Prozkoumání architektury řešení
Než začneme, pojďme se podívat na architekturu, abychom porozuměli všem požadavkům. Přenesení modelu do produkčního prostředí znamená, že potřebujete škálovat řešení a spolupracovat s ostatními týmy. Společně s datovými vědci, datovými inženýry a týmem infrastruktury jste se rozhodli použít následující přístup:
- Všechna data budou uložená ve službě Azure Blob Storage, kterou bude spravovat datový inženýr.
- Tým infrastruktury vytvoří potřebné prostředky Azure, jako je pracovní prostor Azure Machine Learning.
- Datový vědec se zaměří na vnitřní smyčku: vývoj a trénování modelu.
- Technik strojového učení vezme natrénovaný model a nasadí ho ve vnější smyčce.
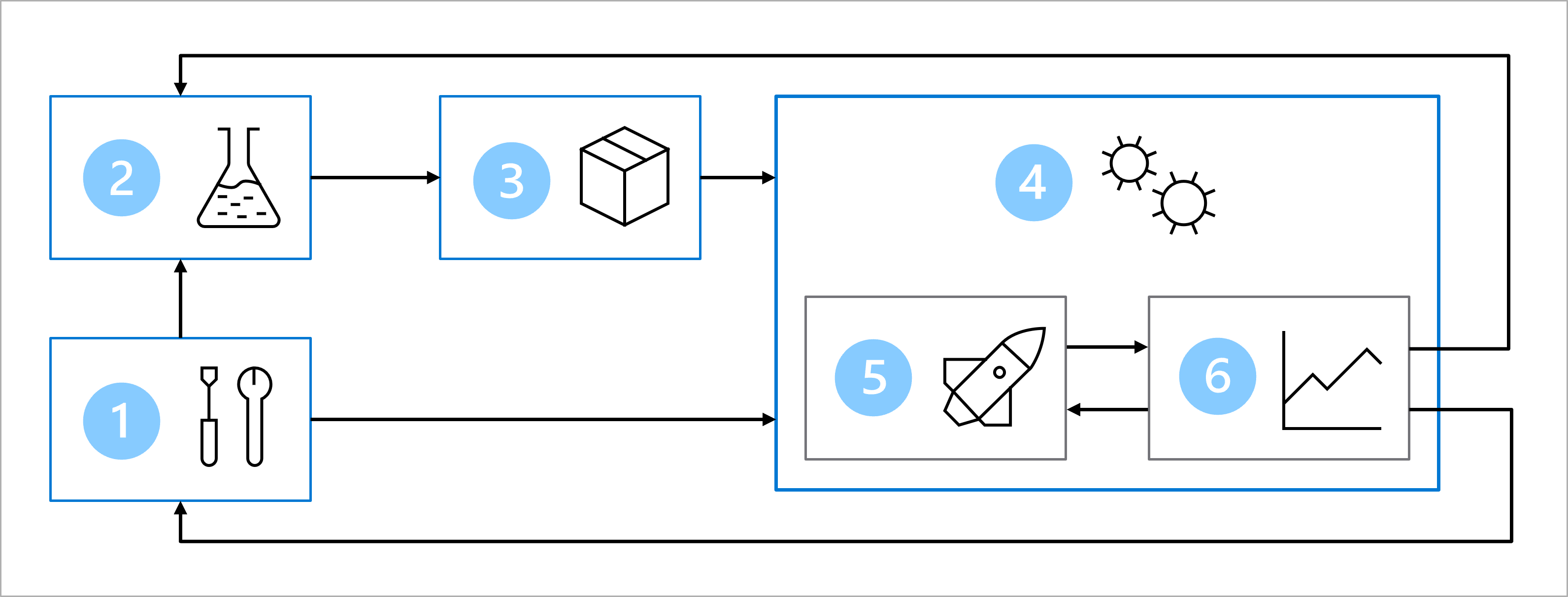
Společně s větším týmem jste navrhli architekturu pro dosažení operací strojového učení (MLOps).
Poznámka:
Diagram je zjednodušená reprezentace architektury MLOps. Pokud chcete zobrazit podrobnější architekturu, prozkoumejte různé případy použití v akcelerátoru řešení MLOps (v2).
Hlavním cílem architektury MLOps je vytvořit robustní a reprodukovatelné řešení. K dosažení toho, že architektura zahrnuje:
- Nastavení: Vytvořte všechny potřebné prostředky Azure pro řešení.
- Vývoj modelů (vnitřní smyčka):Prozkoumejte a zpracujte data pro trénování a vyhodnocení modelu.
- Kontinuální integrace: Zabalte a zaregistrujte model.
- Nasazení modelu (vnější smyčka): Nasaďte model.
- Průběžné nasazování: Otestujte model a propagujte ho do produkčního prostředí.
- Monitorování: Monitorování výkonu modelu a koncového bodu
V tomto okamžiku ve vašem projektu se vytvoří pracovní prostor Azure Machine Learning, data se ukládají ve službě Azure Blob Storage a tým datových věd model vytrénoval.
Chcete přejít z vnitřní smyčky a vývoje modelu na vnější smyčku nasazením modelu do produkčního prostředí. Proto je potřeba převést výstup týmu datových věd na robustní a reprodukovatelný kanál ve službě Azure Machine Learning.
Zajištění, aby se veškerý kód uložil jako skripty a spouštěl skripty jako úlohy Azure Machine Learning, usnadní automatizaci trénování modelů a opětovné trénování modelu v budoucnu.
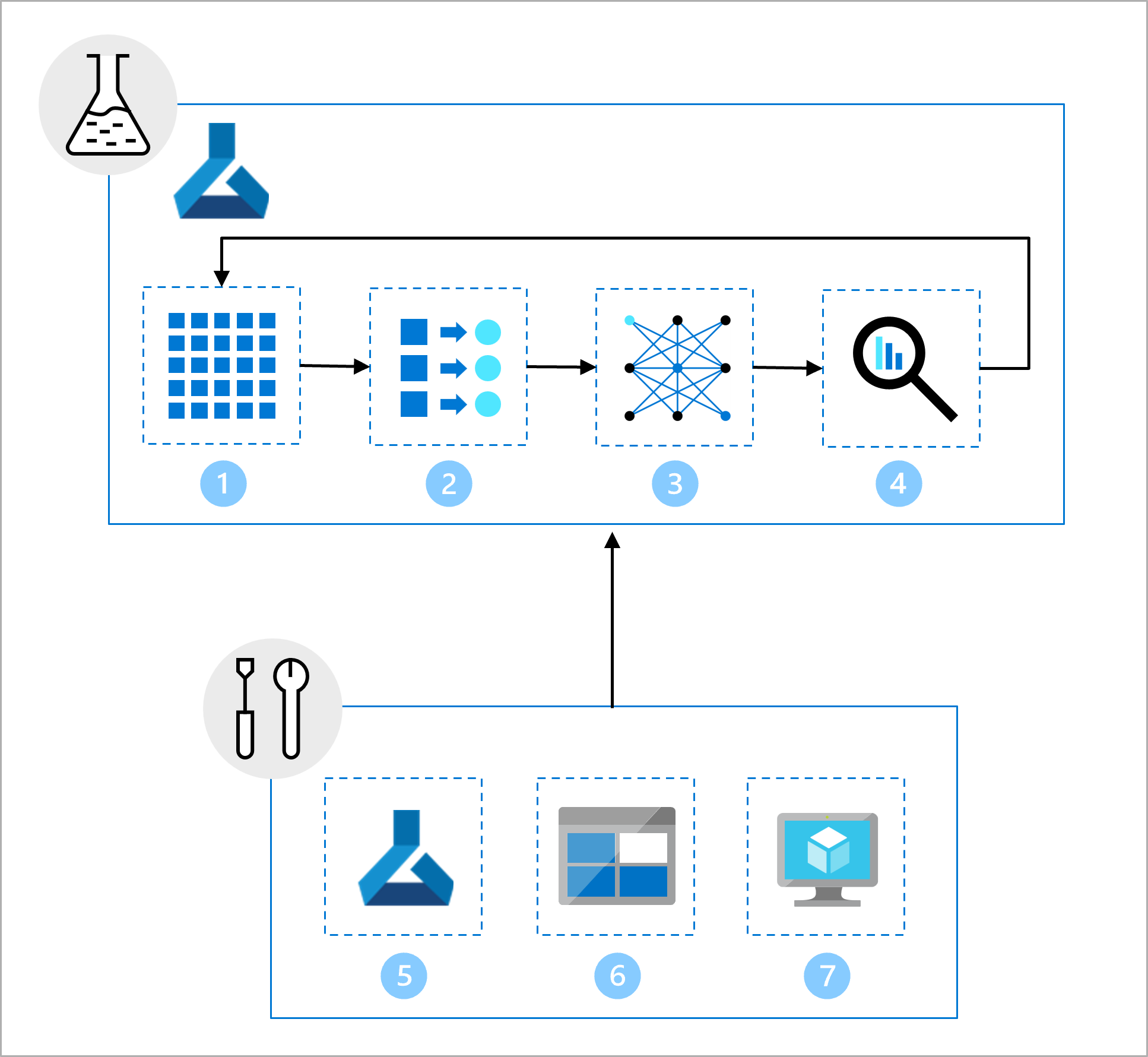
Tým datových věd pracuje na vývoji modelů. Poskytují vám poznámkový blok Jupyter, který obsahuje následující úlohy:
- Přečtěte si data a prozkoumejte je.
- Proveďte přípravu funkcí.
- Trénování modelu
- Vyhodnoťte model.
V rámci nastavení vytvořil tým infrastruktury:
- Pracovní prostor pro vývoj (vývoj) služby Azure Machine Learning, který může použít tým datových věd k prozkoumání a experimentování.
- Datový prostředek v pracovním prostoru, který odkazuje na složku ve službě Azure Blob Storage obsahující data.
- Výpočetní prostředky potřebné ke spouštění poznámkových bloků a skriptů
Vaším prvním úkolem k MLOps je převést práci od datových vědců, abyste mohli snadno automatizovat vývoj modelů. Zatímco tým datových věd pracoval v poznámkovém bloku Jupyter, musíte použít skripty a spouštět je pomocí úloh Azure Machine Learning. Vstupem úlohy bude datový prostředek vytvořený týmem infrastruktury, který odkazuje na data umístěná ve službě Azure Blob Storage připojené k pracovnímu prostoru Azure Machine Learning.