Notesbogvisualisering i Microsoft Fabric
Microsoft Fabric er en integreret analysetjeneste, der fremskynder tiden til indsigt på tværs af data warehouses og big data analytics-systemer. Datavisualisering i notesbøger er en vigtig komponent, der giver dig mulighed for at få indsigt i dine data. Det hjælper med at gøre store og små data nemmere for mennesker at forstå. Det gør det også nemmere at registrere mønstre, tendenser og udenforliggende værdier i grupper af data.
Når du bruger Apache Spark i Fabric, er der forskellige indbyggede muligheder for at hjælpe dig med at visualisere dine data, herunder indstillinger for Fabric-notesbogdiagram og adgang til populære biblioteker med åben kildekode.
Når du bruger en Fabric-notesbog, kan du omdanne visningen af tabelresultater til et tilpasset diagram ved hjælp af diagramindstillinger. Her kan du visualisere dine data uden at skulle skrive kode.
Indbygget visualiseringskommando – funktionen display()
Den indbyggede visualiseringsfunktion Fabric giver dig mulighed for at omdanne Apache Spark DataFrames, Pandas DataFrames og SQL-forespørgselsresultater til omfattende formatdatavisualiseringer.
Du kan bruge visningsfunktionen på datarammer, der er oprettet i PySpark og Scala på Spark DataFrames eller RDD-funktioner (Resilient Distributed Datasets) til at oprette den omfattende tabelvisning og diagramvisning af datarammen.
Du kan angive rækkeantallet for den dataramme, der gengives. Standardværdien er 1000. Notebook-vise outputwidget understøtter visning og profil højst 10.000 rækker i en dataramme.

Du kan bruge filterfunktionen på den globale værktøjslinje til at filtrere de data, der tilknyttes med din brugerdefinerede regel effektivt, betingelsen anvendes på den angivne kolonne, og filterresultatet afspejles i både tabelvisning og diagramvisning.

Outputtet fra SQL-sætningen anvender den samme outputwidget med display() som standard.
Avanceret datarammetabelvisning
Understøttelse af gratis valg i tabelvisning
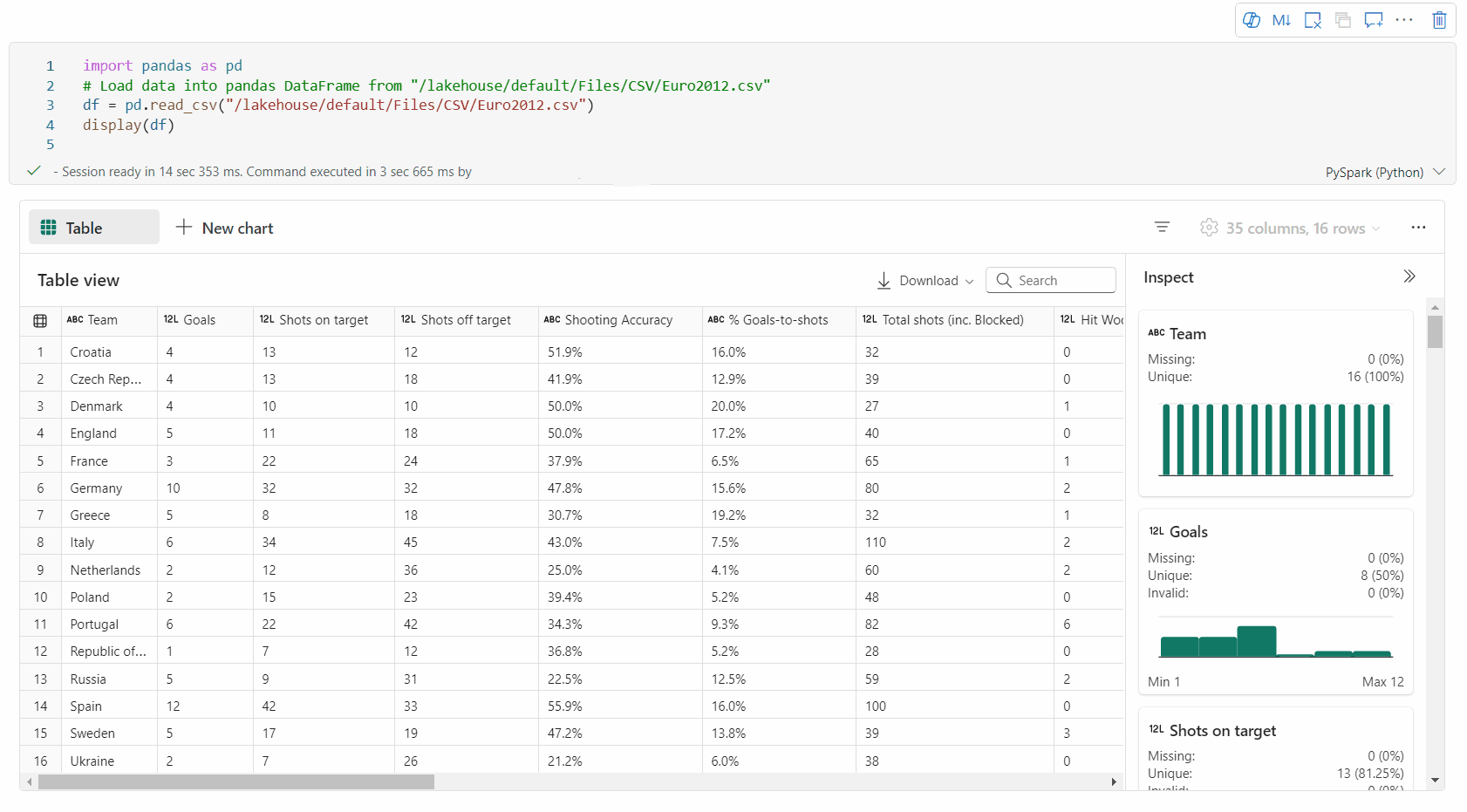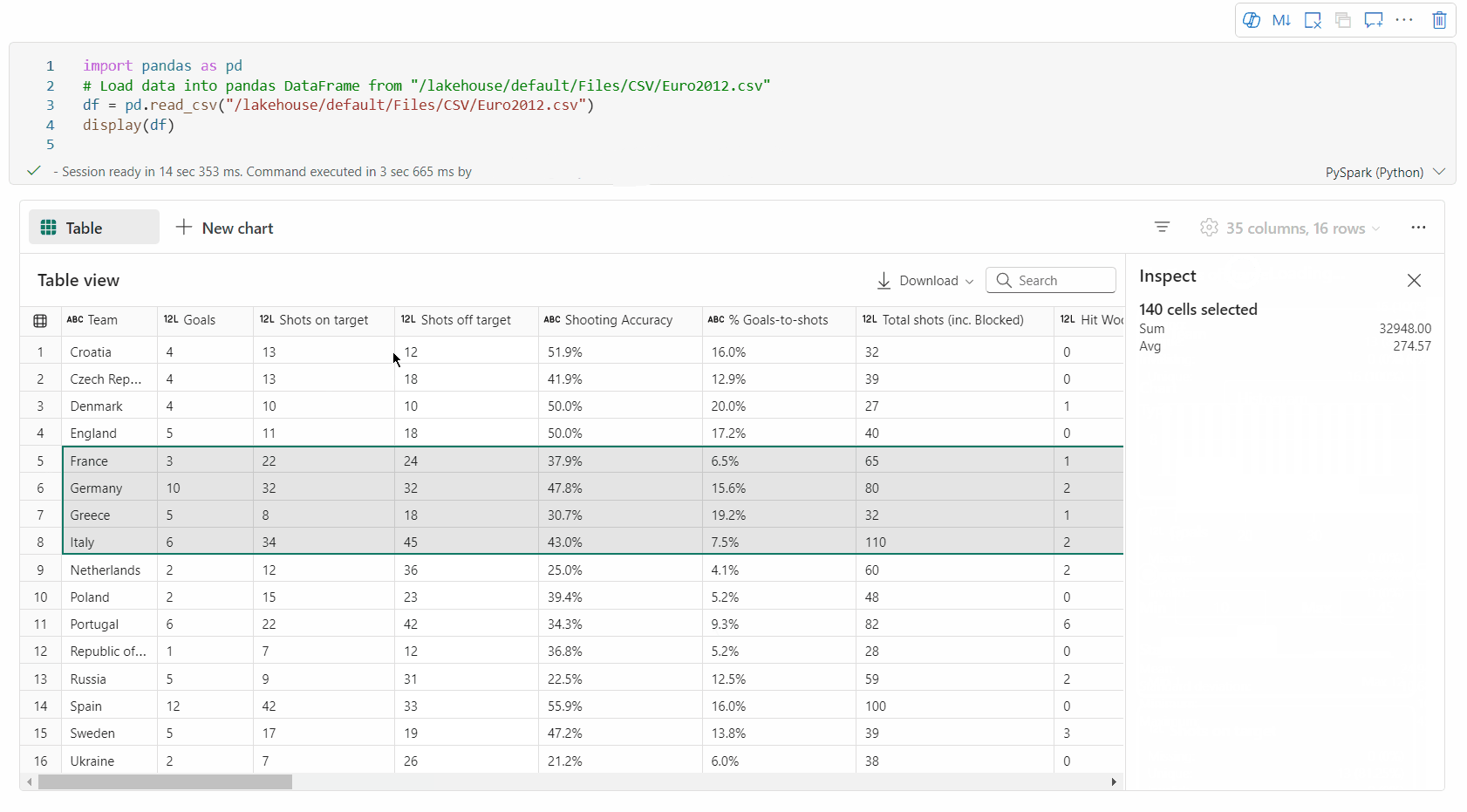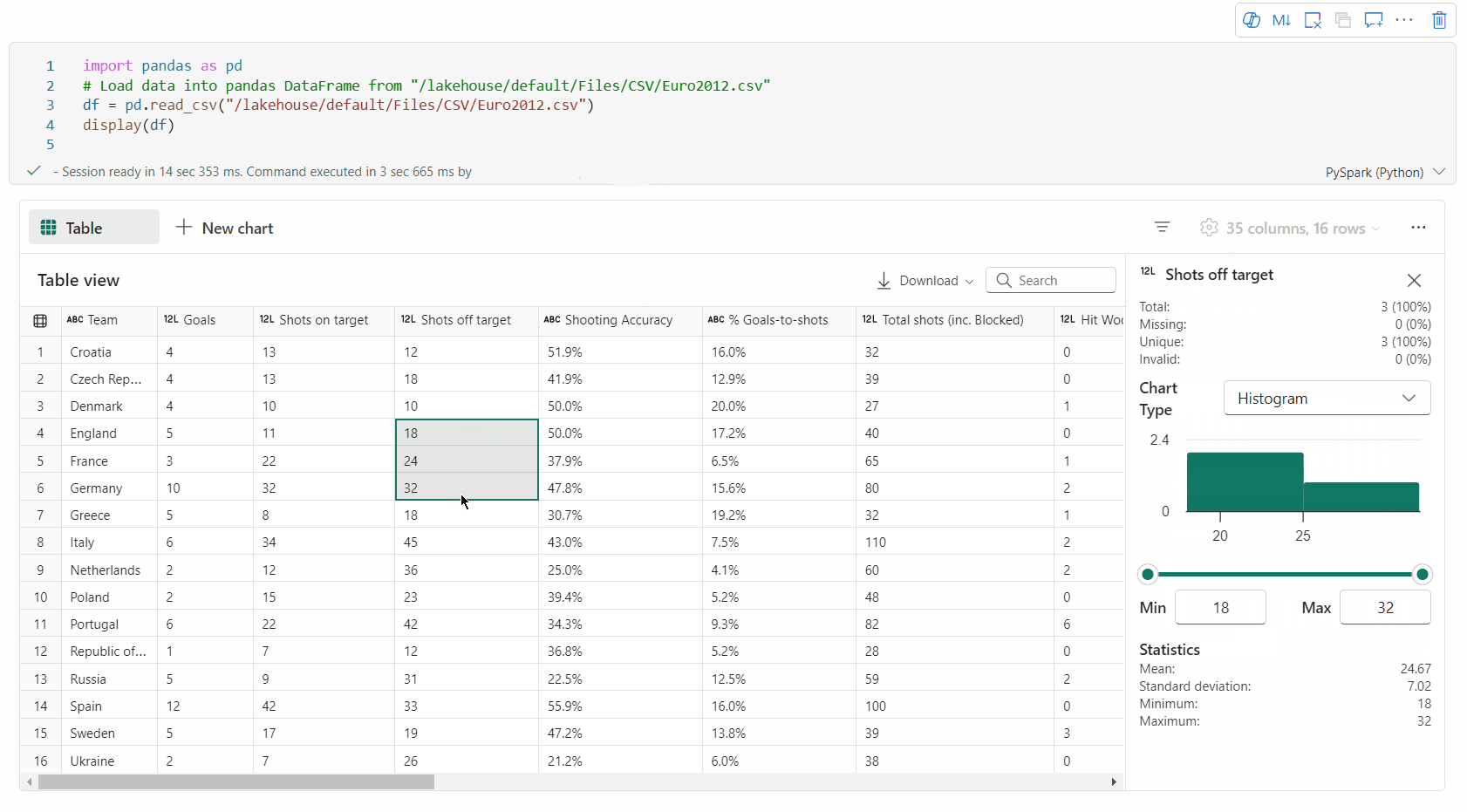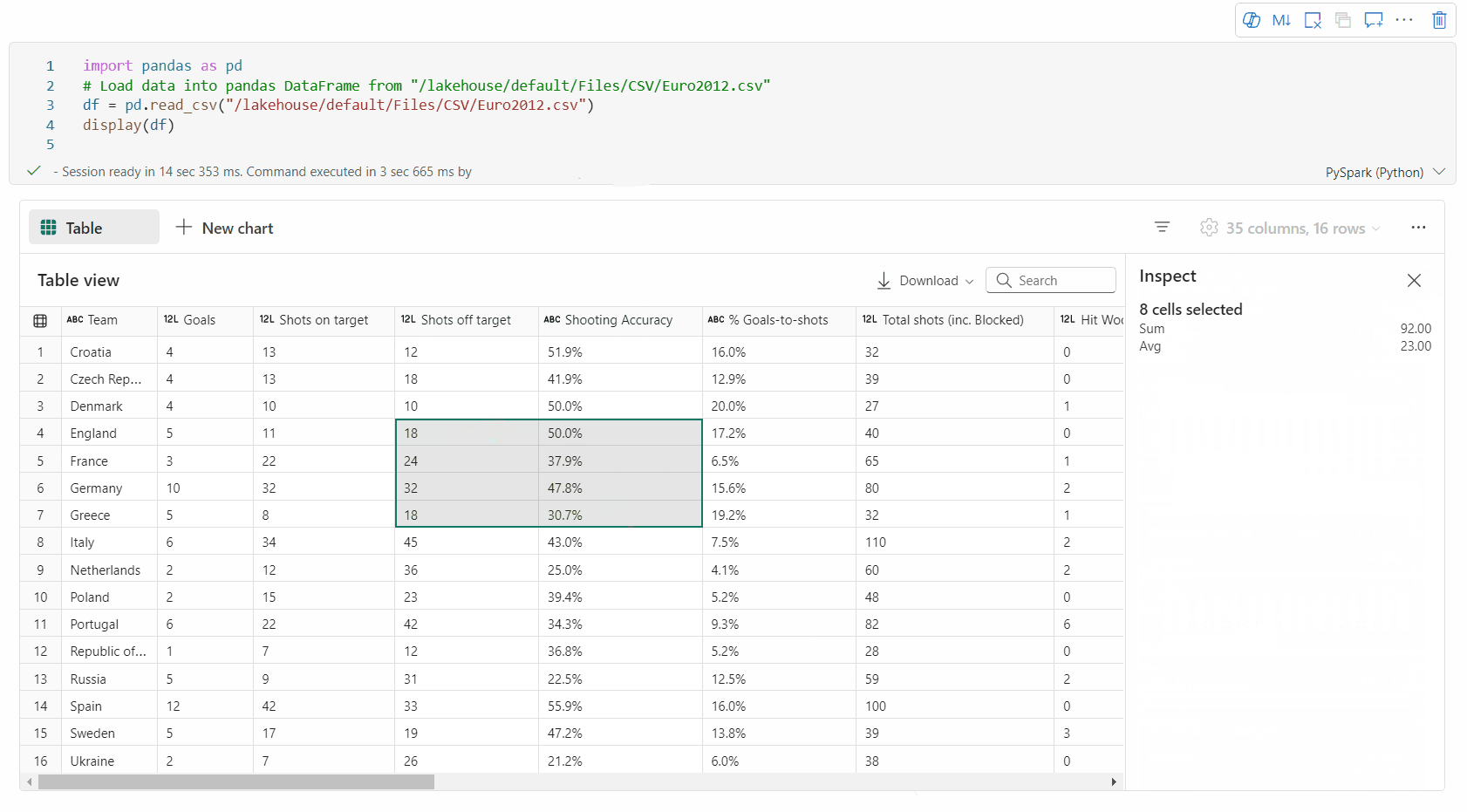
Tabelvisning gengives som standard, når du bruger kommandoen display(). Den omfattende prøveversion af dataramme i notesbogen tilbyder en gratis valgfunktion, der er designet til at forbedre dataanalyseoplevelsen via fleksible og intuitive valgfunktioner. Denne funktion giver brugerne mulighed for at interagere med dataframes mere effektivt og nemt få dybere indsigt.
valg af kolonne
- Enkelt kolonne: Klik på kolonneoverskriften for at markere hele kolonnen.
- Flere kolonner: Når du har valgt en enkelt kolonne, skal du trykke på skift og holde den nede og derefter klikke på en anden kolonneoverskrift for at markere flere kolonner.
rækkemarkering
- Enkelt række: Klik på en rækkeoverskrift for at markere hele rækken.
- Flere rækker: Når du har valgt en enkelt række, skal du trykke på skift og holde den nede og derefter klikke på en anden rækkeoverskrift for at markere flere rækker.
Eksempel på celleindhold: Få vist indholdet af de enkelte celler for at få et hurtigt og detaljeret indblik i dataene uden at skulle skrive yderligere kode.
Kolonneoversigt: Få en oversigt over hver kolonne, herunder datadistribution og nøglestatistikker, for hurtigt at forstå dataenes egenskaber.
valg af friområde: Markér et vilkårligt fortløbende segment i tabellen for at få en oversigt over de markerede celler i alt og de numeriske værdier i det markerede område.
Kopierer markeret indhold: I alle markeringssager kan du hurtigt kopiere det markerede indhold ved hjælp af genvejen 'Ctrl + C'. De valgte data kopieres i CSV-format, hvilket gør det nemt at behandle dem i andre programmer.
Understøttelse af dataprofilering via ruden Undersøg
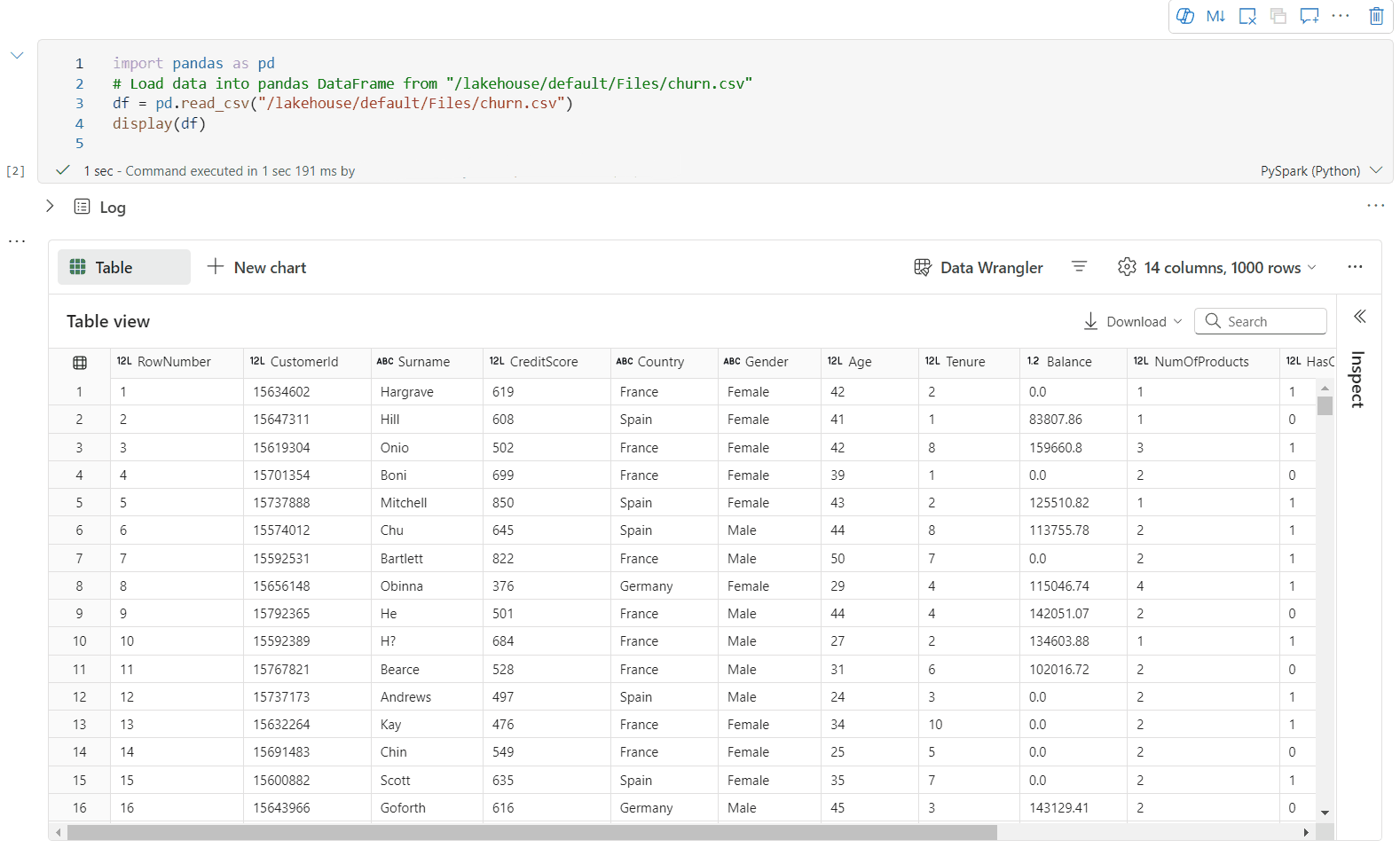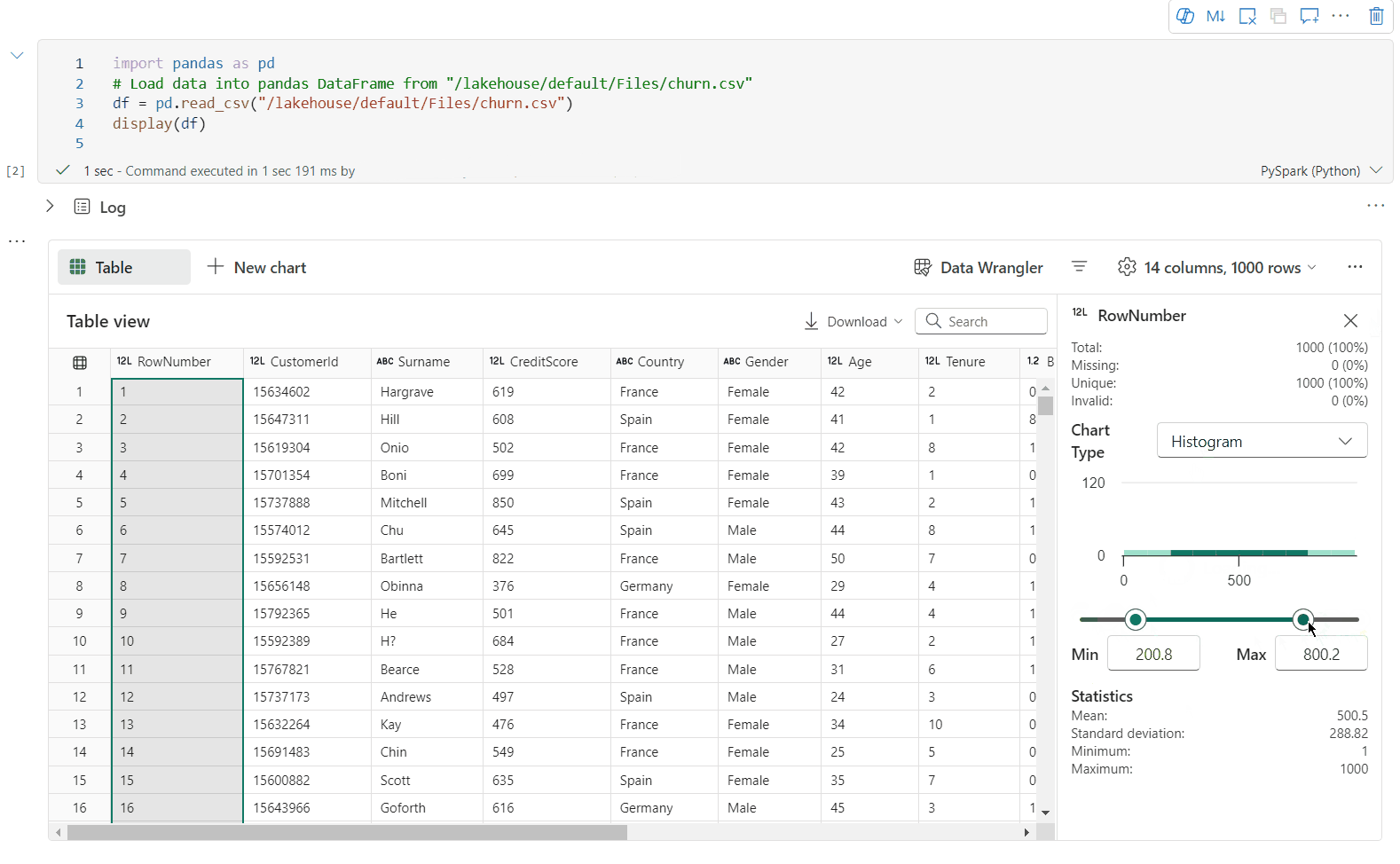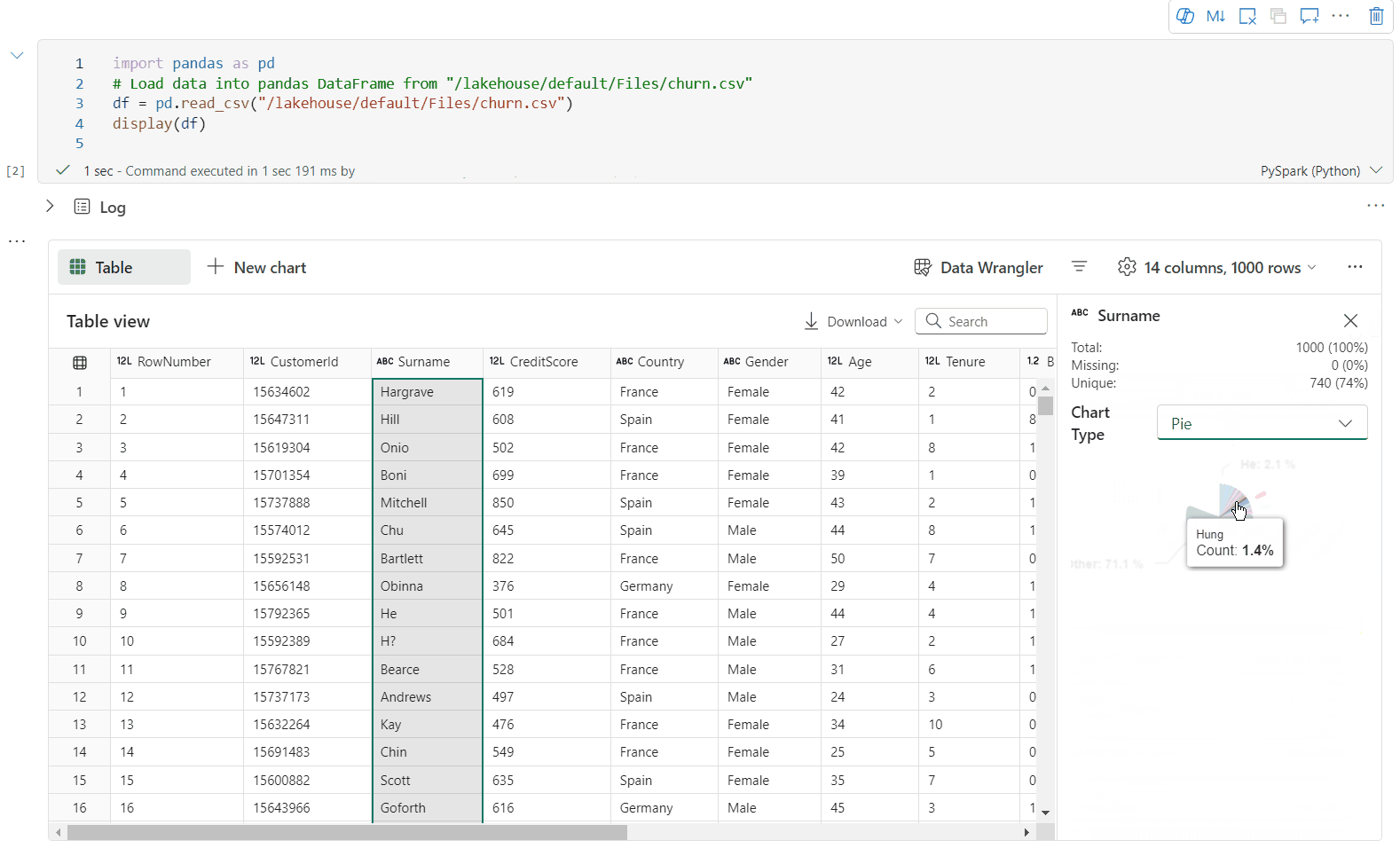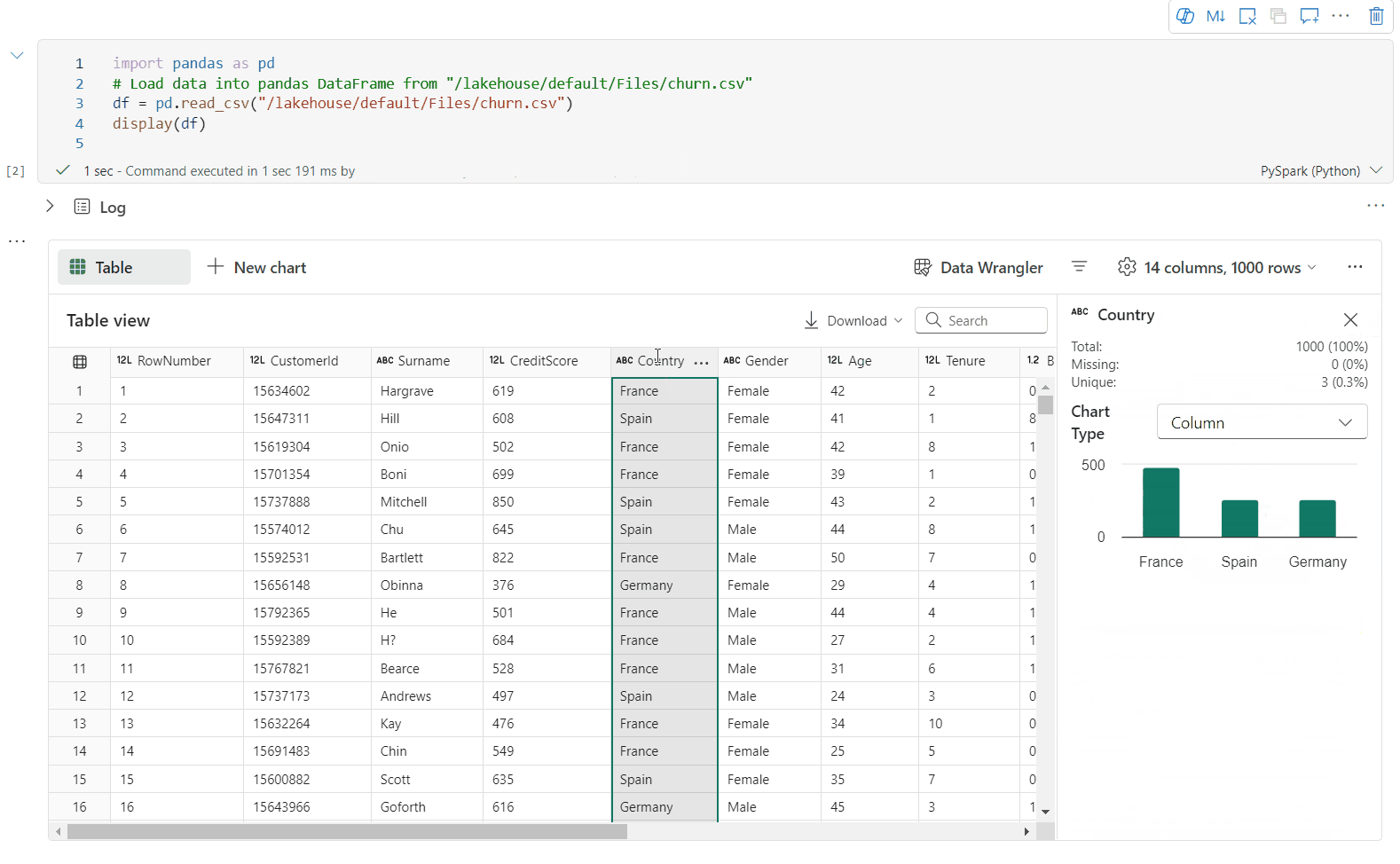
Du kan profilere din dataramme ved at klikke på knappen Undersøg . Den indeholder den opsummerede datadistribution og viser statistikker for hver kolonne.
Hvert kort i sideruden "Undersøg" knyttes til en kolonne i datarammen. Du kan få vist flere oplysninger ved at klikke på kortet eller vælge en kolonne i tabellen.
Du kan få vist celledetaljerne ved at klikke på cellen i tabellen. Denne funktion er nyttig, når datarammen indeholder lang strengtype af indhold.
Ny avanceret datarammediagramvisning
Bemærk
Funktionen er i øjeblikket en prøveversion.
Den forbedrede diagramvisning er tilgængelig på display() -kommandoen. Det giver en mere intuitiv og effektiv oplevelse til visualisering af dine data ved hjælp af kommandoen display().
Nu kan du tilføje op til fem diagrammer i én display() outputwidget ved at klikke på Nyt diagram, så du nemt kan oprette flere diagrammer baseret på forskellige kolonner og nemt sammenligne diagrammer.
Du kan få en liste over diagramanbefalinger baseret på måldatarammen, når du opretter nye diagrammer. Du kan vælge at redigere et anbefalet diagram eller oprette dit eget diagram fra bunden.
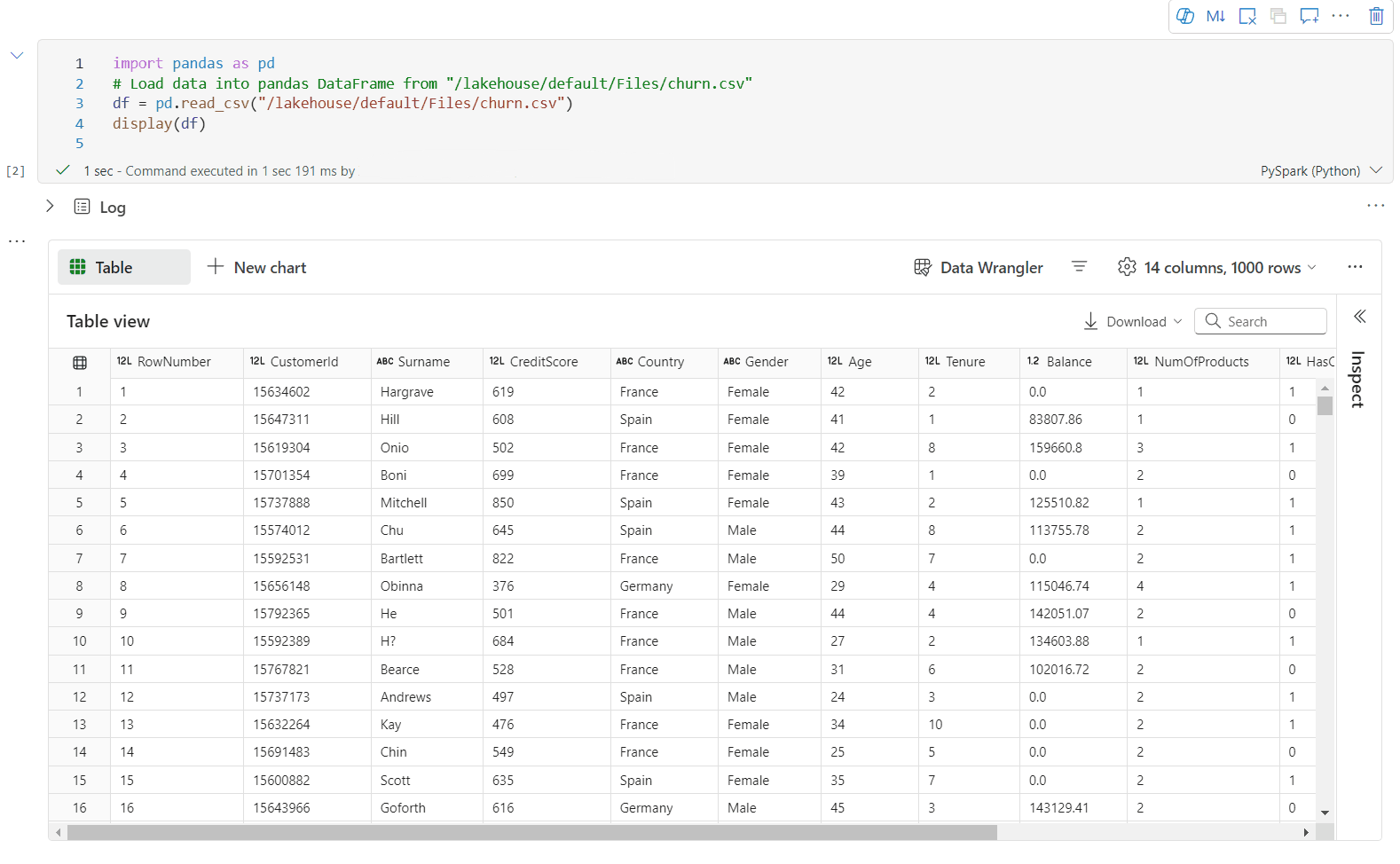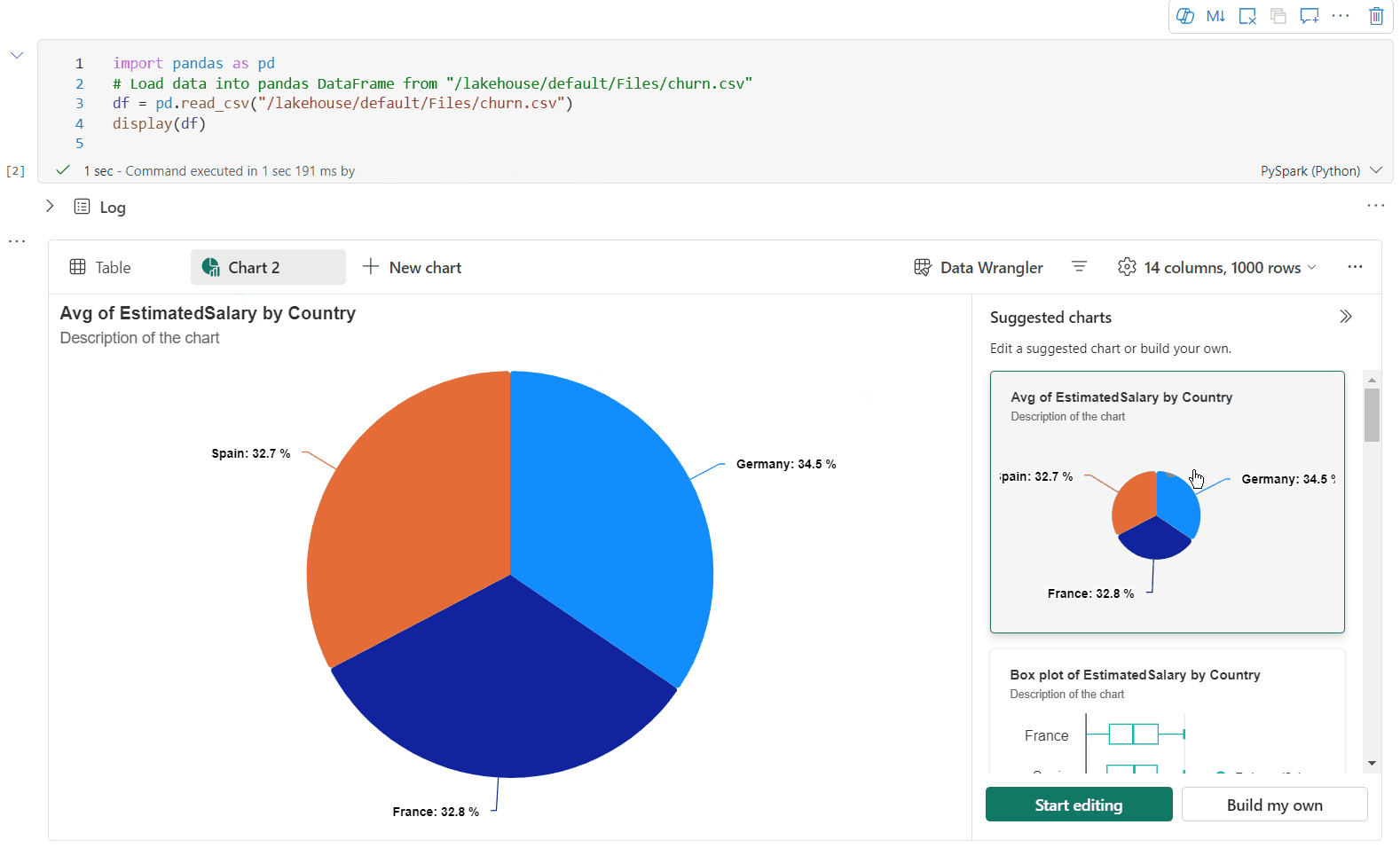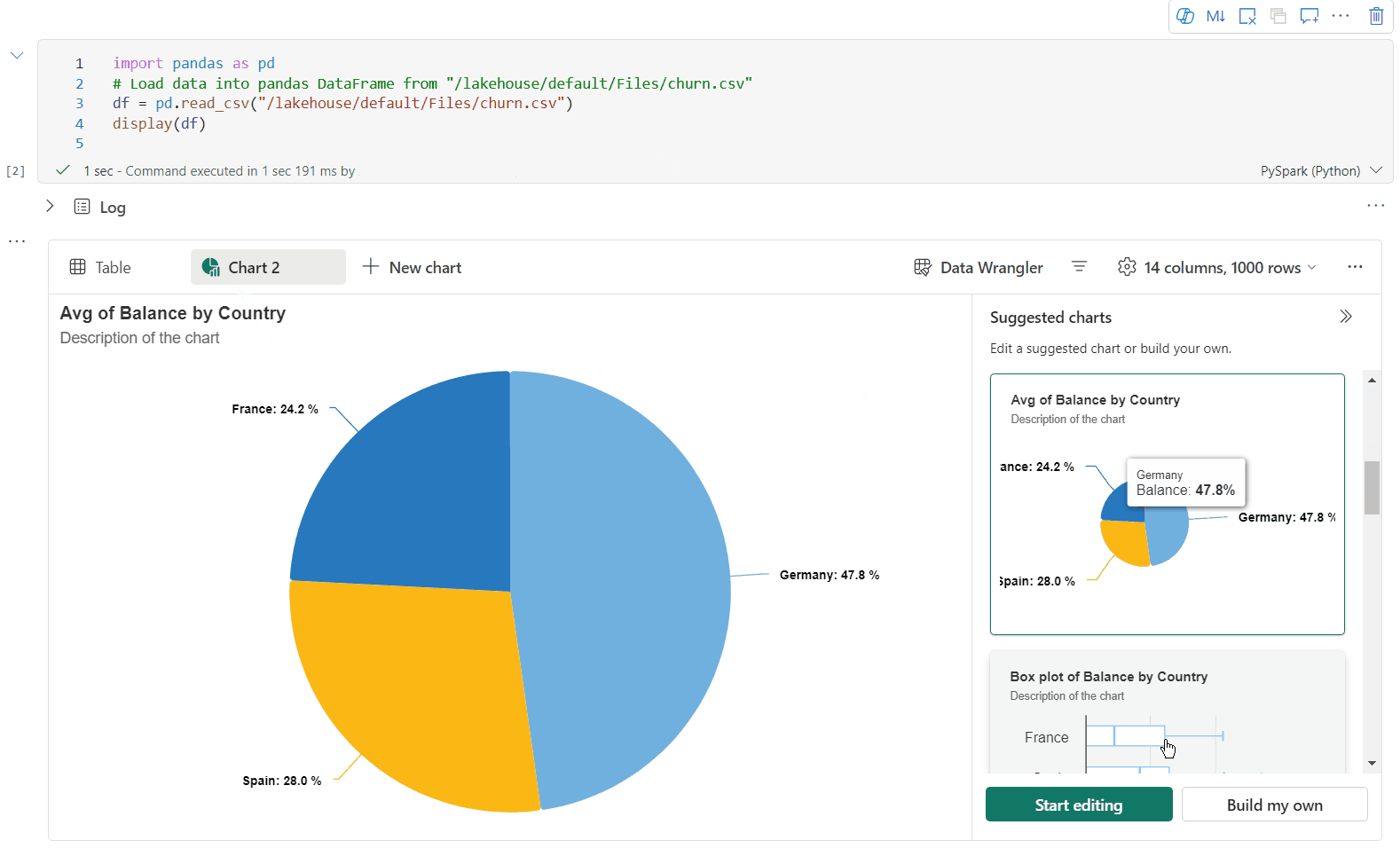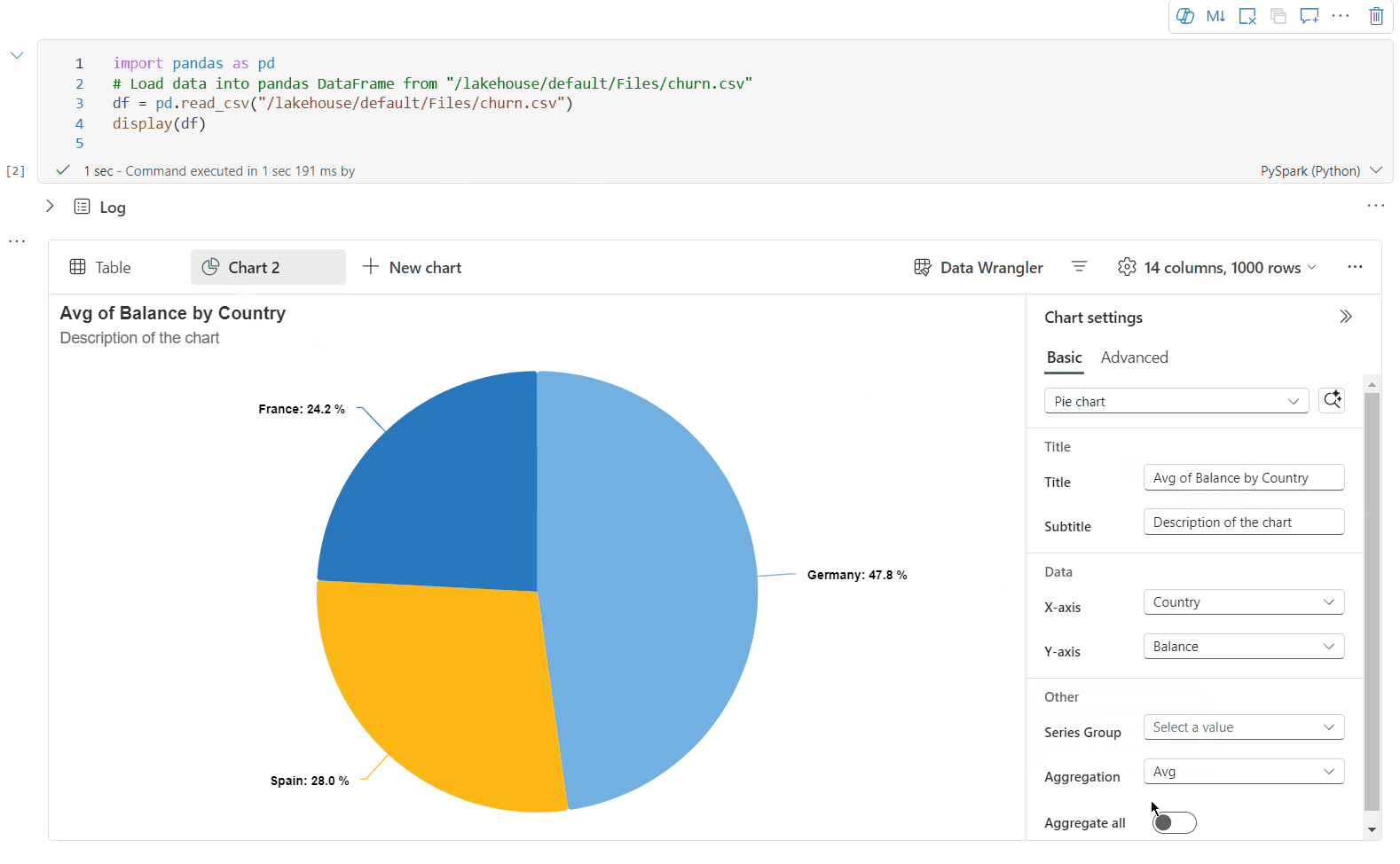
Du kan nu tilpasse din visualisering ved at angive følgende indstillinger. Indstillingsindstillingerne kan blive ændret i henhold til den valgte diagramtype:
Kategori Grundlæggende indstillinger Beskrivelse Diagramtype Visningsfunktionen understøtter en lang række diagramtyper, herunder liggende søjlediagrammer, punktdiagrammer, kurvediagrammer, pivottabeller med mere. Titel Titel Diagrammets titel. Titel Undertekst Undertitlen på diagrammet med flere beskrivelser. Data X-akse Angiv diagrammets nøgle. Data Y-akse Angiv værdierne i diagrammet. Forklaring Vis forklaring Aktivér/deaktiver forklaringen. Forklaring Position Tilpas placeringen af forklaringen. Andet Seriegruppe Brug denne konfiguration til at bestemme grupperne for sammenlægningen. Andet Aggregering Brug denne metode til at aggregere data i din visualisering. Andet Stablet Konfigurer visningstypografien for resultatet. Bemærk
Funktionen display(df) bruger som standard kun de første 1.000 rækker af dataene til at gengive diagrammerne. Vælg Sammenlægning over alle resultater , og vælg derefter Anvend for at anvende diagramoprettelsen fra hele datarammen. Et Spark-job udløses, når diagramindstillingen ændres. Det kan tage flere minutter at fuldføre beregningen og gengive diagrammet.
Kategori Avancerede indstillinger Beskrivelse Color Tema Definer diagrammets temafarvesæt. X-akse Mærkat Angiv en etiket til X-aksen. X-akse Omfang Angiv skalafunktionen for X-aksen. X-akse Range Angiv værdiområdet X-aksen. Y-akse Mærkat Angiv en etiket til Y-aksen. Y-akse Omfang Angiv skalafunktionen for Y-aksen. Y-akse Range Angiv Y-aksen for værdiområdet. Skærm Vis navne Vis/skjul resultatnavnene i diagrammet. Ændringerne af konfigurationer træder i kraft med det samme, og alle konfigurationerne gemmes automatisk i notesbogens indhold.

Du kan nemt omdøbe, duplikere eller slette diagrammer i menuen diagramfane.
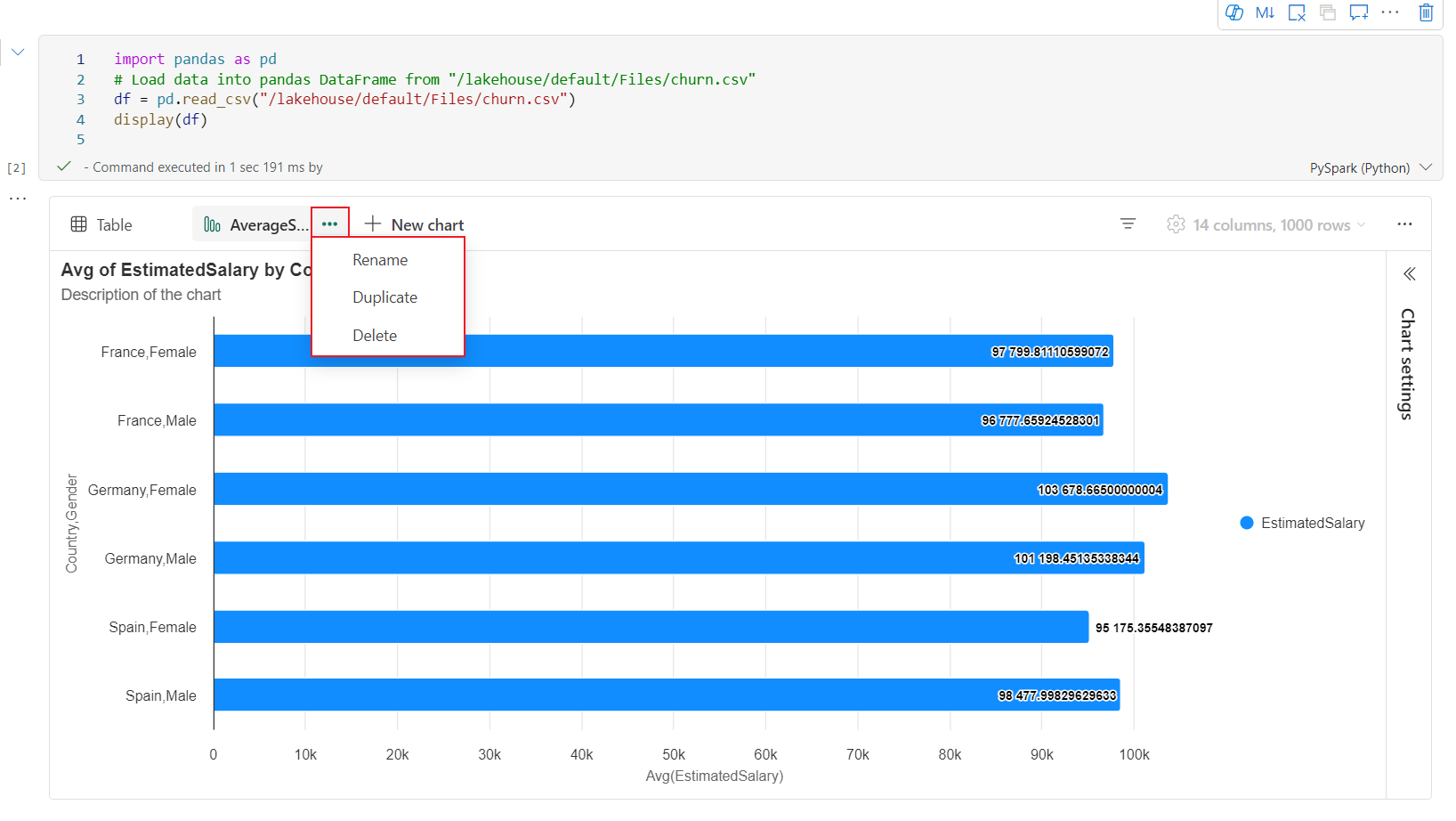
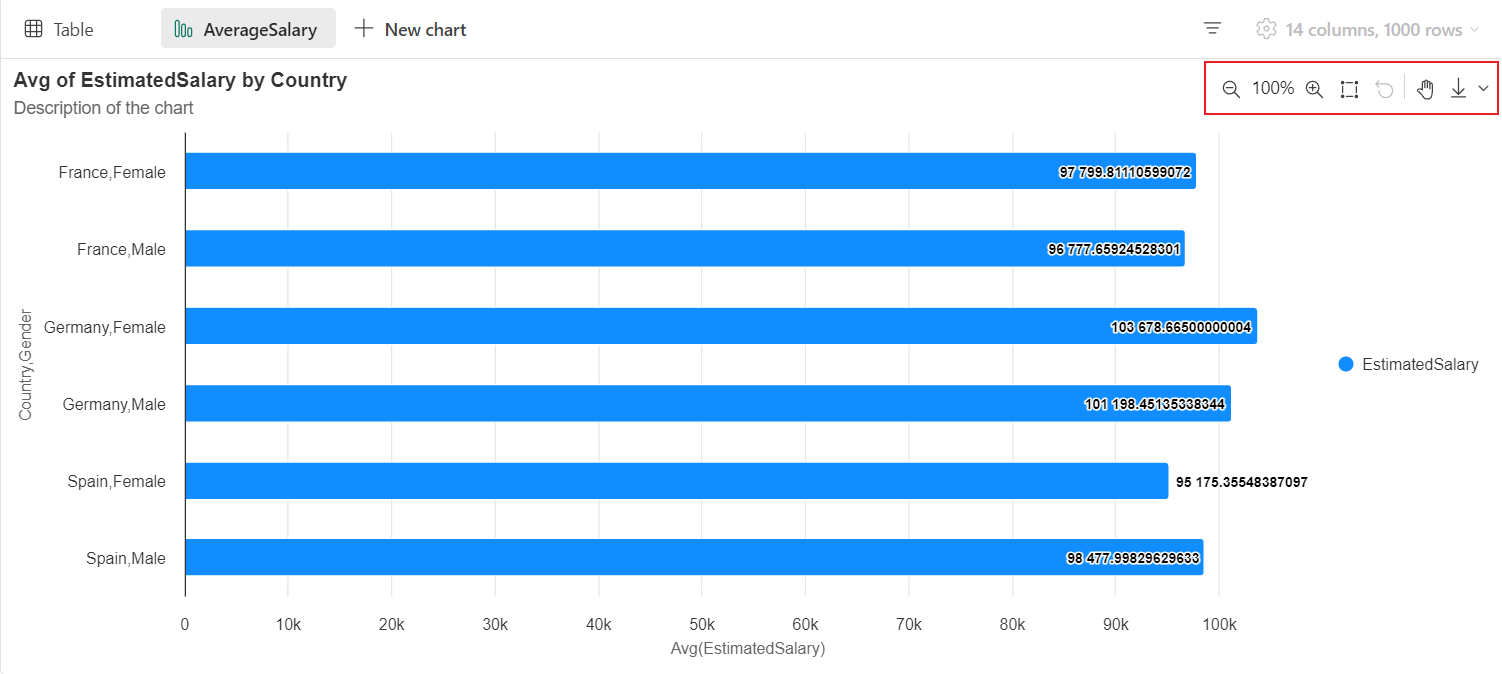
Der er en interaktiv værktøjslinje tilgængelig i den nye diagramoplevelse, når brugeren holder markøren over et diagram. Understøttelseshandlinger som zoom ind, zoom ud, vælg at zoome, nulstille, panorere osv.



Ældre diagramvisning
Bemærk
Den ældre diagramvisning frarådes, når den nye diagramvisning er færdig med prøveversionen.
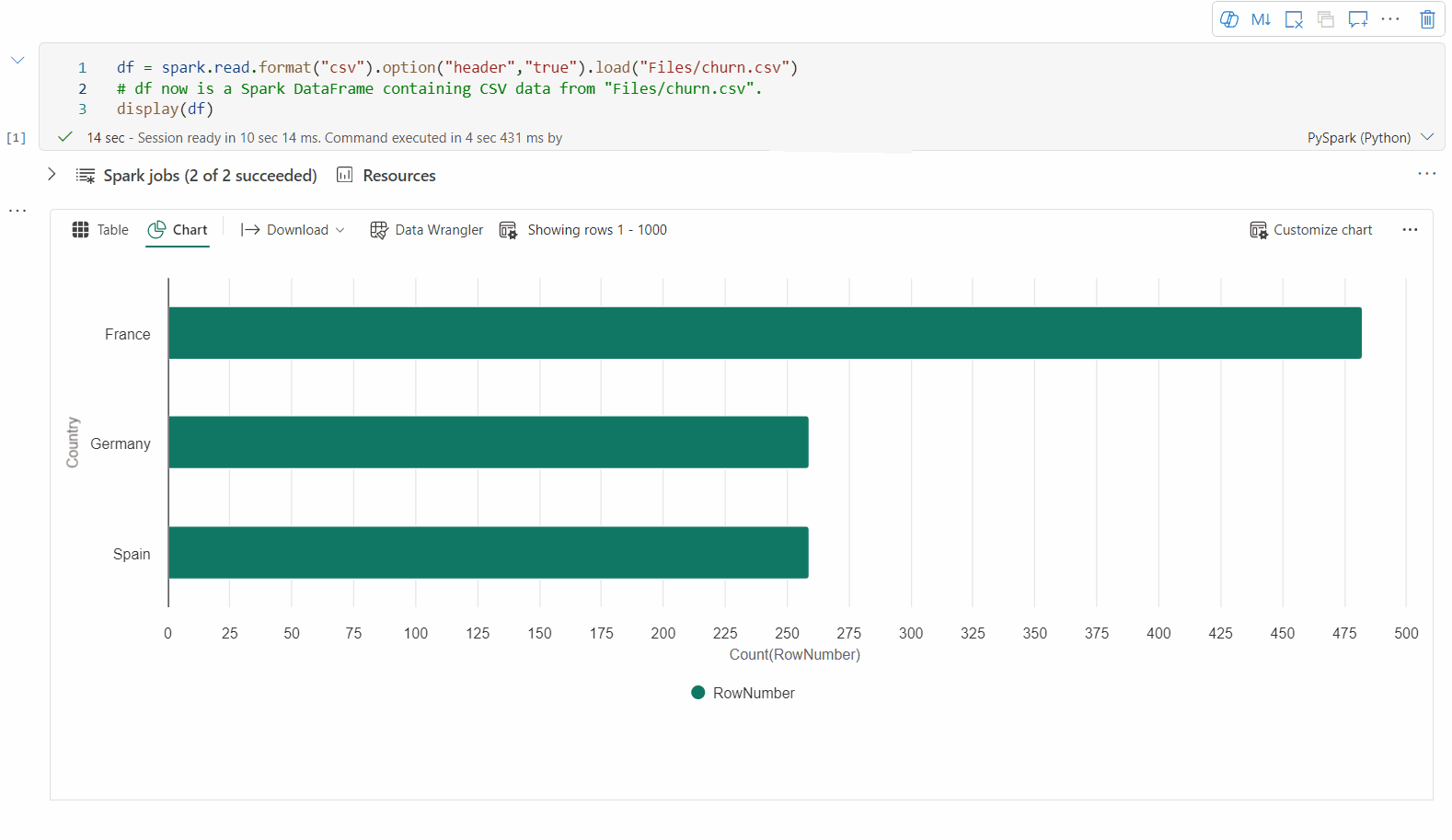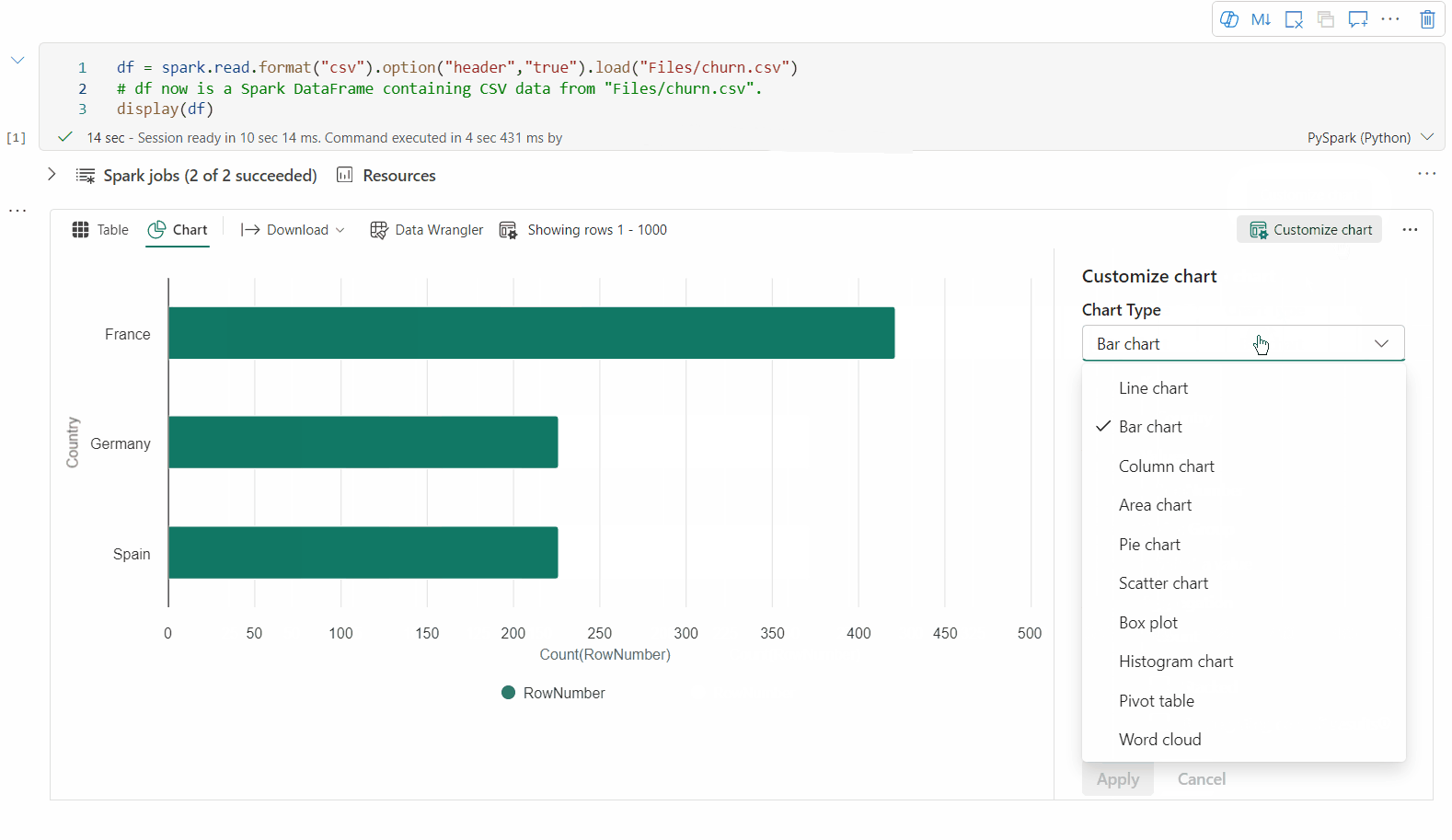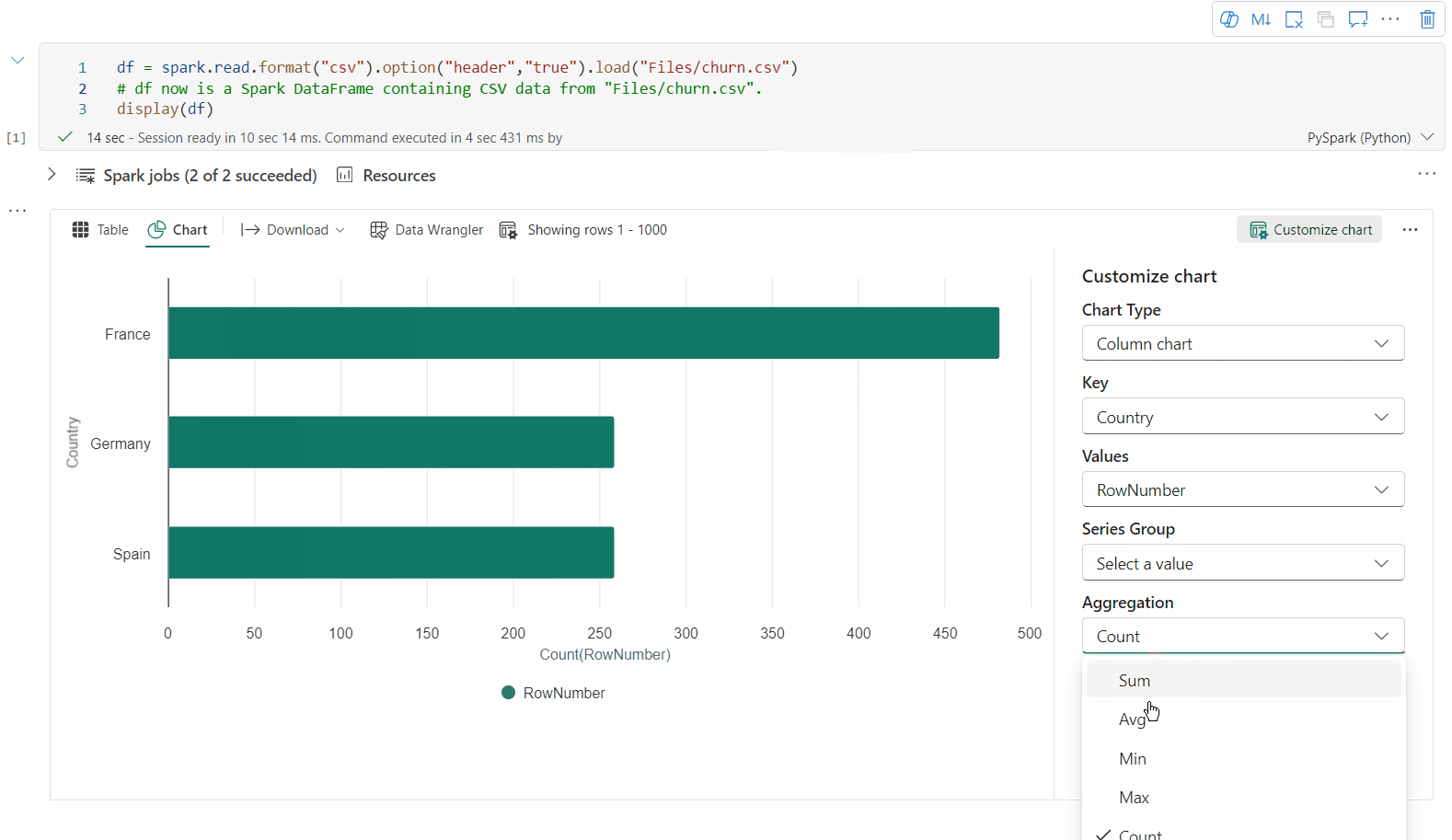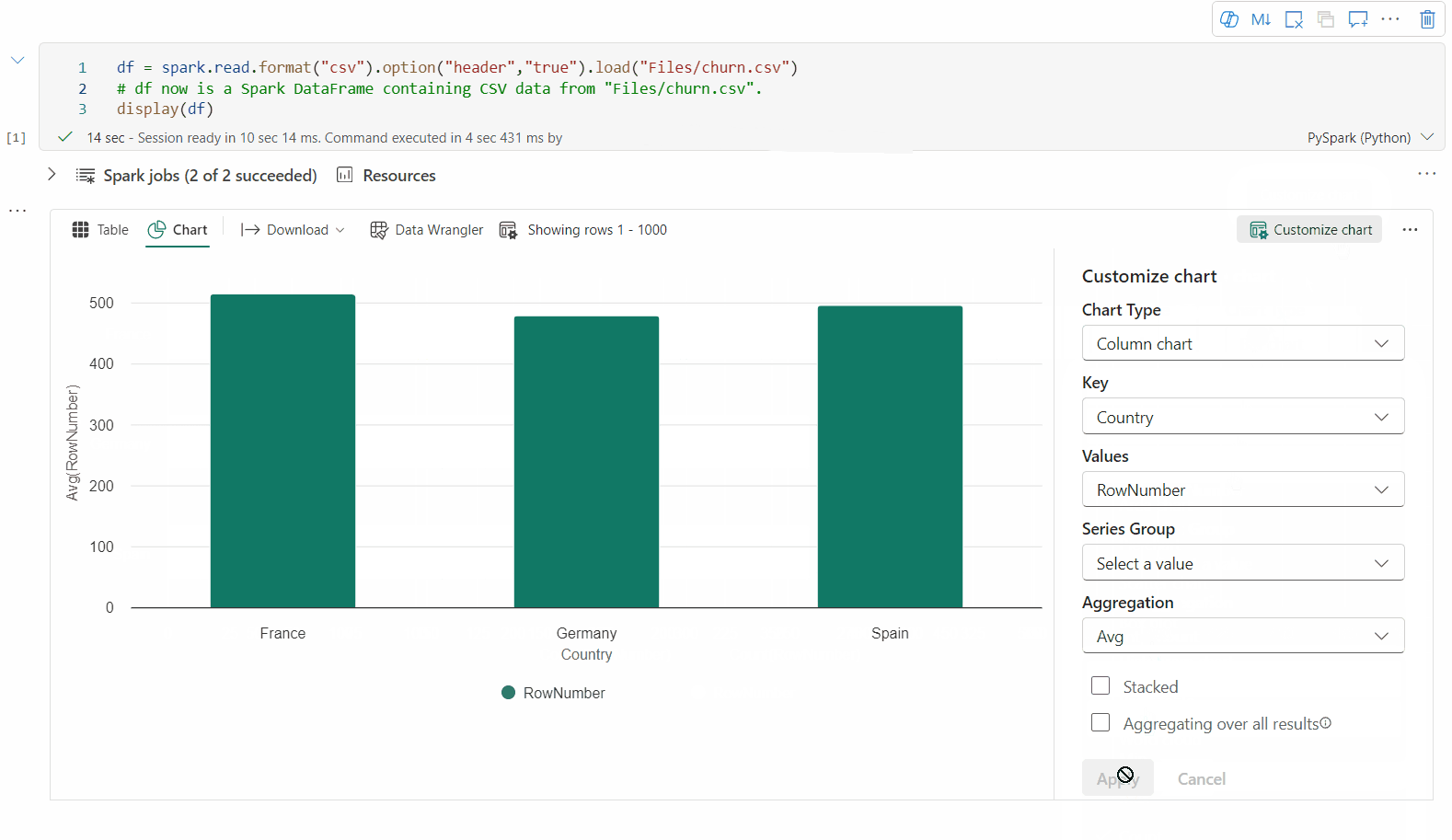
Du kan skifte tilbage til den ældre diagramvisning ved at slå "Ny visualisering" fra. Den nye oplevelse er aktiveret som standard.
Når du har en gengivet tabelvisning, skal du skifte til diagramvisningen .
Notesbogen Fabric anbefaler automatisk diagrammer, der er baseret på måldatarammen, for at gøre diagrammet meningsfuldt med dataindsigt.
Du kan nu tilpasse din visualisering ved at angive følgende værdier:
Konfiguration Beskrivelse Diagramtype Visningsfunktionen understøtter en lang række diagramtyper, herunder liggende søjlediagrammer, punktdiagrammer, kurvediagrammer med mere. Nøgle Angiv værdiområdet for x-aksen. Værdi Angiv værdiområdet for værdierne på y-aksen. Seriegruppe Brug denne konfiguration til at bestemme grupperne for sammenlægningen. Aggregering Brug denne metode til at aggregere data i din visualisering. Konfigurationerne gemmes automatisk i outputindholdet i notesbogen.
Bemærk
Funktionen display(df) tager som standard kun de første 1.000 rækker af dataene for at gengive diagrammerne. Vælg Sammenlægning over alle resultater , og vælg derefter Anvend for at anvende diagramoprettelsen fra hele datarammen. Et Spark-job udløses, når diagramindstillingen ændres. Det kan tage flere minutter at fuldføre beregningen og gengive diagrammet.
Når jobbet er fuldført, kan du få vist og interagere med din endelige visualisering.

display() oversigtsvisning
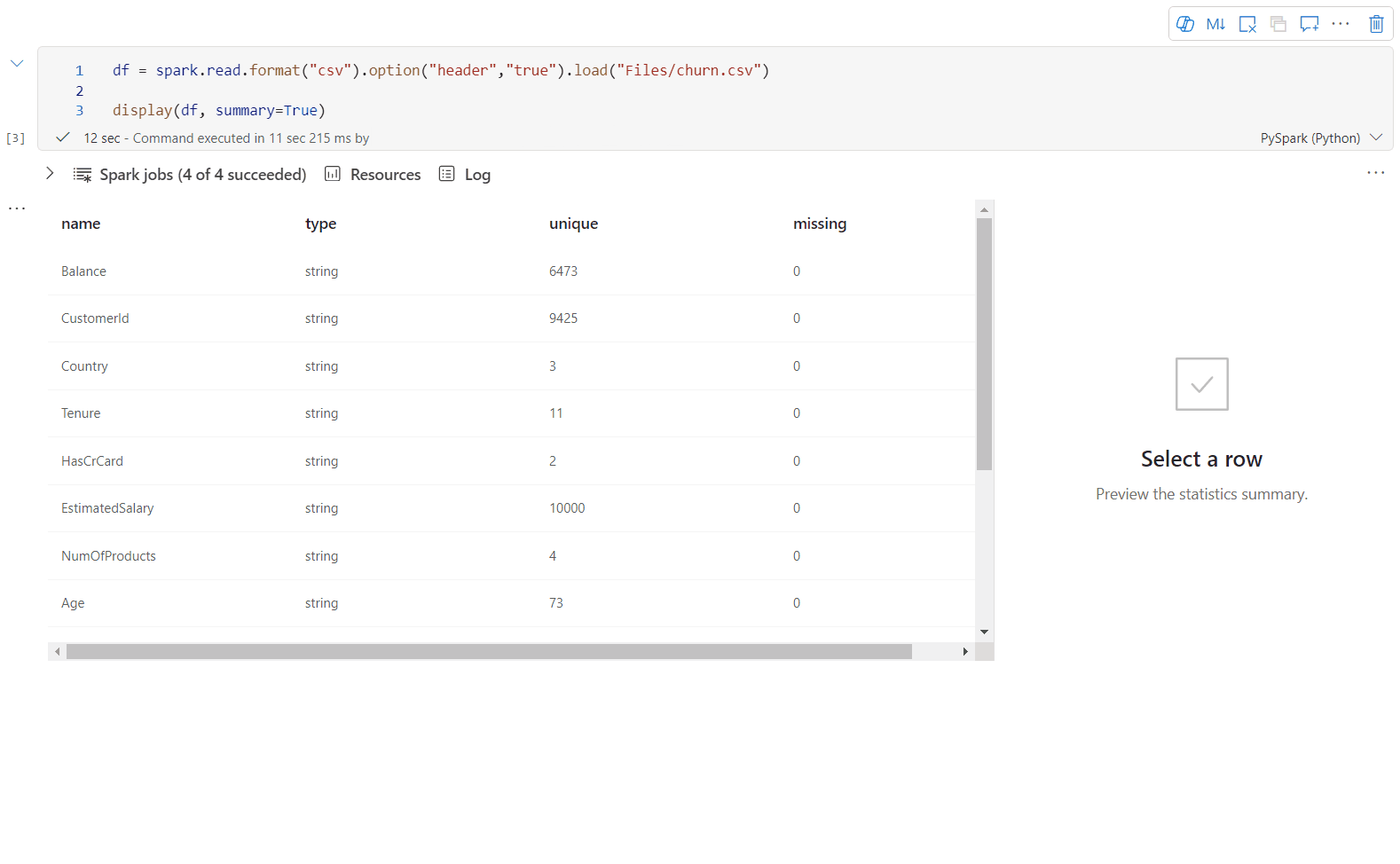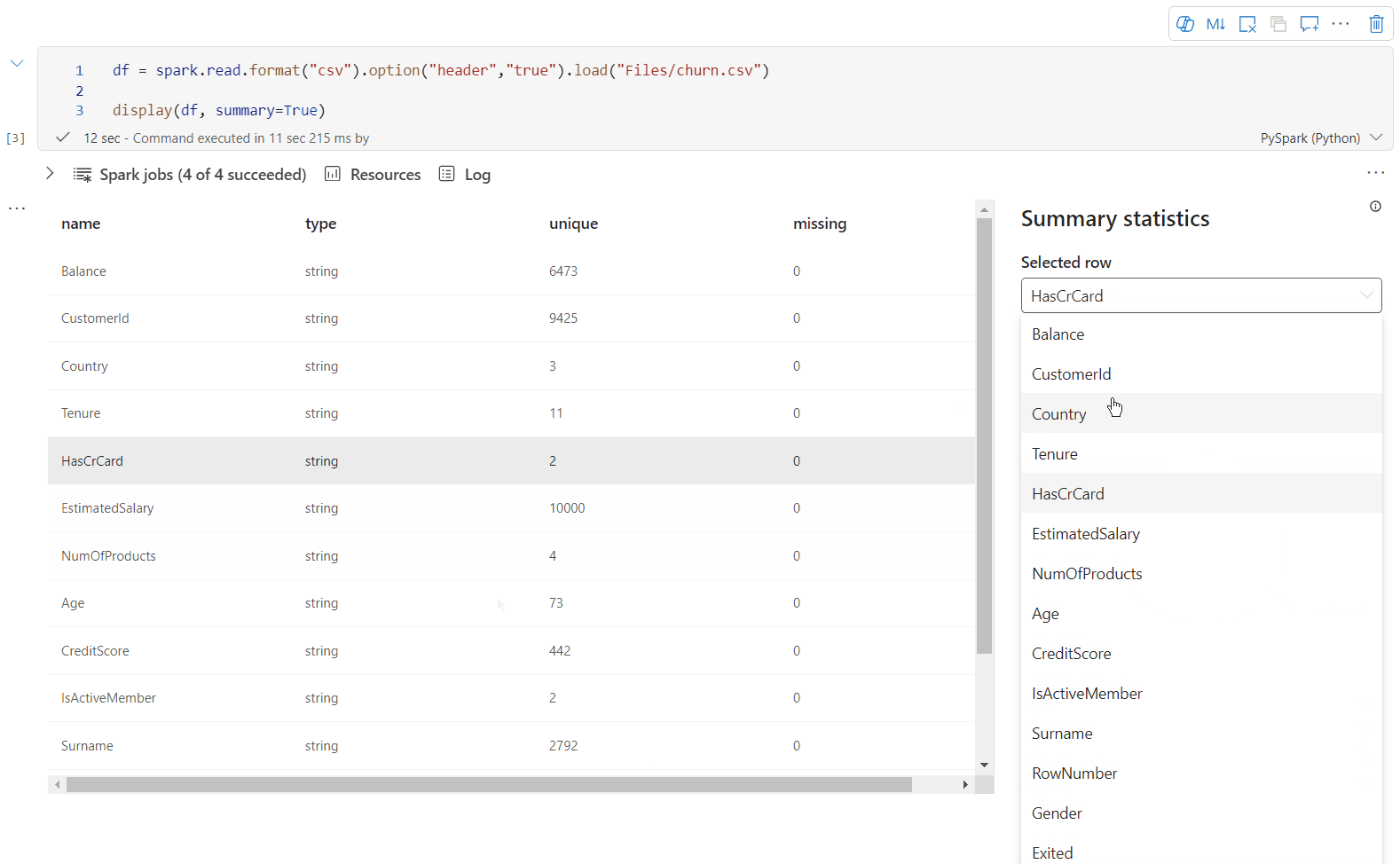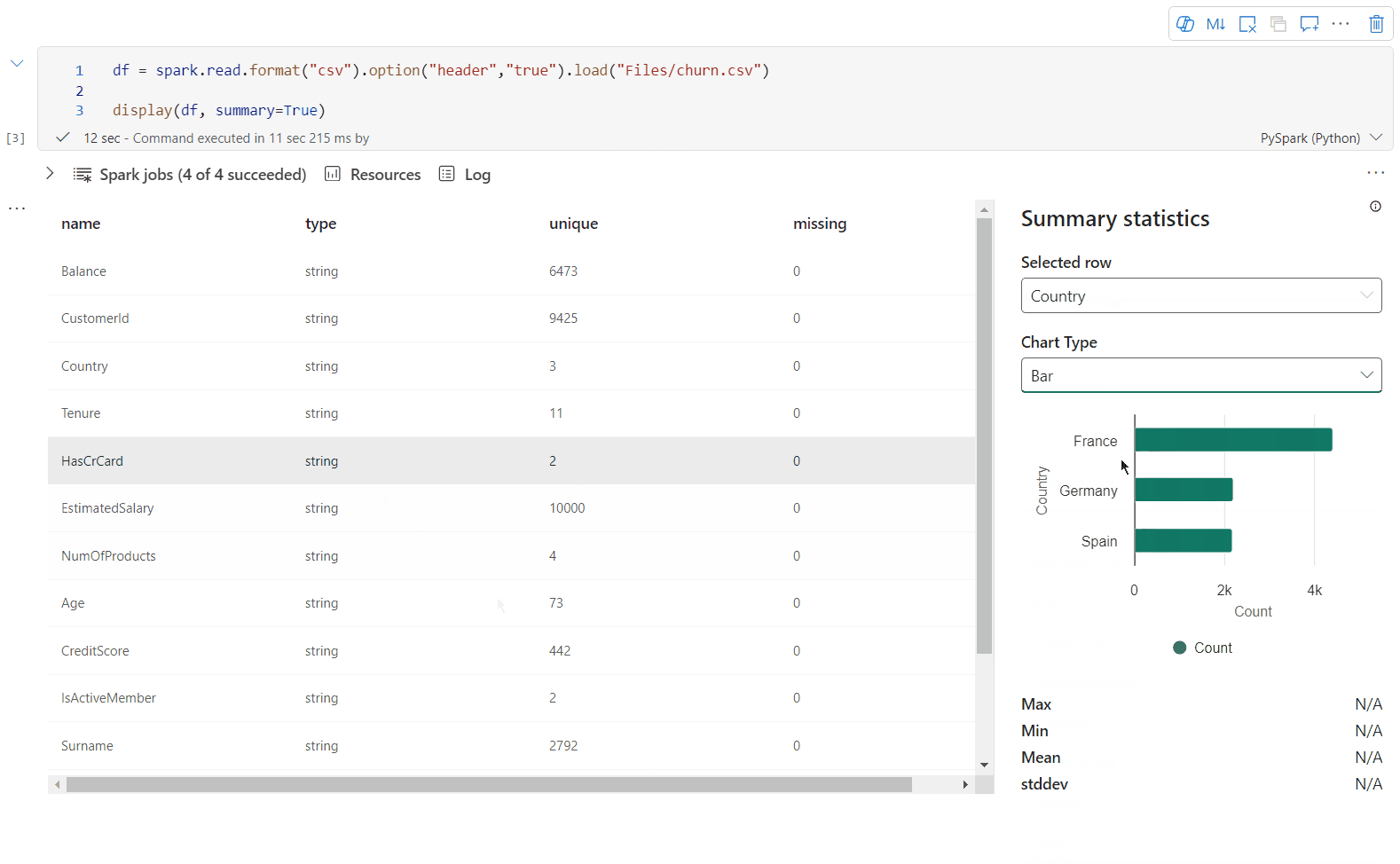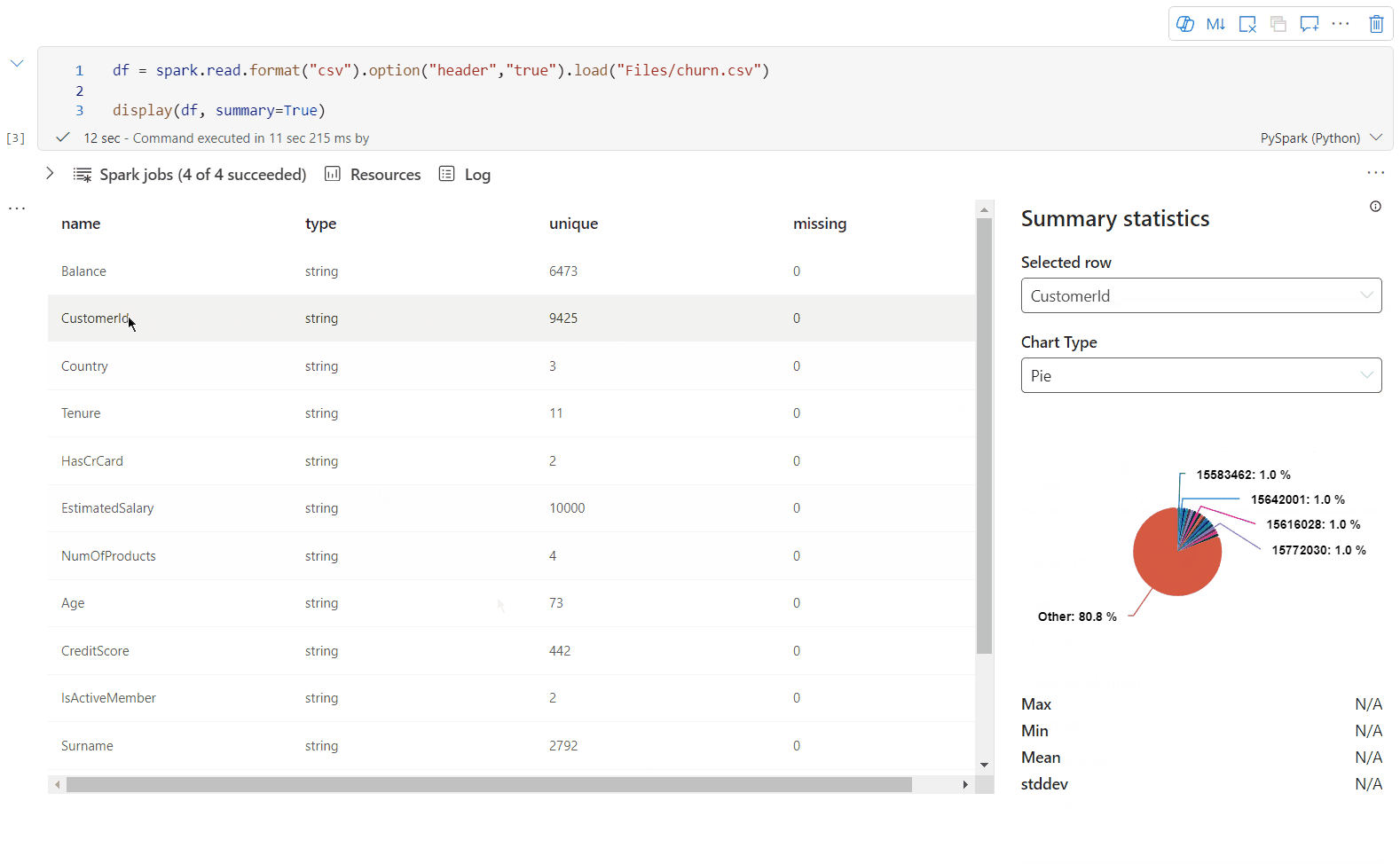
Brug display(df, summary = true) til at kontrollere statistikoversigten for en given Apache Spark DataFrame. Oversigten indeholder kolonnenavnet, kolonnetypen, entydige værdier og manglende værdier for hver kolonne. Du kan også vælge en bestemt kolonne for at se dens minimumværdi, maksimumværdi, middelværdi og standardafvigelse.
indstillingen displayHTML()
Fabric-notesbøger understøtter HTML-grafik ved hjælp af funktionen displayHTML .
Følgende billede er et eksempel på oprettelse af visualiseringer ved hjælp af D3.js.

Kør følgende kode for at oprette denne visualisering.
displayHTML("""<!DOCTYPE html>
<meta charset="utf-8">
<!-- Load d3.js -->
<script src="https://d3js.org/d3.v4.js"></script>
<!-- Create a div where the graph will take place -->
<div id="my_dataviz"></div>
<script>
// set the dimensions and margins of the graph
var margin = {top: 10, right: 30, bottom: 30, left: 40},
width = 400 - margin.left - margin.right,
height = 400 - margin.top - margin.bottom;
// append the svg object to the body of the page
var svg = d3.select("#my_dataviz")
.append("svg")
.attr("width", width + margin.left + margin.right)
.attr("height", height + margin.top + margin.bottom)
.append("g")
.attr("transform",
"translate(" + margin.left + "," + margin.top + ")");
// Create Data
var data = [12,19,11,13,12,22,13,4,15,16,18,19,20,12,11,9]
// Compute summary statistics used for the box:
var data_sorted = data.sort(d3.ascending)
var q1 = d3.quantile(data_sorted, .25)
var median = d3.quantile(data_sorted, .5)
var q3 = d3.quantile(data_sorted, .75)
var interQuantileRange = q3 - q1
var min = q1 - 1.5 * interQuantileRange
var max = q1 + 1.5 * interQuantileRange
// Show the Y scale
var y = d3.scaleLinear()
.domain([0,24])
.range([height, 0]);
svg.call(d3.axisLeft(y))
// a few features for the box
var center = 200
var width = 100
// Show the main vertical line
svg
.append("line")
.attr("x1", center)
.attr("x2", center)
.attr("y1", y(min) )
.attr("y2", y(max) )
.attr("stroke", "black")
// Show the box
svg
.append("rect")
.attr("x", center - width/2)
.attr("y", y(q3) )
.attr("height", (y(q1)-y(q3)) )
.attr("width", width )
.attr("stroke", "black")
.style("fill", "#69b3a2")
// show median, min and max horizontal lines
svg
.selectAll("toto")
.data([min, median, max])
.enter()
.append("line")
.attr("x1", center-width/2)
.attr("x2", center+width/2)
.attr("y1", function(d){ return(y(d))} )
.attr("y2", function(d){ return(y(d))} )
.attr("stroke", "black")
</script>
"""
)
Integrer en Power BI-rapport i en notesbog
Vigtigt
Denne funktion findes i øjeblikket i PRØVEVERSION. Disse oplysninger relaterer til et foreløbig produkt, der kan blive ændret væsentligt, før det nåede Generelt tilgængeligt. Microsoft giver ingen garantier, udtrykt eller stiltiende, med hensyn til de oplysninger, der er angivet her.
Powerbiclient Python-pakken understøttes nu oprindeligt i Fabric-notesbøger. Du behøver ikke at foretage nogen ekstra konfiguration (f.eks. godkendelsesproces) på Spark runtime 3.4 for Fabric-notesbogen. Du skal blot importere powerbiclient og derefter fortsætte din udforskning. Du kan få mere at vide om, hvordan du bruger powerbiclient-pakken, i dokumentationen til powerbiclient.
Powerbiclient understøtter følgende vigtige funktioner.
Gengiv en eksisterende Power BI-rapport
Du kan nemt integrere og interagere med Power BI-rapporter i dine notesbøger med blot nogle få kodelinjer.
Følgende billede er et eksempel på gengivelse af eksisterende Power BI-rapport.

Kør følgende kode for at gengive en eksisterende Power BI-rapport.
from powerbiclient import Report
report_id="Your report id"
report = Report(group_id=None, report_id=report_id)
report
Opret rapportvisualiseringer fra en Spark DataFrame
Du kan bruge en Spark DataFrame i din notesbog til hurtigt at generere indsigtsfulde visualiseringer. Du kan også vælge Gem i den integrerede rapport for at oprette et rapportelement i et destinationsarbejdsområde.
Følgende billede er et eksempel på en QuickVisualize() fra en Spark DataFrame.

Kør følgende kode for at gengive en rapport fra en Spark DataFrame.
# Create a spark dataframe from a Lakehouse parquet table
sdf = spark.sql("SELECT * FROM testlakehouse.table LIMIT 1000")
# Create a Power BI report object from spark data frame
from powerbiclient import QuickVisualize, get_dataset_config
PBI_visualize = QuickVisualize(get_dataset_config(sdf))
# Render new report
PBI_visualize
Opret rapportvisualiseringer fra en pandas DataFrame
Du kan også oprette rapporter baseret på en pandas DataFrame i notesbogen.
Følgende billede er et eksempel på en QuickVisualize() fra en pandas DataFrame.

Kør følgende kode for at gengive en rapport fra en Spark DataFrame.
import pandas as pd
# Create a pandas dataframe from a URL
df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/fips-unemp-16.csv")
# Create a pandas dataframe from a Lakehouse csv file
from powerbiclient import QuickVisualize, get_dataset_config
# Create a Power BI report object from your data
PBI_visualize = QuickVisualize(get_dataset_config(df))
# Render new report
PBI_visualize
Populære biblioteker
Når det kommer til datavisualisering, tilbyder Python flere grafbiblioteker, der er pakket med mange forskellige funktioner. Hver Apache Spark-pool i Fabric indeholder som standard et sæt organiserede og populære biblioteker med åben kildekode.
Matplotlib
Du kan gengive standardafbildningsbiblioteker, f.eks. Matplotlib, ved hjælp af de indbyggede gengivelsesfunktioner for hvert bibliotek.
Følgende billede er et eksempel på oprettelse af et liggende søjlediagram ved hjælp af Matplotlib.


Kør følgende eksempelkode for at tegne dette liggende søjlediagram.
# Bar chart
import matplotlib.pyplot as plt
x1 = [1, 3, 4, 5, 6, 7, 9]
y1 = [4, 7, 2, 4, 7, 8, 3]
x2 = [2, 4, 6, 8, 10]
y2 = [5, 6, 2, 6, 2]
plt.bar(x1, y1, label="Blue Bar", color='b')
plt.bar(x2, y2, label="Green Bar", color='g')
plt.plot()
plt.xlabel("bar number")
plt.ylabel("bar height")
plt.title("Bar Chart Example")
plt.legend()
plt.show()
Bokeh
Du kan gengive HTML- eller interaktive biblioteker, f.eks . bokeh, ved hjælp af displayHTML(df).
Følgende billede er et eksempel på afbildning af glyffer over et kort ved hjælp af bokeh.

Hvis du vil tegne dette billede, skal du køre følgende eksempelkode.
from bokeh.plotting import figure, output_file
from bokeh.tile_providers import get_provider, Vendors
from bokeh.embed import file_html
from bokeh.resources import CDN
from bokeh.models import ColumnDataSource
tile_provider = get_provider(Vendors.CARTODBPOSITRON)
# range bounds supplied in web mercator coordinates
p = figure(x_range=(-9000000,-8000000), y_range=(4000000,5000000),
x_axis_type="mercator", y_axis_type="mercator")
p.add_tile(tile_provider)
# plot datapoints on the map
source = ColumnDataSource(
data=dict(x=[ -8800000, -8500000 , -8800000],
y=[4200000, 4500000, 4900000])
)
p.circle(x="x", y="y", size=15, fill_color="blue", fill_alpha=0.8, source=source)
# create an html document that embeds the Bokeh plot
html = file_html(p, CDN, "my plot1")
# display this html
displayHTML(html)
Plotly
Du kan gengive HTML- eller interaktive biblioteker, f.eks . Plotly, ved hjælp af displayHTML().
Hvis du vil tegne dette billede, skal du køre følgende eksempelkode.

from urllib.request import urlopen
import json
with urlopen('https://raw.githubusercontent.com/plotly/datasets/master/geojson-counties-fips.json') as response:
counties = json.load(response)
import pandas as pd
df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/fips-unemp-16.csv",
dtype={"fips": str})
import plotly
import plotly.express as px
fig = px.choropleth(df, geojson=counties, locations='fips', color='unemp',
color_continuous_scale="Viridis",
range_color=(0, 12),
scope="usa",
labels={'unemp':'unemployment rate'}
)
fig.update_layout(margin={"r":0,"t":0,"l":0,"b":0})
# create an html document that embeds the Plotly plot
h = plotly.offline.plot(fig, output_type='div')
# display this html
displayHTML(h)
Pandaer
Du kan få vist HTML-output fra pandas DataFrames som standardoutput. Fabric-notesbøger viser automatisk det formaterede HTML-indhold.

import pandas as pd
import numpy as np
df = pd.DataFrame([[38.0, 2.0, 18.0, 22.0, 21, np.nan],[19, 439, 6, 452, 226,232]],
index=pd.Index(['Tumour (Positive)', 'Non-Tumour (Negative)'], name='Actual Label:'),
columns=pd.MultiIndex.from_product([['Decision Tree', 'Regression', 'Random'],['Tumour', 'Non-Tumour']], names=['Model:', 'Predicted:']))
df