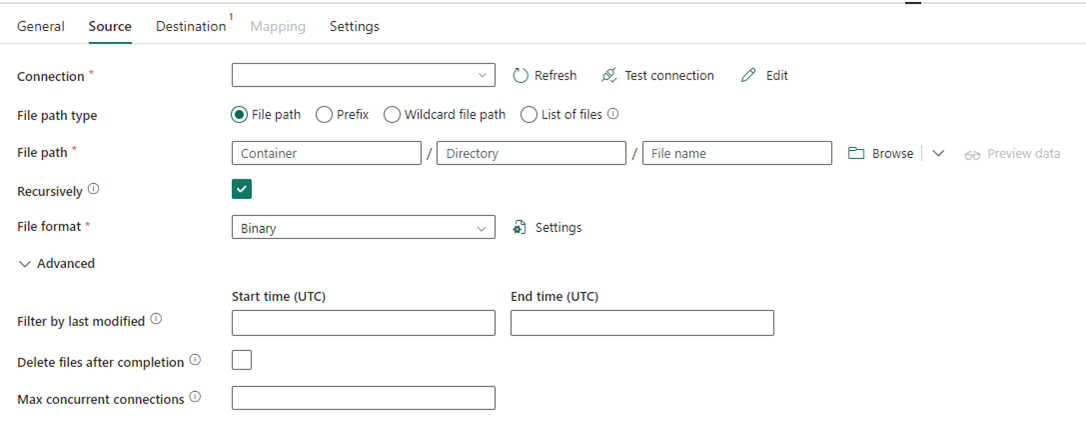
På følgende billede vises konfigurationen af kopiaktiviteten for Data Factory i Fabric, hvor komprimerings- og filstien er indbygget i aktiviteten:
Scenarie nr. 2: ADF med CDC, SSIS og luftflow
CDC & Airflow i ADF er prøveversionsfunktioner, mens SSIS i ADF er en offentlig tilgængelig funktion i mange år. Hver af disse funktioner opfylder forskellige behov for dataintegration, men kræver særlig opmærksomhed, når du migrerer fra ADF til Fabric. CDC (Change Data Capture) er et ADF-koncept på øverste niveau, men i Fabric kan du se denne funktion som Kopiér job.
Airflow er den ADF-cloudadministrerede Apache Airflow-funktion og er også tilgængelig i Fabric Data Factory. Du bør kunne bruge det samme Lager med Airflow-kilde eller tage dine DAG'er og kopiere/indsætte koden i Fabric Airflow-tilbuddet med meget lidt eller ingen ændring, der kræves.
Scenarie 3: Migrering af Git-aktiverede datafabrikker til Fabric
Det er almindeligt, selvom det ikke er påkrævet, at dine ADF- eller Synapse-fabrikker og arbejdsområder er forbundet med din egen eksterne Git-udbyder i ADO eller GitHub. I dette scenarie skal du overføre dine fabriks- og arbejdsområdeelementer til et Fabric-arbejdsområde og derefter konfigurere Git-integration på dit Fabric-arbejdsområde.
Fabric indeholder to primære måder at aktivere CI/CD på, både på arbejdsområdeniveau: Git-integration, hvor du medbringer dit eget Git-lager i ADO og opretter forbindelse til det fra Fabric og indbyggede udrulningspipelines, hvor du kan hæve kode til højere miljøer uden at skulle medbringe din egen Git.
I begge tilfælde fungerer dit eksisterende Git-lager fra ADF ikke sammen med Fabric. Du skal i stedet pege på et nyt lager eller starte en ny udrulningspipeline i Fabric og genopbygge dine pipelineartefakter i Fabric.
Tilslut dine eksisterende ADF-forekomster direkte til et Fabric-arbejdsområde
Tidligere talte vi om at bruge Fabric Data Factory Invoke Pipeline-aktiviteten som en mekanisme til at vedligeholde eksisterende ADF-pipelineinvesteringer og kalde dem indbyggede fra Fabric. Inden for Fabric kan du tage det lignende koncept et skridt videre og montere hele fabrikken i dit Fabric-arbejdsområde som en oprindelig Fabric-vare.
Du kan finde flere oplysninger om, hvordan du monterer forbrugsscenarier, under Scenarier med indholdssamarbejde og levering.
Det giver mange fordele at overveje at montere din Azure Data Factory i dit Fabric-arbejdsområde. Hvis du er ny bruger af Fabric og gerne vil holde dine fabrikker side om side inden for samme glasrude, kan du montere dem i Fabric, så du kan administrere begge dele i Fabric. Den komplette ADF-brugergrænseflade er nu tilgængelig for dig fra din tilsluttede fabrik, hvor du kan overvåge, administrere og redigere dine ADF-fabrikselementer fuldt ud fra Fabric-arbejdsområdet. Denne funktion gør det meget nemmere at begynde at migrere disse elementer til Fabric som oprindelige Fabric-artefakter. Denne funktion er primært til brugervenlighed og gør det nemt at se dine ADF-fabrikker i dit Fabric-arbejdsområde. Den faktiske udførelse af pipelines, aktiviteter, integrationskørsler osv. forekommer dog stadig i dine Azure-ressourcer.