Synchronizace více motorů
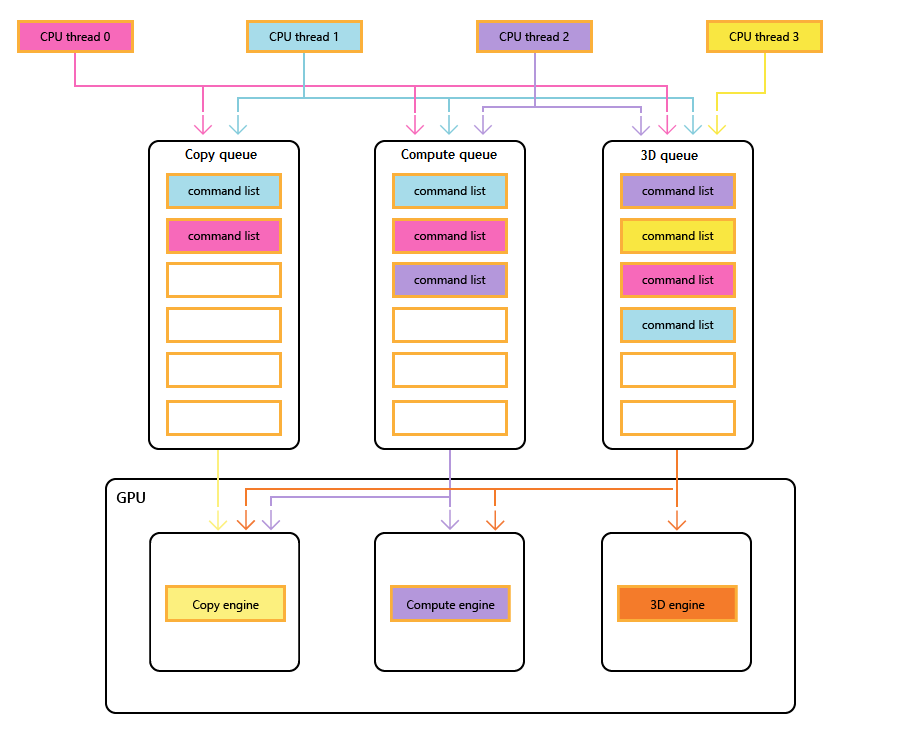
Většina moderních GPU obsahuje více nezávislých modulů, které poskytují specializované funkce. Mnoho z nich má jeden nebo více vyhrazených kopírovaných modulů a výpočetní modul, který se obvykle liší od 3D modulu. Každý z těchto modulů může provádět příkazy paralelně s ostatními. Direct3D 12 poskytuje jemně odstupňovaný přístup k 3D, výpočetním a kopírovat modulům pomocí front a seznamů příkazů.
Moduly GPU
Následující diagram znázorňuje vlákna procesoru názvu, přičemž každá naplňuje jednu nebo více kopií, výpočetních prostředků a 3D front. 3D fronta může řídit všechny tři moduly GPU; výpočetní fronta může řídit výpočetní a kopírovat moduly; a fronta kopírování jednoduše modul kopírování.
Vzhledem k tomu, že různá vlákna naplňují fronty, nemůže existovat žádná jednoduchá záruka pořadí provádění, a proto je potřeba mechanismy synchronizace – pokud je název vyžaduje.
Následující obrázek znázorňuje, jak může název plánovat práci napříč několika moduly GPU, včetně synchronizace mezi moduly, pokud je to potřeba: ukazuje úlohy jednotlivých modulů se závislostmi mezi moduly. V tomto příkladu modul kopírování nejprve zkopíruje určitou geometrii potřebnou k vykreslení. 3D modul čeká na dokončení těchto kopií a vykreslí předdefinovanou geometrii. Ten pak spotřebuje výpočetní modul. Výsledky výpočetního modulu Dispatchspolu s několika operacemi kopírování textury na modulu kopírování jsou spotřebovány 3D modulem pro konečné volání Draw.
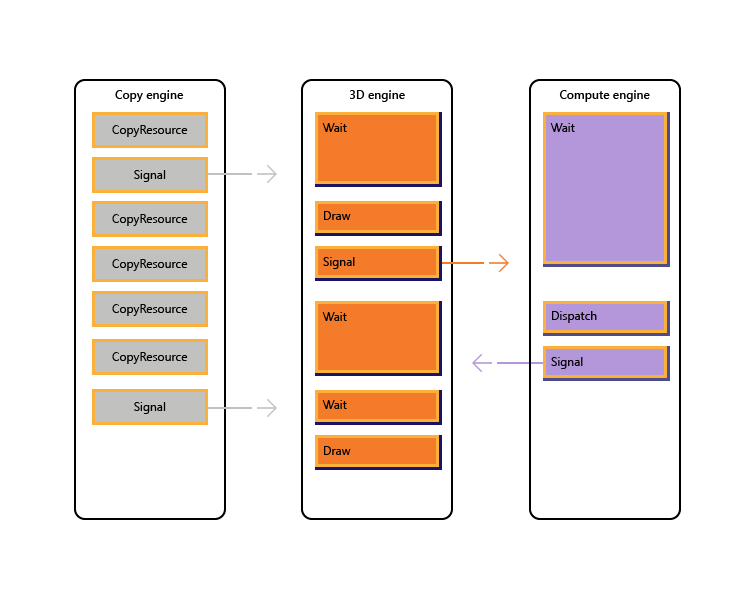
Následující pseudokód znázorňuje, jak může název takovou úlohu odeslat.
// Get per-engine contexts. Note that multiple queues may be exposed
// per engine, however that design is not reflected here.
copyEngine = device->GetCopyEngineContext();
renderEngine = device->GetRenderEngineContext();
computeEngine = device->GetComputeEngineContext();
copyEngine->CopyResource(geometry, ...); // copy geometry
copyEngine->Signal(copyFence, 101);
copyEngine->CopyResource(tex1, ...); // copy textures
copyEngine->CopyResource(tex2, ...); // copy more textures
copyEngine->CopyResource(tex3, ...); // copy more textures
copyEngine->CopyResource(tex4, ...); // copy more textures
copyEngine->Signal(copyFence, 102);
renderEngine->Wait(copyFence, 101); // geometry copied
renderEngine->Draw(); // pre-pass using geometry only into rt1
renderEngine->Signal(renderFence, 201);
computeEngine->Wait(renderFence, 201); // prepass completed
computeEngine->Dispatch(); // lighting calculations on pre-pass (using rt1 as SRV)
computeEngine->Signal(computeFence, 301);
renderEngine->Wait(computeFence, 301); // lighting calculated into buf1
renderEngine->Wait(copyFence, 102); // textures copied
renderEngine->Draw(); // final render using buf1 as SRV, and tex[1-4] SRVs
Následující pseudokód znázorňuje synchronizaci mezi moduly kopírování a 3D, aby bylo možné dosáhnout přidělení paměti podobné haldě prostřednictvím vyrovnávací paměti okruhu. Názvy mají flexibilitu zvolit správnou rovnováhu mezi maximalizací paralelismu (prostřednictvím velké vyrovnávací paměti) a snížením spotřeby a latence paměti (přes malou vyrovnávací paměť).
device->CreateBuffer(&ringCB);
for(int i=1;i++){
if(i > length) copyEngine->Wait(fence1, i - length);
copyEngine->Map(ringCB, value%length, WRITE, pData); // copy new data
copyEngine->Signal(fence2, i);
renderEngine->Wait(fence2, i);
renderEngine->Draw(); // draw using copied data
renderEngine->Signal(fence1, i);
}
// example for length = 3:
// copyEngine->Map();
// copyEngine->Signal(fence2, 1); // fence2 = 1
// copyEngine->Map();
// copyEngine->Signal(fence2, 2); // fence2 = 2
// copyEngine->Map();
// copyEngine->Signal(fence2, 3); // fence2 = 3
// copy engine has exhausted the ring buffer, so must wait for render to consume it
// copyEngine->Wait(fence1, 1); // fence1 == 0, wait
// renderEngine->Wait(fence2, 1); // fence2 == 3, pass
// renderEngine->Draw();
// renderEngine->Signal(fence1, 1); // fence1 = 1, copy engine now unblocked
// renderEngine->Wait(fence2, 2); // fence2 == 3, pass
// renderEngine->Draw();
// renderEngine->Signal(fence1, 2); // fence1 = 2
// renderEngine->Wait(fence2, 3); // fence2 == 3, pass
// renderEngine->Draw();
// renderEngine->Signal(fence1, 3); // fence1 = 3
// now render engine is starved, and so must wait for the copy engine
// renderEngine->Wait(fence2, 4); // fence2 == 3, wait
Scénáře s více moduly
Direct3D 12 umožňuje vyhnout se nečekaným výpadkům způsobeným neočekávanými zpožděními synchronizace. Umožňuje také zavést synchronizaci na vyšší úrovni, kde je možné požadovanou synchronizaci určit s větší jistotou. Druhým problémem, který řeší více modulů, je explicitnější operace, což zahrnuje přechody mezi 3D a videem, které byly tradičně nákladné kvůli synchronizaci mezi několika kontexty jádra.
Konkrétně je možné řešit následující scénáře s Direct3D 12.
- Práce s GPU s asynchronní a nízkou prioritou To umožňuje souběžné spouštění operací GPU s nízkou prioritou a atomických operací, které umožňují jednomu vláknu GPU využívat výsledky jiného nesynchronizovaného vlákna bez blokování.
- Práce s výpočetními prostředky s vysokou prioritou Pomocí výpočetních prostředků na pozadí je možné přerušit vykreslování 3D, aby se udělalo malé množství výpočetních operací s vysokou prioritou. Výsledky této práce lze získat v rané fázi pro další zpracování procesoru.
- Práce na výpočetním prostředí na pozadí Samostatná fronta s nízkou prioritou pro výpočetní úlohy umožňuje aplikaci využívat náhradní cykly GPU k provádění výpočtů na pozadí bez negativního dopadu na primární úlohy vykreslování (nebo jiné). Úlohy na pozadí můžou zahrnovat dekompresi prostředků nebo aktualizaci simulací nebo struktur zrychlení. Úlohy na pozadí by se měly synchronizovat na procesoru zřídka (přibližně jednou na snímek), aby nedocházelo k zastavení nebo zpomalení práce na popředí.
- Streamování a nahrávání dat Samostatná fronta kopírování nahrazuje koncepty D3D11 počátečních dat a aktualizace prostředků. I když je aplikace zodpovědná za další podrobnosti v modelu Direct3D 12, tato odpovědnost je součástí výkonu. Aplikace může řídit, kolik systémové paměti se věnuje ukládání dat do vyrovnávací paměti. Aplikace může zvolit, kdy a jak (procesor vs. GPU, blokování vs. neblokující), a může sledovat průběh a řídit množství práce ve frontě.
- Zvýšená paralelismus. Aplikace můžou používat hlubší fronty pro úlohy na pozadí (např. dekódování videa), pokud mají samostatné fronty pro práci na popředí.
V Direct3D 12 je koncept fronty příkazů reprezentace rozhraní API zhruba sériové posloupnosti práce odeslané aplikací. Překážky a další techniky umožňují, aby se tato práce prováděla v kanálu nebo mimo pořadí, ale aplikace vidí jenom jednu časovou osu dokončení. To odpovídá bezprostřednímu kontextu v D3D11.
Rozhraní API pro synchronizaci
Zařízení a fronty
Zařízení Direct3D 12 má metody pro vytváření a načítání front příkazů s různými typy a prioritami. Většina aplikací by měla používat výchozí fronty příkazů, protože tyto fronty umožňují sdílené využití jinými komponentami. Aplikace s dalšími požadavky na souběžnost můžou vytvářet další fronty. Fronty jsou určené typem seznamu příkazů, který spotřebovávají.
Projděte si následující metody vytváření ID3D12Device.
- CreateCommandQueue : vytvoří frontu příkazů na základě informací ve struktuře Direct3D 12_COMMAND_QUEUE_DESC.
- CreateCommandList : vytvoří seznam příkazů typu Direct3D 12_COMMAND_LIST_TYPE.
- CreateFence : vytvoří plot, který označuje příznaky v Direct3D 12_FENCE_FLAGS. Ploty se používají k synchronizaci front.
Fronty všech typů (3D, výpočetních prostředků a kopírování) sdílejí stejné rozhraní a všechny jsou založené na příkazovém seznamu.
Projděte si následující metody ID3D12CommandQueue.
- ExecuteCommandLists : odešle pole seznamů příkazů ke spuštění. Každý seznam příkazů definovaný ID3D12CommandList.
- signal: nastaví hodnotu plotu, když fronta (spuštěná na GPU) dosáhne určitého bodu.
- Čekání: Fronta čeká, dokud zadaný plot nedosáhne zadané hodnoty.
Mějte na paměti, že sady nejsou využívány žádnými frontami, a proto tento typ nelze použít k vytvoření fronty.
Ploty
Rozhraní API s více moduly poskytuje explicitní rozhraní API pro vytváření a synchronizaci pomocí plotů. Plot je konstrukce synchronizace řízená hodnotou UINT64. Hodnoty plotu jsou nastaveny aplikací. Operace signálu upraví hodnotu plotu a čekací bloky, dokud plot nedosáhne požadované hodnoty nebo vyšší. Událost může být aktivována, když plot dosáhne určité hodnoty.
Projděte si metody rozhraní ID3D12Fence.
- GetCompletedValue : vrátí aktuální hodnotu plotu.
- SetEventOnCompletion : způsobí, že se událost aktivuje, když plot dosáhne dané hodnoty.
- signál : nastaví plot na danou hodnotu.
Ploty umožňují přístup procesoru k aktuální hodnotě plotu a procesor čeká a signály.
Metoda Signal na rozhraní ID3D12Fence aktualizuje plot ze strany procesoru. K této aktualizaci dojde okamžitě. Metoda Signal na ID3D12CommandQueue aktualizuje plot ze strany GPU. K této aktualizaci dochází po dokončení všech ostatních operací ve frontě příkazů.
Všechny uzly v nastavení s více moduly můžou číst a reagovat na jakýkoli plot, který dosáhne správné hodnoty.
Aplikace nastavují vlastní hodnoty plotu, dobrým výchozím bodem může být zvýšení plotu jednou za rámec.
Plot může. To znamená, že hodnota plotu nemusí pouze zvýšit. Pokud je operace signálu zařazena do fronty dvou různých příkazů, nebo pokud dvě vlákna procesoru volají signál na plotu, může existovat závod, který určí, který Signál dokončí poslední, a proto hodnota plotu je hodnota, která zůstane. Pokud je plot znovu zatěžován, všechny nové čekání (včetně SetEventOnCompletion požadavky) budou porovnány s novou nižší hodnotou plotu, a proto nemusí být splněny, i když hodnota plotu byla dříve dostatečně vysoká, aby je uspokojila. Pokud dojde k rase, mezi hodnotou, která bude vyhovovat nevyrovnanému čekání, a nižší hodnotou, která ne, bude čekání bude splněna bez ohledu na to, kterou hodnotu zůstane poté.
Rozhraní API plotu poskytují výkonné funkce synchronizace, ale můžou způsobit potenciálně obtížné ladění problémů. Doporučuje se, aby každý plot byl použit pouze k označení průběhu na jedné časové ose, aby se zabránilo rasám mezi signalizátory.
Kopírování a výpočty seznamů příkazů
Všechny tři typy seznamu příkazů používají rozhraní ID3D12GraphicsCommandList, ale pro kopírování a výpočty se podporuje pouze podmnožina metod.
Seznamy příkazů pro kopírování a výpočty můžou používat následující metody.
- Zavřít
- CopyBufferRegion
- CopyResource
- CopyTextureRegion
- CopyTiles
- resetování
- resourceBarrier
Seznamy výpočetních příkazů můžou také používat následující metody.
- ClearState
- ClearUnorderedAccessViewFloat
- ClearUnorderedAccessViewUint
- DiscardResource
- dispatch
- executeIndirect
- SetComputeRoot32BitConstant
- SetComputeRoot32BitConstants
- SetComputeRootConstantBufferView
- SetComputeRootDescriptorTable
- SetComputeRootShaderResourceView
- SetComputeRootSignature
- SetComputeRootUnorderedAccessView
- SetDescriptorHeaps
- SetPipelineState
- SetPredication
- EndQuery
Seznamy výpočetních příkazů musí při volání SetPipelineStatenastavit výpočetní PSO .
Sady není možné použít s výpočetními nebo kopírovat seznamy příkazů nebo fronty.
Příklad výpočetních prostředků a grafiky kanálu
Tento příklad ukazuje, jak je možné použít synchronizaci plotů k vytvoření kanálu výpočetní práce ve frontě (odkazované pComputeQueue), která je spotřebována grafikou ve frontě pGraphicsQueue. Výpočetní a grafická práce je kanálovaná s frontou grafiky, která spotřebovává výsledek výpočetní práce z několika snímků zpět a událost procesoru se používá k omezení celkové celkové fronty práce.
void PipelinedComputeGraphics()
{
const UINT CpuLatency = 3;
const UINT ComputeGraphicsLatency = 2;
HANDLE handle = CreateEvent(nullptr, FALSE, FALSE, nullptr);
UINT64 FrameNumber = 0;
while (1)
{
if (FrameNumber > ComputeGraphicsLatency)
{
pComputeQueue->Wait(pGraphicsFence,
FrameNumber - ComputeGraphicsLatency);
}
if (FrameNumber > CpuLatency)
{
pComputeFence->SetEventOnFenceCompletion(
FrameNumber - CpuLatency,
handle);
WaitForSingleObject(handle, INFINITE);
}
++FrameNumber;
pComputeQueue->ExecuteCommandLists(1, &pComputeCommandList);
pComputeQueue->Signal(pComputeFence, FrameNumber);
if (FrameNumber > ComputeGraphicsLatency)
{
UINT GraphicsFrameNumber = FrameNumber - ComputeGraphicsLatency;
pGraphicsQueue->Wait(pComputeFence, GraphicsFrameNumber);
pGraphicsQueue->ExecuteCommandLists(1, &pGraphicsCommandList);
pGraphicsQueue->Signal(pGraphicsFence, GraphicsFrameNumber);
}
}
}
Pro podporu tohoto kanálu musí existovat vyrovnávací paměť ComputeGraphicsLatency+1 různých kopií dat předávaných z výpočetní fronty do grafické fronty. Seznamy příkazů musí pro čtení a zápis z odpovídající "verze" dat ve vyrovnávací paměti používat UAV a indirection. Výpočetní fronta musí čekat, dokud grafická fronta nedokončí čtení z dat pro rámec N, aby mohl zapisovat rámec N+ComputeGraphicsLatency.
Všimněte si, že množství výpočetní fronty fungovalo vzhledem k procesoru přímo na množství požadované vyrovnávací paměti, ale řazení GPU do fronty nad rámec dostupného místa vyrovnávací paměti je méně cenné.
Alternativním mechanismem, který by se zabránilo nepřímému použití, by bylo vytvořit několik seznamů příkazů odpovídajících každé "přejmenované" verzi dat. V dalším příkladu se tato technika používá při rozšíření předchozího příkladu, aby výpočetní a grafické fronty běžely asynchronněji.
Příklad asynchronního výpočetního výkonu a grafiky
Tento další příklad umožňuje, aby se grafika vykreslovat asynchronně z výpočetní fronty. Mezi těmito dvěma fázemi je stále pevné množství dat uložených ve vyrovnávací paměti, ale teď grafika funguje nezávisle a používá nejvíce up-to-date výsledek výpočetní fáze, jak se označuje na procesoru, když je grafická práce zařazena do fronty. To by bylo užitečné, pokud byla grafická práce aktualizována jiným zdrojem, například uživatelským vstupem. Musí existovat několik seznamů příkazů, aby ComputeGraphicsLatency rámečky grafiky byly najednou v letu a funkce UpdateGraphicsCommandList představuje aktualizaci seznamu příkazů tak, aby zahrnoval nejnovější vstupní data a přečetla z výpočetních dat z příslušné vyrovnávací paměti.
Výpočetní fronta musí stále čekat na dokončení grafické fronty s vyrovnávacími paměťmi kanálu, ale třetí plot (pGraphicsComputeFence) je zaveden tak, aby bylo možné sledovat průběh výpočetních operací čtení grafiky a průběhu grafiky obecně. To odráží skutečnost, že nyní po sobě jdoucí grafické snímky by mohly číst ze stejného výpočetního výsledku nebo přeskočit výpočetní výsledek. Efektivnější, ale o něco složitější návrh by používal pouze jeden grafický plot a uložil mapování na výpočetní rámce používané jednotlivými grafickými rámečky.
void AsyncPipelinedComputeGraphics()
{
const UINT CpuLatency{ 3 };
const UINT ComputeGraphicsLatency{ 2 };
// The compute fence is at index 0; the graphics fence is at index 1.
ID3D12Fence* rgpFences[]{ pComputeFence, pGraphicsFence };
HANDLE handles[2];
handles[0] = CreateEvent(nullptr, FALSE, TRUE, nullptr);
handles[1] = CreateEvent(nullptr, FALSE, TRUE, nullptr);
UINT FrameNumbers[]{ 0, 0 };
ID3D12GraphicsCommandList* rgpGraphicsCommandLists[CpuLatency];
CreateGraphicsCommandLists(ARRAYSIZE(rgpGraphicsCommandLists),
rgpGraphicsCommandLists);
// Graphics needs to wait for the first compute frame to complete; this is the
// only wait that the graphics queue will perform.
pGraphicsQueue->Wait(pComputeFence, 1);
while (true)
{
for (auto i = 0; i < 2; ++i)
{
if (FrameNumbers[i] > CpuLatency)
{
rgpFences[i]->SetEventOnCompletion(
FrameNumbers[i] - CpuLatency,
handles[i]);
}
else
{
::SetEvent(handles[i]);
}
}
auto WaitResult = ::WaitForMultipleObjects(2, handles, FALSE, INFINITE);
if (WaitResult > WAIT_OBJECT_0 + 1) continue;
auto Stage = WaitResult - WAIT_OBJECT_0;
++FrameNumbers[Stage];
switch (Stage)
{
case 0:
{
if (FrameNumbers[Stage] > ComputeGraphicsLatency)
{
pComputeQueue->Wait(pGraphicsComputeFence,
FrameNumbers[Stage] - ComputeGraphicsLatency);
}
pComputeQueue->ExecuteCommandLists(1, &pComputeCommandList);
pComputeQueue->Signal(pComputeFence, FrameNumbers[Stage]);
break;
}
case 1:
{
// Recall that the GPU queue started with a wait for pComputeFence, 1
UINT64 CompletedComputeFrames = min(1,
pComputeFence->GetCompletedValue());
UINT64 PipeBufferIndex =
(CompletedComputeFrames - 1) % ComputeGraphicsLatency;
UINT64 CommandListIndex = (FrameNumbers[Stage] - 1) % CpuLatency;
// Update graphics command list based on CPU input and using the appropriate
// buffer index for data produced by compute.
UpdateGraphicsCommandList(PipeBufferIndex,
rgpGraphicsCommandLists[CommandListIndex]);
// Signal *before* new rendering to indicate what compute work
// the graphics queue is DONE with
pGraphicsQueue->Signal(pGraphicsComputeFence, CompletedComputeFrames - 1);
pGraphicsQueue->ExecuteCommandLists(1,
rgpGraphicsCommandLists + CommandListIndex);
pGraphicsQueue->Signal(pGraphicsFence, FrameNumbers[Stage]);
break;
}
}
}
}
Přístup k prostředkům s více frontou
Pro přístup k prostředku ve více než jedné frontě musí aplikace dodržovat následující pravidla.
Přístup k prostředkům (odkaz na Direct3D 12_RESOURCE_STATES) je určen třídami typu fronty, nikoli objektem fronty. Existují dvě třídy typu fronty: Výpočetní/3D fronta je jedna třída typu, Copy je druhá třída typu. Prostředek, který má bariéru pro NON_PIXEL_SHADER_RESOURCE stav v jedné 3D frontě, lze v daném stavu použít v libovolné 3D nebo výpočetní frontě, a to v závislosti na požadavcích na synchronizaci, které vyžadují serializaci většiny zápisů. Stavy prostředků sdílené mezi dvěma třídami typu (COPY_SOURCE a COPY_DEST) jsou pro každou třídu typů považovány za různé stavy. Takže pokud prostředek přejde na COPY_DEST ve frontě kopírování, nebude přístupný jako cíl kopírování z 3D nebo výpočetních front a naopak.
Shrnutí
- Fronta "object" je libovolná jedna fronta.
- Fronta "type" je jedna z těchto tří: Compute, 3D a Copy.
- Fronta type class je jedna z těchto dvou: Compute/3D a Copy.
Příznaky COPY (COPY_DEST a COPY_SOURCE) používané jako počáteční stavy představují stavy ve třídě typu 3D/Compute. Pokud chcete použít prostředek původně ve frontě kopírování, měl by se spustit ve stavu COMMON. Stav COMMON lze použít pro všechna použití ve frontě kopírování pomocí implicitních přechodů stavu.
Přestože se stav prostředků sdílí ve všech výpočetních a 3D frontách, není dovoleno zapisovat do prostředku současně v různých frontách. "Simultánně" znamená nesynchronizované, notace nesynchronizovaného spuštění není na některém hardwaru možná. Platí následující pravidla.
- Do prostředku může najednou zapisovat pouze jedna fronta.
- Více front může číst z prostředku, pokud nepřečtou bajty upravené zapisovačem (čtení bajtů, které se zapisují současně, vytvoří nedefinované výsledky).
- Plot se musí použít k synchronizaci po zápisu, aby jiná fronta mohl číst zapsané bajty nebo provádět jakýkoli přístup k zápisu.
Předváděné vyrovnávací paměti musí být ve stavu 12_RESOURCE_STATE_COMMON Direct3D.
Související témata
průvodce programováním Direct3D 12
Použití překážek prostředků k synchronizaci stavů prostředků v Direct3D 12
správa paměti v direct3D 12