Principy Delta Lake
Delta Lake je opensourcová vrstva úložiště, která přidává sémantiku relační databáze ke zpracování datového jezera založeného na Sparku. Tabulky v Microsoft Fabric Lakehouses jsou tabulky Delta, které jsou znaménkem trojúhelníkové ikony Delta (Δ) u tabulek v uživatelském rozhraní lakehouse.
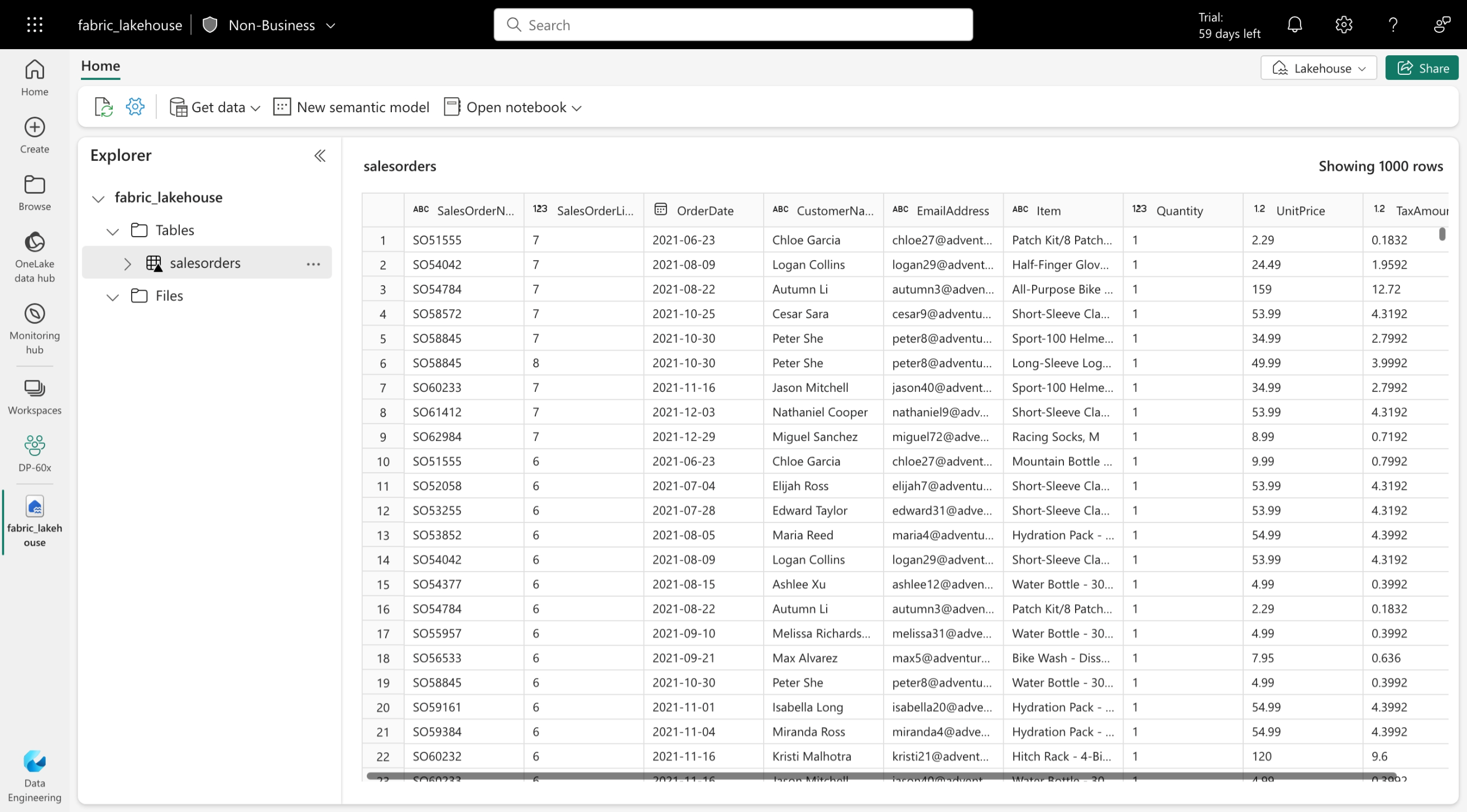
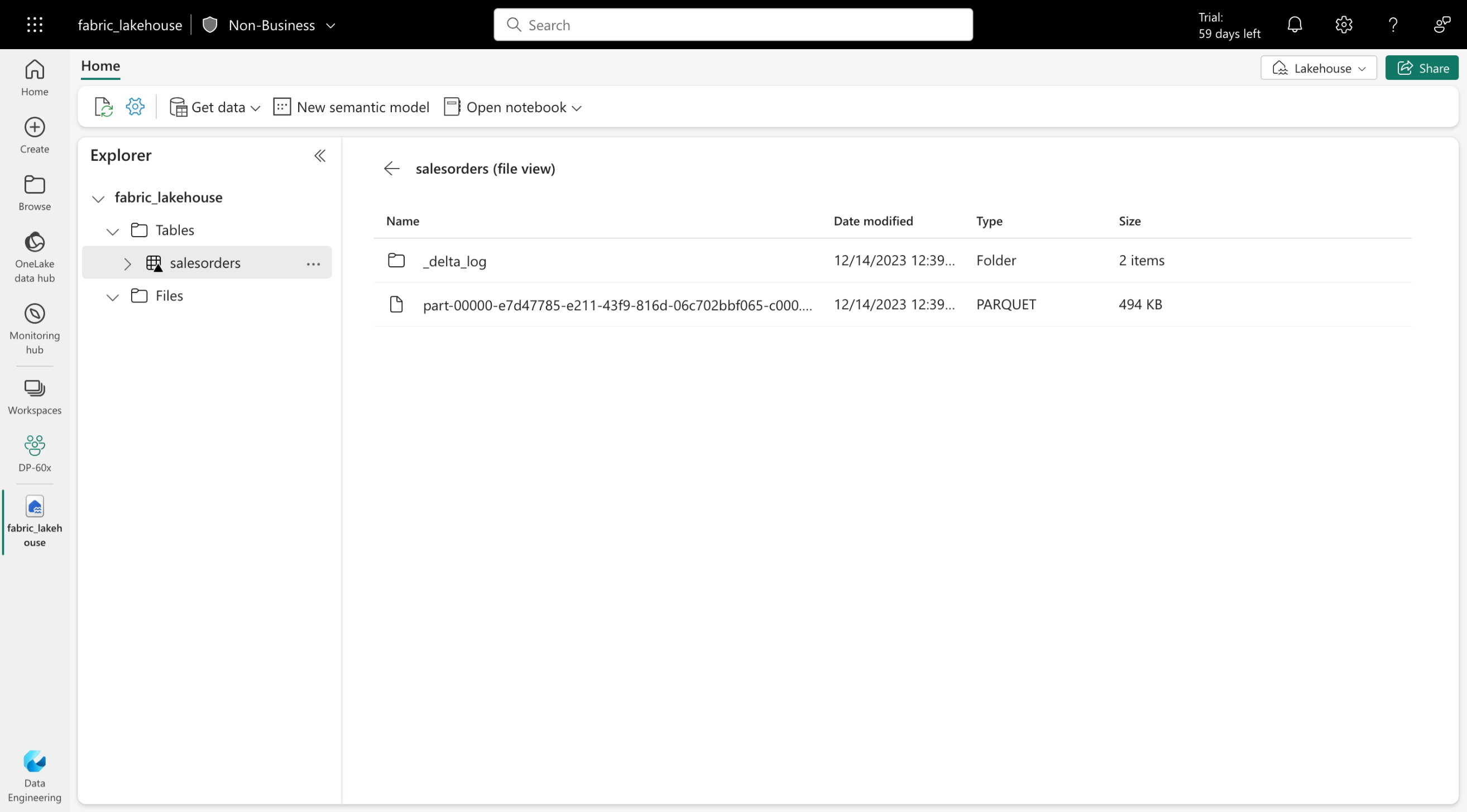
Tabulky Delta jsou abstrakce schématu u datových souborů uložených ve formátu Delta. Pro každou tabulku ukládá lakehouse složku obsahující datové soubory Parquet a složku _delta_Log , ve které jsou podrobnosti transakce protokolovány ve formátu JSON.
Mezi výhody používání tabulek Delta patří:
- Relační tabulky, které podporují dotazování a úpravy dat. Pomocí Apache Sparku můžete ukládat data do tabulek Delta, které podporují operace CRUD (vytváření, čtení, aktualizace a odstraňování). Jinými slovy, můžete vybrat, vložit, aktualizovat a odstranit řádky dat stejným způsobem jako v relačním databázovém systému.
- Podpora transakcí ACID. Relační databáze jsou navrženy tak, aby podporovaly úpravy transakčních dat, které poskytují atomicitu (transakce jsou dokončeny jako jedna jednotka práce), konzistence (transakce opouštějí databázi v konzistentním stavu), izolaci (transakce v procesu nemohou vzájemně narušovat) a stálost (po dokončení transakce, provedené změny se zachovají). Delta Lake přináší do Sparku stejnou transakční podporu implementací transakčního protokolu a vynucením serializovatelné izolace pro souběžné operace.
- Správa verzí dat a doba trvání Vzhledem k tomu, že všechny transakce jsou protokolovány v transakčním protokolu, můžete sledovat více verzí každého řádku tabulky a dokonce použít funkci časového cestování k načtení předchozí verze řádku v dotazu.
- Podpora dávkových a streamovaných dat Většina relačních databází sice obsahuje tabulky, které ukládají statická data, ale Spark zahrnuje nativní podporu streamování dat prostřednictvím rozhraní API strukturovaného streamování Sparku. Tabulky Delta Lake je možné použít jako jímky (cíle) i zdroje pro streamovaná data.
- Standardní formáty a interoperabilita. Podkladová data tabulek Delta jsou uložená ve formátu Parquet, který se běžně používá v kanálech příjmu dat Data Lake. Kromě toho můžete použít koncový bod analýzy SQL pro Microsoft Fabric Lakehouse k dotazování tabulek Delta v SQL.