Optimalizace tabulek delta
Spark je architektura paralelního zpracování s daty uloženými na jednom nebo více pracovních uzlech. Soubory Parquet jsou navíc neměnné s novými soubory napsanými pro každou aktualizaci nebo odstranění. Výsledkem tohoto procesu může být, že Spark ukládá data do velkého počtu malých souborů, označovaných jako problém s malým souborem. To znamená, že dotazy nad velkými objemy dat můžou běžet pomalu nebo dokonce selžou dokončení.
OptimizeWrite – funkce
OptimizeWrite je funkce Delta Lake, která snižuje počet souborů při zápisu. Místo psaní mnoha malých souborů zapisuje méně větších souborů. To pomáhá zabránit problémům s malými soubory a zajistit, aby se výkon nezhoršoval.
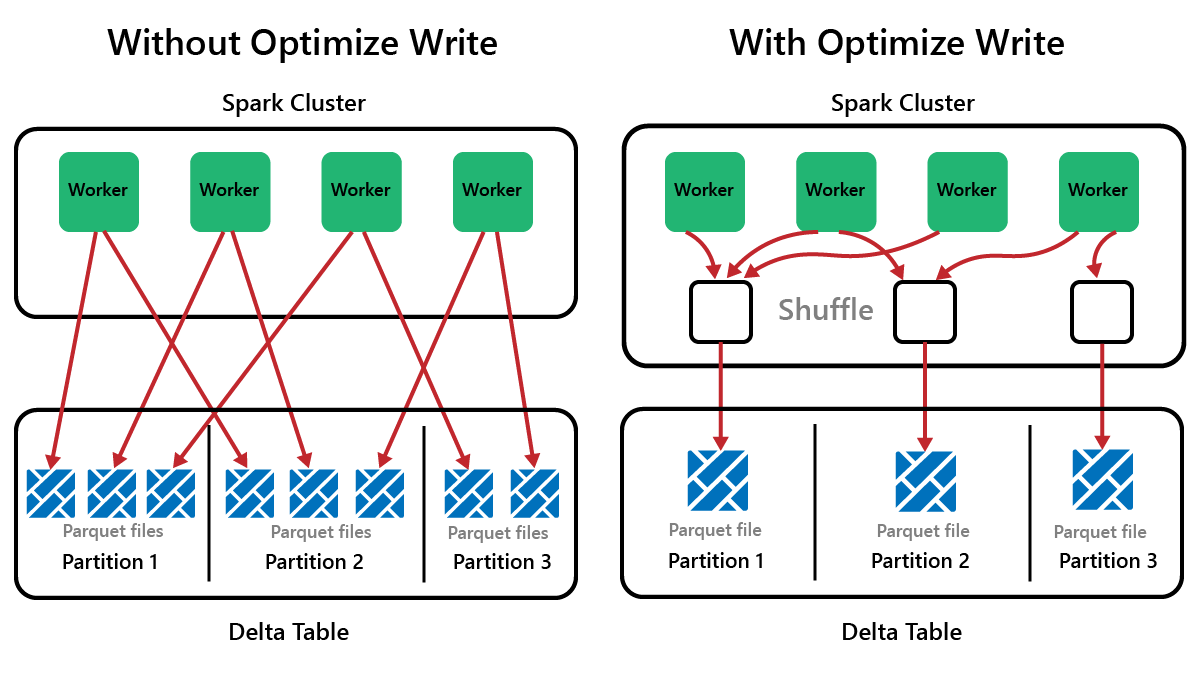
Ve výchozím nastavení je v Microsoft Fabric OptimizeWrite povolená. Můžete ho povolit nebo zakázat na úrovni relace Sparku:
# Disable Optimize Write at the Spark session level
spark.conf.set("spark.microsoft.delta.optimizeWrite.enabled", False)
# Enable Optimize Write at the Spark session level
spark.conf.set("spark.microsoft.delta.optimizeWrite.enabled", True)
print(spark.conf.get("spark.microsoft.delta.optimizeWrite.enabled"))
Poznámka:
OptimizeWrite lze také nastavit ve vlastnostech tabulky a pro jednotlivé příkazy zápisu.
Optimalizovat
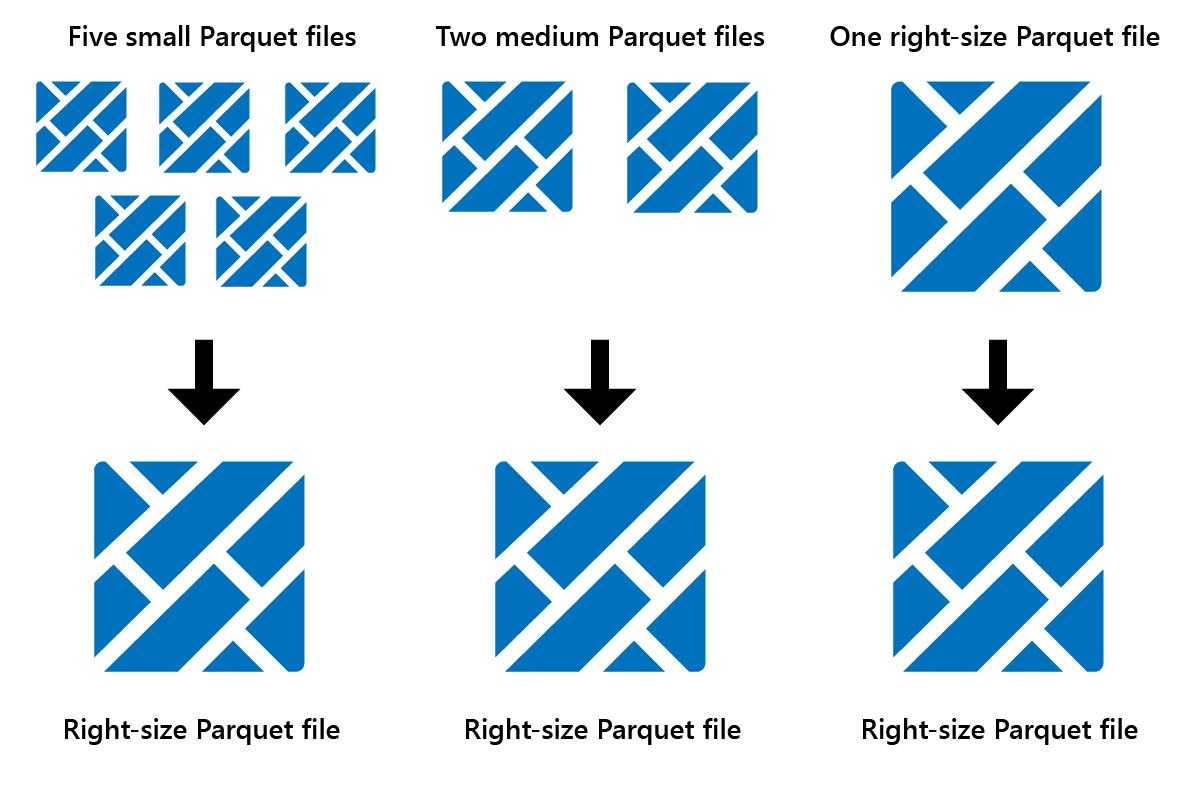
Optimalizace je funkce údržby tabulek, která slučí malé soubory Parquet do méně velkých souborů. Optimalizaci můžete spustit po načtení velkých tabulek, což vede k:
- menší počet větších souborů
- lepší komprese
- efektivní distribuce dat mezi uzly
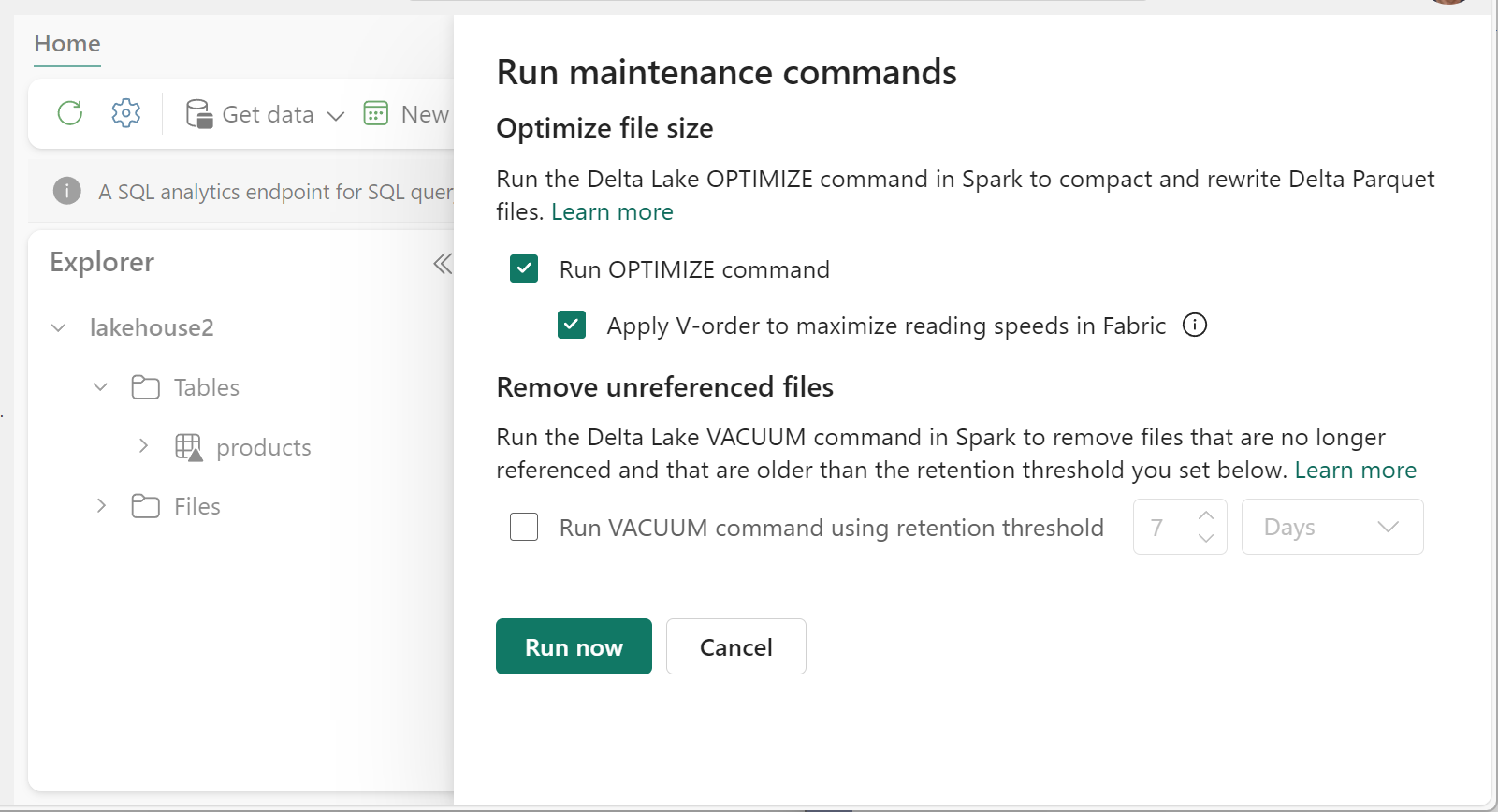
Spuštění optimalizace:
- V Průzkumníku Lakehouse vyberte ... vedle názvu tabulky a vyberte Možnost Údržba.
- Vyberte příkaz Run OPTIMIZE (Spustit optimalizaci).
- Volitelně můžete vybrat Možnost Použít pořadí V pro maximalizaci rychlosti čtení v prostředcích infrastruktury.
- Vyberte Spustit.
Funkce V-Order
Při spuštění optimalizace můžete volitelně spustit V-Order, který je určený pro formát souboru Parquet v prostředcích infrastruktury. V-Order umožňuje bleskově rychlé čtení s dobami přístupu k datům podobným v paměti. Zvyšuje také nákladovou efektivitu, protože během čtení snižuje prostředky sítě, disku a procesoru.
V Microsoft Fabric je ve výchozím nastavení povolená objednávka V a používá se při zápisu dat. Způsobuje menší režii přibližně 15 %, takže zápisy jsou trochu pomalejší. V-Order ale umožňuje rychlejší čtení z výpočetních modulů Microsoft Fabric, jako jsou Power BI, SQL, Spark a další.
V Microsoft Fabric používají moduly Power BI a SQL technologii Microsoft Verti-Scan, která využívá plnou výhodu optimalizace V-Order ke zrychlení čtení. Spark a další moduly nepoužívají technologii VertiScan, ale stále využívají optimalizaci objednávek V o 10 % rychlejších čtení, někdy až o 50 %.
Pořadí V-Order funguje použitím speciálního řazení, distribuce skupiny řádků, kódování slovníku a komprese u souborů Parquet. Je 100% kompatibilní s opensourcovým formátem Parquet a všechny moduly Parquet ho mohou číst.
V-Order nemusí být přínosné pro scénáře náročné na zápis, jako jsou například přípravná úložiště dat, kde se data čtou jen jednou nebo dvakrát. V těchto situacích může zakázání V-Order zkrátit celkovou dobu zpracování příjmu dat.
Spuštěním OPTIMIZE příkazu použijte pořadí V-Order u jednotlivých tabulek pomocí funkce Údržba tabulek.
Vacuum
Příkaz VACUUM umožňuje odebrat staré datové soubory.
Při každé aktualizaci nebo odstranění se vytvoří nový soubor Parquet a v transakčním protokolu se vytvoří položka. Staré soubory Parquet se zachovají, aby bylo možné povolit časová cesta, což znamená, že se soubory Parquet hromadí v průběhu času.
Příkaz VACUUM odebere staré datové soubory Parquet, ale ne transakční protokoly. Když spustíte vakuum, nemůžete čas vrátit zpět, než je doba uchovávání informací.
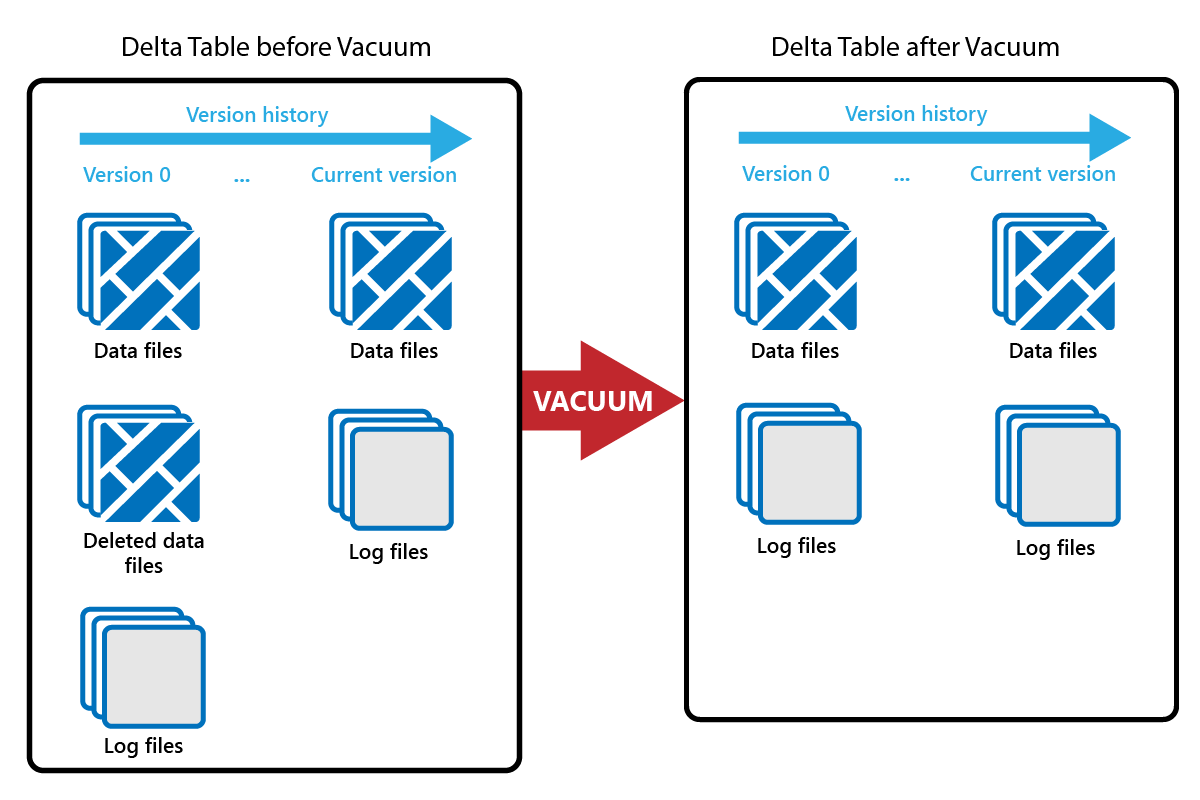
Datové soubory, na které se v transakčním protokolu aktuálně neodkazují a které jsou starší než zadaná doba uchovávání, se trvale odstraní spuštěním funkce VACUUM. Zvolte dobu uchovávání na základě faktorů, jako jsou:
- Požadavky na uchovávání dat
- Náklady na velikost dat a úložiště
- Frekvence změn dat
- Zákonné požadavky
Výchozí doba uchovávání je 7 dnů (168 hodin) a systém vám brání v používání kratší doby uchovávání.
Pomocí poznámkových bloků Fabric můžete spouštět úklid ad hoc nebo naplánovat.
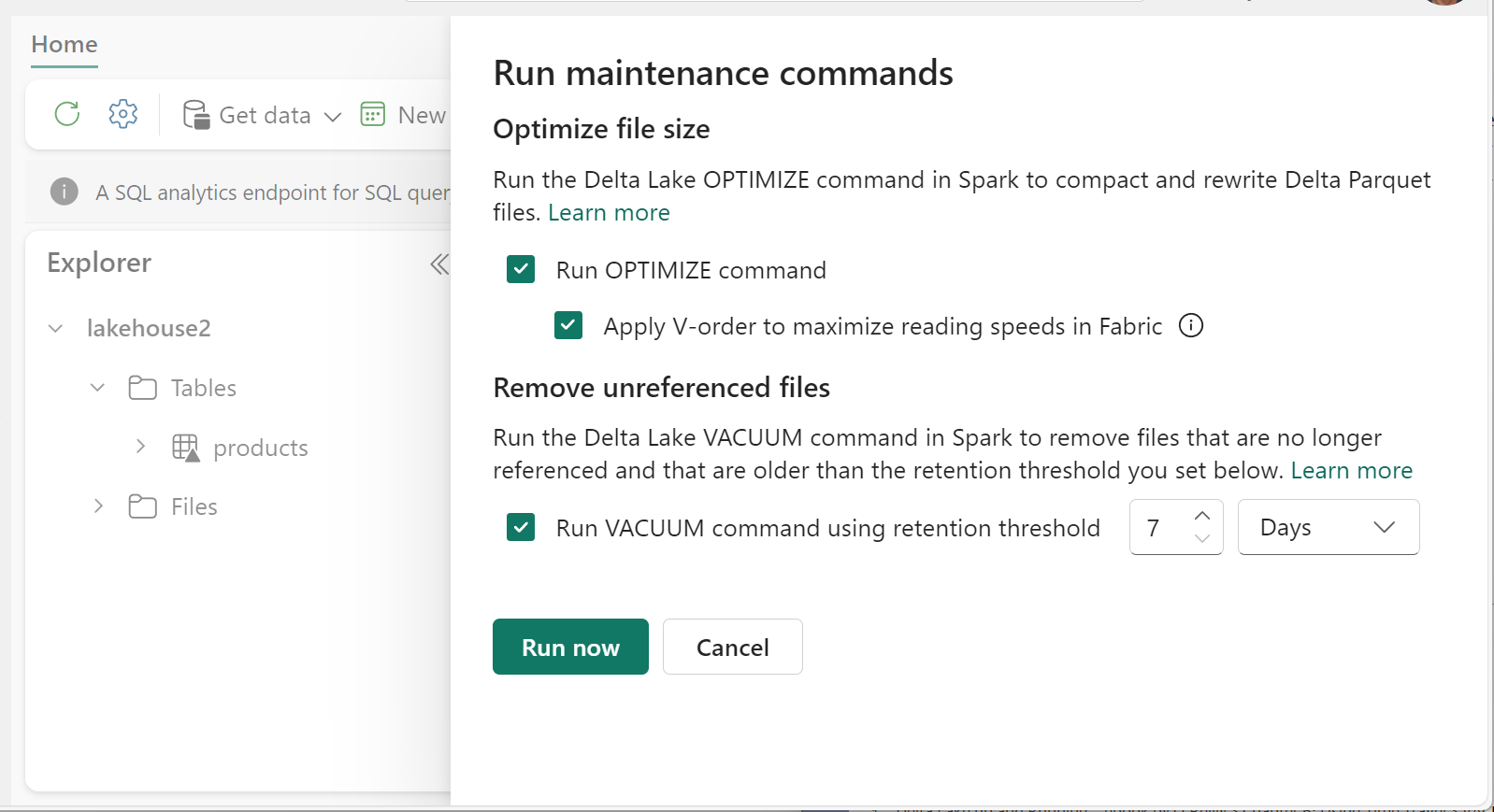
Spusťte funkci ÚKLIDu u jednotlivých tabulek pomocí funkce Údržba tabulek:
- V Průzkumníku Lakehouse vyberte ... vedle názvu tabulky a vyberte Možnost Údržba.
- Vyberte Příkaz Spustit vakuum s použitím prahové hodnoty uchovávání a nastavte prahovou hodnotu uchovávání.
- Vyberte Spustit.
V poznámkovém bloku můžete také spustit vakuum jako příkaz SQL:
%%sql
VACUUM lakehouse2.products RETAIN 168 HOURS;
Vakuové potvrzení do transakčního protokolu Delta, takže můžete zobrazit předchozí spuštění v ČÁSTI DESCRIBE HISTORY.
%%sql
DESCRIBE HISTORY lakehouse2.products;
Dělení tabulek Delta
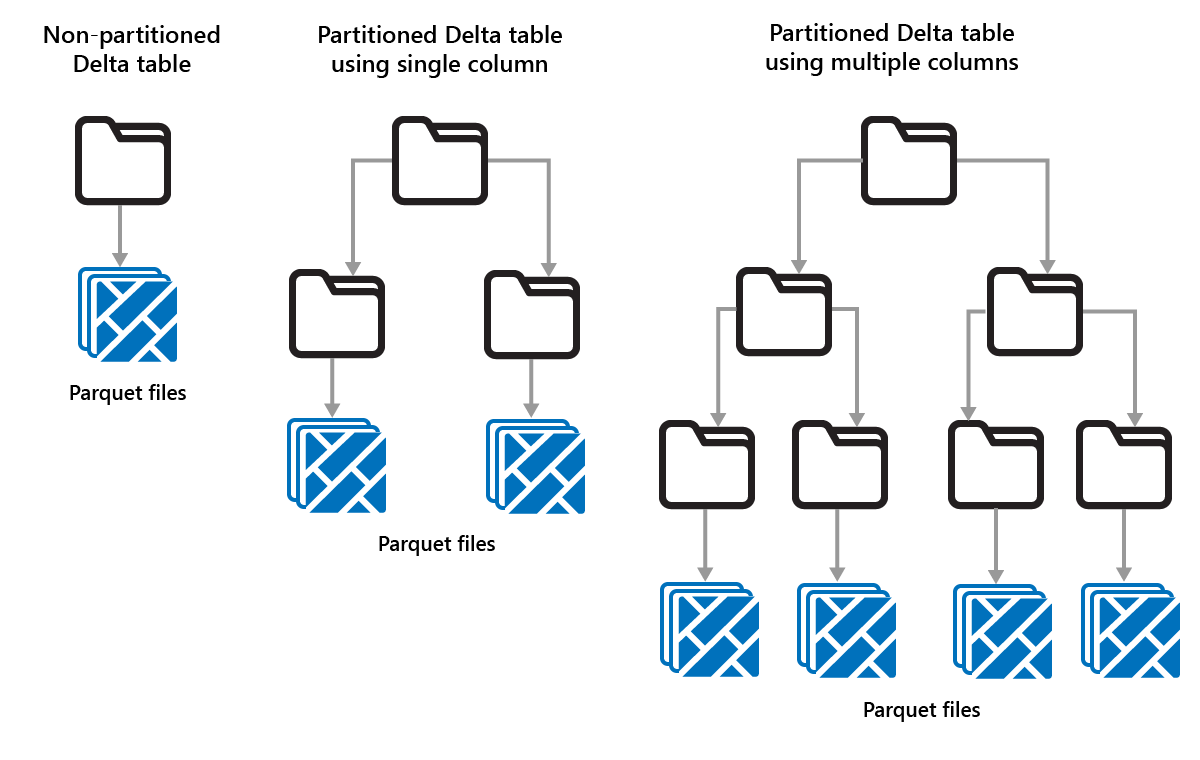
Delta Lake umožňuje uspořádat data do oddílů. To může zvýšit výkon povolením přeskočení dat, což zvyšuje výkon přeskočením irelevantních datových objektů na základě metadat objektu.
Představte si situaci, kdy se ukládají velké objemy prodejních dat. Data o prodeji můžete rozdělit podle roku. Oddíly jsou uložené v podsložkách s názvem year=2021, year=2022 atd. Pokud chcete vykazovat pouze údaje o prodeji za rok 2024, můžete oddíly pro jiné roky přeskočit, což zlepšuje výkon čtení.
Dělení malých objemů dat ale může snížit výkon, protože zvyšuje počet souborů a může zhoršit "problém s malými soubory".
Dělení použijte v případech:
- Máte velmi velké objemy dat.
- Tabulky je možné rozdělit do několika velkých oddílů.
Nepoužívejte dělení, když:
- Objemy dat jsou malé.
- Sloupec dělení má vysokou kardinalitu, protože tím se vytvoří velký počet oddílů.
- Dělení sloupce by vedlo k několika úrovním.
Oddíly představují pevné rozložení dat a nepřizpůsobují se různým vzorům dotazů. Při zvažování, jak používat dělení, zamyslete se nad tím, jak se vaše data používají, a jejich členitost.
V tomto příkladu je datový rámec obsahující data produktu rozdělený podle kategorie:
df.write.format("delta").partitionBy("Category").saveAsTable("partitioned_products", path="abfs_path/partitioned_products")
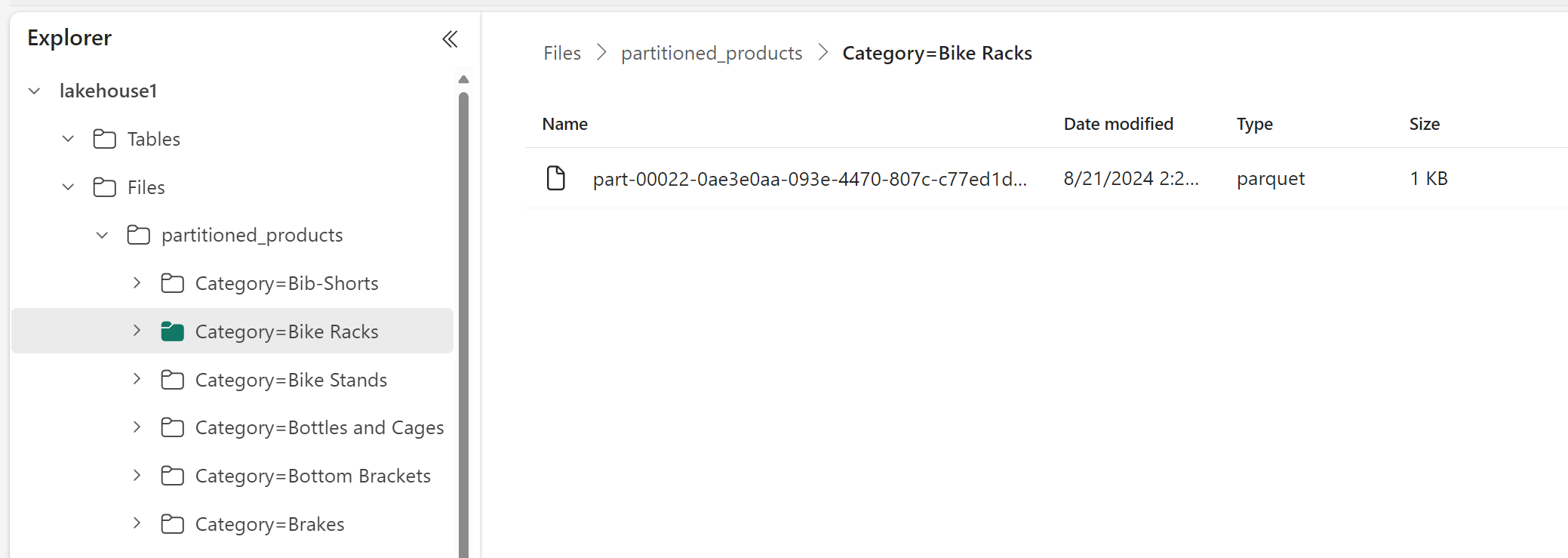
V Průzkumníku Lakehouse můžete vidět, že data jsou dělenou tabulkou.
- Tabulka obsahuje jednu složku s názvem "partitioned_products".
- Pro každou kategorii existují podsložky, například Category=Bike Racks atd.
Pomocí SQL můžeme vytvořit podobnou dělenou tabulku:
%%sql
CREATE TABLE partitioned_products (
ProductID INTEGER,
ProductName STRING,
Category STRING,
ListPrice DOUBLE
)
PARTITIONED BY (Category);