Transformér data ved at køre en Spark Job Definition-aktivitet
Spark Job Definition-aktiviteten i Data Factory til Microsoft Fabric giver dig mulighed for at oprette forbindelser til dine Spark Job-definitioner og køre dem fra en datapipeline.
Forudsætninger
For at komme i gang skal du fuldføre følgende forudsætninger:
- En lejerkonto med et aktivt abonnement. Opret en konto til gratis.
- Der oprettes et arbejdsområde.
Føj en Spark-jobdefinitionsaktivitet til en pipeline med brugergrænsefladen
Opret en ny datapipeline i dit arbejdsområde.
Søg efter Spark Job Definition på startskærmkortet, og vælg den, eller vælg aktiviteten på aktivitetslinjen for at føje den til pipelinelærredet.
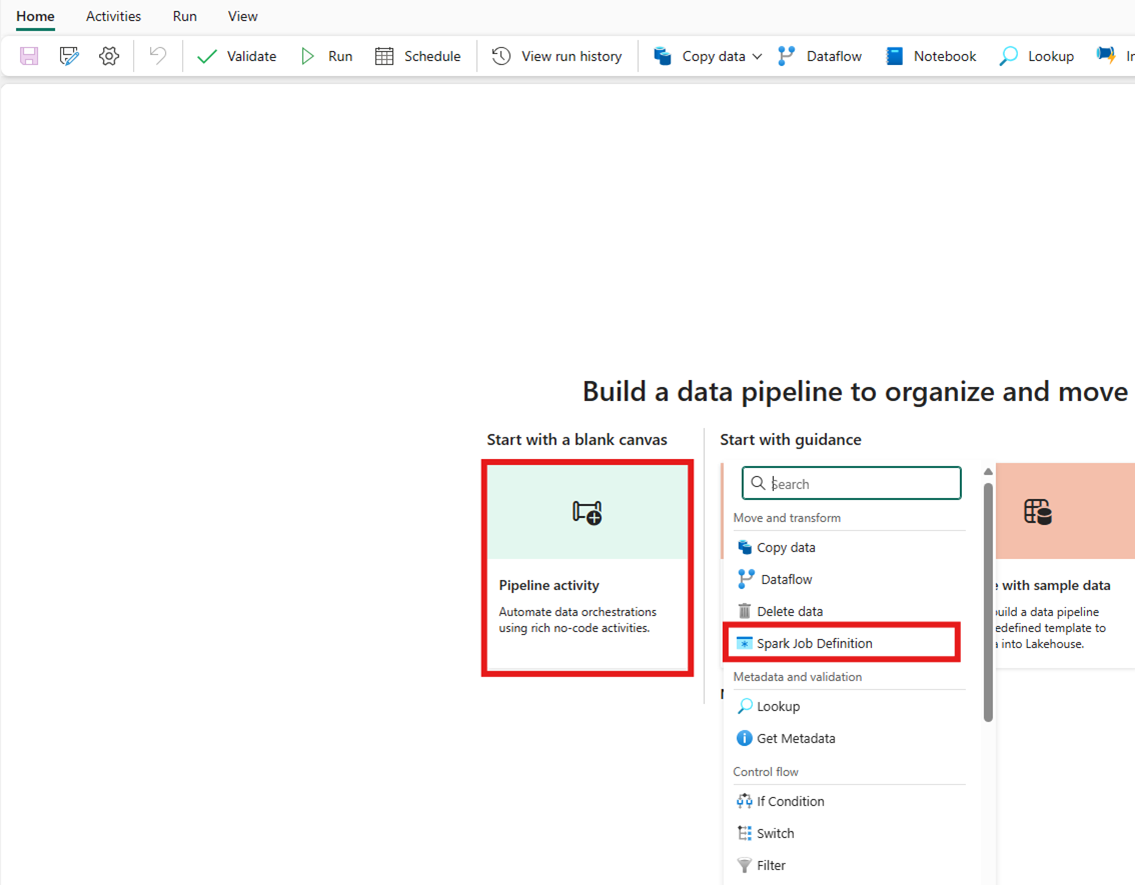
Opretter aktiviteten fra startskærmkortet:
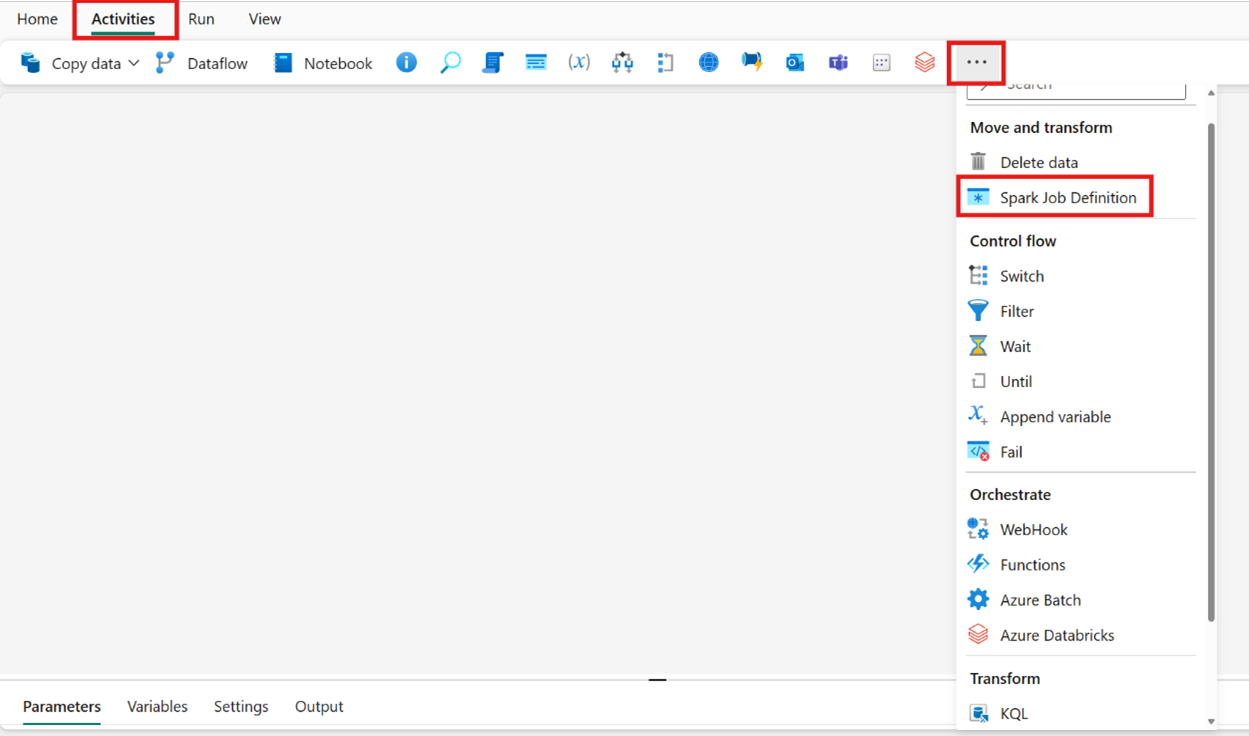
Opretter aktiviteten fra aktivitetslinjen:
Vælg den nye Spark Job Definition-aktivitet på lærredet i pipelineeditoren, hvis den ikke allerede er valgt.
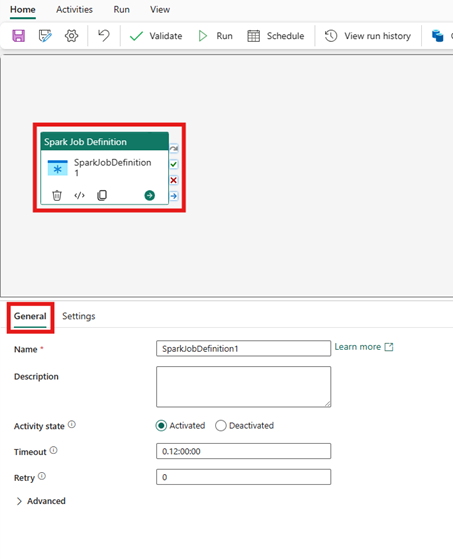
Se Generelle indstillinger vejledning til at konfigurere de indstillinger, der findes under fanen Generelle indstillinger under fanen Generelle indstillinger.



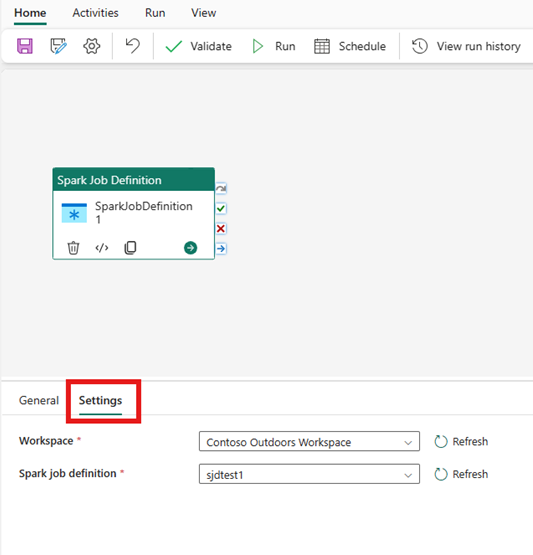
Indstillinger for spark jobdefinitionsaktivitet
Vælg fanen Indstillinger i ruden med aktivitetsegenskaber, og vælg derefter det Fabric Workspace, der indeholder den Spark-jobdefinition, du vil køre.
Kendte begrænsninger
De aktuelle begrænsninger i Spark Job Definition-aktiviteten for Fabric Data Factory er angivet her. Denne sektion kan ændres.
- Vi understøtter i øjeblikket ikke oprettelse af en ny Spark-jobdefinitionsaktivitet i aktiviteten (under Indstillinger)
- Understøttelse af parametre er ikke tilgængelig.
- Selvom vi understøtter overvågning af aktiviteten via outputfanen, kan du endnu ikke overvåge Spark-jobdefinitionen på et mere detaljeret niveau. Links til overvågningssiden, status, varighed og tidligere Spark Job Definition-kørsler er f.eks. ikke tilgængelige direkte i Data Factory. Du kan dog se flere detaljerede detaljer på overvågningssiden Spark Job Definition.
Gem og kør eller planlæg pipelinen
Når du har konfigureret andre aktiviteter, der kræves til pipelinen, skal du skifte til fanen Hjem øverst i pipelineeditoren og vælge knappen Gem for at gemme pipelinen. Vælg Kør for at køre den direkte, eller Planlæg for at planlægge den. Du kan også få vist kørselsoversigten her eller konfigurere andre indstillinger.
