Oprindeligt udførelsesprogram til Fabric Spark
Det oprindelige udførelsesprogram er en banebrydende forbedring af Apache Spark-jobudførelser i Microsoft Fabric. Dette vektoriserede program optimerer ydeevnen og effektiviteten af dine Spark-forespørgsler ved at køre dem direkte på din lakehouse-infrastruktur. Programmets problemfrie integration betyder, at det ikke kræver nogen kodeændringer og undgår leverandørlåsning. Den understøtter Apache Spark-API'er og er kompatibel med Runtime 1.3 (Apache Spark 3.5) og fungerer med både parquet- og Delta-formater. Uanset dine datas placering i OneLake, eller hvis du får adgang til data via genveje, maksimerer det oprindelige udførelsesprogram effektiviteten og ydeevnen.
Det oprindelige udførelsesprogram hæver forespørgslens ydeevne betydeligt, samtidig med at driftsomkostningerne minimeres. Det leverer en bemærkelsesværdig hastighedsforbedring, der giver op til fire gange hurtigere ydeevne sammenlignet med traditionelle OSS (open source software) Spark, som valideret af TPC-DS 1 TB benchmark. Programmet er velegnet til at administrere en lang række databehandlingsscenarier, lige fra rutinemæssig dataindtagelse, batchjob og ETL-opgaver (udtræk, transformér, indlæs) til komplekse datavidenskabsanalyser og dynamiske interaktive forespørgsler. Brugerne drager fordel af accelererede behandlingstider, øget gennemløb og optimeret ressourceudnyttelse.
Det oprindelige eksekveringsprogram er baseret på to vigtige OSS-komponenter: Velox, et C++-databaseaccelerationsbibliotek, der blev introduceret af Meta, og Apache Gluten (inkubation), som er et mellemlag, der er ansvarligt for at aflaste JVM-baserede SQL-motorers udførelse til oprindelige programmer, der introduceres af Intel.
Bemærk
Det oprindelige udførelsesprogram er i øjeblikket i offentlig prøveversion. Du kan få flere oplysninger under de aktuelle begrænsninger. Vi opfordrer dig til at aktivere det oprindelige udførelsesprogram på dine arbejdsbelastninger uden yderligere omkostninger. Du får fordel af hurtigere jobudførelse uden at betale mere – effektivt betaler du mindre for det samme arbejde.
Hvornår skal du bruge det oprindelige udførelsesprogram?
Det oprindelige udførelsesprogram tilbyder en løsning til kørsel af forespørgsler på store datasæt. Den optimerer ydeevnen ved hjælp af de oprindelige funktioner i underliggende datakilder og minimerer de omkostninger, der typisk er forbundet med dataflytning og serialisering i traditionelle Spark-miljøer. Programmet understøtter forskellige operatorer og datatyper, herunder aggregering af akkumuleringshash, BNLJ (broadcast nested loop join) og præcise tidsstempelformater. Hvis du vil have fuldt udbytte af programmets funktioner, skal du dog overveje dets optimale anvendelsesområder:
- Programmet er effektivt, når der arbejdes med data i formaterne Parquet og Delta, som det kan behandle oprindeligt og effektivt.
- Forespørgsler, der involverer komplicerede transformationer og sammenlægninger, drager stor fordel af funktionen til behandling og vektorisering af kolonnen i programmet.
- Forbedringer af ydeevnen er mest bemærkelsesværdige i scenarier, hvor forespørgslerne ikke udløser reservemekanismen ved at undgå funktioner eller udtryk, der ikke understøttes.
- Programmet er velegnet til forespørgsler, der er beregningstunge i stedet for simple eller I/O-bundne.
Du kan få oplysninger om de operatorer og funktioner, der understøttes af det oprindelige udførelsesprogram, i dokumentationen til Apache Gluten.
Aktivér det oprindelige udførelsesprogram
Hvis du vil bruge de fulde funktioner i det oprindelige udførelsesprogram i prøveversionsfasen, er specifikke konfigurationer nødvendige. Følgende procedurer viser, hvordan du aktiverer denne funktion for notesbøger, Spark-jobdefinitioner og hele miljøer.
Vigtigt
Det oprindelige kørselsprogram understøtter den nyeste version af ga-runtime, som er Runtime 1.3 (Apache Spark 3.5, Delta Lake 3.2). Med udgivelsen af det oprindelige udførelsesprogram i Runtime 1.3 er understøttelsen af den tidligere version – Runtime 1.2 (Apache Spark 3.4, Delta Lake 2.4) ophørt. Vi opfordrer alle kunder til at opgradere til den nyeste Runtime 1.3. Hvis du bruger det oprindelige udførelsesprogram på Runtime 1.2, deaktiveres oprindelig acceleration snart.
Aktivér på miljøniveau
Hvis du vil sikre en ensartet forbedring af ydeevnen, skal du aktivere det oprindelige udførelsesprogram på tværs af alle job og notesbøger, der er knyttet til dit miljø:
Gå til dine miljøindstillinger.
Gå til Spark compute.
Gå til fanen Acceleration .
Markér afkrydsningsfeltet med navnet Aktivér oprindeligt udførelsesprogram.
Gem og publicer ændringerne.
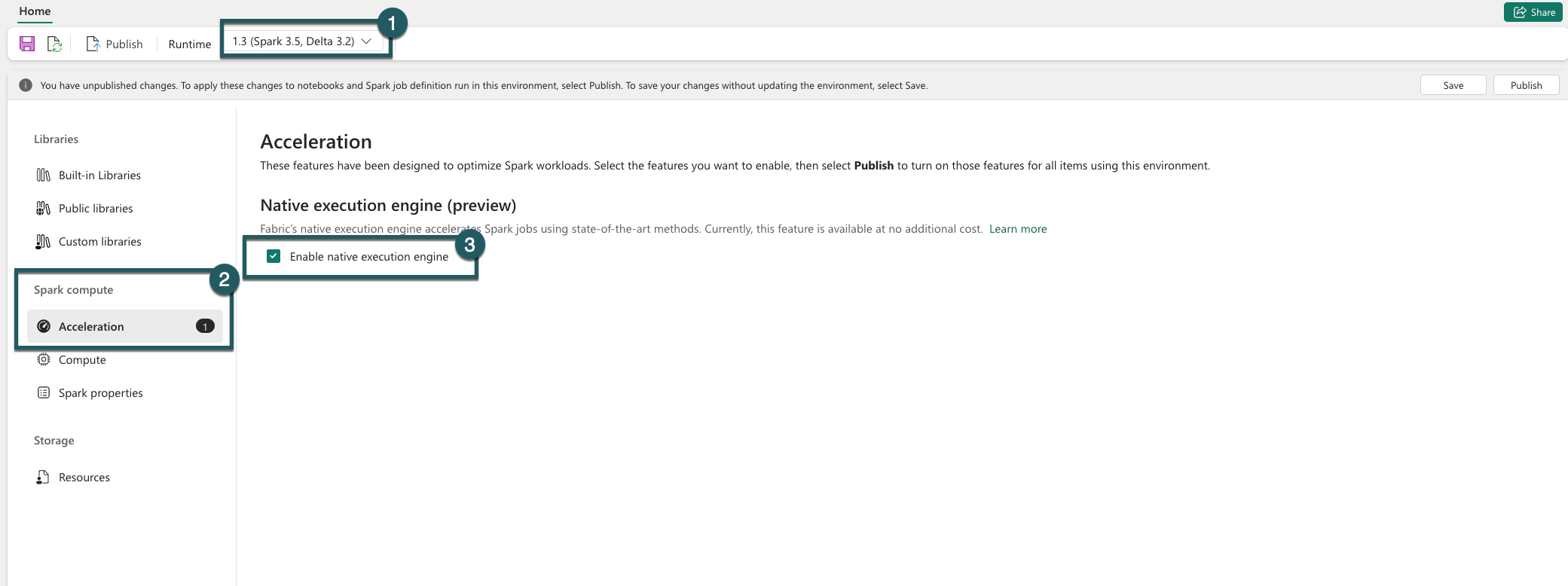

Når indstillingen er aktiveret på miljøniveau, arver alle efterfølgende job og notesbøger indstillingen. Denne nedarvning sikrer, at alle nye sessioner eller ressourcer, der er oprettet i miljøet, automatisk drager fordel af de forbedrede udførelsesfunktioner.
Vigtigt
Tidligere blev det oprindelige udførelsesprogram aktiveret via Spark-indstillinger i miljøkonfigurationen. Med vores seneste opdatering (udrulning i gang) har vi forenklet dette ved at introducere en til/fra-knap under fanen Acceleration under miljøindstillingerne. Genaktiver det oprindelige udførelsesprogram ved hjælp af den nye til/fra-knap – hvis du vil fortsætte med at bruge det oprindelige udførelsesprogram, skal du gå til fanen Acceleration i miljøindstillingerne og aktivere det via til/fra-knappen. Den nye til/fra-indstilling i brugergrænsefladen har nu højere prioritet end alle tidligere Spark-egenskabskonfigurationer. Hvis du tidligere har aktiveret det oprindelige udførelsesprogram via Spark-indstillinger, deaktiveres det, indtil det aktiveres igen via til/fra-knappen for brugergrænsefladen.
Aktivér for en notesbog eller spark-jobdefinition
Hvis du vil aktivere det oprindelige udførelsesprogram for en enkelt notesbog eller spark-jobdefinition, skal du indarbejde de nødvendige konfigurationer i starten af dit udførelsesscript:
%%configure
{
"conf": {
"spark.native.enabled": "true",
}
}
I forbindelse med notesbøger skal du indsætte de påkrævede konfigurationskommandoer i den første celle. I forbindelse med Spark-jobdefinitioner skal du inkludere konfigurationerne i frontlinjen af definitionen af dit Spark-job. Det oprindelige udførelsesprogram er integreret med dynamiske puljer, så når du aktiverer funktionen, træder det i kraft med det samme, uden at du skal starte en ny session.
Vigtigt
Konfigurationen af det oprindelige udførelsesprogram skal udføres, før Spark-sessionen initieres. Når Spark-sessionen starter, spark.shuffle.manager bliver indstillingen uforanderlig og kan ikke ændres. Sørg for, at disse konfigurationer er angivet i %%configure blokken i notesbøger eller i Spark-sessionsgeneratoren til Spark-jobdefinitioner.
Kontrolelement på forespørgselsniveau
Mekanismerne til aktivering af det oprindelige udførelsesprogram på lejer-, arbejdsområde- og miljøniveauerne, der er problemfrit integreret med brugergrænsefladen, er under aktiv udvikling. I mellemtiden kan du deaktivere det oprindelige udførelsesprogram for bestemte forespørgsler, især hvis de involverer operatorer, der ikke understøttes i øjeblikket (se begrænsninger). Hvis du vil deaktivere, skal du angive Spark-konfigurationen spark.native.enabled til false for den specifikke celle, der indeholder din forespørgsel.
%%sql
SET spark.native.enabled=FALSE;

Når du har udført den forespørgsel, hvor det oprindelige udførelsesprogram er deaktiveret, skal du genaktivere det for efterfølgende celler ved at angive spark.native.enabled til true. Dette trin er nødvendigt, fordi Spark udfører kodeceller sekventielt.
%%sql
SET spark.native.enabled=TRUE;
Identificer handlinger udført af programmet
Der er flere metoder til at afgøre, om en operator i dit Apache Spark-job blev behandlet ved hjælp af det oprindelige udførelsesprogram.
Spark UI og Spark-oversigtsserver
Få adgang til Spark-brugergrænsefladen eller Spark-oversigtsserveren for at finde den forespørgsel, du skal undersøge. Hvis du vil have adgang til spark-webbrugergrænsefladen, skal du navigere til din Spark Job Definition og køre den. Vælg

I den forespørgselsplan, der vises i Brugergrænsefladen i Spark, skal du søge efter nodenavne, der slutter med suffikset Transformer, *NativeFileScan eller VeloxColumnarToRowExec. Suffikset angiver, at det oprindelige udførelsesprogram udførte handlingen. Noder kan f.eks. være mærket som RollUpHashAggregateTransformer, ProjectExecTransformer, BroadcastHashJoinExecTransformer, ShuffledHashJoinExecTransformer eller BroadcastNestedLoopJoinExecTransformer.

Forklaring af dataramme
Du kan også udføre kommandoen i notesbogen df.explain() for at få vist udførelsesplanen. I outputtet skal du søge efter de samme Transformer, *NativeFileScan eller VeloxColumnarToRowExec suffikser. Denne metode gør det hurtigt at bekræfte, om bestemte handlinger håndteres af det oprindelige udførelsesprogram.

Reservemekanisme
I nogle tilfælde kan det oprindelige udførelsesprogram muligvis ikke udføre en forespørgsel på grund af årsager som f.eks. funktioner, der ikke understøttes. I disse tilfælde falder operationen tilbage til den traditionelle Spark-motor. Denne automatiske reservemekanisme sikrer, at arbejdsprocessen ikke afbrydes.


Overvåg forespørgsler og dataframes, der udføres af programmet
Hvis du vil have en bedre forståelse af, hvordan det oprindelige udførelsesprogram anvendes på SQL-forespørgsler og DataFrame-handlinger, og hvis du vil analysere ned til fase- og operatorniveauerne, kan du se Spark UI og Spark History Server for at få mere detaljerede oplysninger om den oprindelige programudførelse.
Fanen Oprindeligt udførelsesprogram
Du kan navigere til den nye fane 'Gluten SQL/DataFrame' for at få vist oplysninger om glutenopbygning og detaljer om udførelse af forespørgsler. Tabellen Forespørgsler giver indsigt i antallet af noder, der kører på det oprindelige program, og dem, der falder tilbage til JVM for hver forespørgsel.

Graf over udførelse af forespørgsel
Du kan også vælge i forespørgselsbeskrivelsen for visualiseringen Apache Spark-forespørgselsplan. Udførelsesgrafen indeholder oprindelige udførelsesoplysninger på tværs af faser og deres respektive handlinger. Baggrundsfarver skelner mellem udførelsesprogrammer: grøn repræsenterer det oprindelige eksekveringsprogram, mens lyseblå angiver, at handlingen kører på JVM-standardprogrammet.

Begrænsninger
Selvom det oprindelige udførelsesprogram forbedrer ydeevnen for Apache Spark-job, skal du være opmærksom på de aktuelle begrænsninger.
- Nogle Delta-specifikke handlinger understøttes ikke (men vi arbejder aktivt på det), herunder fletningshandlinger, kontrolpunktscanninger og sletningsvektorer.
- Visse Spark-funktioner og -udtryk er ikke kompatible med det oprindelige udførelsesprogram, f.eks. brugerdefinerede funktioner (UDF'er) og funktionen
array_containssamt struktureret Spark-streaming. Brugen af disse inkompatible handlinger eller funktioner som en del af et importeret bibliotek vil også medføre fallback for Spark-programmet. - Scanninger fra lagerløsninger, der bruger private slutpunkter, understøttes ikke (endnu, da vi aktivt arbejder på det).
- Programmet understøtter ikke ANSI-tilstand, så det søger, og når ANSI-tilstand er aktiveret, falder det automatisk tilbage til vanilla Spark.
Når du bruger datofiltre i forespørgsler, er det vigtigt at sikre, at datatyperne på begge sider af sammenligningen stemmer overens for at undgå problemer med ydeevnen. Uoverensstemmende datatyper medfører muligvis ikke en forøgelse af udførelse af forespørgsler og kan kræve eksplicit casting. Sørg altid for, at datatyperne for venstre side (LHS) og højre side (RHS) i en sammenligning er identiske, da uoverensstemmende typer ikke altid tildeles automatisk. Hvis en typeuoverensstemmelse ikke kan undgås, skal du bruge eksplicit casting til at matche datatyperne, f.eks CAST(order_date AS DATE) = '2024-05-20'. . Forespørgsler med uoverensstemmende datatyper, der kræver casting, fremskyndes ikke af det oprindelige udførelsesprogram, så det er afgørende for at opretholde ydeevnen, at typen er ensartet. I stedet for order_date = '2024-05-20'order_date hvor er DATETIME , og strengen er DATE, skal du f.eks. eksplicit caste order_date for at DATE sikre ensartede datatyper og forbedre ydeevnen.