Transformér data ved at køre en Azure Databricks-aktivitet
Azure Databricks-aktiviteten i Data Factory til Microsoft Fabric giver dig mulighed for at orkestrere følgende Azure Databricks-job:
- Notesbog
- Krukke
- Python
Denne artikel indeholder en trinvis gennemgang, der beskriver, hvordan du opretter en Azure Databricks-aktivitet ved hjælp af Data Factory-grænsefladen.
Forudsætninger
For at komme i gang skal du fuldføre følgende forudsætninger:
- En lejerkonto med et aktivt abonnement. Opret en konto gratis.
- Der oprettes et arbejdsområde.
Konfiguration af en Azure Databricks-aktivitet
Hvis du vil bruge en Azure Databricks-aktivitet i en pipeline, skal du udføre følgende trin:
Konfigurerer forbindelse
Opret en ny pipeline i dit arbejdsområde.
Klik på Tilføj en pipelineaktivitet, og søg efter Azure Databricks.
Du kan også søge efter Azure Databricks i ruden PipelineAktiviteter og vælge den for at føje den til pipelinelærredet.
Vælg den nye Azure Databricks-aktivitet på lærredet, hvis den ikke allerede er valgt.
Se vejledningen til generelle indstillinger for at konfigurere fanen Generelle indstillinger.
Konfiguration af klynger
Vælg fanen Klynge . Derefter kan du vælge en eksisterende eller oprette en ny Azure Databricks-forbindelse og derefter vælge en ny jobklynge, en eksisterende interaktiv klynge eller en eksisterende forekomstgruppe.
Afhængigt af hvad du vælger til klyngen, skal du udfylde de tilsvarende felter som præsenteret.
- Under ny jobklynge og eksisterende forekomstpulje har du også mulighed for at konfigurere antallet af arbejdere og aktivere staffageforekomster.
Du kan også angive yderligere klyngeindstillinger, f.eks . Klyngepolitik, Spark-konfiguration, Spark-miljøvariabler og brugerdefinerede mærker, som kræves for den klynge, du opretter forbindelse til. Databricks-initscripts og destinationsstien for klyngelog kan også tilføjes under de ekstra klyngeindstillinger.
Bemærk
Alle avancerede klyngeegenskaber og dynamiske udtryk, der understøttes i azure Data Factory Azure Databricks-linkede tjenester, understøttes nu også i Azure Databricks-aktiviteten i Microsoft Fabric under afsnittet "Yderligere klyngekonfiguration" i brugergrænsefladen. Da disse egenskaber nu er inkluderet i brugergrænsefladen for aktiviteter. De kan nemt bruges sammen med et udtryk (dynamisk indhold), uden at der er behov for den avancerede JSON-specifikation i Azure Data Factory Azure Databricks-linkede tjenesten.
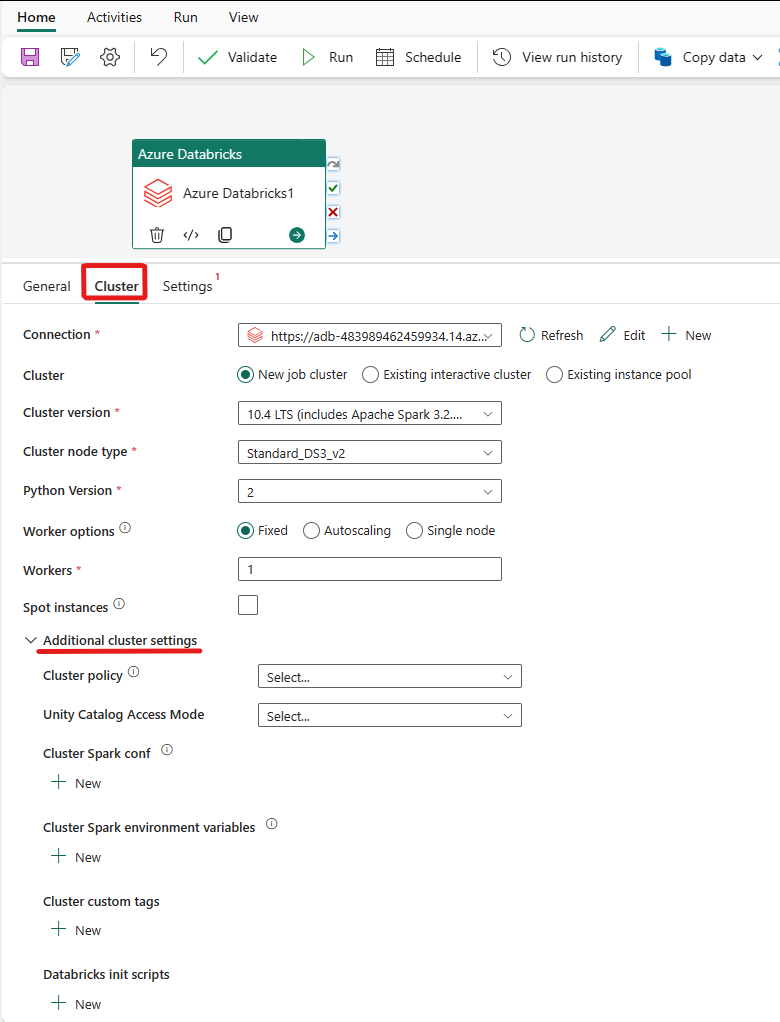
Azure Databricks Activity understøtter nu også klyngepolitik og understøttelse af Unity Catalog.
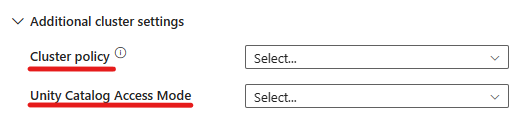
- Under avancerede indstillinger har du mulighed for at vælge klyngepolitikken , så du kan angive, hvilke klyngekonfigurationer der er tilladt.
- Under avancerede indstillinger har du også mulighed for at konfigurere Unity Catalog Access Mode for ekstra sikkerhed. De tilgængelige adgangstilstandstyper er:
- Adgangstilstand for enkelt bruger Denne tilstand er udviklet til scenarier, hvor hver klynge bruges af en enkelt bruger. Det sikrer, at dataadgangen i klyngen kun er begrænset til den pågældende bruger. Denne tilstand er nyttig til opgaver, der kræver isolation og individuel datahåndtering.
- Delt adgangstilstand I denne tilstand kan flere brugere få adgang til den samme klynge. Den kombinerer Unity Catalogs datastyring med de ældre ACL'er (Table Access Control List). Denne tilstand gør det muligt at få adgang til samarbejdsdata, samtidig med at du bevarer styrings- og sikkerhedsprotokoller. Den har dog visse begrænsninger, f.eks. ikke at understøtte Databricks Runtime ML, Spark-submit-job og specifikke Spark-API'er og UDF'er.
- Ingen adgangstilstand Denne tilstand deaktiverer interaktion med Unity Catalog, hvilket betyder, at klynger ikke har adgang til data, der administreres af Unity Catalog. Denne tilstand er nyttig til arbejdsbelastninger, der ikke kræver enhedskatalogets styringsfunktioner.
Konfigurerer indstillinger
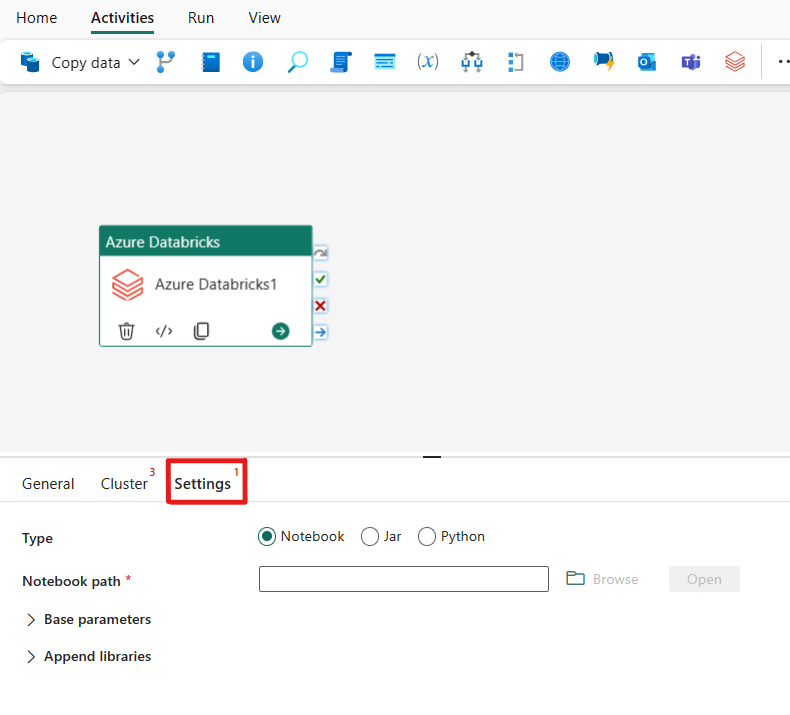
Hvis du vælger fanen Indstillinger , kan du vælge mellem tre indstillinger, som du vil orkestrere i Azure Databricks .
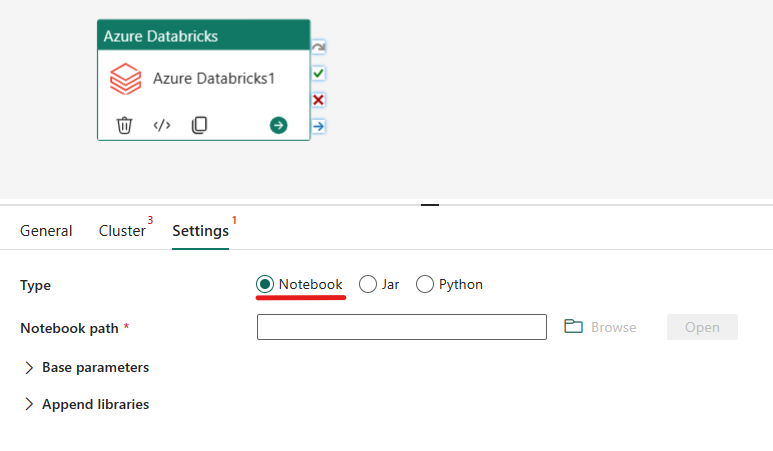
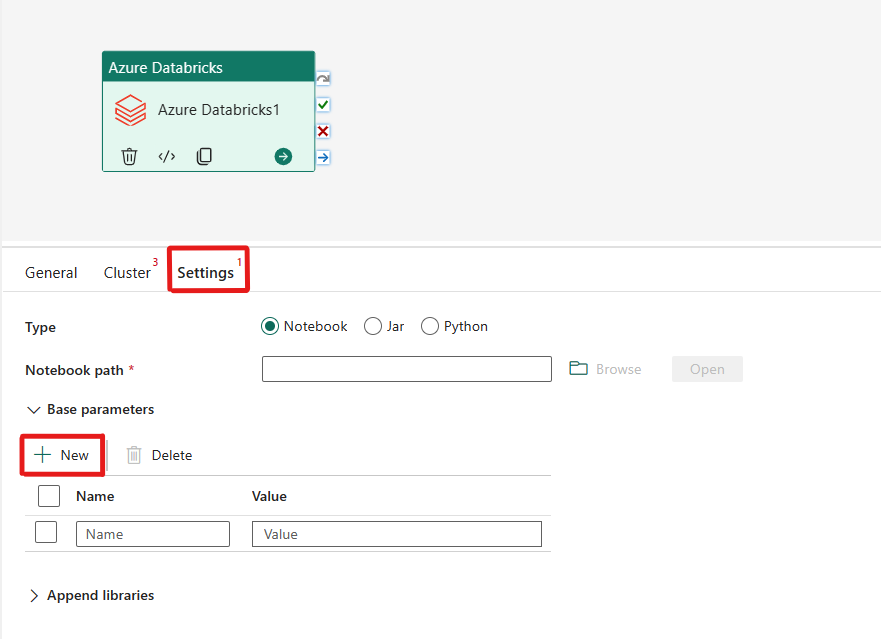
Orkestrering af notesbogtypen i Azure Databricks-aktiviteten:
Under fanen Indstillinger kan du vælge alternativknappen Notesbog for at køre en notesbog. Du skal angive den notesbogsti, der skal udføres på Azure Databricks, valgfri basisparametre, der skal overføres til notesbogen, og eventuelle yderligere biblioteker, der skal installeres på klyngen for at udføre jobbet.
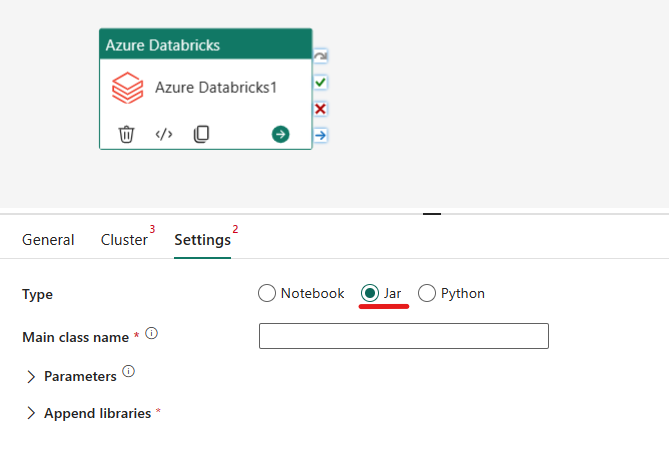
Orkestrering af Jar-typen i Azure Databricks-aktiviteten:
Under fanen Indstillinger kan du vælge alternativknappen Jar for at køre en krukke. Du skal angive det klassenavn, der skal udføres på Azure Databricks, valgfrie basisparametre, der skal overføres til jaren, og eventuelle yderligere biblioteker, der skal installeres på klyngen for at udføre jobbet.
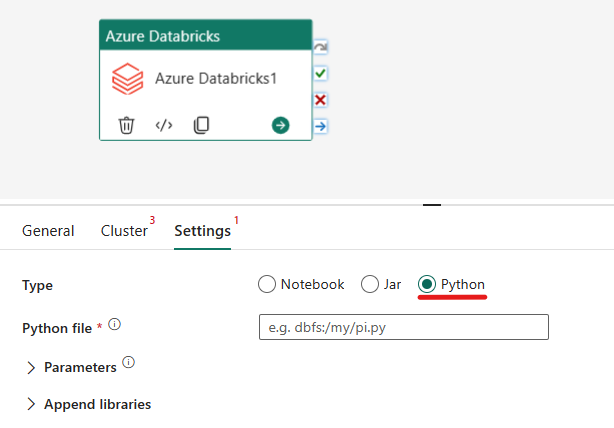
Orkestrering af Python-typen i Azure Databricks-aktivitet:
Under fanen Indstillinger kan du vælge alternativknappen Python for at køre en Python-fil. Du skal angive stien i Azure Databricks til en Python-fil, der skal udføres, valgfrie basisparametre, der skal overføres, og eventuelle yderligere biblioteker, der skal installeres på klyngen for at udføre jobbet.
Understøttede biblioteker til Azure Databricks-aktiviteten
I ovenstående Databricks-aktivitetsdefinition kan du angive disse bibliotekstyper: krukke, æg, whl, maven, pypi, cran.
Du kan få flere oplysninger i dokumentationen til Databricks for bibliotekstyper.
Overførsel af parametre mellem Azure Databricks-aktivitet og -pipelines
Du kan overføre parametre til notesbøger ved hjælp af egenskaben baseParameters i databricks-aktivitet.
I visse tilfælde kan det være nødvendigt at overføre visse værdier fra notesbogen tilbage til tjenesten, som kan bruges til at styre flowet (betinget kontrol) i tjenesten eller forbruges af downstream-aktiviteter (størrelsesgrænsen er 2 MB).
I din notesbog kan du f.eks. kalde dbutils.notebook.exit("returnValue"), og tilsvarende "returnValue" returneres til tjenesten.
Du kan forbruge outputtet i tjenesten ved hjælp af udtryk som
@{activity('databricks activity name').output.runOutput}.
Gem og kør eller planlæg pipelinen
Når du har konfigureret andre aktiviteter, der kræves til pipelinen, skal du skifte til fanen Hjem øverst i pipelineeditoren og vælge knappen Gem for at gemme pipelinen. Vælg Kør for at køre den direkte eller Planlæg for at planlægge den. Du kan også få vist kørselsoversigten her eller konfigurere andre indstillinger.
