Opret og administrer Apache Spark-jobdefinitioner i Visual Studio Code
Visual Studio-kodeudvidelsen (VS) til Synapse understøtter fuldt ud CURD-jobdefinitionshandlinger (opret, opdater, læs og slet) Spark-jobdefinitioner i Fabric. Når du har oprettet en Spark-jobdefinition, kan du uploade flere refererede biblioteker, sende en anmodning om at køre Definitionen af Spark-job og kontrollere kørselsoversigten.
Opret en Spark-jobdefinition
Sådan opretter du en ny Spark-jobdefinition:
I VS Code Explorer skal du vælge indstillingen Opret Spark-jobdefinition .

Angiv de indledende obligatoriske felter: navn, refereret lakehouse og standard lakehouse.
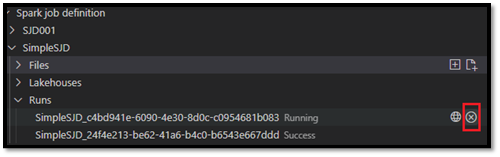
Anmodningsprocesserne og navnet på den nyoprettede Spark-jobdefinition vises under rodnoden Spark Job Definition i VS Code Explorer. Under navnenoden for Spark-jobdefinitionen kan du se tre undernoder:
- Filer: Liste over hoveddefinitionsfilen og andre biblioteker, der refereres til. Du kan uploade nye filer fra denne liste.
- Lakehouse: Liste over alle lakehouses, der henvises til i denne Spark-jobdefinition. Standard lakehouse er markeret på listen, og du kan få adgang til det via den relative sti
Files/…, Tables/…. - Kør: Liste over kørselsoversigten for denne Spark-jobdefinition og jobstatus for hver kørsel.
Overfør en hoveddefinitionsfil til et bibliotek, der refereres til
Hvis du vil overføre eller overskrive hoveddefinitionsfilen, skal du vælge indstillingen Tilføj hovedfil .
Hvis du vil overføre den biblioteksfil, som hoveddefinitionsfilen refererer til, skal du vælge indstillingen Tilføj biblioteksfil .
Når du har uploadet en fil, kan du tilsidesætte den ved at klikke på indstillingen Opdater fil og uploade en ny fil, eller du kan slette filen via indstillingen Slet .
Send en kørselsanmodning
Sådan sender du en anmodning om at køre Spark-jobdefinitionen fra VS Code:
Fra indstillingerne til højre for navnet på den Spark-jobdefinition, du vil køre, skal du vælge indstillingen Kør Spark Job .

Når du har sendt anmodningen, vises der et nyt Apache Spark-program i noden Kørsler på listen Stifinder. Du kan annullere det kørende job ved at vælge indstillingen Annuller Spark-job .
Åbn en Spark-jobdefinition på Fabric-portalen
Du kan åbne siden til oprettelse af Spark-jobdefinitioner på Fabric-portalen ved at vælge indstillingen Åbn i browser .
Du kan også vælge Åbn i browser ud for en fuldført kørsel for at se siden med detaljeovervågning for den pågældende kørsel.

Debug Spark-jobdefinitionskildekode (Python)
Hvis Spark-jobdefinitionen oprettes med PySpark (Python), kan du downloade .py scriptet for hoveddefinitionsfilen og den fil, der refereres til, og foretage fejlfinding af kildescriptet i VS Code.
Hvis du vil downloade kildekoden, skal du vælge indstillingen Debug Spark Job Definition til højre for Definitionen af Spark-job.

Når overførslen er fuldført, åbnes mappen med kildekoden automatisk.
Vælg indstillingen Hav tillid til forfatterne , når du bliver bedt om det. Denne indstilling vises kun, første gang du åbner mappen. Hvis du ikke vælger denne indstilling, kan du ikke foretage fejlfinding eller køre kildescriptet. Du kan finde flere oplysninger i Visual Studio Code Workspace Trust Security.)
Hvis du har downloadet kildekoden før, bliver du bedt om at bekræfte, at du vil overskrive den lokale version med den nye download.
Bemærk
I rodmappen for kildescriptet opretter systemet en undermappe med navnet conf. I denne mappe indeholder en fil med navnet lighter-config.json nogle systemmetadata, der skal bruges til fjernkørsel. Foretag IKKE ændringer af den.
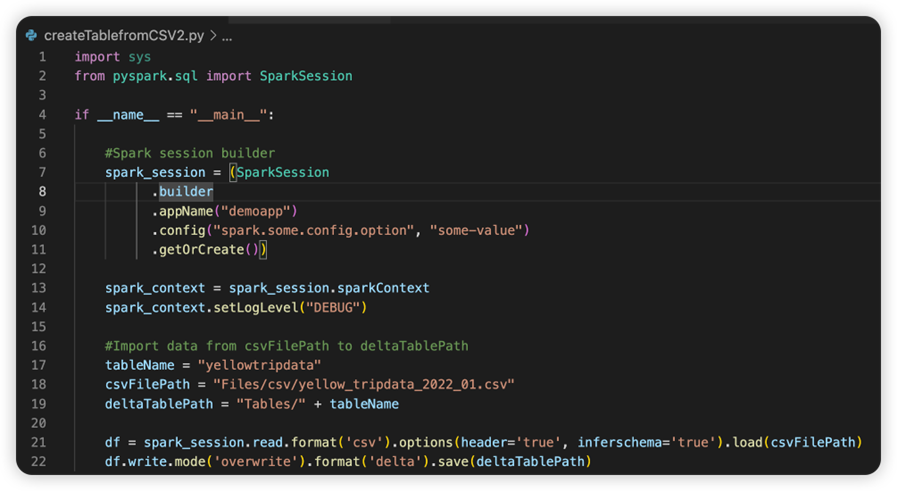
Filen med navnet sparkconf.py indeholder et kodestykke, som du skal tilføje for at konfigurere SparkConf-objektet . Hvis du vil aktivere fjernfejlfindingen, skal du sørge for, at SparkConf-objektet er konfigureret korrekt. På følgende billede vises den oprindelige version af kildekoden.
Det næste billede er den opdaterede kildekode, når du har kopieret og indsat kodestykket.
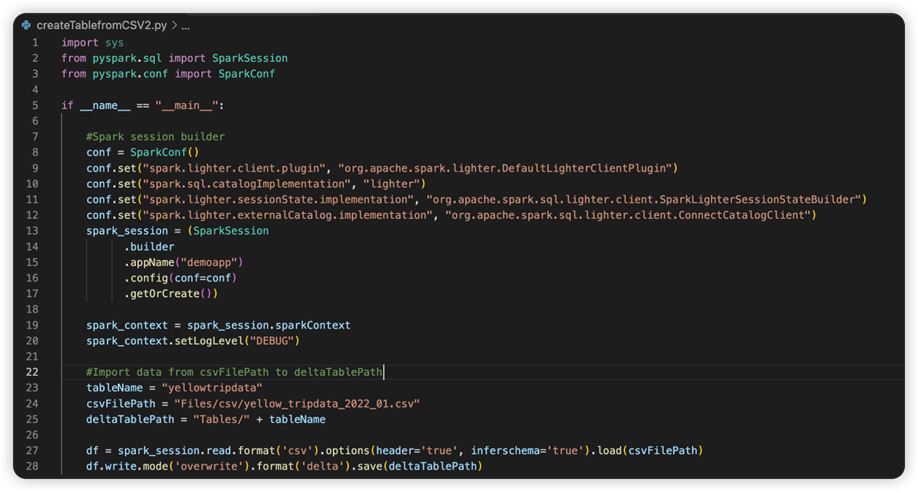
Når du har opdateret kildekoden med den nødvendige forbindelse, skal du vælge den rigtige Python-fortolker. Sørg for at vælge den, der er installeret i miljøet synapse-spark-kernel conda.
Rediger egenskaber for Spark-jobdefinition
Du kan redigere detaljeegenskaberne for Spark-jobdefinitioner, f.eks. kommandolinjeargumenter.
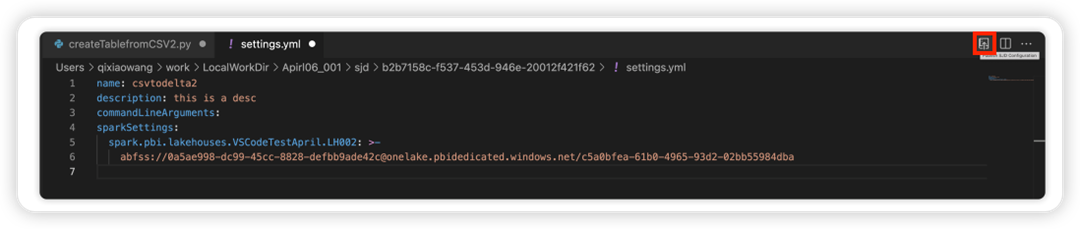
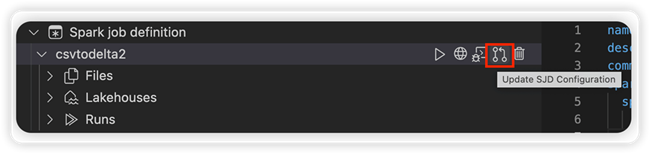
Vælg indstillingen Opdater SJD-konfiguration for at åbne en settings.yml fil. De eksisterende egenskaber udfylder indholdet af denne fil.
Opdater og gem filen .yml.
Vælg indstillingen Publicer SJD-egenskab i øverste højre hjørne for at synkronisere ændringen tilbage til fjernarbejdsområdet.