Hurtig start: Flyt og transformér data med dataflow og datapipelines
I dette selvstudium finder du ud af, hvordan dataflow- og datapipelineoplevelsen kan skabe en effektiv og omfattende Data Factory-løsning.
Forudsætninger
Du skal have følgende forudsætninger for at komme i gang:
- En lejerkonto med et aktivt abonnement. Opret en gratis konto.
- Sørg for, at du har et Arbejdsområde, der er aktiveret af Microsoft Fabric: Opret et arbejdsområde, der ikke er standard for Mit arbejdsområde.
- En Azure SQL-database med tabeldata.
- En Blob Storage-konto.
Dataflow sammenlignet med pipelines
Med Dataflow Gen2 kan du bruge en grænseflade med lav kode og mere end 300 data og AI-baserede transformationer, så du nemt kan rense, forberede og transformere data med større fleksibilitet end noget andet værktøj. Datapipelines gør det muligt at oprette fleksible dataarbejdsprocesser, der opfylder virksomhedens behov, ved hjælp af avancerede orkestreringsfunktioner til dataorkestrering. I en pipeline kan du oprette logiske grupperinger af aktiviteter, der udfører en opgave, hvilket kan omfatte at kalde et dataflow for at rense og forberede dine data. Selvom der er nogle funktionalitetsoverlapninger mellem de to, afhænger valget af, hvilken du vil bruge til et bestemt scenarie, af, om du har brug for en komplet mængde pipelines, eller om du kan bruge de enklere, men mere begrænsede funktioner i dataflow. Du kan få flere oplysninger i Fabric-beslutningsvejledningen
Transformér data med dataflow
Følg disse trin for at konfigurere dit dataflow.
Trin 1: Opret et dataflow
Vælg dit Fabric-aktiverede arbejdsområde, og vælg derefter Ny. Vælg derefter Dataflow Gen2.
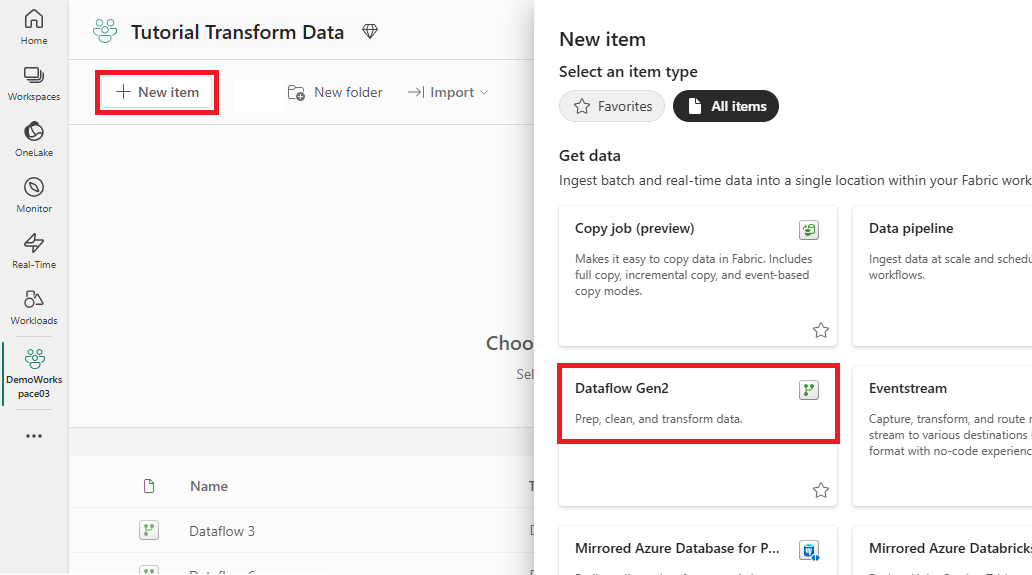
Vinduet datafloweditor vises. Vælg kortet Importér fra SQL Server.
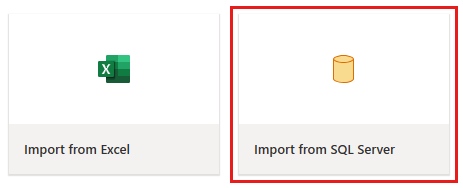

Trin 2: Hent data
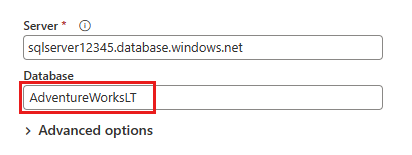
I dialogboksen Opret forbindelse til datakilde, der vises derefter, skal du angive detaljerne for at oprette forbindelse til din Azure SQL-database og derefter vælge Næste. I dette eksempel skal du bruge den AdventureWorksLT- eksempeldatabase, der konfigureres, når du konfigurerer Azure SQL-databasen i forudsætningerne.
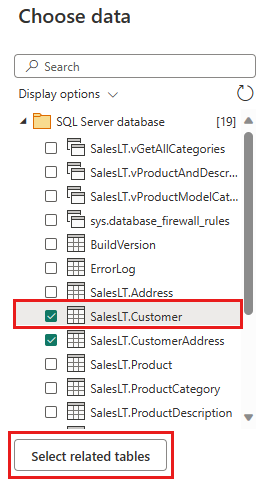
Vælg de data, du vil transformere, og vælg derefter Opret. I denne hurtige introduktion skal du vælge SalesLT.Customer- fra AdventureWorksLT- eksempeldata, der er angivet for Azure SQL DB, og derefter knappen Vælg relaterede tabeller for automatisk at inkludere to andre relaterede tabeller.


Trin 3: Transformér dine data
Hvis den ikke er markeret, skal du vælge knappen diagramvisning langs statuslinjen nederst på siden eller vælge Diagramvisning under menuen Vis øverst i Power Query-editoren. En af disse indstillinger kan slå diagramvisningen til eller fra.
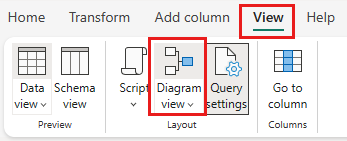
Højreklik på forespørgslen SalesLT Customer, eller vælg den lodrette ellipse til højre for forespørgslen, og vælg derefter Flet forespørgsler.
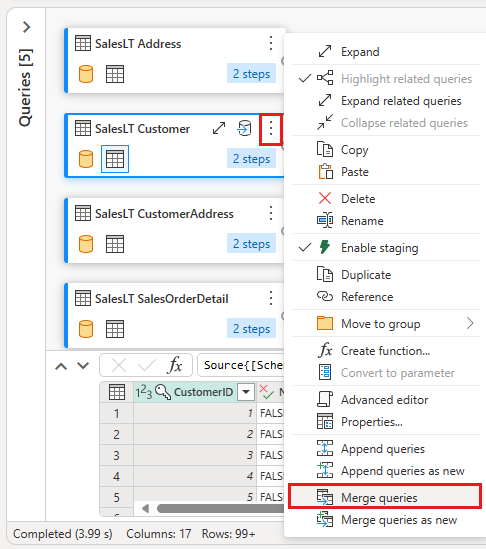
Konfigurer fletningen ved at vælge den SalesLTOrderHeader- tabel som den højre tabel til fletningen, CustomerID kolonne fra hver tabel som joinkolonne og venstre ydre som joinforbindelsestype. Vælg derefter OK for at tilføje fletteforespørgslen.
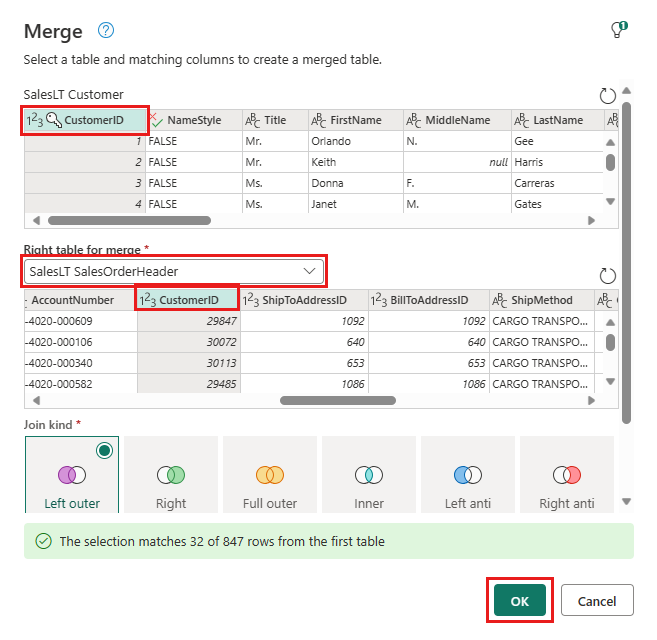
Vælg knappen Tilføj datadestination, der ligner et databasesymbol med en pil over den, fra den nye fletteforespørgsel, du har oprettet. Vælg derefter Azure SQL-database som destinationstype.
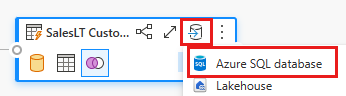
Angiv oplysninger om din Azure SQL-databaseforbindelse, hvor fletteforespørgslen skal publiceres. I dette eksempel kan du også bruge databasen AdventureWorksLT, som vi brugte som datakilde for destinationen.
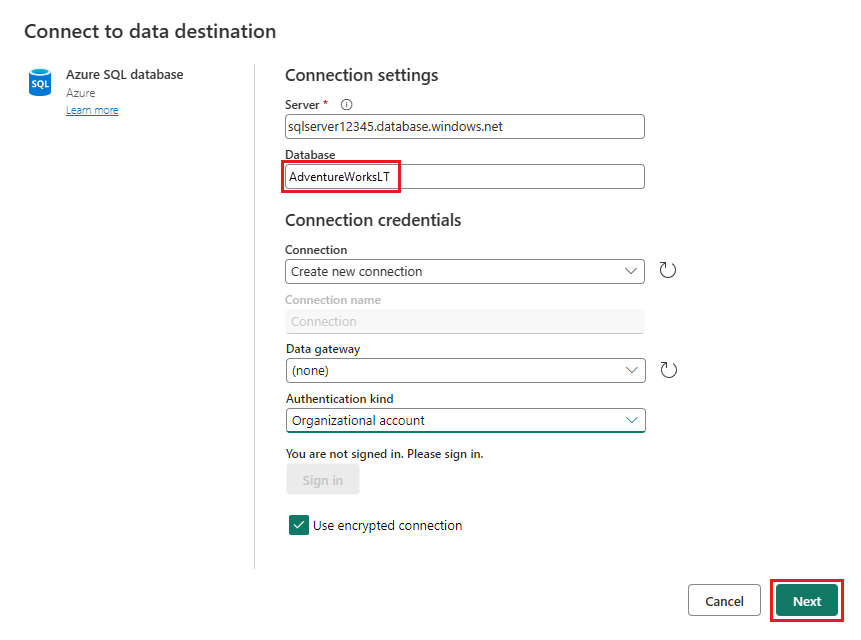
Vælg en database, hvor dataene skal gemmes, og angiv et tabelnavn, og vælg derefter Næste.
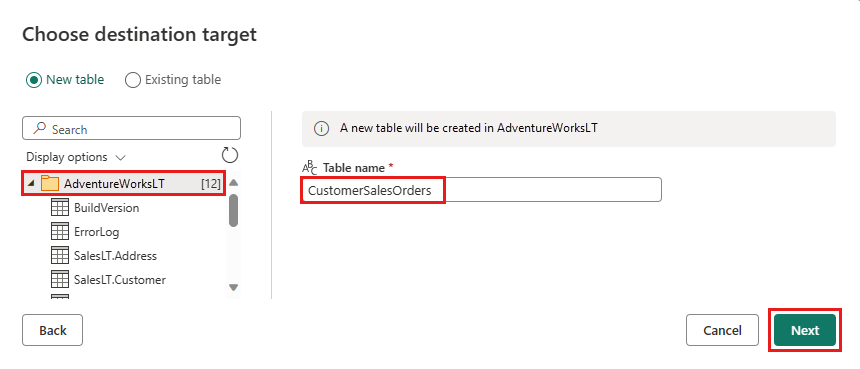
Du kan lade standardindstillingerne være i dialogboksen Vælg destinationsindstillinger og blot vælge Gem indstillinger uden at foretage ændringer her.
Vælg Publicer tilbage på siden med datafloweditoren for at publicere dataflowet.



Flyt data med datapipelines
Nu, hvor du har oprettet et Dataflow Gen2, kan du arbejde med det i en pipeline. I dette eksempel kopierer du de data, der er genereret fra dataflowet, til tekstformat på en Azure Blob Storage-konto.
Trin 1: Opret en ny datapipeline
Vælg Nyi dit arbejdsområde, og vælg derefter Datapipeline.
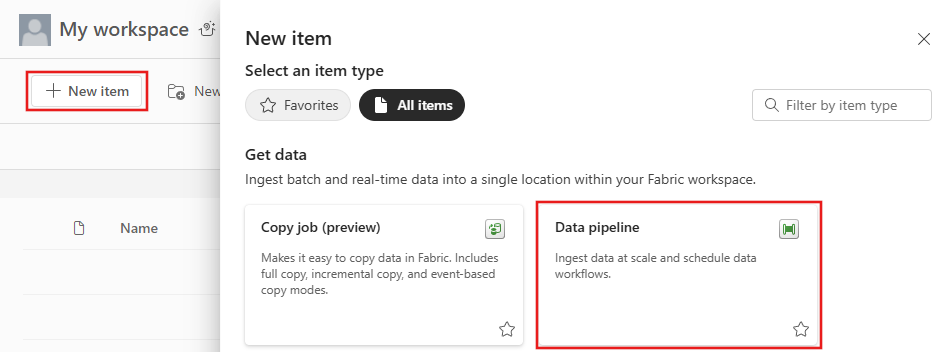
Navngiv pipelinen, og vælg derefter Opret.
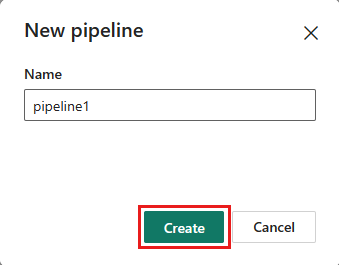
Trin 2: Konfigurer dit dataflow
Føj en ny dataflowaktivitet til din datapipeline ved at vælge dataflow under fanen Aktiviteter.

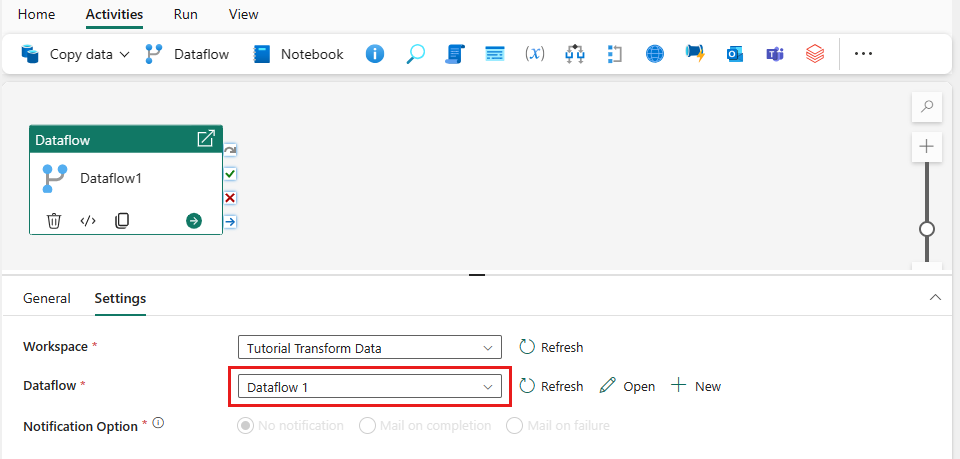
Vælg dataflowet på pipelinelærredet, og derefter fanen Indstillinger. Vælg det dataflow, du oprettede tidligere, på rullelisten.
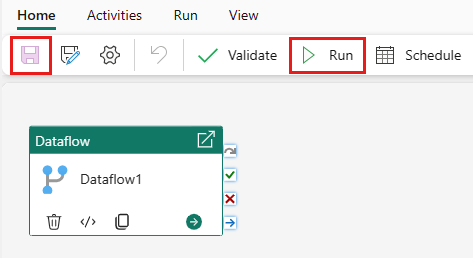
Vælg Gem, og derefter Kør for at køre dataflowet for først at udfylde den flettede forespørgselstabel, du designede i det foregående trin.
Trin 3: Brug kopiassistenten til at tilføje en kopiaktivitet
Vælg Kopiér data på lærredet for at åbne værktøjet til kopiassistent for at komme i gang. Eller vælg Brug kopiassistent på rullelisten Kopiér data under fanen Aktiviteter på båndet.
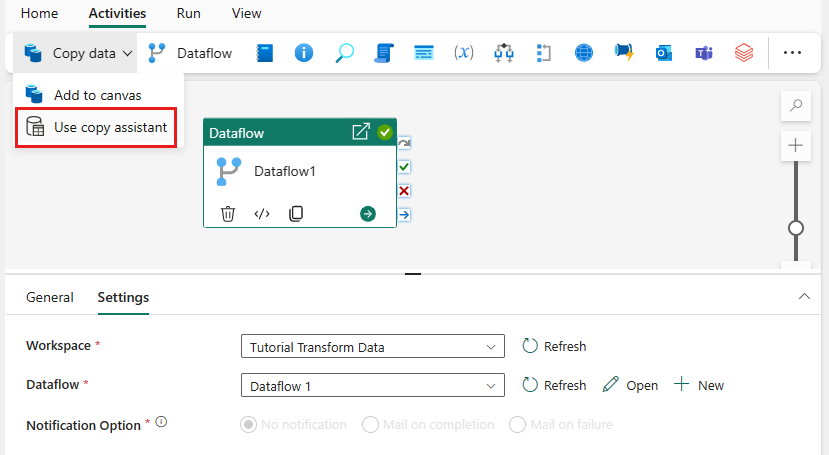
Vælg din datakilde ved at vælge en datakildetype. I dette selvstudium skal du bruge den Azure SQL Database, der tidligere blev brugt, da du oprettede dataflowet, til at generere en ny fletteforespørgsel. Rul ned under eksempeldatatilbudene, og vælg fanen Azure, og derefter Azure SQL Database. Vælg derefter Næste for at fortsætte.
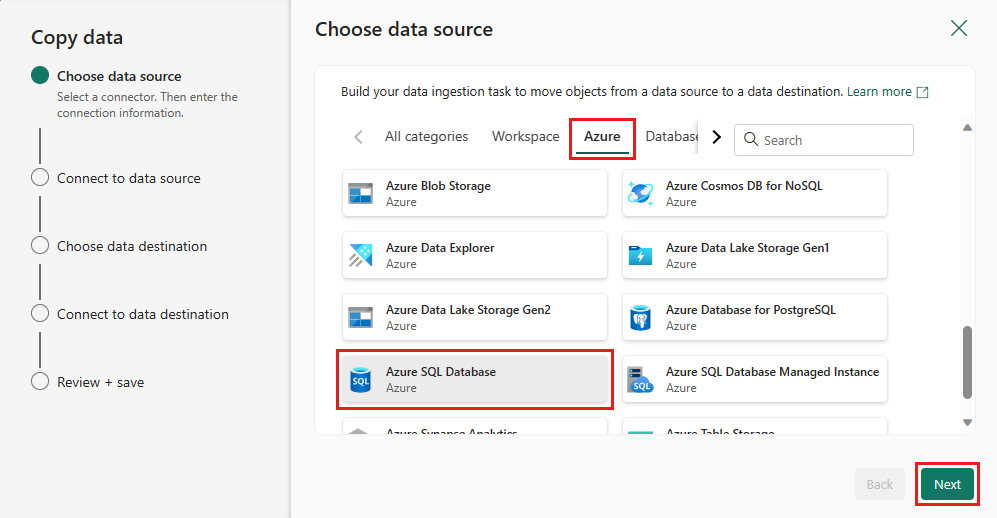
Opret en forbindelse til datakilden ved at vælge Opret ny forbindelse. Udfyld de påkrævede forbindelsesoplysninger i panelet, og angiv AdventureWorksLT for databasen, hvor vi oprettede fletteforespørgslen i dataflowet. Vælg derefter Næste.
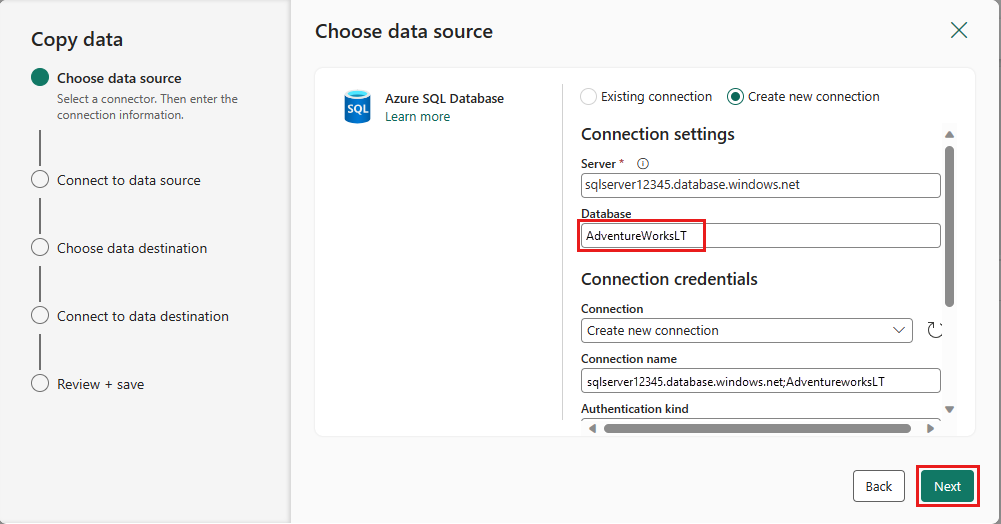
Vælg den tabel, du oprettede i dataflowtrinnet tidligere, og vælg derefter Næste.
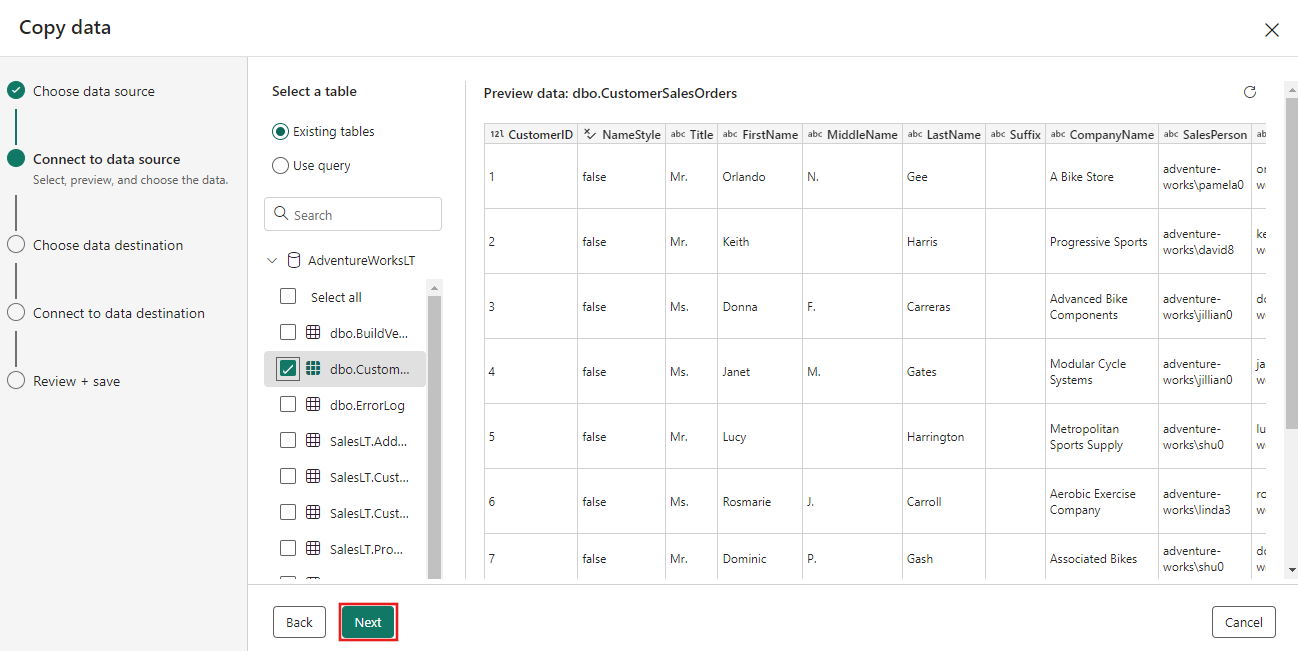
Vælg Azure Blob Storage- for destinationen, og vælg derefter Næste.
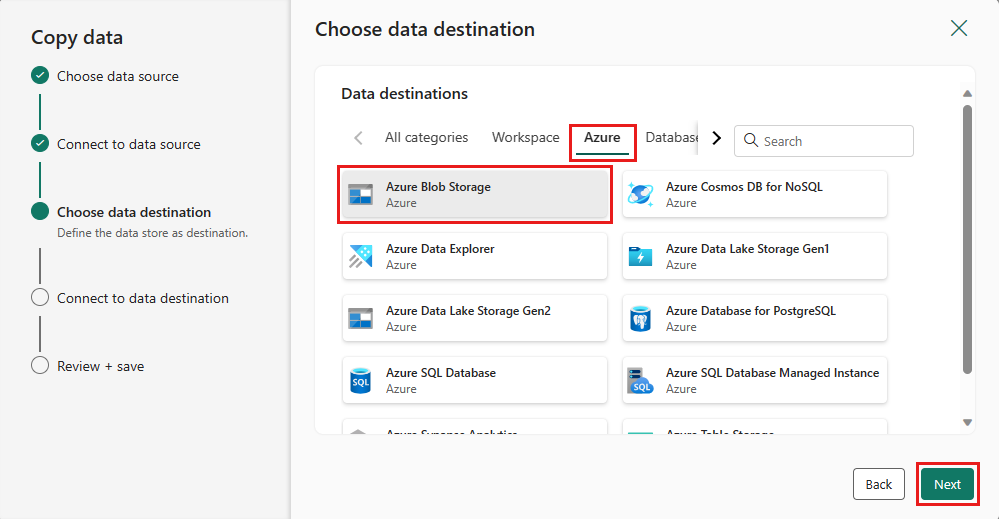
Opret en forbindelse til destinationen ved at vælge Opret ny forbindelse. Angiv detaljerne for forbindelsen, og vælg derefter Næste.
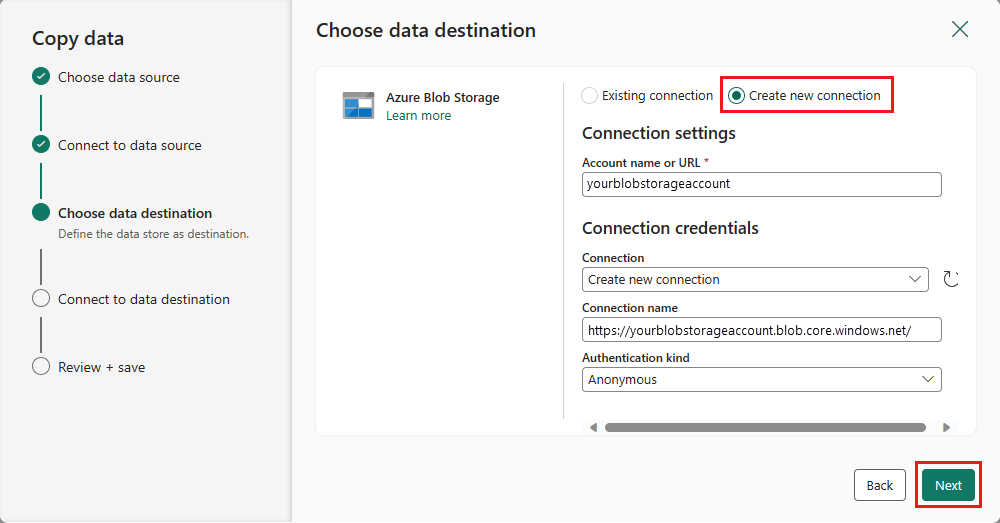
Vælg stien til den mappe, og angiv et Filnavn, og vælg derefter Næste.
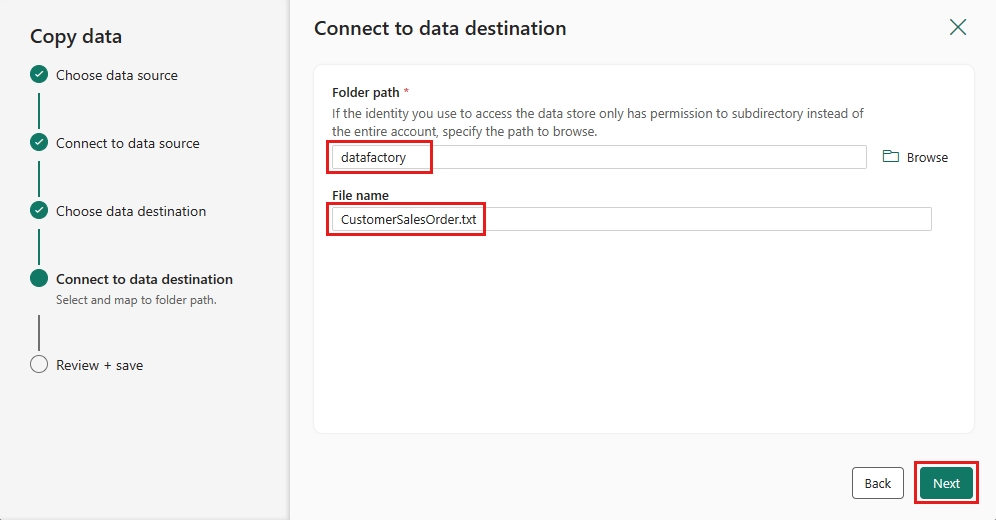
Vælg Næste igen for at acceptere standardfilformatet, kolonneafgrænseren, rækkeafgrænseren og komprimeringstypen, eventuelt inklusive en overskrift.
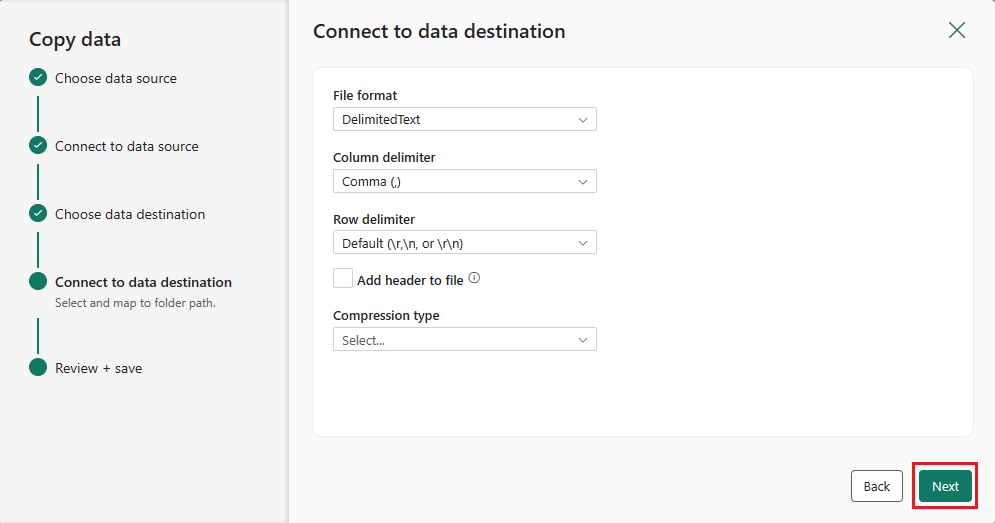
Afslut indstillingerne. Gennemse og vælg derefter Gem + Kør for at afslutte processen.
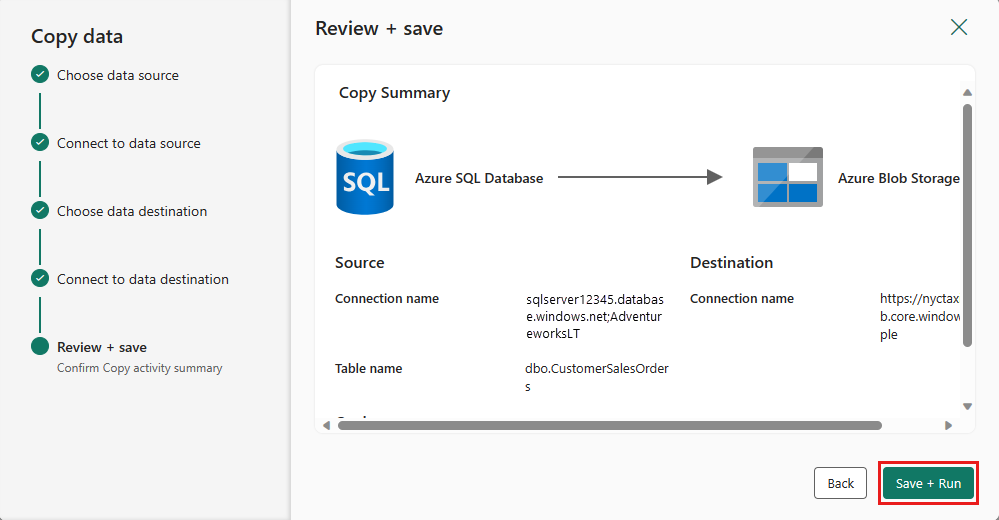
Trin 5: Design din datapipeline, og gem for at køre og indlæse data
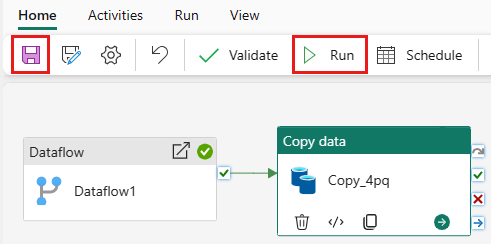
Hvis du vil køre Kopiér-aktivitet efter --aktivitet, skal du trække fra lykkedes på aktivitet for dataflowet til den Kopiér-aktivitet. Den Kopiér-aktivitet kører kun, når dataflowaktiviteten er fuldført.

Vælg Gem for at gemme din datapipeline. Vælg derefter Kør for at køre din datapipeline og indlæse dataene.
Planlæg udførelse af pipeline
Når du er færdig med at udvikle og teste din pipeline, kan du planlægge, at den skal udføres automatisk.
Vælg
Planlæg på fanenStartside i vinduet pipelineeditor. 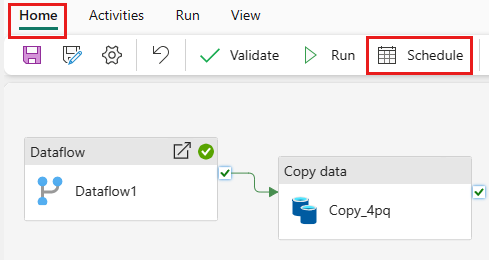
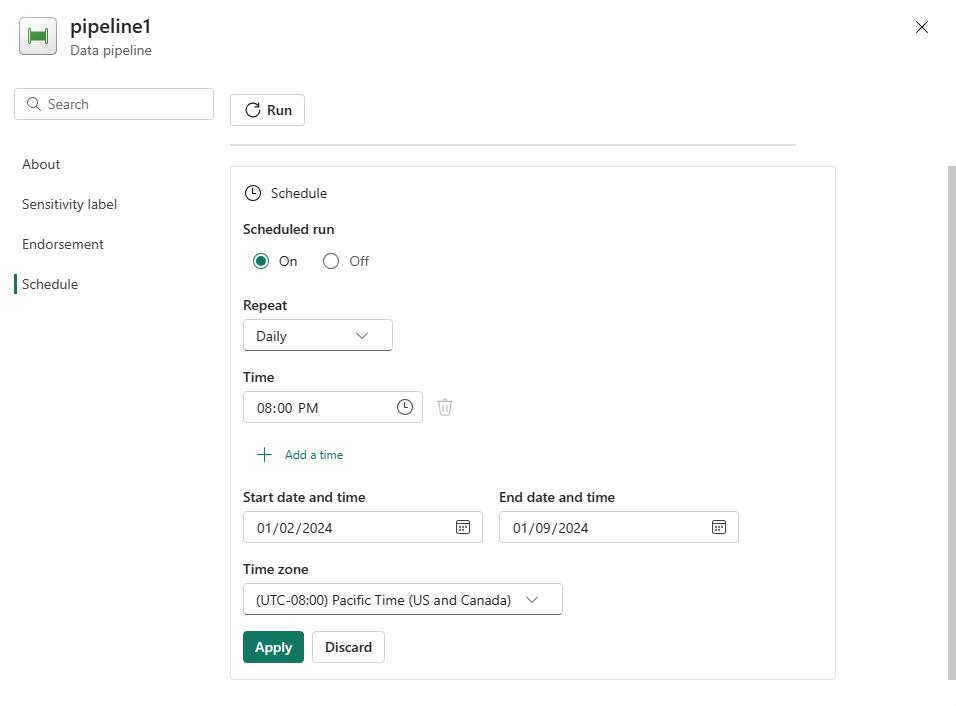
Konfigurer tidsplanen efter behov. I eksemplet her planlægges pipelinen til at blive udført dagligt kl. 20:00 indtil slutningen af året.
Relateret indhold
I dette eksempel kan du se, hvordan du opretter og konfigurerer en Dataflow Gen2 for at oprette en fletteforespørgsel og gemme den i en Azure SQL-database og derefter kopiere data fra databasen til en tekstfil i Azure Blob Storage. Du har lært, hvordan du:
- Opret et dataflow.
- Transformér data med dataflowet.
- Opret en datapipeline ved hjælp af dataflowet.
- Bestil udførelsen af trin i pipelinen.
- Kopiér data med Kopiér assistent.
- Kør og planlæg din datapipeline.
Gå derefter videre for at få mere at vide om overvågning af dine pipelinekørsler.