Develop applications with LangChain and Azure AI Foundry
LangChain is a development ecosystem that makes as easy possible for developers to build applications that reason. The ecosystem is composed by multiple components. Most of the them can be used by themselves, allowing you to pick and choose whichever components you like best.
Models deployed to Azure AI Foundry can be used with LangChain in two ways:
Using the Azure AI model inference API: All models deployed to Azure AI Foundry support the Azure AI model inference API, which offers a common set of functionalities that can be used for most of the models in the catalog. The benefit of this API is that, since it's the same for all the models, changing from one to another is as simple as changing the model deployment being use. No further changes are required in the code. When working with LangChain, install the extensions
langchain-azure-ai.Using the model's provider specific API: Some models, like OpenAI, Cohere, or Mistral, offer their own set of APIs and extensions for LangChain. Those extensions may include specific functionalities that the model support and hence are suitable if you want to exploit them. When working with LangChain, install the extension specific for the model you want to use, like
langchain-openaiorlangchain-cohere.
In this tutorial, you learn how to use the packages langchain-azure-ai to build applications with LangChain.
Prerequisites
To run this tutorial, you need:
A model deployment supporting the Azure AI model inference API deployed. In this example, we use a
Mistral-Large-2407deployment in the Azure AI model inference.Python 3.9 or later installed, including pip.
LangChain installed. You can do it with:
pip install langchain-coreIn this example, we are working with the Azure AI model inference API, hence we install the following packages:
pip install -U langchain-azure-ai
Configure the environment
To use LLMs deployed in Azure AI Foundry portal, you need the endpoint and credentials to connect to it. Follow these steps to get the information you need from the model you want to use:
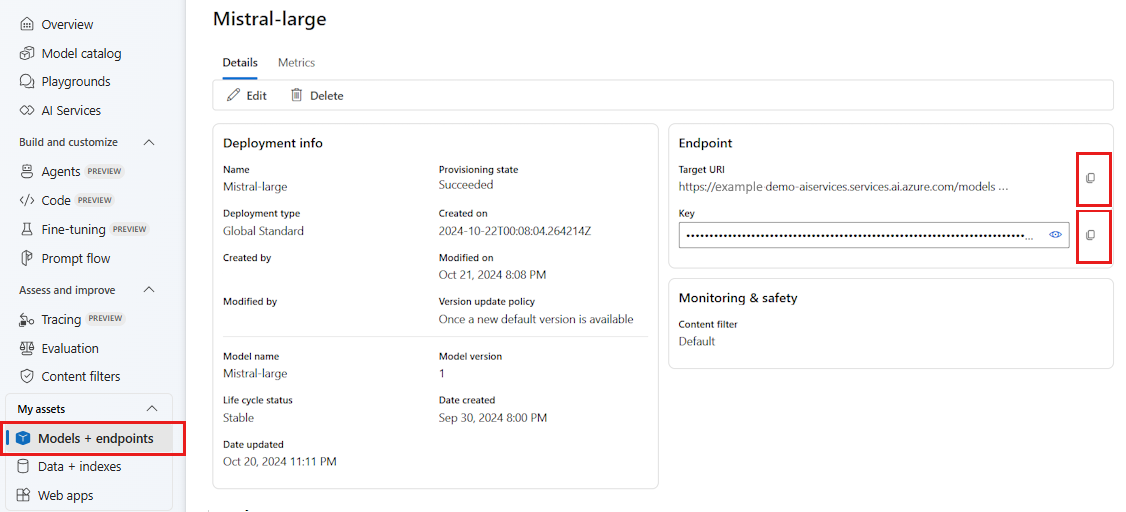
Go to the Azure AI Foundry.
Open the project where the model is deployed, if it isn't already open.
Go to Models + endpoints and select the model you deployed as indicated in the prerequisites.
Copy the endpoint URL and the key.
Tip
If your model was deployed with Microsoft Entra ID support, you don't need a key.

In this scenario, we placed both the endpoint URL and key in the following environment variables:
export AZURE_INFERENCE_ENDPOINT="<your-model-endpoint-goes-here>"
export AZURE_INFERENCE_CREDENTIAL="<your-key-goes-here>"
Once configured, create a client to connect to the endpoint. In this case, we are working with a chat completions model hence we import the class AzureAIChatCompletionsModel.
import os
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
model = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model="mistral-large-2407",
)
Tip
For Azure OpenAI models, configure the client as indicated at Using Azure OpenAI models.
You can use the following code to create the client if your endpoint supports Microsoft Entra ID:
import os
from azure.identity import DefaultAzureCredential
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
model = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=DefaultAzureCredential(),
model_name="mistral-large-2407",
)
Note
When using Microsoft Entra ID, make sure that the endpoint was deployed with that authentication method and that you have the required permissions to invoke it.
If you are planning to use asynchronous calling, it's a best practice to use the asynchronous version for the credentials:
from azure.identity.aio import (
DefaultAzureCredential as DefaultAzureCredentialAsync,
)
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
model = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=DefaultAzureCredentialAsync(),
model_name="mistral-large-2407",
)
If your endpoint is serving one model, like with the Serverless API Endpoints, you don't have to indicate model_name parameter:
import os
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
model = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
)
Use chat completions models
Let's first use the model directly. ChatModels are instances of LangChain Runnable, which means they expose a standard interface for interacting with them. To simply call the model, we can pass in a list of messages to the invoke method.
from langchain_core.messages import HumanMessage, SystemMessage
messages = [
SystemMessage(content="Translate the following from English into Italian"),
HumanMessage(content="hi!"),
]
model.invoke(messages)
You can also compose operations as needed in what's called chains. Let's now use a prompt template to translate sentences:
from langchain_core.output_parsers import StrOutputParser
system_template = "Translate the following into {language}:"
prompt_template = ChatPromptTemplate.from_messages(
[("system", system_template), ("user", "{text}")]
)
As you can see from the prompt template, this chain has a language and text input. Now, let's create an output parser:
from langchain_core.prompts import ChatPromptTemplate
parser = StrOutputParser()
We can now combine the template, model, and the output parser from above using the pipe (|) operator:
chain = prompt_template | model | parser
To invoke the chain, identify the inputs required and provide values using the invoke method:
chain.invoke({"language": "italian", "text": "hi"})
'ciao'
Chaining multiple LLMs together
Models deployed to Azure AI Foundry support the Azure AI model inference API, which is standard across all the models. Chain multiple LLM operations based on the capabilities of each model so you can optimize for the right model based on capabilities.
In the following example, we create two model clients, one is a producer and another one is a verifier. To make the distinction clear, we are using a multi-model endpoint like the Azure AI model inference service and hence we are passing the parameter model_name to use a Mistral-Large and a Mistral-Small model, quoting the fact that producing content is more complex than verifying it.
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
producer = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model_name="mistral-large-2407",
)
verifier = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model_name="mistral-small",
)
Tip
Explore the model card of each of the models to understand the best use cases for each model.
The following example generates a poem written by an urban poet:
from langchain_core.prompts import PromptTemplate
producer_template = PromptTemplate(
template="You are an urban poet, your job is to come up \
verses based on a given topic.\n\
Here is the topic you have been asked to generate a verse on:\n\
{topic}",
input_variables=["topic"],
)
verifier_template = PromptTemplate(
template="You are a verifier of poems, you are tasked\
to inspect the verses of poem. If they consist of violence and abusive language\
report it. Your response should be only one word either True or False.\n \
Here is the lyrics submitted to you:\n\
{input}",
input_variables=["input"],
)
Now let's chain the pieces:
chain = producer_template | producer | parser | verifier_template | verifier | parser
The previous chain returns the output of the step verifier only. Since we want to access the intermediate result generated by the producer, in LangChain you need to use a RunnablePassthrough object to also output that intermediate step. The following code shows how to do it:
from langchain_core.runnables import RunnablePassthrough, RunnableParallel
generate_poem = producer_template | producer | parser
verify_poem = verifier_template | verifier | parser
chain = generate_poem | RunnableParallel(poem=RunnablePassthrough(), verification=RunnablePassthrough() | verify_poem)
To invoke the chain, identify the inputs required and provide values using the invoke method:
chain.invoke({"topic": "living in a foreign country"})
{
"peom": "...",
"verification: "false"
}
Use embeddings models
In the same way, you create an LLM client, you can connect to an embeddings model. In the following example, we are setting the environment variable to now point to an embeddings model:
export AZURE_INFERENCE_ENDPOINT="<your-model-endpoint-goes-here>"
export AZURE_INFERENCE_CREDENTIAL="<your-key-goes-here>"
Then create the client:
from langchain_azure_ai.embeddings import AzureAIEmbeddingsModel
embed_model = AzureAIEmbeddingsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ['AZURE_INFERENCE_CREDENTIAL'],
model_name="text-embedding-3-large",
)
The following example shows a simple example using a vector store in memory:
from langchain_core.vectorstores import InMemoryVectorStore
vector_store = InMemoryVectorStore(embed_model)
Let's add some documents:
from langchain_core.documents import Document
document_1 = Document(id="1", page_content="foo", metadata={"baz": "bar"})
document_2 = Document(id="2", page_content="thud", metadata={"bar": "baz"})
documents = [document_1, document_2]
vector_store.add_documents(documents=documents)
Let's search by similarity:
results = vector_store.similarity_search(query="thud",k=1)
for doc in results:
print(f"* {doc.page_content} [{doc.metadata}]")
Using Azure OpenAI models
If you are using Azure OpenAI service or Azure AI model inference service with OpenAI models with langchain-azure-ai package, you might need to use api_version parameter to select a specific API version. The following example shows how to connect to an Azure OpenAI model deployment in Azure OpenAI service:
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
llm = AzureAIChatCompletionsModel(
endpoint="https://<resource>.openai.azure.com/openai/deployments/<deployment-name>",
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
api_version="2024-05-01-preview",
)
Important
Check which is the API version that your deployment is using. Using a wrong api_version or one not supported by the model results in a ResourceNotFound exception.
If the deployment is hosted in Azure AI Services, you can use the Azure AI model inference service:
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
llm = AzureAIChatCompletionsModel(
endpoint="https://<resource>.services.ai.azure.com/models",
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model_name="<model-name>",
api_version="2024-05-01-preview",
)
Debugging and troubleshooting
If you need to debug your application and understand the requests sent to the models in Azure AI Foundry, you can use the debug capabilities of the integration as follows:
First, configure logging to the level you are interested in:
import sys
import logging
# Acquire the logger for this client library. Use 'azure' to affect both
# 'azure.core` and `azure.ai.inference' libraries.
logger = logging.getLogger("azure")
# Set the desired logging level. logging.INFO or logging.DEBUG are good options.
logger.setLevel(logging.DEBUG)
# Direct logging output to stdout:
handler = logging.StreamHandler(stream=sys.stdout)
# Or direct logging output to a file:
# handler = logging.FileHandler(filename="sample.log")
logger.addHandler(handler)
# Optional: change the default logging format. Here we add a timestamp.
formatter = logging.Formatter("%(asctime)s:%(levelname)s:%(name)s:%(message)s")
handler.setFormatter(formatter)
To see the payloads of the requests, when instantiating the client, pass the argument logging_enable=True to the client_kwargs:
import os
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
model = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model_name="mistral-large-2407",
client_kwargs={"logging_enable": True},
)
Use the client as usual in your code.
Tracing
You can use the tracing capabilities in Azure AI Foundry by creating a tracer. Logs are stored in Azure Application Insights and can be queried at any time using Azure Monitor or Azure AI Foundry portal. Each AI Hub has an Azure Application Insights associated with it.
Get your instrumentation connection string
You can configure your application to send telemetry to Azure Application Insights either by:
Using the connection string to Azure Application Insights directly:
Go to Azure AI Foundry portal and select Tracing.
Select Manage data source. In this screen you can see the instance that is associated with the project.
Copy the value at Connection string and set it to the following variable:
import os application_insights_connection_string = "instrumentation...."
Using the Azure AI Foundry SDK and the project connection string.
Ensure you have the package
azure-ai-projectsinstalled in your environment.Go to Azure AI Foundry portal.
Copy your project's connection string and set it the following code:
from azure.ai.projects import AIProjectClient from azure.identity import DefaultAzureCredential project_client = AIProjectClient.from_connection_string( credential=DefaultAzureCredential(), conn_str="<your-project-connection-string>", ) application_insights_connection_string = project_client.telemetry.get_connection_string()
Configure tracing for Azure AI Foundry
The following code creates a tracer connected to the Azure Application Insights behind a project in Azure AI Foundry. Notice that the parameter enable_content_recording is set to True. This enables the capture of the inputs and outputs of the entire application as well as the intermediate steps. Such is helpful when debugging and building applications, but you might want to disable it on production environments. It defaults to the environment variable AZURE_TRACING_GEN_AI_CONTENT_RECORDING_ENABLED:
from langchain_azure_ai.callbacks.tracers import AzureAIInferenceTracer
tracer = AzureAIInferenceTracer(
connection_string=application_insights_connection_string,
enable_content_recording=True,
)
To configure tracing with your chain, indicate the value config in the invoke operation as a callback:
chain.invoke({"topic": "living in a foreign country"}, config={"callbacks": [tracer]})
To configure the chain itself for tracing, use the .with_config() method:
chain = chain.with_config({"callbacks": [tracer]})
Then use the invoke() method as usual:
chain.invoke({"topic": "living in a foreign country"})
View traces
To see traces:
Go to Azure AI Foundry portal.
Navigate to Tracing section.
Identify the trace you have created. It may take a couple of seconds for the trace to show.
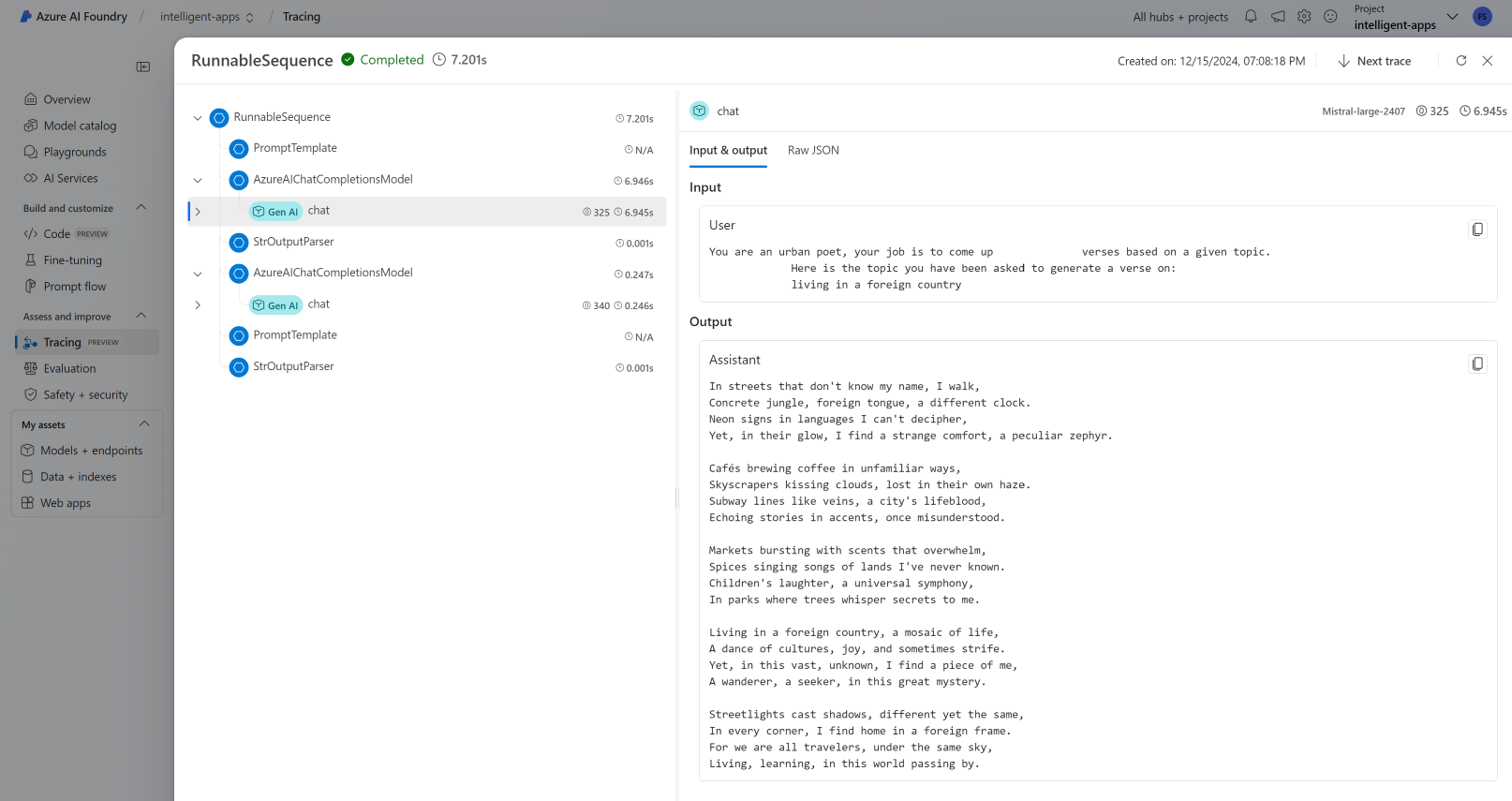

Learn more about how to visualize and manage traces.