Transformér data ved hjælp af dbt
Bemærk
Apache Airflow-jobbet drives af Apache Airflow.
dbt(Data Build Tool) er en kommandolinjegrænseflade med åben kildekode, der forenkler datatransformation og modellering i data warehouses ved at administrere kompleks SQL-kode på en struktureret, vedligeholdbar måde. Det gør det muligt for datateams at oprette pålidelige transformationer, der kan testes, i kernen af deres analysepipelines.
Når dbt er parret med Apache Airflow, forbedres transformationsfunktionerne af Airflows planlægnings-, orkestrerings- og opgavestyringsfunktioner. Denne kombinerede tilgang, der bruger dbt's transformationsekspertise sammen med Airflows arbejdsprocesstyring, leverer effektive og robuste datapipelines, hvilket i sidste ende fører til hurtigere og mere indsigtsfulde datadrevne beslutninger.
Dette selvstudium illustrerer, hvordan du opretter en Apache Airflow DAG, der bruger dbt til at transformere data, der er gemt i Microsoft Fabric Data Warehouse.
Forudsætninger
For at komme i gang skal du fuldføre følgende forudsætninger:
Aktivér Apache Airflow-job i din lejer.
Bemærk
Da Apache Airflow-jobbet er i prøveversionstilstand, skal du aktivere det via din lejeradministrator. Hvis du allerede kan se Apache Airflow Job, har din lejeradministrator muligvis allerede aktiveret det.
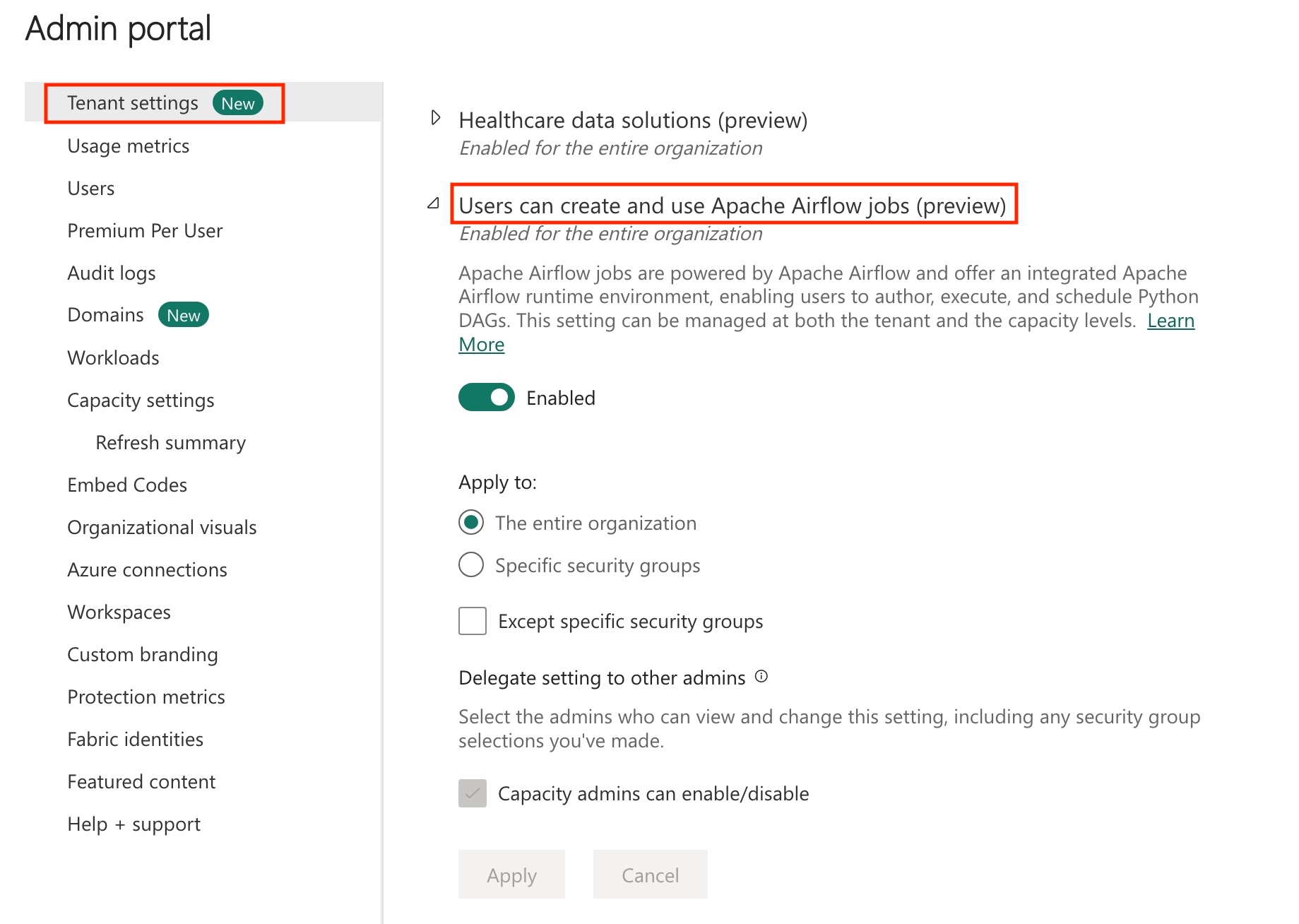
Gå til administrationsportalen –> Lejerindstillinger –> under Microsoft Fabric –> Udvid afsnittet "Brugere kan oprette og bruge Apache Airflow Job (prøveversion)".
Vælg Anvend.
Opret tjenesteprincipalen. Tilføj tjenesteprincipalen
Contributorsom i det arbejdsområde, hvor du opretter data warehouse.Hvis du ikke har et, skal du oprette et Fabric-lager. Indfødning af eksempeldataene i lageret ved hjælp af datapipeline. I dette selvstudium bruger vi EKSEMPLET NYC Taxi-Green .

Transformér de data, der er gemt i Fabric Warehouse, ved hjælp af dbt
I dette afsnit gennemgås følgende trin:
- Angiv kravene.
- Opret et dbt-projekt i det Fabric-administrerede lager, der leveres af Apache Airflow-jobbet.
- Opret en Apache Airflow DAG for at orkestrere dbt-job
Angiv kravene
Opret en fil requirements.txt i mappen dags . Tilføj følgende pakker som Apache Airflow-krav.
astronomer-cosmos: Denne pakke bruges til at køre dine dbt-kerneprojekter som Apache Airflow-dags og opgavegrupper.
dbt-fabric: Denne pakke bruges til at oprette dbt-projekt, som derefter kan udrulles til et Fabric Data Warehouse
astronomer-cosmos==1.0.3 dbt-fabric==1.5.0
Opret et dbt-projekt i det Fabric-administrerede lager, der leveres af Apache Airflow-jobbet.
I dette afsnit opretter vi et eksempel på et dbt-projekt i Apache Airflow-jobbet for datasættet
nyc_taxi_greenmed følgende mappestruktur.dags |-- my_cosmos_dag.py |-- nyc_taxi_green | |-- profiles.yml | |-- dbt_project.yml | |-- models | | |-- nyc_trip_count.sql | |-- targetOpret den mappe, der er navngivet
nyc_taxi_greeni mappendagsmedprofiles.ymlfilen. Denne mappe indeholder alle de filer, der kræves til dbt-projektet.
Kopiér følgende indhold til
profiles.yml. Denne konfigurationsfil indeholder oplysninger om databaseforbindelse og profiler, der bruges af dbt. Opdater pladsholderværdierne, og gem filen.config: partial_parse: true nyc_taxi_green: target: fabric-dev outputs: fabric-dev: type: fabric driver: "ODBC Driver 18 for SQL Server" server: <sql connection string of your data warehouse> port: 1433 database: "<name of the database>" schema: dbo threads: 4 authentication: ServicePrincipal tenant_id: <Tenant ID of your service principal> client_id: <Client ID of your service principal> client_secret: <Client Secret of your service principal>Opret filen,
dbt_project.ymlog kopiér følgende indhold. Denne fil angiver konfigurationen på projektniveau.name: "nyc_taxi_green" config-version: 2 version: "0.1" profile: "nyc_taxi_green" model-paths: ["models"] seed-paths: ["seeds"] test-paths: ["tests"] analysis-paths: ["analysis"] macro-paths: ["macros"] target-path: "target" clean-targets: - "target" - "dbt_modules" - "logs" require-dbt-version: [">=1.0.0", "<2.0.0"] models: nyc_taxi_green: materialized: tableOpret mappen
modelsi mappennyc_taxi_green. I dette selvstudium opretter vi eksempelmodellen i filen med navnetnyc_trip_count.sql, der opretter tabellen, der viser antallet af ture pr. dag pr. leverandør. Kopiér følgende indhold i filen.with new_york_taxis as ( select * from nyctlc ), final as ( SELECT vendorID, CAST(lpepPickupDatetime AS DATE) AS trip_date, COUNT(*) AS trip_count FROM [contoso-data-warehouse].[dbo].[nyctlc] GROUP BY vendorID, CAST(lpepPickupDatetime AS DATE) ORDER BY vendorID, trip_date; ) select * from final


Opret en Apache Airflow DAG for at orkestrere dbt-job
Opret filen med navnet
my_cosmos_dag.pyidagsmappen, og indsæt følgende indhold i den.import os from pathlib import Path from datetime import datetime from cosmos import DbtDag, ProjectConfig, ProfileConfig, ExecutionConfig DEFAULT_DBT_ROOT_PATH = Path(__file__).parent.parent / "dags" / "nyc_taxi_green" DBT_ROOT_PATH = Path(os.getenv("DBT_ROOT_PATH", DEFAULT_DBT_ROOT_PATH)) profile_config = ProfileConfig( profile_name="nyc_taxi_green", target_name="fabric-dev", profiles_yml_filepath=DBT_ROOT_PATH / "profiles.yml", ) dbt_fabric_dag = DbtDag( project_config=ProjectConfig(DBT_ROOT_PATH,), operator_args={"install_deps": True}, profile_config=profile_config, schedule_interval="@daily", start_date=datetime(2023, 9, 10), catchup=False, dag_id="dbt_fabric_dag", )
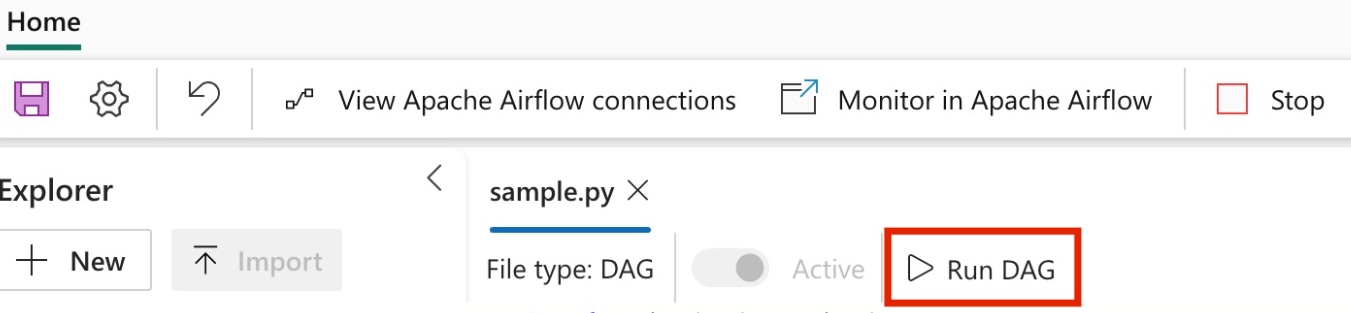
Kør din DAG
Kør DAG i Apache Airflow Job.
Hvis du vil se din dag indlæst i Apache Airflow-brugergrænsefladen, skal du klikke på
Monitor in Apache Airflow.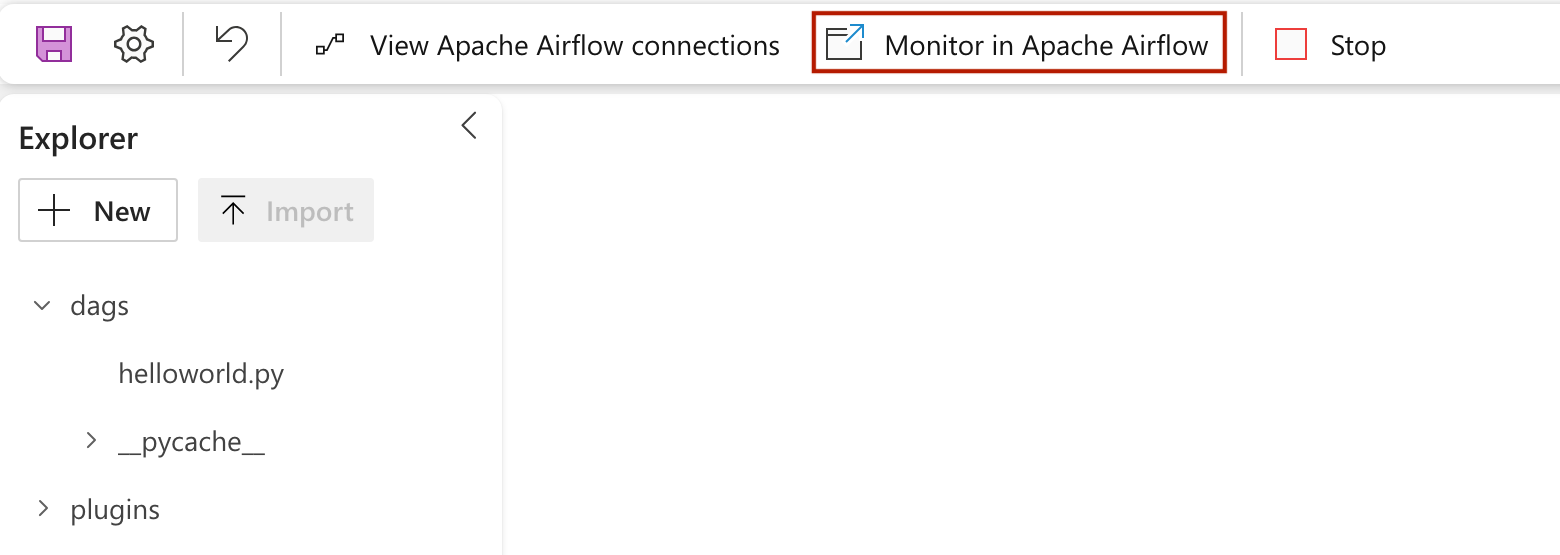
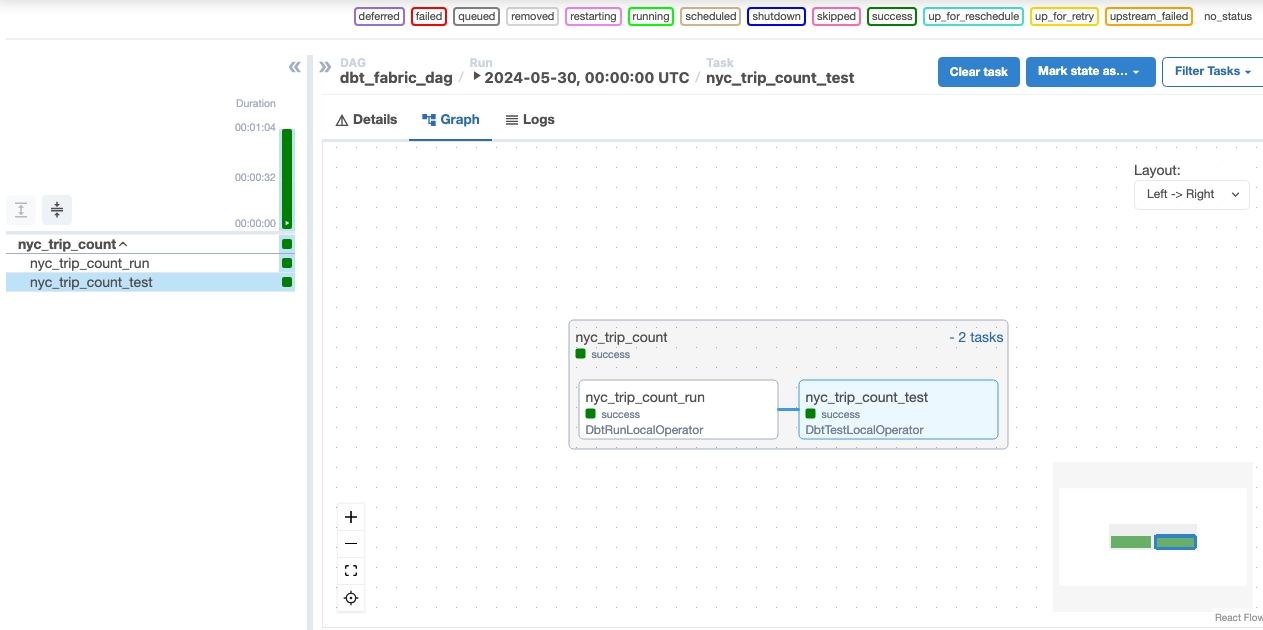



Valider dine data
- Når du har kørt, kan du for at validere dine data se den nye tabel med navnet 'nyc_trip_count.sql', der er oprettet i dit Fabric-data warehouse.

