Sådan konfigurerer du Amazon RDS til SQL Server i kopiaktivitet
I denne artikel beskrives det, hvordan du bruger kopiaktiviteten i en datapipeline til at kopiere data fra Amazon RDS til SQL Server.
Understøttet konfiguration
Hvis du vil konfigurere hver fane under kopiaktivitet, skal du gå til henholdsvis følgende afsnit.
Generelt
Se vejledningen til generelle indstillinger for at konfigurere fanen Generelle indstillinger.
Kilde
Følgende egenskaber understøttes for Amazon RDS til SQL Server under fanen Kilde i en kopiaktivitet.
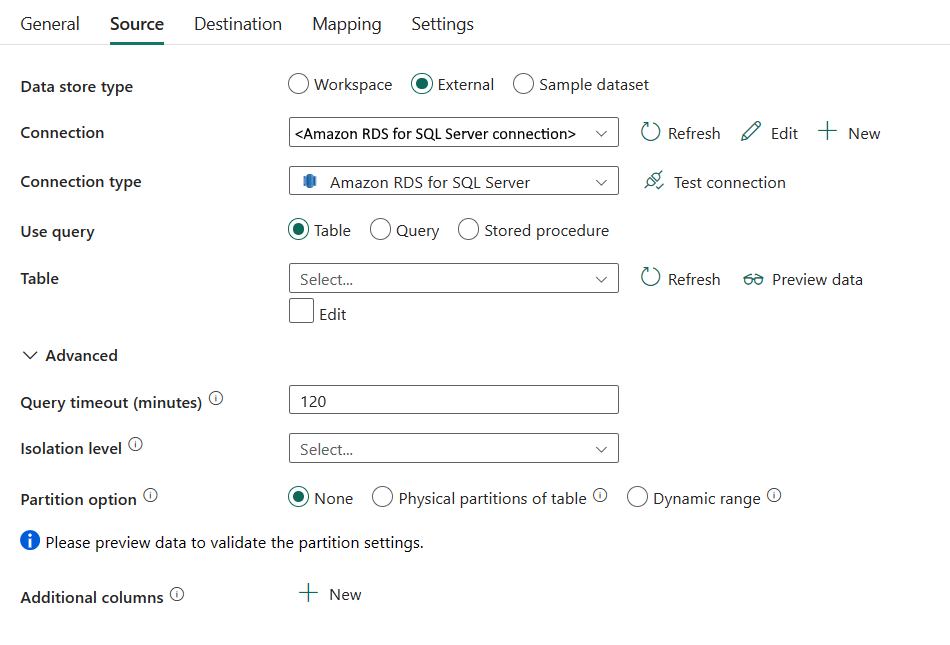
Følgende egenskaber er påkrævet:
Datalagertype: Vælg ekstern.
Forbindelse: Vælg en Amazon RDS til SQL Server-forbindelse på forbindelseslisten. Hvis forbindelsen ikke findes, skal du oprette en ny Amazon RDS til SQL Server-forbindelse ved at vælge Ny.
Forbindelsestype: Vælg Amazon RDS til SQL Server.
Brug forespørgsel: Angiv, hvordan data skal læses. Du kan vælge Tabel, Forespørgsel eller Lagret procedure. På følgende liste beskrives konfigurationen af hver indstilling:
Tabel: Læs data fra den angivne tabel. Vælg din kildetabel på rullelisten, eller vælg Rediger for at angive den manuelt.
Forespørgsel: Angiv den brugerdefinerede SQL-forespørgsel for at læse data. Et eksempel er
select * from MyTable. Eller vælg blyantsikonet for at redigere i kodeeditoren.
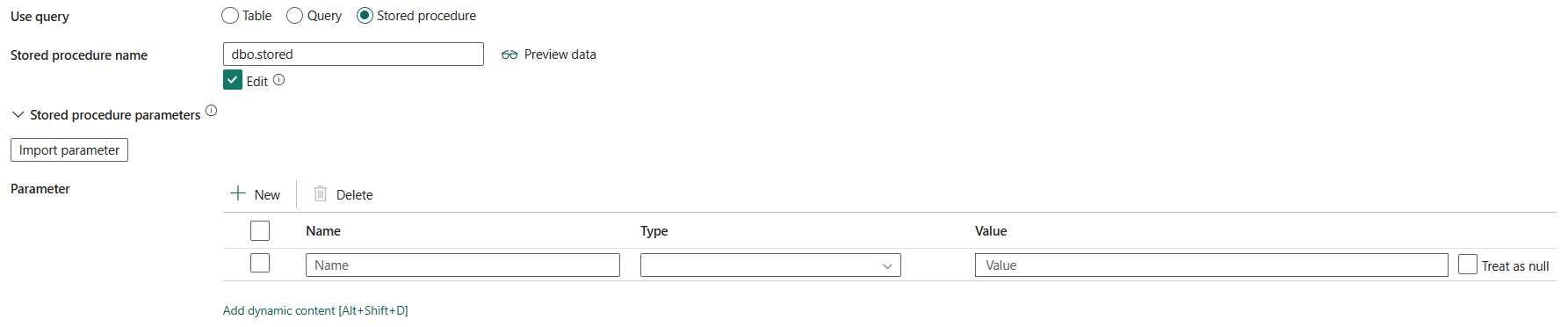
Lagret procedure: Brug den lagrede procedure, der læser data fra kildetabellen. Den sidste SQL-sætning skal være en SELECT-sætning i den lagrede procedure.
Navn på lagret procedure: Vælg den lagrede procedure, eller angiv navnet på den lagrede procedure manuelt, når du vælger Rediger for at læse data fra kildetabellen.
Lagrede procedureparametre: Angiv værdier for lagrede procedureparametre. Tilladte værdier er navne- eller værdipar. Navnene på og kabinettet for parametre skal stemme overens med navnene og kabinettet for parametrene for den lagrede procedure. Du kan vælge Importér parametre for at hente dine lagrede procedureparametre.
Under Avanceret kan du angive følgende felter:
Timeout for forespørgsel (minutter): Angiv timeout for udførelse af forespørgselskommando. Standarden er 120 minutter. Hvis der er angivet en parameter for denne egenskab, er de tilladte værdier et tidsrum, f.eks. "02:00:00" (120 minutter).
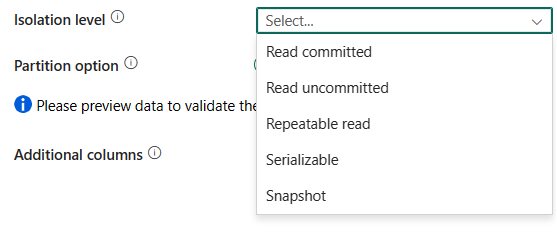
Isolationsniveau: Angiver funktionsmåden for transaktionslåsning for SQL-kilden. De tilladte værdier er: Read committed, Read uncommitted, Repeatable read, Serializable, Snapshot. Hvis den ikke er angivet, bruges standardisolationsniveauet for databasen. Se IsolationLevel Enum for at få flere oplysninger.
Partitionsindstilling: Angiv de indstillinger for datapartitionering, der bruges til at indlæse data fra Amazon RDS til SQL Server. Tilladte værdier er: Ingen (standard), Fysiske partitioner i tabellen og Dynamisk område. Når en partitionsindstilling er aktiveret (dvs. ikke Ingen), styres graden af parallelitet med samtidig indlæsning af data fra Amazon RDS for SQL Server af Graden af kopi parallelitet under fanen indstillinger for kopiaktivitet.
Ingen: Vælg denne indstilling for ikke at bruge en partition.
Fysiske partitioner i tabellen: Når du bruger en fysisk partition, bestemmes partitionskolonnen og -mekanismen automatisk på baggrund af definitionen af din fysiske tabel.
Dynamisk område: Når du bruger en forespørgsel med parallel aktiveret, er områdepartitionsparameteren(
?DfDynamicRangePartitionCondition) nødvendig. Eksempelforespørgsel:SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition.Navn på partitionskolonne: Angiv navnet på kildekolonnen i heltals- eller dato-/datetime-typen (
int,smallint,bigint,datesmalldatetime,datetime,datetime2ellerdatetimeoffset), der bruges til områdepartitionering til parallel kopiering. Hvis den ikke er angivet, registreres indekset eller tabellens primære nøgle automatisk og bruges som partitionskolonnen.Hvis du bruger en forespørgsel til at hente kildedataene, skal du koble
?DfDynamicRangePartitionConditiontil WHERE-delsætningen. Du kan se et eksempel i afsnittet Parallel kopi fra SQL-database .Øvre partitionsgrænse: Angiv den maksimale værdi for partitionskolonnen for opdeling af partitionsområdet. Denne værdi bruges til at bestemme partitionsskridtet, ikke til filtrering af rækkerne i tabellen. Alle rækker i tabellen eller forespørgselsresultatet partitioneres og kopieres. Hvis den ikke er angivet, skal du automatisk registrere værdien for kopiering af aktivitet. Du kan se et eksempel i afsnittet Parallel kopi fra SQL-database .
Nedre grænse for partition: Angiv minimumværdien af partitionskolonnen for opdeling af partitionsområdet. Denne værdi bruges til at bestemme partitionsskridtet, ikke til filtrering af rækkerne i tabellen. Alle rækker i tabellen eller forespørgselsresultatet partitioneres og kopieres. Hvis den ikke er angivet, skal du automatisk registrere værdien for kopiering af aktivitet. Du kan se et eksempel i afsnittet Parallel kopi fra SQL-database .
Flere kolonner: Tilføj flere datakolonner for at gemme kildefilernes relative sti eller statiske værdi. Udtrykket understøttes for sidstnævnte.
Vær opmærksom på følgende punkter:
- Hvis Forespørgsel er angivet for kilde, kører kopiaktiviteten denne forespørgsel mod Amazon RDS for SQL Server-kilden for at hente dataene. Du kan også angive en lagret procedure ved at angive navn på lagret procedure og Parametre for lagret procedure, hvis den lagrede procedure kræver parametre.
- Når du bruger en lagret procedure i kilden til at hente data, skal du være opmærksom på, at hvis den lagrede procedure er designet til at returnere et andet skema, når der overføres en anden parameterværdi, kan der opstå fejl eller opstå uventede resultater, når skemaet importeres fra brugergrænsefladen, eller når du kopierer data til SQL-databasen med automatisk oprettelse af tabeller.
Tilknytning
For Konfiguration af fanen Tilknytning skal du gå til Konfigurer dine tilknytninger under fanen Tilknytning.
Indstillinger
For Konfiguration af fanen Indstillinger skal du gå til Konfigurer dine andre indstillinger under fanen Indstillinger.
Parallel kopi fra SQL-database
Amazon RDS til SQL Server-connectoren i kopiaktivitet giver indbygget datapartitionering for at kopiere data parallelt. Du kan finde indstillinger for datapartitionering under fanen Kilde i kopiaktiviteten.
Når du aktiverer partitioneret kopiering, kører kopieringsaktivitet parallelle forespørgsler mod din Amazon RDS til SQL Server-kilde for at indlæse data fra partitioner. Den parallelle grad styres af graden af kopi parallelitet under fanen indstillinger for kopiaktivitet. Hvis du f.eks. angiver Grad af kopi parallelitet til fire, genererer og kører tjenesten samtidig fire forespørgsler baseret på din angivne partitionsindstilling og dine angivne indstillinger, og hver forespørgsel henter en del af dataene fra din Amazon RDS til SQL Server.
Du foreslås at aktivere parallel kopiering med datapartitionering, især når du indlæser store mængder data fra din Amazon RDS til SQL Server. Følgende er foreslåede konfigurationer til forskellige scenarier. Når du kopierer data til et filbaseret datalager, anbefales det at skrive til en mappe som flere filer (angiv kun mappenavn), i hvilket tilfælde ydeevnen er bedre end at skrive til en enkelt fil.
| Scenarie | Foreslåede indstillinger |
|---|---|
| Fuld belastning fra store tabeller med fysiske partitioner. | Partitionsindstilling: Fysiske partitioner i tabellen. Under udførelsen registrerer tjenesten automatisk de fysiske partitioner og kopierer data fra partitioner. Hvis du vil kontrollere, om tabellen har en fysisk partition eller ej, kan du se denne forespørgsel. |
| Fuld belastning fra store tabeller uden fysiske partitioner, mens der er en heltals- eller datetime-kolonne til datapartitionering. | Partitionsindstillinger: Partition med dynamisk område. Partitionskolonne (valgfrit): Angiv den kolonne, der skal bruges til at partitionere data. Hvis den ikke er angivet, bruges kolonnen med den primære nøgle. Partition med øvre grænse og nedre partitionsgrænse (valgfri): Angiv, om du vil bestemme partitionens fremskridt. Dette er ikke til filtrering af rækkerne i tabellen. Alle rækker i tabellen partitioneres og kopieres. Hvis den ikke er angivet, registrerer kopiaktivitet automatisk værdierne, og det kan tage lang tid, afhængigt af værdierne MIN og MAX. Det anbefales at angive øvre og nedre grænse. Hvis partitionskolonnen "ID" f.eks. har værdier fra 1 til 100, og du angiver den nedre grænse som 20 og den øvre grænse som 80, med parallel kopi som 4, henter tjenesten data efter 4 partitioner – id'er i området <=20, [21, 50], [51, 80] og >=81. |
| Indlæs en stor mængde data ved hjælp af en brugerdefineret forespørgsel uden fysiske partitioner, mens du har et heltal eller en dato/datetime-kolonne til datapartitionering. | Partitionsindstillinger: Partition med dynamisk område. Forespørgsel: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.Partitionskolonne: Angiv den kolonne, der skal bruges til at partitionere data. Partition med øvre grænse og nedre partitionsgrænse (valgfri): Angiv, om du vil bestemme partitionens fremskridt. Dette er ikke til filtrering af rækkerne i tabellen. Alle rækker i forespørgselsresultatet partitioneres og kopieres. Hvis den ikke er angivet, skal du automatisk registrere værdien for kopiering af aktivitet. Hvis partitionskolonnen "ID" f.eks. har værdier fra 1 til 100, og du angiver den nedre grænse som 20 og den øvre grænse som 80, med parallel kopi som 4, henter tjenesten data efter henholdsvis 4 partitioner - id'er i området <=20, [21, 50], [51, 80] og >=81. Her er flere eksempelforespørgsler til forskellige scenarier: • Forespørg hele tabellen: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition• Forespørg fra en tabel med valg af kolonne og yderligere where-clause-filtre: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Forespørgsel med underforespørgsler: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Forespørgsel med partition i underforespørgsel: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Bedste fremgangsmåder til indlæsning af data med partitionsindstilling:
- Vælg en karakteristisk kolonne som partitionskolonne (f.eks. primær nøgle eller entydig nøgle) for at undgå dataforvrængelse.
- Hvis tabellen har en indbygget partition, skal du bruge partitionsindstillingen Fysiske partitioner i tabellen for at få en bedre ydeevne.
Eksempelforespørgsel til kontrol af fysisk partition
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Hvis tabellen har en fysisk partition, kan du se "HasPartition" som "ja" som følgende.

Tabeloversigt
Se følgende tabel for at få en oversigt og flere oplysninger om kopiaktiviteten Amazon RDS til SQL Server.
Kildeoplysninger
| Navn | Beskrivelse | Værdi | Obligatorisk | JSON-scriptegenskab |
|---|---|---|---|---|
| Datalagertype | Datalagertypen. | Eksternt | Ja | / |
| Forbindelse | Din forbindelse til kildedatalageret. | < din forbindelse > | Ja | forbindelse |
| Forbindelsestype | Din forbindelsestype. Vælg Amazon RDS til SQL Server. | Amazon RDS til SQL Server | Ja | / |
| Brug forespørgsel | Den brugerdefinerede SQL-forespørgsel til læsning af data. | •Bord •Forespørgsel • Lagret procedure |
Ja | / |
| Tabel | Din kildedatatabel. | < navnet på destinationstabellen> | Nr. | skema table |
| Forespørgsel | Den brugerdefinerede SQL-forespørgsel til læsning af data. | < din forespørgsel > | Nr. | sqlReaderQuery |
| Navn på lagret procedure | Denne egenskab er navnet på den lagrede procedure, der læser data fra kildetabellen. Den sidste SQL-sætning skal være en SELECT-sætning i den lagrede procedure. | < lagret procedurenavn > | Nr. | sqlReaderStoredProcedureName |
| Parameter for lagret procedure | Disse parametre gælder for den lagrede procedure. Tilladte værdier er navne- eller værdipar. Navnene på og kabinettet for parametre skal stemme overens med navnene og kabinettet for parametrene for den lagrede procedure. | < navne- eller værdipar > | Nr. | storedProcedureParameters |
| Timeout for forespørgsel | Timeout for udførelse af forespørgselskommando. | timespan (standarden er 120 minutter) |
Nr. | queryTimeout |
| Isolationsniveau | Angiver funktionsmåden for transaktionslåsning for SQL-kilden. | • Bekræftet læsning • Ikke-indlæst læsning • Læs igen •Serialiserbar •Snapshot |
Nr. | isolationLevel: • Skrivebeskyttet • ReadUncommitted • RepeatableRead •Serialiserbar •Snapshot |
| Partitionsindstilling | De indstillinger for datapartitionering, der bruges til at indlæse data fra Amazon RDS til SQL Server. | • Ingen (standard) • Fysiske partitioner i tabellen •Dynamikområde |
Nr. | partitionOption: • Ingen (standard) • PhysicalPartitionsOfTable • Dynamisk rækkefølge |
| Navn på partitionskolonne | Navnet på kildekolonnen i typen heltal eller dato/dato/klokkeslæt (int, smallint, bigint, smalldatetimedate, , datetime, datetime2eller datetimeoffset), der bruges af områdepartitionering til parallel kopiering. Hvis den ikke er angivet, registreres indekset eller tabellens primære nøgle automatisk og bruges som partitionskolonnen. Hvis du bruger en forespørgsel til at hente kildedataene, skal du koble ?DfDynamicRangePartitionCondition til WHERE-delsætningen. |
< navne på partitionskolonner > | Nr. | partitionColumnName |
| Partition, øvre grænse | Den maksimale værdi for partitionskolonnen for opdeling af partitionsområde. Denne værdi bruges til at bestemme partitionsskridtet, ikke til filtrering af rækkerne i tabellen. Alle rækker i tabellen eller forespørgselsresultatet partitioneres og kopieres. Hvis den ikke er angivet, skal du automatisk registrere værdien for kopiering af aktivitet. | < overbunden partition > | Nr. | partitionUpperBound |
| Partition med nedre grænse | Den mindste værdi for partitionskolonnen for opdeling af partitionsområdet. Denne værdi bruges til at bestemme partitionsskridtet, ikke til filtrering af rækkerne i tabellen. Alle rækker i tabellen eller forespørgselsresultatet partitioneres og kopieres. Hvis den ikke er angivet, skal du automatisk registrere værdien for kopiering af aktivitet. | < din nedre grænse for partition > | Nr. | partitionLowerBound |
| Flere kolonner | Tilføj yderligere datakolonner for at gemme kildefilernes relative sti eller statiske værdi. Udtrykket understøttes for sidstnævnte. | • Navn •Værdi |
Nr. | additionalColumns: •Navn •værdi |