Transformér data ved at køre en Azure HDInsight-aktivitet
Azure HDInsight-aktiviteten i Data Factory til Microsoft Fabric giver dig mulighed for at orkestrere følgende Azure HDInsight-jobtyper:
- Udfør Hive-forespørgsler
- Aktivér et MapReduce-program
- Udfør svineforespørgsler
- Udfør et Spark-program
- Udfør et Hadoop Stream-program
Denne artikel indeholder en trinvis gennemgang, der beskriver, hvordan du opretter en Azure HDInsight-aktivitet ved hjælp af Data Factory-grænsefladen.
Forudsætninger
For at komme i gang skal du fuldføre følgende forudsætninger:
- En lejerkonto med et aktivt abonnement. Opret en konto gratis.
- Der oprettes et arbejdsområde.
Føj en Azure HDInsight-aktivitet (HDI) til en pipeline med brugergrænseflade
Opret en ny datapipeline i dit arbejdsområde.
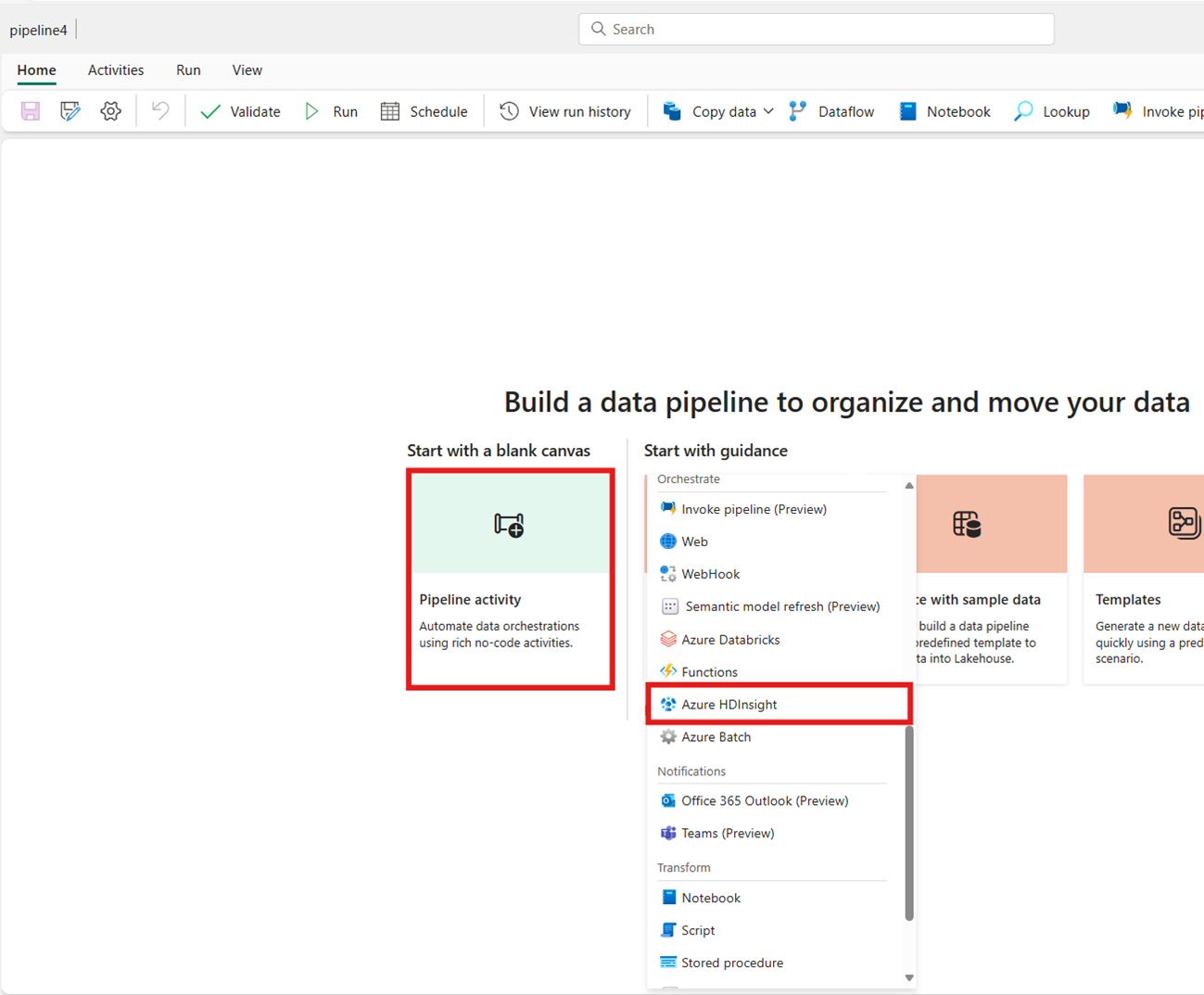
Søg efter Azure HDInsight på startskærmkortet, og vælg den, eller vælg aktiviteten på aktivitetslinjen for at føje den til pipelinelærredet.
Opretter aktiviteten fra startskærmkortet:
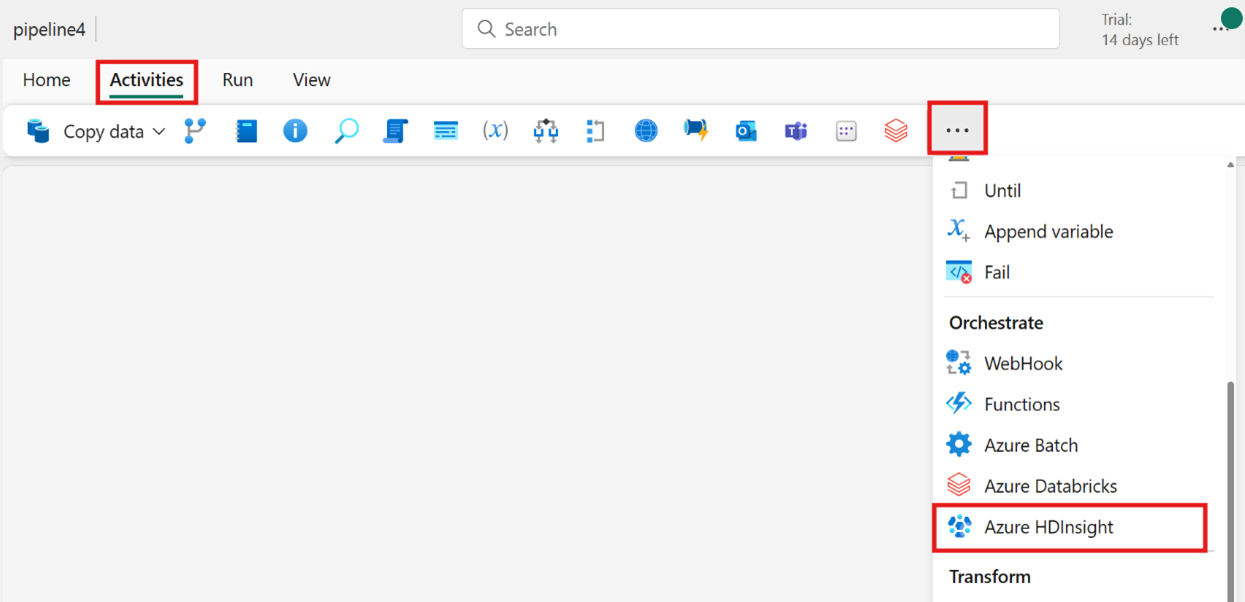
Opretter aktiviteten fra aktivitetslinjen:
Vælg den nye Azure HDInsight-aktivitet på lærredet i pipelineeditoren, hvis den ikke allerede er valgt.
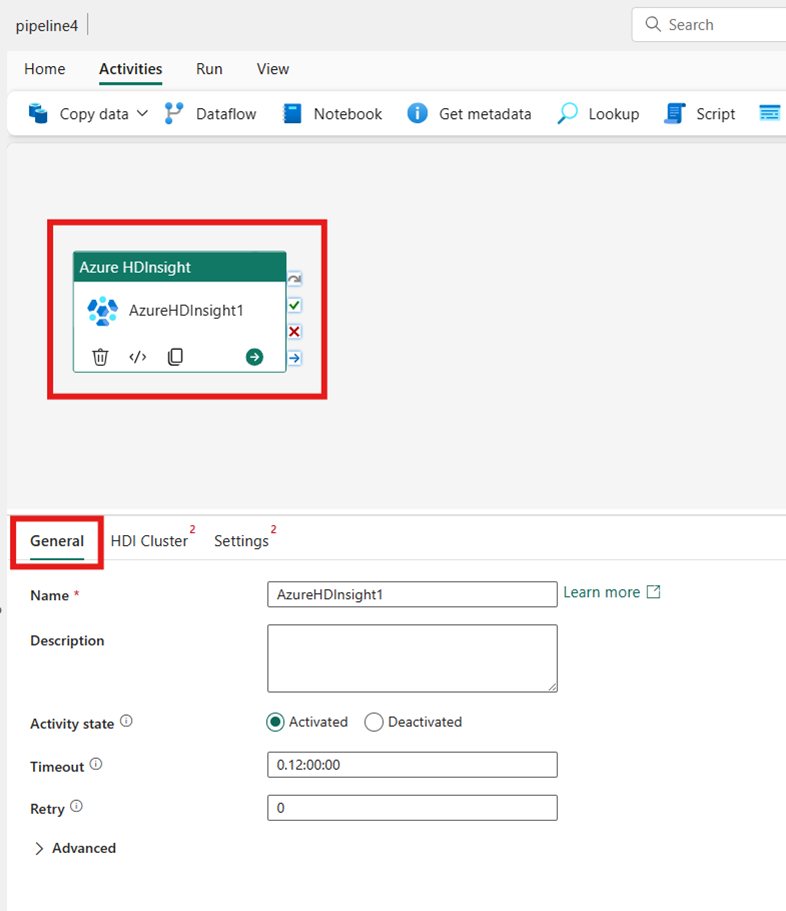
Se vejledningen til generelle indstillinger for at konfigurere de indstillinger, der findes under fanen Generelle indstillinger .

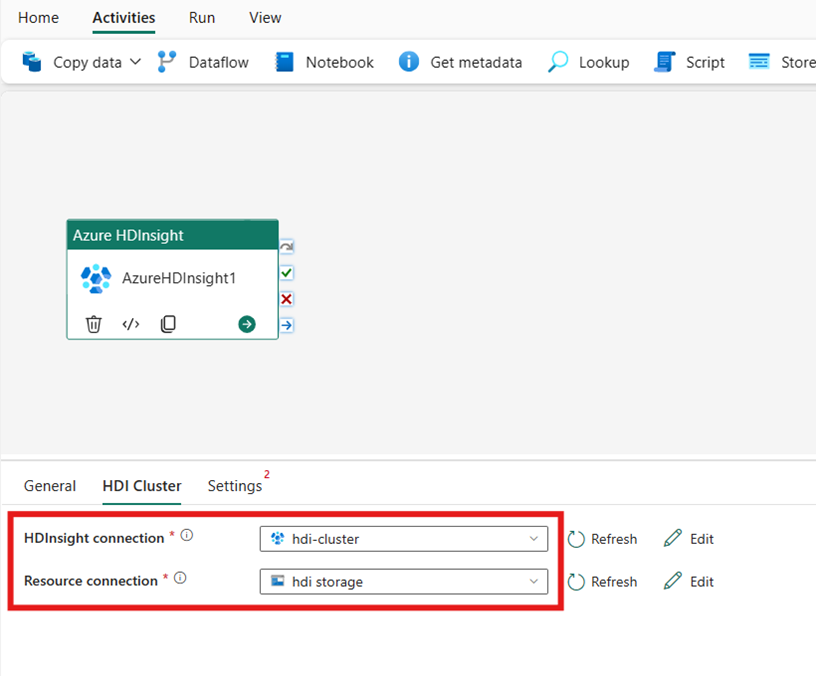
Konfigurer HDI-klyngen
Vælg fanen HDI-klynge. Derefter kan du vælge en eksisterende eller oprette en ny HDInsight-forbindelse.
For ressourceforbindelsen skal du vælge det Azure Blob Storage, der refererer til din Azure HDInsight-klynge. Du kan vælge et eksisterende bloblager eller oprette et nyt.
Konfigurere indstillinger
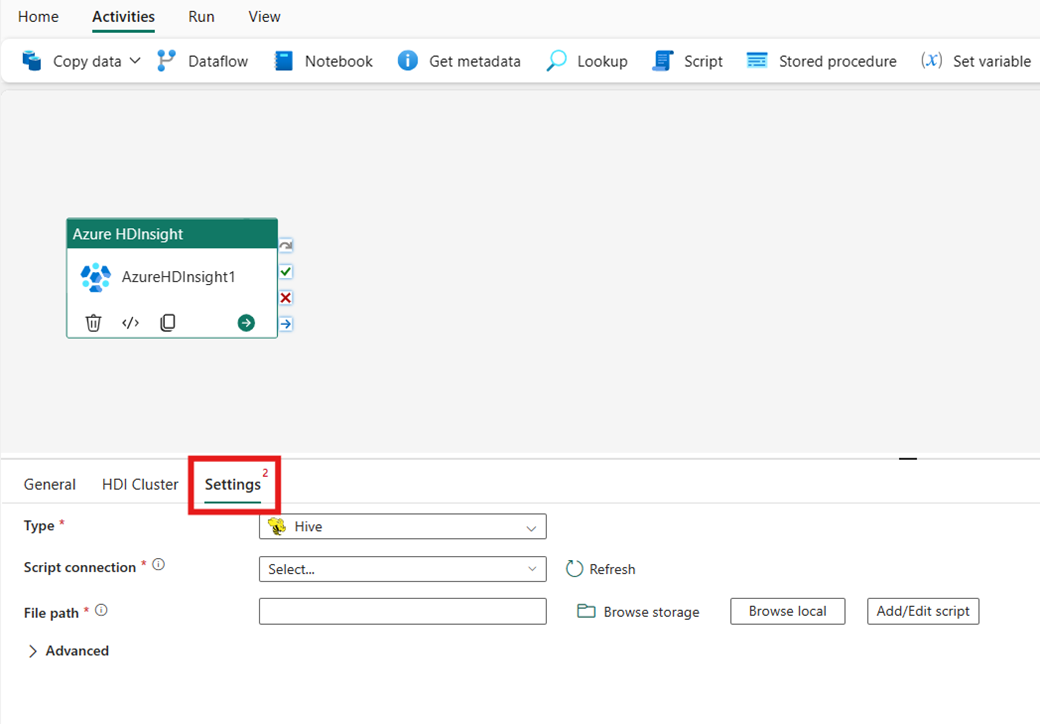
Vælg fanen Indstillinger for at se de avancerede indstillinger for aktiviteten.
Alle avancerede klyngeegenskaber og dynamiske udtryk, der understøttes i den tilknyttede Azure Data Factory- og Synapse Analytics HDInsight-tjeneste , understøttes nu også i Azure HDInsight-aktiviteten for Data Factory i Microsoft Fabric under afsnittet Avanceret i brugergrænsefladen. Disse egenskaber understøtter alle brugervenlige brugerdefinerede parameteriserede udtryk med dynamisk indhold.
Klyngetype
Hvis du vil konfigurere indstillinger for HDInsight-klyngen, skal du først vælge dens Type blandt de tilgængelige indstillinger, herunder Hive, Map Reduce, Pig, Spark og Streaming.
Hive
Hvis du vælger Hive som Type, udfører aktiviteten en Hive-forespørgsel. Du kan eventuelt angive scriptforbindelsen, der refererer til en lagerkonto, der har Hive-typen. Som standard bruges den lagerforbindelse, du angav under fanen HDI-klynger . Du skal angive den filsti , der skal udføres på Azure HDInsight. Du kan også angive flere konfigurationer i afsnittet Avanceret , Fejlfindingsoplysninger, Timeout for forespørgsel, Argumenter, Parametre og Variabler.
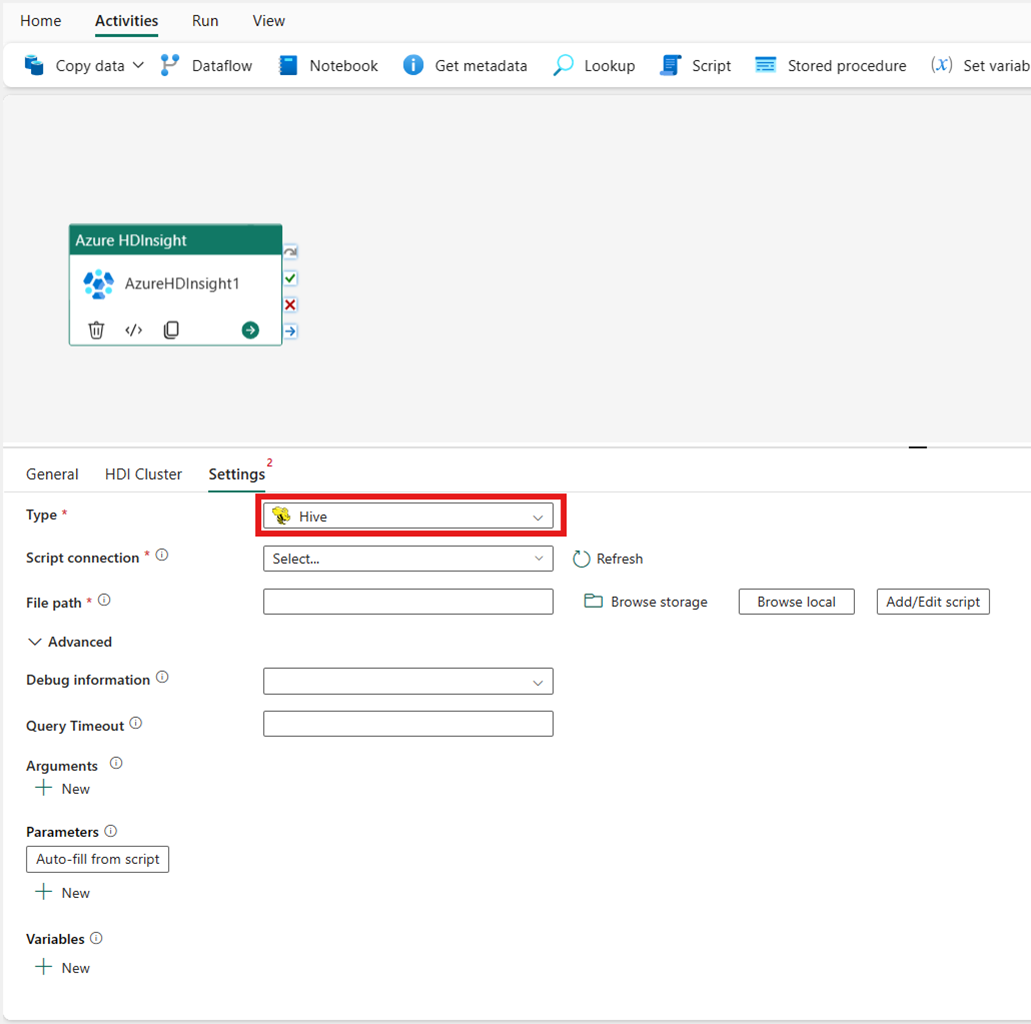
Reducer kort
Hvis du vælger Tilknyt reducer for type, aktiverer aktiviteten et kortreduceringsprogram. Du kan eventuelt angive i Jar-forbindelsen, der refererer til en lagerkonto, der har typen Kortreducering. Som standard bruges den lagerforbindelse, du angav under fanen HDI-klynger. Du skal angive det klassenavn og den filsti, der skal udføres på Azure HDInsight. Du kan eventuelt angive flere konfigurationsoplysninger, f.eks. import af Jar-biblioteker, fejlfindingsoplysninger, argumenter og parametre under afsnittet Avanceret .
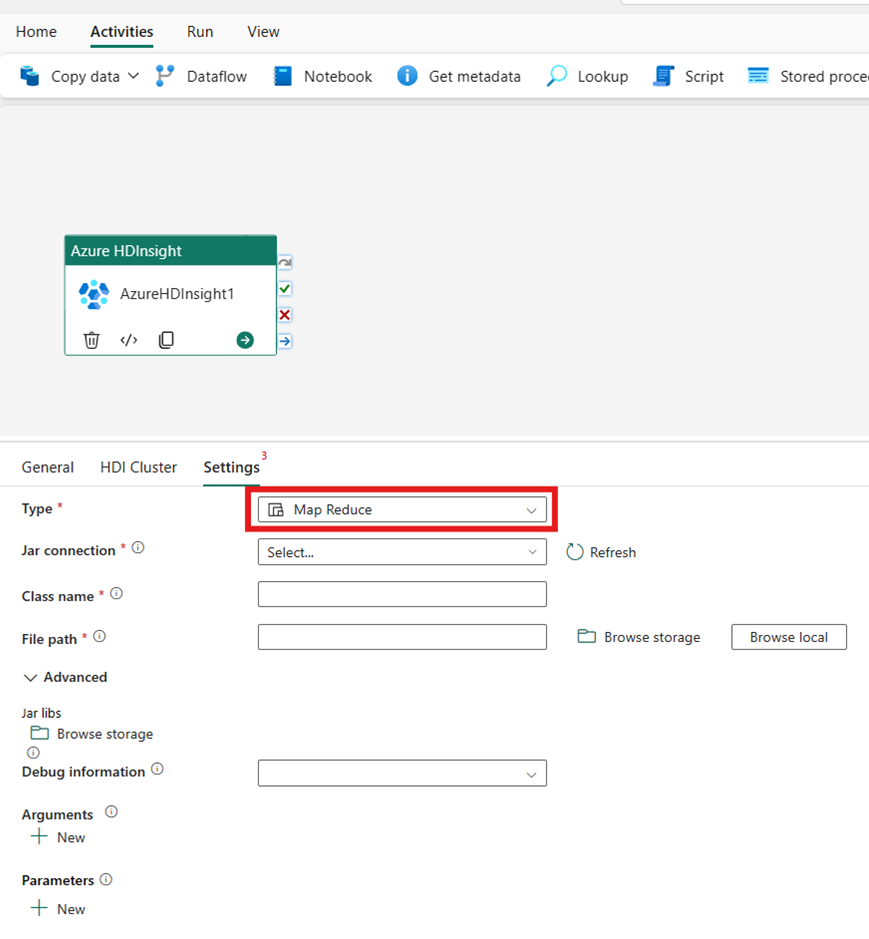
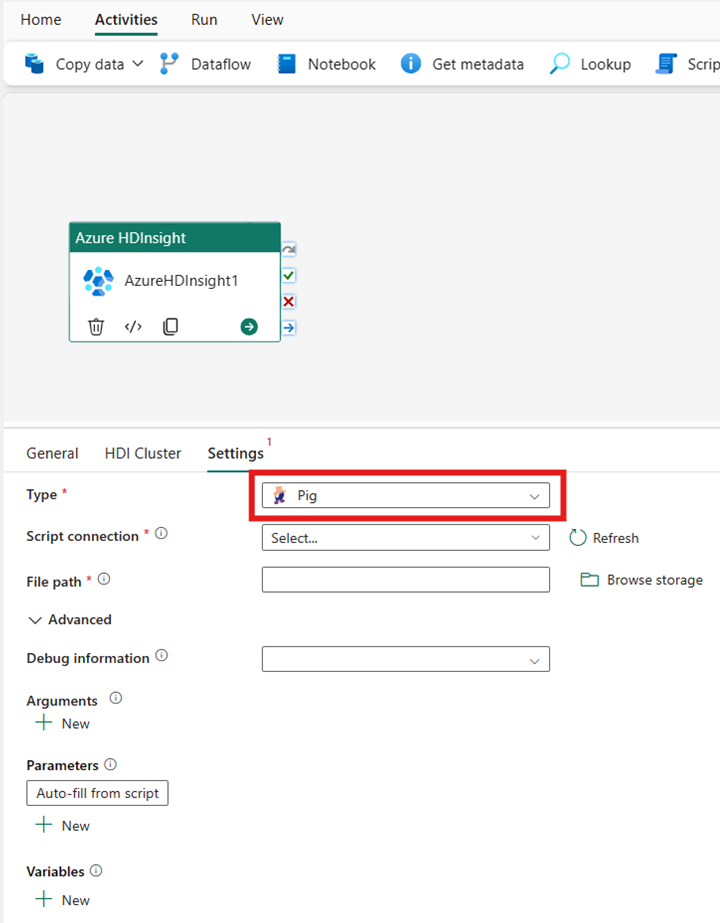
Pig
Hvis du vælger Svin som Type, aktiverer aktiviteten en grisforespørgsel. Du kan vælge at angive indstillingen Scriptforbindelse , der refererer til den lagerkonto, der indeholder svinetypen. Som standard bruges den lagerforbindelse, du angav under fanen HDI-klynger. Du skal angive den filsti , der skal udføres på Azure HDInsight. Du kan eventuelt angive flere konfigurationer, f.eks. fejlfindingsoplysninger, argumenter, parametre og variabler under afsnittet Avanceret .
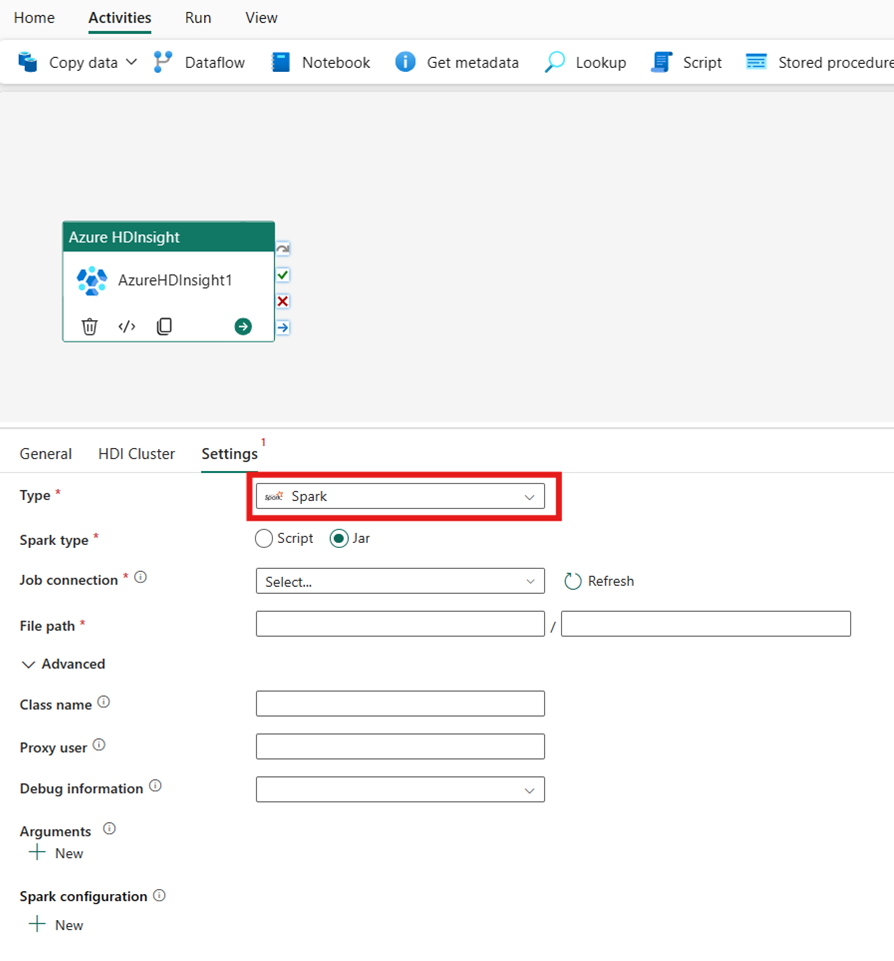
Spark
Hvis du vælger Spark som Type, aktiverer aktiviteten et Spark-program. Vælg enten Script eller Jar som Spark-type. Du kan eventuelt angive den jobforbindelse , der refererer til den lagerkonto, der har Spark-typen. Som standard bruges den lagerforbindelse, du angav under fanen HDI-klynger. Du skal angive den filsti , der skal udføres på Azure HDInsight. Du kan eventuelt angive flere konfigurationer, f.eks. klassenavn, proxybruger, fejlfindingsoplysninger, argumenter og spark-konfiguration under afsnittet Avanceret.
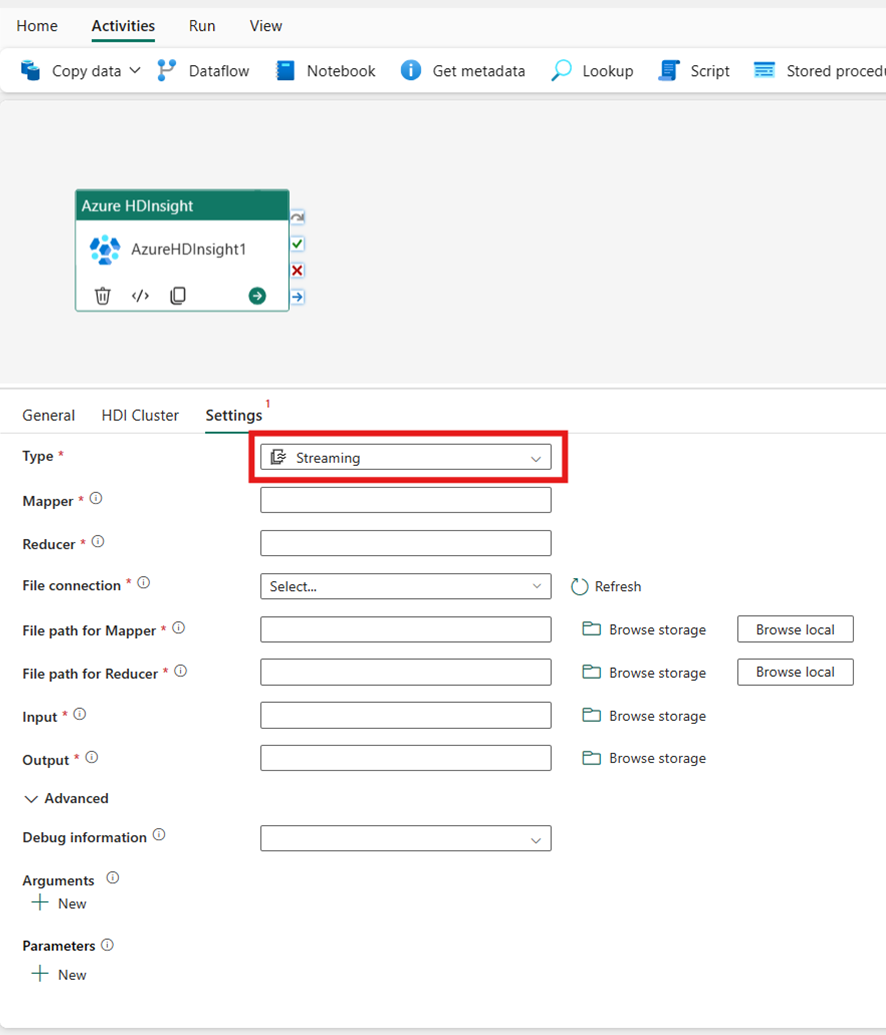
Streaming
Hvis du vælger Streaming for Type, aktiverer aktiviteten et streamingprogram. Angiv navnene Mapper og Reducer, og du kan eventuelt angive filforbindelsen, der refererer til den lagerkonto, der har streamingtypen. Som standard bruges den lagerforbindelse, du angav under fanen HDI-klynger. Du skal angive filstien for Mapper og Filsti til reduktion, der skal udføres på Azure HDInsight. Medtag også indstillingerne Input og Output for WASB-stien. Du kan eventuelt angive flere konfigurationer, f.eks. fejlfindingsoplysninger, argumenter og parametre under afsnittet Avanceret.
Egenskabsreference
| Egenskab | Beskrivelse | Obligatorisk |
|---|---|---|
| type | For Hadoop Streaming Activity er aktivitetstypen HDInsightStreaming | Ja |
| mapper | Angiver navnet på mapperens eksekverbare fil | Ja |
| Reduktionsgear | Angiver navnet på den eksekverbare reducer | Ja |
| Combiner | Angiver navnet på den eksekverbare kombinerbar fil | Nr. |
| filforbindelse | Reference til en Azure Storage Linked Service, der bruges til at gemme programmerne Mapper, Combiner og Reducer, der skal udføres. | Nr. |
| Her understøttes kun Azure Blob Storage- og ADLS Gen2-forbindelser. Hvis du ikke angiver denne forbindelse, bruges den lagerforbindelse, der er defineret i HDInsight-forbindelsen. | ||
| filePath | Angiv en matrix af stier til mapper-, kombiner- og reduktionsprogrammer, der er gemt i Azure Storage, som filforbindelsen henviser til. | Ja |
| input | Angiver WASB-stien til inputfilen til Mapper. | Ja |
| udgang | Angiver WASB-stien til outputfilen for reduktionsprogrammet. | Ja |
| getDebugInfo | Angiver, hvornår logfilerne kopieres til Azure Storage, der bruges af HDInsight-klyngen (eller), der er angivet af scriptLinkedService. | Nr. |
| Tilladte værdier: None, Always eller Failure. Standardværdi: Ingen. | ||
| Argumenter | Angiver en matrix af argumenter for et Hadoop-job. Argumenterne overføres som kommandolinjeargumenter til hver opgave. | Nr. |
| Definerer | Angiv parametre som nøgle-/værdipar til reference i Hive-scriptet. | Nr. |
Gem og kør eller planlæg pipelinen
Når du har konfigureret andre aktiviteter, der kræves til pipelinen, skal du skifte til fanen Hjem øverst i pipelineeditoren og vælge knappen Gem for at gemme pipelinen. Vælg Kør for at køre den direkte eller Planlæg for at planlægge den. Du kan også få vist kørselsoversigten her eller konfigurere andre indstillinger.
