Konfigurer Azure Synapse Analytics i en kopiaktivitet
I denne artikel beskrives det, hvordan du bruger kopiaktiviteten i datapipeline til at kopiere data fra og til Azure Synapse Analytics.
Understøttet konfiguration
Hvis du vil konfigurere hver fane under kopiaktivitet, skal du gå til henholdsvis følgende afsnit.
Generelt
Se vejledningen til generelle indstillinger for at konfigurere fanen Generelle indstillinger.
Kilde
Følgende egenskaber understøttes for Azure Synapse Analytics under fanen Kilde i en kopiaktivitet.

Følgende egenskaber er påkrævet:
Datalagertype: Vælg ekstern.
Forbind ion: Vælg en Azure Synapse Analytics-forbindelse på forbindelseslisten. Hvis forbindelsen ikke findes, skal du oprette en ny Azure Synapse Analytics-forbindelse ved at vælge Ny.
Forbind ionstype: Vælg Azure Synapse Analytics.
Brug forespørgsel: Du kan vælge Tabel, Forespørgsel eller Lagret procedure for at læse kildedataene. På følgende liste beskrives konfigurationen af hver indstilling:
Tabel: Læs data fra den tabel, du har angivet i Tabel , hvis du vælger denne knap. Vælg din tabel på rullelisten, eller vælg Rediger for at angive skemaet og tabelnavnet manuelt.

Forespørgsel: Angiv den brugerdefinerede SQL-forespørgsel for at læse data. Et eksempel er
select * from MyTable. Eller vælg blyantsikonet for at redigere i kodeeditoren.
Lagret procedure: Brug den lagrede procedure, der læser data fra kildetabellen. Den sidste SQL-sætning skal være en SELECT-sætning i den lagrede procedure.
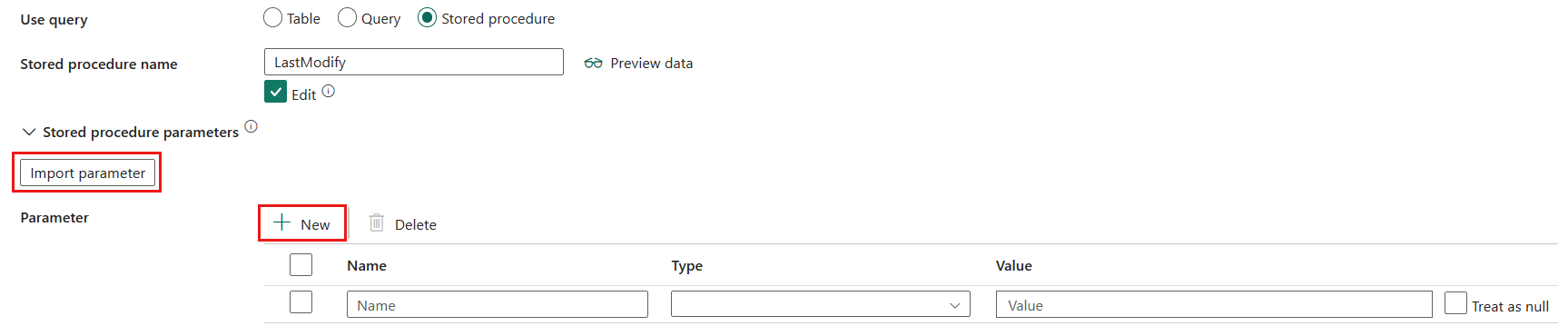
- Navn på lagret procedure: Vælg den lagrede procedure, eller angiv navnet på den lagrede procedure manuelt, når du vælger Rediger.
- Parametre for lagrede procedurer: Vælg Importér parametre for at importere parameteren i den angivne lagrede procedure, eller tilføj parametre for den lagrede procedure ved at vælge + Ny. Tilladte værdier er navne- eller værdipar. Navne og casing af parametre skal stemme overens med navnene og kabinettet for parametrene for den lagrede procedure.

Under Avanceret kan du angive følgende felter:
Timeout for forespørgsel (minutter): Angiv timeout for udførelse af forespørgselskommando. Standarden er 120 minutter. Hvis der er angivet en parameter for denne egenskab, er de tilladte værdier et tidsrum, f.eks. "02:00:00" (120 minutter).
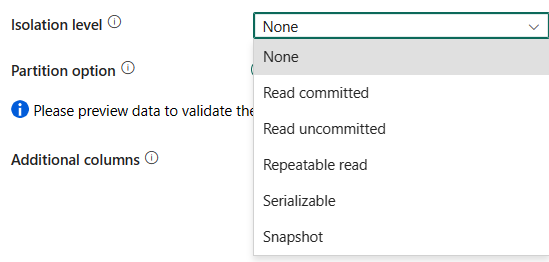
Isolationsniveau: Angiver funktionsmåden for transaktionslåsning for SQL-kilden. De tilladte værdier er: None, Read committed, Read uncommitted, Repeatable read, Serializable eller Snapshot. Hvis den ikke er angivet, bruges ingen isolationsniveau. Se IsolationLevel Enum for at få flere oplysninger.
Partitionsindstilling: Angiv de indstillinger for datapartitionering, der bruges til at indlæse data fra Azure Synapse Analytics. Tilladte værdier er: Ingen (standard), Fysiske partitioner i tabellen og Dynamisk område. Når en partitionsindstilling er aktiveret (dvs. ikke Ingen), styres graden af parallelitet med samtidig indlæsning af data fra en Azure Synapse Analytics af indstillingen for parallel kopiering i kopiaktiviteten.
Ingen: Vælg denne indstilling for ikke at bruge en partition.
Fysiske partitioner i tabellen: Vælg denne indstilling, hvis du vil bruge en fysisk partition. Partitionskolonnen og -mekanismen bestemmes automatisk på baggrund af definitionen af din fysiske tabel.
Dynamisk område: Vælg denne indstilling, hvis du vil bruge partition med dynamisk område. Når du bruger forespørgslen med parallel aktiveret, skal du bruge parameteren(
?DfDynamicRangePartitionCondition) for områdepartitionen. Eksempelforespørgsel:SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition.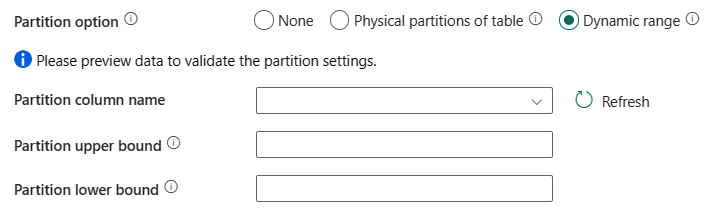
- Navn på partitionskolonne: Angiv navnet på kildekolonnen i heltals- eller dato-/datetime-typen (
int,smallint,bigint,datesmalldatetime,datetime,datetime2ellerdatetimeoffset), der bruges til områdepartitionering til parallel kopiering. Hvis den ikke er angivet, registreres indekset eller tabellens primære nøgle automatisk, og den bruges som partitionskolonne. - Øvre partitionsgrænse: Angiv den maksimale værdi for partitionskolonnen for opdeling af partitionsområdet. Denne værdi bruges til at bestemme partitionsskridtet, ikke til filtrering af rækkerne i tabellen. Alle rækker i tabellen eller forespørgselsresultatet partitioneres og kopieres.
- Nedre grænse for partition: Angiv minimumværdien af partitionskolonnen for opdeling af partitionsområdet. Denne værdi bruges til at bestemme partitionsskridtet, ikke til filtrering af rækkerne i tabellen. Alle rækker i tabellen eller forespørgselsresultatet partitioneres og kopieres.
- Navn på partitionskolonne: Angiv navnet på kildekolonnen i heltals- eller dato-/datetime-typen (
Flere kolonner: Tilføj flere datakolonner for at gemme kildefilernes relative sti eller statiske værdi. Udtrykket understøttes for sidstnævnte. Du kan finde flere oplysninger ved at gå til Tilføj flere kolonner under kopiering.
Destination
Følgende egenskaber understøttes for Azure Synapse Analytics under fanen Destination for en kopiaktivitet.
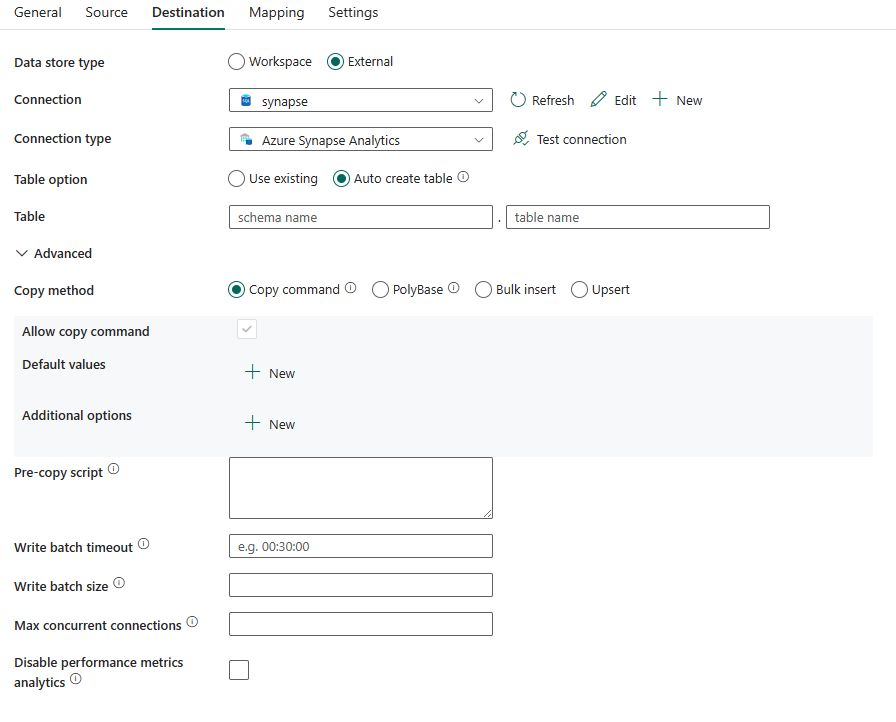
Følgende egenskaber er påkrævet:
- Datalagertype: Vælg ekstern.
- Forbind ion: Vælg en Azure Synapse Analytics-forbindelse på forbindelseslisten. Hvis forbindelsen ikke findes, skal du oprette en ny Azure Synapse Analytics-forbindelse ved at vælge Ny.
- Forbind ionstype: Vælg Azure Synapse Analytics.
- Tabelindstilling: Du kan vælge Brug eksisterende, Opret tabel automatisk. På følgende liste beskrives konfigurationen af hver indstilling:
- Brug eksisterende: Vælg tabellen i databasen på rullelisten. Eller markér Rediger for at angive skemaet og tabelnavnet manuelt.
- Opret automatisk tabel: Tabellen oprettes automatisk (hvis den ikke findes) i kildeskemaet.
Under Avanceret kan du angive følgende felter:
Kopiér metode Vælg den metode, du vil bruge til at kopiere data. Du kan vælge Kommandoen Kopiér, PolyBase, Masseindsætning eller Upsert. På følgende liste beskrives konfigurationen af hver indstilling:
Kommandoen Copy: Brug COPY-sætningen til at indlæse data fra Azure Storage i Azure Synapse Analytics eller SQL Pool.
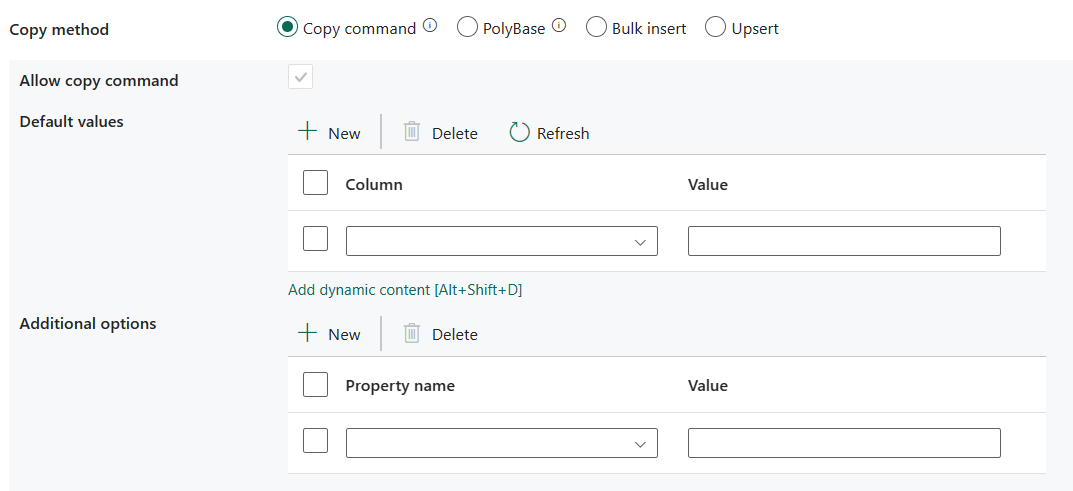
- Tillad kopieringskommando: Det er obligatorisk at vælge, når du vælger Kommandoen Kopiér.
- Standardværdier: Angiv standardværdierne for hver destinationskolonne i Azure Synapse Analytics. Standardværdierne i egenskaben overskriver den STANDARD-begrænsning, der er angivet i data warehouse, og identitetskolonnen kan ikke have en standardværdi.
- Yderligere indstillinger: Yderligere indstillinger, der overføres til en Azure Synapse Analytics COPY-sætning direkte i "With"-delsætningen i COPY-sætningen. Anførselstegn den værdi, der er nødvendig for at tilpasse sig kravene i COPY-sætningen.
PolyBase: PolyBase er en mekanisme med høj gennemløb. Brug den til at indlæse store mængder data i Azure Synapse Analytics eller SQL Pool.
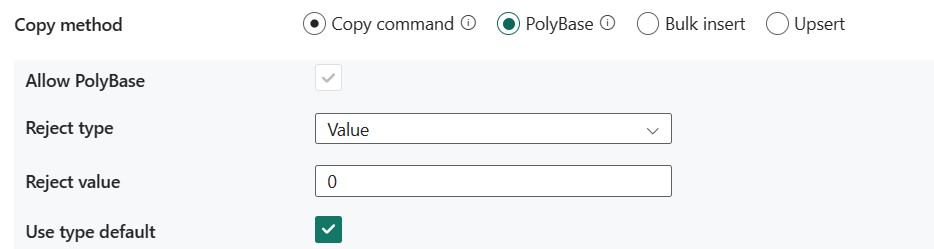
- Tillad PolyBase: Det er obligatorisk at vælge, når du vælger PolyBase.
- Afvis type: Angiv, om indstillingen rejectValue er en konstantværdi eller en procentdel. Tilladte værdier er Værdi (standard) og Procent.
- Afvis værdi: Angiv antallet eller procentdelen af rækker, der kan afvises, før forespørgslen mislykkes. Få mere at vide om PolyBases afvisningsindstillinger i afsnittet Argumenter i CREATE EXTERNAL TABLE (Transact-SQL). Tilladte værdier er 0 (standard), 1, 2 osv.
- Afvis eksempelværdi: Bestemmer antallet af rækker, der skal hentes, før PolyBase genberegner procentdelen af afviste rækker. Tilladte værdier er 1, 2 osv. Hvis du vælger Procent som afvisningstype, er denne egenskab påkrævet.
- Brug typestandard: Angiv, hvordan manglende værdier skal håndteres i afgrænsede tekstfiler, når PolyBase henter data fra tekstfilen. Få mere at vide om denne egenskab i afsnittet Argumenter i CREATE EXTERNAL FILE FORMAT (Transact-SQL). Tilladte værdier er valgt (standard) eller ikke markeret.
Masseindsætning: Brug Masseindsætning til at indsætte data til destinationen samlet.

- Fastlåsning af masseindsætningstabel: Brug denne til at forbedre kopiydeevnen under masseindsætning i tabellen uden indeks fra flere klienter. Få mere at vide fra BULK INSERT (Transact-SQL).
Upsert: Angiv gruppen af indstillinger for skrivefunktionsmåde, når du vil sætte data op til destinationen.
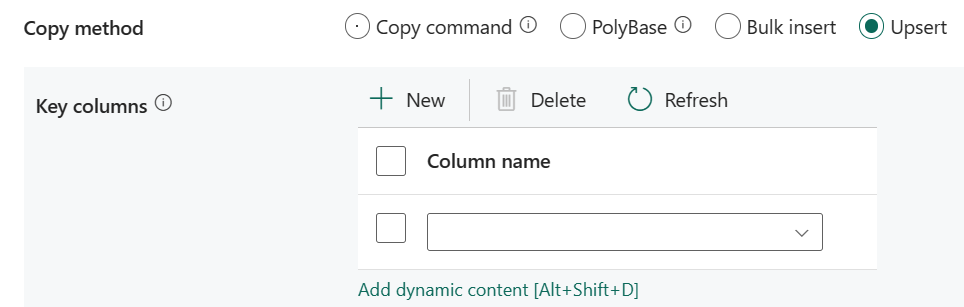
Nøglekolonner: Vælg, hvilken kolonne der skal bruges til at bestemme, om en række fra kilden svarer til en række fra destinationen.
Fastlåsning af masseindsætningstabel: Brug denne til at forbedre kopiydeevnen under masseindsætning i tabellen uden indeks fra flere klienter. Få mere at vide fra BULK INSERT (Transact-SQL).
Forudkopieringsscript: Angiv et script for Kopiér aktivitet, der skal udføres, før du skriver data til en destinationstabel i hver kørsel. Du kan bruge denne egenskab til at rydde op i forudindlæste data.
Timeout for skrivning af batch: Angiv ventetiden for batchindsætningshandlingen, før der opstår timeout. Den tilladte værdi er et tidsrum. Standardværdien er "00:30:00" (30 minutter).
Skriv batchstørrelse: Angiv det antal rækker, der skal indsættes i SQL-tabellen pr. batch. Den tilladte værdi er heltal (antal rækker). Tjenesten bestemmer som standard dynamisk den relevante batchstørrelse baseret på rækkestørrelsen.
Maksimalt antal samtidige forbindelser: Angiv den øvre grænse for samtidige forbindelser, der er oprettet til datalageret under aktivitetskørslen. Angiv kun en værdi, når du vil begrænse samtidige forbindelser.
Deaktiver analyse af målepunkter for ydeevne: Denne indstilling bruges til at indsamle målepunkter, f.eks. DTU, DWU, RU osv. til optimering af kopiydeevne og anbefalinger. Hvis du er bekymret for denne funktionsmåde, skal du markere dette afkrydsningsfelt. Den er som standard ikke markeret.
Direkte kopiering ved hjælp af kommandoen COPY
Kommandoen Azure Synapse Analytics COPY understøtter direkte Azure Blob Storage og Azure Data Lake Storage Gen2 som kildedatalagre. Hvis dine kildedata opfylder de kriterier, der er beskrevet i dette afsnit, skal du bruge kommandoen COPY til at kopiere direkte fra kildedatalageret til Azure Synapse Analytics.
Kildedataene og -formatet indeholder følgende typer og godkendelsesmetoder:
Type af understøttet kildedatalager Understøttet format Understøttet kildegodkendelsestype Azure Blob Storage Afgrænset tekst
ParquetAnonym godkendelse
Godkendelse af kontonøgle
Godkendelse af signatur for delt adgangAzure Data Lake Storage Gen2 Afgrænset tekst
ParquetGodkendelse af kontonøgle
Godkendelse af signatur for delt adgangFølgende formatindstillinger kan angives:
- For Parquet: Komprimeringstypen kan være None, snappy eller gzip.
- For afgrænset tekst:
- Rækkeafgrænser: Når du kopierer afgrænset tekst til Azure Synapse Analytics via kommandoen direct COPY, skal du eksplicit angive rækkeafgrænseren (\r; \n; eller \r\n). Kun når rækkeafgrænseren i kildefilen er \r\n, fungerer standardværdien (\r, \n eller \r\n). Ellers skal du aktivere midlertidig lagring for dit scenarie.
- Null-værdien er tilbage som standard eller indstillet til en tom streng ("").
- Kodning er tilbage som standard eller indstillet til UTF-8 eller UTF-16.
- Spring linjeantal tilbage som standard eller indstillet til 0.
- Komprimeringstypen kan være None eller gzip.
Hvis din kilde er en mappe, skal du markere afkrydsningsfeltet Rekursivt .
Starttidspunkt (UTC) og Sluttidspunkt (UTC) i Filtrer efter senest ændret, Præfiks, Aktivér partitionsregistrering og Yderligere kolonner er ikke angivet.
Du kan få mere at vide om, hvordan du henter data i din Azure Synapse Analytics ved hjælp af kommandoen COPY, i denne artikel.
Hvis dit kildedatalager og -format ikke oprindeligt understøttes af en COPY-kommando, skal du i stedet bruge funktionen Fased kopi ved hjælp af kommandoen COPY. Dataene konverteres automatisk til et kopiér kommandokompatibelt format og kalder derefter en COPY-kommando for at indlæse data i Azure Synapse Analytics.
Tilknytning
Hvis du ikke anvender Azure Synapse Analytics med automatisk oprettelse af tabel som destination under fanen Tilknytning, skal du gå til Tilknytning.
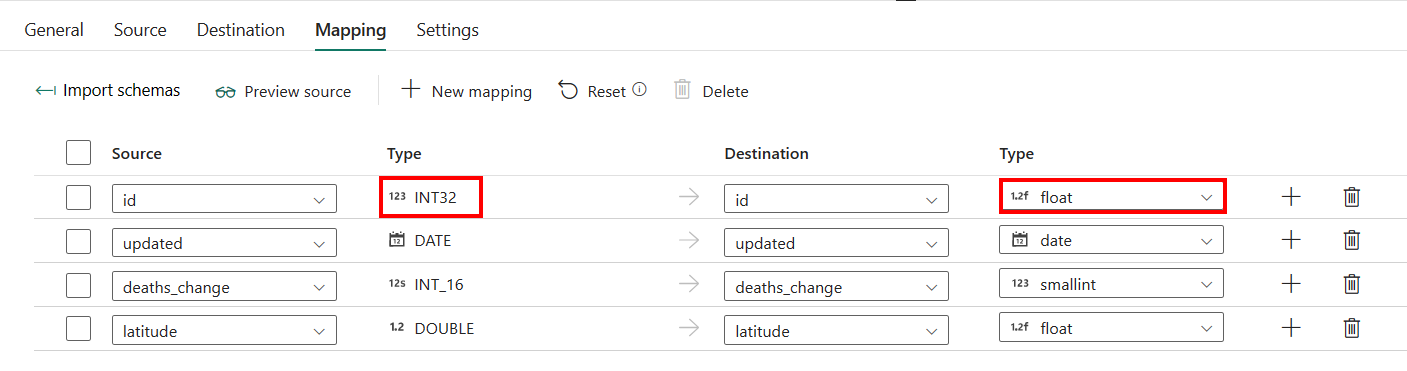
Hvis du anvender Azure Synapse Analytics med tabel til automatisk oprettelse som destination, undtagen konfigurationen i Tilknytning, kan du redigere typen for dine destinationskolonner. Når du har valgt Importér skemaer, kan du angive kolonnetypen i destinationen.
Typen af id-kolonne i kilden er f.eks. int, og du kan ændre den til flydende type, når du tilknytter destinationskolonnen.
Indstillinger
Hvis du vil have Indstillinger fanekonfiguration, skal du gå til Konfigurer dine andre indstillinger under fanen Indstillinger.
Parallel kopi fra Azure Synapse Analytics
Azure Synapse Analytics-connectoren i kopiaktivitet giver indbygget datapartitionering for at kopiere data parallelt. Du kan finde indstillinger for datapartitionering under fanen Kilde i kopiaktiviteten.
Når du aktiverer partitioneret kopi, kører kopieringsaktivitet parallelle forespørgsler mod din Azure Synapse Analytics-kilde for at indlæse data efter partitioner. Den parallelle grad styres af graden af kopi parallelitet under fanen indstillinger for kopiaktivitet. Hvis du f.eks. angiver Grad af kopi parallelitet til fire, genererer og kører tjenesten samtidig fire forespørgsler baseret på din angivne partitionsindstilling og dine angivne indstillinger, og hver forespørgsel henter en del af dataene fra din Azure Synapse Analytics.
Du foreslås at aktivere parallel kopiering med datapartitionering, især når du indlæser store mængder data fra din Azure Synapse Analytics. Følgende er foreslåede konfigurationer til forskellige scenarier. Når du kopierer data til et filbaseret datalager, anbefales det at skrive til en mappe som flere filer (angiv kun mappenavn), i hvilket tilfælde ydeevnen er bedre end at skrive til en enkelt fil.
| Scenarie | Foreslåede indstillinger |
|---|---|
| Fuld belastning fra store tabeller med fysiske partitioner. | Partitionsindstilling: Fysiske partitioner i tabellen. Under udførelsen registrerer tjenesten automatisk de fysiske partitioner og kopierer data fra partitioner. Hvis du vil kontrollere, om tabellen har en fysisk partition eller ej, kan du se denne forespørgsel. |
| Fuld belastning fra store tabeller uden fysiske partitioner, mens der er en heltals- eller datetime-kolonne til datapartitionering. | Partitionsindstillinger: Partition med dynamisk område. Partitionskolonne (valgfrit): Angiv den kolonne, der skal bruges til at partitionere data. Hvis den ikke er angivet, bruges kolonnen med indekset eller den primære nøgle. Partition med øvre grænse og nedre partitionsgrænse (valgfri): Angiv, om du vil bestemme partitionens fremskridt. Dette er ikke til filtrering af rækkerne i tabellen. Alle rækker i tabellen partitioneres og kopieres. Hvis den ikke er angivet, registrerer kopiaktiviteten automatisk værdierne. Hvis partitionskolonnen "ID" f.eks. har værdier fra 1 til 100, og du angiver den nedre grænse som 20 og den øvre grænse som 80, med parallel kopi som 4, henter tjenesten data efter 4 partitioner – id'er i området <=20, [21, 50], [51, 80] og >=81. |
| Indlæs en stor mængde data ved hjælp af en brugerdefineret forespørgsel uden fysiske partitioner, mens du har et heltal eller en dato/datetime-kolonne til datapartitionering. | Partitionsindstillinger: Partition med dynamisk område. Forespørgsel: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.Partitionskolonne: Angiv den kolonne, der skal bruges til at partitionere data. Partition med øvre grænse og nedre partitionsgrænse (valgfri): Angiv, om du vil bestemme partitionens fremskridt. Dette er ikke til filtrering af rækkerne i tabellen. Alle rækker i forespørgselsresultatet partitioneres og kopieres. Hvis den ikke er angivet, skal du automatisk registrere værdien for kopiering af aktivitet. Hvis partitionskolonnen "ID" f.eks. har værdier fra 1 til 100, og du angiver den nedre grænse som 20 og den øvre grænse som 80, med parallel kopi som 4, henter tjenesten data efter henholdsvis 4 partitioner - id'er i området <=20, [21, 50], [51, 80] og >=81. Her er flere eksempelforespørgsler til forskellige scenarier: • Forespørg hele tabellen: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition• Forespørg fra en tabel med valg af kolonne og yderligere where-clause-filtre: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Forespørgsel med underforespørgsler: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Forespørgsel med partition i underforespørgsel: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Bedste fremgangsmåder til indlæsning af data med partitionsindstilling:
- Vælg en karakteristisk kolonne som partitionskolonne (f.eks. primær nøgle eller entydig nøgle) for at undgå dataforvrængelse.
- Hvis tabellen har en indbygget partition, skal du bruge partitionsindstillingen Fysiske partitioner i tabellen for at få en bedre ydeevne.
- Azure Synapse Analytics kan maksimalt udføre 32 forespørgsler på et tidspunkt, og hvis du angiver Graden af kopi parallelitet for stor, kan det medføre et problem med synapsebegrænsning.
Eksempelforespørgsel til kontrol af fysisk partition
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, c.name AS ColumnName, CASE WHEN c.name IS NULL THEN 'no' ELSE 'yes' END AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.types AS y ON c.system_type_id = y.system_type_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Hvis tabellen har en fysisk partition, kan du se "HasPartition" som "ja".
Tabeloversigt
Følgende tabeller indeholder flere oplysninger om kopiaktiviteten i Azure Synapse Analytics.
Kilde
| Navn | Beskrivelse | Værdi | Obligatorisk | JSON-scriptegenskab |
|---|---|---|---|---|
| Datalagertype | Datalagertypen. | Eksternt | Ja | / |
| Forbind ion | Din forbindelse til kildedatalageret. | < din forbindelse > | Ja | Forbindelse |
| Forbind ionstype | Kildeforbindelsestypen. | Azure Synapse Analytics | Ja | / |
| Brug forespørgsel | Måden at læse data på. | •Tabel •Forespørgsel • Lagret procedure |
Ja | • typeEgenskaber (under typeProperties ->source)-Skema -Tabel • sqlReaderQuery • sqlReaderStoredProcedureName storedProcedureParameters -Navn -Værdi |
| Timeout for forespørgsel | Timeout for udførelse af forespørgselskommando er som standard 120 minutter. | Timespan | Nr. | queryTimeout |
| Isolationsniveau | Funktionsmåden for transaktionslåsning for SQL-kilden. | •Ingen • Bekræftet læsning • Ikke-indlæst læsning • Læs igen •Serialiserbar •Snapshot |
Nr. | isolationLevel: • Skrivebeskyttet • ReadUncommitted • RepeatableRead •Serialiserbar •Snapshot |
| Partitionsindstilling | De indstillinger for datapartitionering, der bruges til at indlæse data fra Azure SQL Database. | •Ingen • Fysiske partitioner i tabellen •Dynamikområde - Navn på partitionskolonne - Partition, øvre grænse - Partition med nedre grænse |
Nr. | partitionOption: • PhysicalPartitionsOfTable • Dynamisk rækkefølge partition Indstillinger: - partitionColumnName - partitionUpperBound - partitionLowerBound |
| Flere kolonner | Tilføj yderligere datakolonner for at gemme kildefilernes relative sti eller statiske værdi. Udtrykket understøttes for sidstnævnte. | • Navn •Værdi |
Nr. | additionalColumns: •Navn •Værdi |
Destination
| Navn | Beskrivelse | Værdi | Obligatorisk | JSON-scriptegenskab |
|---|---|---|---|---|
| Datalagertype | Datalagertypen. | Eksternt | Ja | / |
| Forbind ion | Din forbindelse til destinationsdatalageret. | < din forbindelse > | Ja | Forbindelse |
| Forbind ionstype | Destinationsforbindelsestypen. | Azure Synapse Analytics | Ja | / |
| Tabelindstilling | Indstillingen destinationsdatatabel. | • Brug eksisterende • Opret tabel automatisk |
Ja | • typeEgenskaber (under typeProperties ->sink)-Skema -Tabel • tableOption: - opret automatisk typeProperties (under typeProperties ->sink)-Skema -Tabel |
| Kopiér metode | Den metode, der bruges til at kopiere data. | • Kommandoen Kopiér • PolyBase • Masseindsætning • Upsert |
Nr. | / |
| Når du vælger kommandoen Kopiér | Brug COPY-sætningen til at indlæse data fra Azure Storage i Azure Synapse Analytics eller SQL Pool. | / | Nej. Anvend, når du bruger COPY. |
allowCopyCommand: true copyCommand Indstillinger |
| Standardværdier | Angiv standardværdierne for hver destinationskolonne i Azure Synapse Analytics. Standardværdierne i egenskaben overskriver den STANDARD-begrænsning, der er angivet i data warehouse, og identitetskolonnen kan ikke have en standardværdi. | < Standardværdier > | Nr. | defaultValues: - columnName -Standardværdi |
| Yderligere indstillinger | Yderligere indstillinger, der overføres til en Azure Synapse Analytics COPY-sætning direkte i "With"-delsætningen i COPY-sætningen. Anførselstegn den værdi, der er nødvendig for at tilpasse sig kravene i COPY-sætningen. | < yderligere indstillinger > | Nr. | additionalOptions: - <egenskabsnavn> : <værdi> |
| Når du vælger PolyBase | PolyBase er en mekanisme med høj gennemløb. Brug den til at indlæse store mængder data i Azure Synapse Analytics eller SQL Pool. | / | Nej. Anvend, når du bruger PolyBase. |
allowPolyBase: true polyBase Indstillinger |
| Afvis type | Afvisningsværdiens type. | •Værdi •Procentdel |
Nr. | rejectType: -Værdi -Procentdel |
| Afvis værdi | Det antal eller den procentdel af rækker, der kan afvises, før forespørgslen mislykkes. | 0 (standard), 1, 2 osv. | Nr. | rejectValue |
| Afvis eksempelværdi | Bestemmer det antal rækker, der skal hentes, før PolyBase genberegner procentdelen af afviste rækker. | 1, 2 osv. | Ja, når du angiver Procent som afvisningstype | afvisSampleValue |
| Brug standardtype | Angiv, hvordan manglende værdier skal håndteres i afgrænsede tekstfiler, når PolyBase henter data fra tekstfilen. Få mere at vide om denne egenskab fra afsnittet Argumenter i CREATE EXTERNAL FILE FORMAT (Transact-SQL) | valgt (standard) eller ikke markeret. | Nr. | useTypeDefault: true (standard) eller false |
| Når du vælger Masseindsætning | Indsæt data til destinationen samlet. | / | Nr. | writeBehavior: Indsæt |
| Lås til masseindsætning af tabel | Brug dette til at forbedre kopiydeevnen under masseindsætningshandlingen i tabellen uden indeks fra flere klienter. Få mere at vide fra BULK INSERT (Transact-SQL). | markeret eller ikke markeret (standard) | Nr. | sqlWriterUseTableLock: true eller false (standard) |
| Når du vælger Upsert | Angiv gruppen af indstillinger for skrivefunktionsmåde, når du vil overføre data til destinationen. | / | Nr. | writeBehavior: Upsert |
| Nøglekolonner | Angiver, hvilken kolonne der bruges til at bestemme, om en række fra kilden svarer til en række fra destinationen. | < kolonnenavn> | Nr. | upsert Indstillinger: - nøgler: < kolonnenavn > - interimSchemaName |
| Lås til masseindsætning af tabel | Brug dette til at forbedre kopiydeevnen under masseindsætningshandlingen i tabellen uden indeks fra flere klienter. Få mere at vide fra BULK INSERT (Transact-SQL). | markeret eller ikke markeret (standard) | Nr. | sqlWriterUseTableLock: true eller false (standard) |
| Forudkopieringsscript | Et script til Kopier aktivitet, der skal udføres, før du skriver data til en destinationstabel i hver kørsel. Du kan bruge denne egenskab til at rydde op i forudindlæste data. | < pre-copy script > (streng) |
Nr. | preCopyScript |
| Timeout for skrivning af batch | Ventetiden for, at batchindsætningshandlingen afsluttes, før der udløber timeout. Den tilladte værdi er et tidsrum. Standardværdien er "00:30:00" (30 minutter). | Timespan | Nr. | writeBatchTimeout |
| Skriv batchstørrelse | Det antal rækker, der skal indsættes i SQL-tabellen pr. batch. Tjenesten bestemmer som standard dynamisk den relevante batchstørrelse baseret på rækkestørrelsen. | < antal rækker > (heltal) |
Nr. | writeBatchSize |
| Maks. antal samtidige forbindelser | Den øvre grænse for samtidige forbindelser, der er oprettet til datalageret under aktivitetskørslen. Angiv kun en værdi, når du vil begrænse samtidige forbindelser. | < øvre grænse for samtidige forbindelser > (heltal) |
Nr. | maxConcurrent Forbind ions |
| Deaktiver analyse af målepunkter for ydeevne | Denne indstilling bruges til at indsamle målepunkter, f.eks. DTU, DWU, RU osv. til optimering af kopiydeevne og anbefalinger. Hvis du er bekymret for denne funktionsmåde, skal du markere dette afkrydsningsfelt. | vælg eller fjern markeringen (standard) | Nr. | disableMetricsCollection: true eller false (standard) |