Troubleshoot slow SQL Server performance caused by I/O issues
Applies to: SQL Server
This article provides guidance on what I/O issues cause slow SQL Server performance and how to troubleshoot the issues.
Define slow I/O performance
Performance monitor counters are used to determine slow I/O performance. These counters measure how fast the I/O subsystem services each I/O request on average in terms of clock time. The specific Performance monitor counters that measure I/O latency in Windows are Avg Disk sec/ Read, Avg. Disk sec/Write, and Avg. Disk sec/Transfer (cumulative of both reads and writes).
In SQL Server, things work the same way. Commonly, you look at whether SQL Server reports any I/O bottlenecks measured in clock time (milliseconds). SQL Server makes I/O requests to the OS by calling the Win32 functions such as WriteFile(), ReadFile(), WriteFileGather(), and ReadFileScatter(). When it posts an I/O request, SQL Server times the request and reports the duration of the request using wait types. SQL Server uses wait types to indicate I/O waits at different places in the product. The I/O related waits are:
If these waits exceed 10-15 milliseconds consistently, I/O is considered a bottleneck.
Note
To provide context and perspective, in the world of troubleshooting SQL Server, Microsoft CSS has observed cases where an I/O request took over one second and as high as 15 seconds per transfer-such I/O systems need optimization. Conversely, Microsoft CSS has seen systems where the throughput is below one millisecond/transfer. With today's SSD/NVMe technology, advertised throughput rates range in tens of microseconds per transfer. Therefore, the 10-15 millisecond/transfer figure is a very approximate threshold we selected based on collective experience between Windows and SQL Server engineers over the years. Usually, when numbers go beyond this approximate threshold, SQL Server users start seeing latency in their workloads and report them. Ultimately, the expected throughput of an I/O subsystem is defined by the manufacturer, model, configuration, workload, and potentially multiple other factors.
Methodology
A flow chart at the end of this article describes the methodology Microsoft CSS uses to approach slow I/O issues with SQL Server. It isn't an exhaustive or exclusive approach but has proven useful in isolating the issue and resolving it.
You can choose one of following two options to resolve the problem:
Option 1: Execute the steps directly in a notebook via Azure Data Studio
Note
Before attempting to open this notebook, make sure that Azure Data Studio is installed on your local machine. To install it, go to Learn how to install Azure Data Studio.
Option 2: Follow the steps manually
The methodology is outlined in these steps:
Step 1: Is SQL Server reporting slow I/O?
SQL Server may report I/O latency in several ways:
- I/O wait types
- DMV
sys.dm_io_virtual_file_stats - Error log or Application Event log
I/O wait types
Determine if there's I/O latency reported by SQL Server wait types. The values PAGEIOLATCH_*, WRITELOG, and ASYNC_IO_COMPLETION and the values of several other less common wait types should generally stay below 10-15 milliseconds per I/O request. If these values are greater consistently, an I/O performance problem exists and requires further investigation. The following query may help you gather this diagnostic information on your system:
#replace with server\instance or server for default instance
$sqlserver_instance = "server\instance"
for ([int]$i = 0; $i -lt 100; $i++)
{
sqlcmd -E -S $sqlserver_instance -Q "SELECT r.session_id, r.wait_type, r.wait_time as wait_time_ms`
FROM sys.dm_exec_requests r JOIN sys.dm_exec_sessions s `
ON r.session_id = s.session_id `
WHERE wait_type in ('PAGEIOLATCH_SH', 'PAGEIOLATCH_EX', 'WRITELOG', `
'IO_COMPLETION', 'ASYNC_IO_COMPLETION', 'BACKUPIO')`
AND is_user_process = 1"
Start-Sleep -s 2
}
File stats in sys.dm_io_virtual_file_stats
To view the database file-level latency as reported in SQL Server, run the following query:
#replace with server\instance or server for default instance
$sqlserver_instance = "server\instance"
sqlcmd -E -S $sqlserver_instance -Q "SELECT LEFT(mf.physical_name,100), `
ReadLatency = CASE WHEN num_of_reads = 0 THEN 0 ELSE (io_stall_read_ms / num_of_reads) END, `
WriteLatency = CASE WHEN num_of_writes = 0 THEN 0 ELSE (io_stall_write_ms / num_of_writes) END, `
AvgLatency = CASE WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 0 `
ELSE (io_stall / (num_of_reads + num_of_writes)) END,`
LatencyAssessment = CASE WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 'No data' ELSE `
CASE WHEN (io_stall / (num_of_reads + num_of_writes)) < 2 THEN 'Excellent' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 2 AND 5 THEN 'Very good' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 6 AND 15 THEN 'Good' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 16 AND 100 THEN 'Poor' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 100 AND 500 THEN 'Bad' `
ELSE 'Deplorable' END END, `
[Avg KBs/Transfer] = CASE WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 0 `
ELSE ((([num_of_bytes_read] + [num_of_bytes_written]) / (num_of_reads + num_of_writes)) / 1024) END, `
LEFT (mf.physical_name, 2) AS Volume, `
LEFT(DB_NAME (vfs.database_id),32) AS [Database Name]`
FROM sys.dm_io_virtual_file_stats (NULL,NULL) AS vfs `
JOIN sys.master_files AS mf ON vfs.database_id = mf.database_id `
AND vfs.file_id = mf.file_id `
ORDER BY AvgLatency DESC"
Look at the AvgLatency and LatencyAssessment columns to understand the latency details.
Error 833 reported in Errorlog or Application Event log
In some cases, you may observe error 833 SQL Server has encountered %d occurrence(s) of I/O requests taking longer than %d seconds to complete on file [%ls] in database [%ls] (%d) in the error log. You can check SQL Server error logs on your system by running the following PowerShell command:
Get-ChildItem -Path "c:\program files\microsoft sql server\mssql*" -Recurse -Include Errorlog |
Select-String "occurrence(s) of I/O requests taking longer than Longer than 15 secs"
Also, for more information on this error, see the MSSQLSERVER_833 section.
Step 2: Do Perfmon Counters indicate I/O latency?
If SQL Server reports I/O latency, refer to OS counters. You can determine if there's an I/O problem by examining the latency counter Avg Disk Sec/Transfer. The following code snippet indicates one way to collect this information through PowerShell. It gathers counters on all disk volumes: "_total". Change to a specific drive volume (for example, "D:"). To find which volumes host your database files, run the following query in your SQL Server:
#replace with server\instance or server for default instance
$sqlserver_instance = "server\instance"
sqlcmd -E -S $sqlserver_instance -Q "SELECT DISTINCT LEFT(volume_mount_point, 32) AS volume_mount_point `
FROM sys.master_files f `
CROSS APPLY sys.dm_os_volume_stats(f.database_id, f.file_id) vs"
Gather Avg Disk Sec/Transfer metrics on your volume of choice:
clear
$cntr = 0
# replace with your server name, unless local computer
$serverName = $env:COMPUTERNAME
# replace with your volume name - C: , D:, etc
$volumeName = "_total"
$Counters = @(("\\$serverName" +"\LogicalDisk($volumeName)\Avg. disk sec/transfer"))
$disksectransfer = Get-Counter -Counter $Counters -MaxSamples 1
$avg = $($disksectransfer.CounterSamples | Select-Object CookedValue).CookedValue
Get-Counter -Counter $Counters -SampleInterval 2 -MaxSamples 30 | ForEach-Object {
$_.CounterSamples | ForEach-Object {
[pscustomobject]@{
TimeStamp = $_.TimeStamp
Path = $_.Path
Value = ([Math]::Round($_.CookedValue, 5))
turn = $cntr = $cntr +1
running_avg = [Math]::Round(($avg = (($_.CookedValue + $avg) / 2)), 5)
} | Format-Table
}
}
write-host "Final_Running_Average: $([Math]::Round( $avg, 5)) sec/transfer`n"
if ($avg -gt 0.01)
{
Write-Host "There ARE indications of slow I/O performance on your system"
}
else
{
Write-Host "There is NO indication of slow I/O performance on your system"
}
If the values of this counter are consistently above 10-15 milliseconds, you need to look at the issue further. Occasional spikes don't count in most cases but be sure to double-check the duration of a spike. If the spike lasted one minute or more, it's more of a plateau than a spike.
If the Performance monitor counters don't report latency, but SQL Server does, then the problem is between SQL Server and the Partition Manager, that is, filter drivers. The Partition Manager is an I/O layer where the OS collects Perfmon counters. To address the latency, ensure proper exclusions of filter drivers and resolve filter driver issues. Filter drivers are used by programs like Anti-virus software, Backup solutions, Encryption, Compression, and so on. You can use this command to list filter drivers on the systems and the volumes they attach to. Then, you can look up the driver names and software vendors in the Allocated filter altitudes article.
fltmc instances
For more information, see How to choose antivirus software to run on computers that are running SQL Server.
Avoid using Encrypting File System (EFS) and file-system compression because they cause asynchronous I/O to become synchronous and therefore slower. For more information, see the Asynchronous disk I/O appears as synchronous on Windows article.
Step 3: Is the I/O subsystem overwhelmed beyond capacity?
If SQL Server and the OS indicate that the I/O subsystem is slow, check if the cause is the system being overwhelmed beyond capacity. You can check capacity by looking at I/O counters Disk Bytes/Sec, Disk Read Bytes/Sec, or Disk Write Bytes/Sec. Be sure to check with your System Administrator or hardware vendor for the expected throughput specifications for your SAN (or other I/O subsystem). For example, you can push no more than 200 MB/sec of I/O through a 2 GB/sec HBA card or 2 GB/sec dedicated port on a SAN switch. The expected throughput capacity defined by a hardware manufacturer defines how you proceed from here.
clear
$serverName = $env:COMPUTERNAME
$Counters = @(
("\\$serverName" +"\PhysicalDisk(*)\Disk Bytes/sec"),
("\\$serverName" +"\PhysicalDisk(*)\Disk Read Bytes/sec"),
("\\$serverName" +"\PhysicalDisk(*)\Disk Write Bytes/sec")
)
Get-Counter -Counter $Counters -SampleInterval 2 -MaxSamples 20 | ForEach-Object {
$_.CounterSamples | ForEach-Object {
[pscustomobject]@{
TimeStamp = $_.TimeStamp
Path = $_.Path
Value = ([Math]::Round($_.CookedValue, 3)) }
}
}
Step 4: Is SQL Server driving the heavy I/O activity?
If the I/O subsystem is overwhelmed beyond capacity, find out if SQL Server is the culprit by looking at Buffer Manager: Page Reads/Sec (most common culprit) and Page Writes/Sec (a lot less common) for the specific instance. If SQL Server is the main I/O driver and I/O volume is beyond what the system can handle, then work with the Application Development teams or application vendor to:
- Tune queries, for example: better indexes, update statistics, rewrite queries, and redesign the database.
- Increase max server memory or add more RAM on the system. More RAM will cache more data or index pages without frequently re-reading from disk, which will reduce I/O activity. Increased memory can also reduce
Lazy Writes/sec, which are driven by Lazy Writer flushes when there's a frequent need to store more database pages in the limited memory available. - If you find that page writes are the source of heavy I/O activity, examine
Buffer Manager: Checkpoint pages/secto see if it's due to massive page flushes required to meet recovery interval configuration demands. You can either use Indirect checkpoints to even out I/O over time, or increase hardware I/O throughput.
Causes
In general, the following issues are the high-level reasons why SQL Server queries suffer from I/O latency:
Hardware issues:
A SAN misconfiguration (switch, cables, HBA, storage)
Exceeded I/O capacity (unbalanced throughout the entire SAN network, not just back-end storage)
Drivers or firmware issues
Hardware vendors and/or system administrators need to be engaged at this stage.
Query issues: SQL Server is saturating disk volumes with I/O requests and is pushing the I/O subsystem beyond capacity, which causes I/O transfer rates to be high. In this case, the solution is to find the queries that are causing a high number of logical reads (or writes) and tune those queries to minimize disk I/O-using appropriate indexes is the first step to do that. Also, keep statistics updated as they provide the query optimizer with sufficient information to choose the best plan. Also, incorrect database design and query design can lead to an increase in I/O issues. Therefore, redesigning queries and sometimes tables may help with improved I/O.
Filter drivers: The SQL Server I/O response can be severely impacted if file-system filter drivers process heavy I/O traffic. Proper file exclusions from anti-virus scanning and correct filter driver design by software vendors are recommended to prevent impact on I/O performance.
Other application(s): Another application on the same machine with SQL Server can saturate the I/O path with excessive read or write requests. This situation may push the I/O subsystem beyond capacity limits and cause I/O slowness for SQL Server. Identify the application and tune it or move it elsewhere to eliminate its impact on the I/O stack.
Graphical representation of the methodology
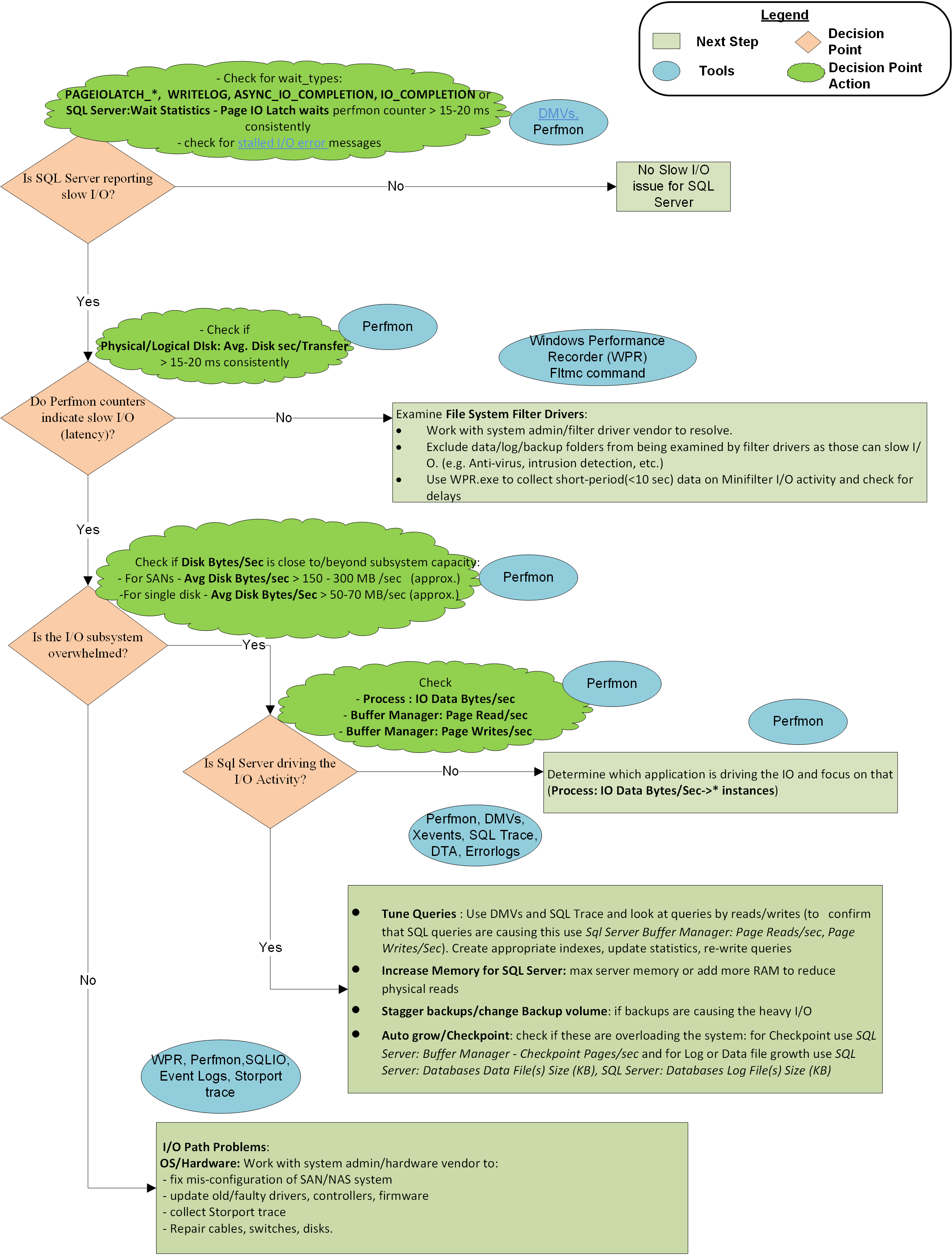
Information on I/O-related wait types
The following are descriptions of the common wait types observed in SQL Server when disk I/O issues are reported.
PAGEIOLATCH_EX
Occurs when a task is waiting on a latch for a data or index page (buffer) in an I/O request. The latch request is in the Exclusive mode. An Exclusive mode is used when the buffer is being written to disk. Long waits may indicate problems with the disk subsystem.
PAGEIOLATCH_SH
Occurs when a task is waiting on a latch for a data or index page (buffer) in an I/O request. The latch request is in the Shared mode. The Shared mode is used when the buffer is being read from the disk. Long waits may indicate problems with the disk subsystem.
PAGEIOLATCH_UP
Occurs when a task is waiting on a latch for a buffer in an I/O request. The latch request is in the Update mode. Long waits may indicate problems with the disk subsystem.
WRITELOG
Occurs when a task is waiting for a transaction log flush to complete. A flush occurs when the Log Manager writes its temporary contents to disk. Common operations that cause log flushes are transaction commits and checkpoints.
Common reasons for long waits on WRITELOG are:
Transaction log disk latency: This is the most common cause of
WRITELOGwaits. Generally, the recommendation is to keep the data and log files on separate volumes. Transaction log writes are sequential writes while reading or writing data from a data file is random. Mixing data and log files on one drive volume (especially conventional spinning disk drives) will cause excessive disk head movement.Too many VLFs: Too many virtual log files (VLFs) can cause
WRITELOGwaits. Too many VLFs can cause other types of issues, such as long recovery.Too many small transactions: While large transactions can lead to blocking, too many small transactions can lead to another set of issues. If you don't explicitly begin a transaction, any insert, delete, or update will result in a transaction (we call this auto transaction). If you do 1,000 inserts in a loop, there will be 1,000 transactions generated. Each transaction in this example needs to commit, which results in a transaction log flush and 1,000 transaction flushes. When possible, group individual update, delete, or insert into a bigger transaction to reduce transaction log flushes and increase performance. This operation can lead to fewer
WRITELOGwaits.Scheduling issues cause Log Writer threads to not get scheduled fast enough: Prior to SQL Server 2016, a single Log Writer thread performed all log writes. If there were issues with thread scheduling (for example, high CPU), both the Log Writer thread and log flushes could get delayed. In SQL Server 2016, up to four Log Writer threads were added to increase the log-writing throughput. See SQL 2016 - It Just Runs Faster: Multiple Log Writer Workers. In SQL Server 2019, up to eight Log Writer threads were added, which improves throughput even more. Also, in SQL Server 2019, each regular worker thread can do log writes directly instead of posting to the Log writer thread. With these improvements,
WRITELOGwaits would rarely be triggered by scheduling issues.
ASYNC_IO_COMPLETION
Occurs when some of the following I/O activities happen:
- The Bulk Insert Provider ("Insert Bulk") uses this wait type when performing I/O.
- Reading Undo file in LogShipping and directing Async I/O for Log Shipping.
- Reading the actual data from the data files during a data backup.
IO_COMPLETION
Occurs while waiting for I/O operations to complete. This wait type generally involves I/Os not related to data pages (buffers). Examples include:
- Reading and writing of sort/hash results from/to disk during a spill (check performance of tempdb storage).
- Reading and writing eager spools to disk (check tempdb storage).
- Reading log blocks from the transaction log (during any operation that causes the log to be read from disk - for example, recovery).
- Reading a page from disk when database isn't set up yet.
- Copying pages to a database snapshot (Copy-on-Write).
- Closing database file and file uncompression.
BACKUPIO
Occurs when a backup task is waiting for data, or is waiting for a buffer to store data. This type isn't typical, except when a task is waiting for a tape mount.