Seznámení se Sparkem
Pokud chcete lépe porozumět tomu, jak zpracovávat a analyzovat data pomocí Apache Sparku v Azure Databricks, je důležité porozumět základní architektuře.
Podrobný přehled
Od vysoké úrovně služba Azure Databricks spouští a spravuje clustery Apache Spark v rámci vašeho předplatného Azure. Clustery Apache Spark jsou skupiny počítačů, které jsou považovány za jeden počítač a zpracovávají provádění příkazů vydaných z poznámkových bloků. Clustery umožňují paralelizovat zpracování dat napříč mnoha počítači, aby se zlepšilo škálování a výkon. Skládají se z ovladače Sparku a pracovních uzlů. Uzel ovladače odesílá práci do pracovních uzlů a dává jim pokyn, aby načítá data ze zadaného zdroje dat.
V Databricks je rozhraní poznámkového bloku obvykle program ovladače. Tento program ovladače obsahuje hlavní smyčku pro program a vytvoří v clusteru distribuované datové sady a pak na tyto datové sady použije operace. Programy ovladačů přistupují k Apache Sparku prostřednictvím objektu SparkSession bez ohledu na umístění nasazení.
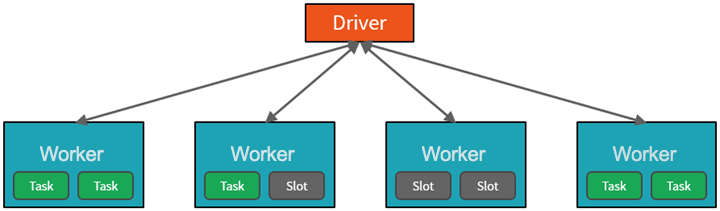
Microsoft Azure spravuje cluster a podle potřeby ho automaticky škáluje na základě vašeho využití a nastavení použitého při konfiguraci clusteru. Automatické ukončení je také možné povolit, což Azure umožňuje ukončit cluster po zadaném počtu minut nečinnosti.
Úlohy Sparku podrobně
Práce odeslaná do clusteru se rozdělí na libovolný počet nezávislých úloh. Tímto způsobem se distribuuje práce mezi uzly clusteru. Úlohy jsou dále rozdělené na úkoly. Vstup do úlohy je rozdělený do jednoho nebo více oddílů. Tyto oddíly jsou jednotkou práce pro každý slot. Mezi úkoly může být potřeba změnit uspořádání oddílů a sdílet je přes síť.
Tajný kód pro vysoký výkon Sparku je paralelismus. Vertikální škálování (přidáním prostředků do jednoho počítače) je omezené na omezenou velikost paměti RAM, vláken a procesoru, ale clustery se škálují horizontálně a podle potřeby do clusteru přidávají nové uzly.
Spark paralelizuje úlohy na dvou úrovních:
- První úrovní paralelizace je exekutor – virtuální počítač Java (JVM) běžící na pracovním uzlu, obvykle jedna instance na uzel.
- Druhou úrovní paralelizace je slot – počet, jehož počet je určen počtem jader a procesorů každého uzlu.
- Každý exekutor má více slotů, ke kterým je možné přiřadit paralelizované úlohy.
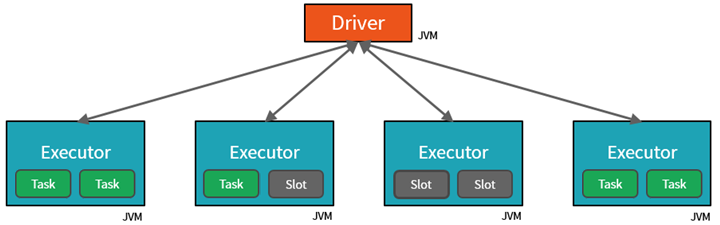
JVM je přirozeně vícevláknový, ale jeden JVM, například ten, který koordinuje práci na ovladači, má konečný horní limit. Rozdělením práce na úkoly může ovladač přiřadit jednotky práce *slotům v exekutorech na pracovních uzlech pro paralelní spuštění. Kromě toho ovladač určuje, jak rozdělit data tak, aby je bylo možné distribuovat pro paralelní zpracování. Ovladač tedy každému úkolu přiřadí oddíl dat, aby každý úkol věděl, která část dat se má zpracovat. Po spuštění načte každý úkol oddíl dat přiřazených k němu.
Úlohy a fáze
V závislosti na prováděné práci může být vyžadováno několik paralelizovaných úloh. Každá úloha je rozdělená do fází. Užitečnou analogií je představit si, že úkolem je sestavit dům:
- První fází by bylo položit základ.
- Druhá fáze by byla postavit stěny.
- Třetí fází by bylo přidat střechu.
Když se pokusíte provést některý z těchto kroků mimo pořadí, nedá smysl a může být ve skutečnosti nemožné. Podobně Spark rozdělí jednotlivé úlohy do fází, aby se zajistilo, že všechno probíhá ve správném pořadí.
Modularita
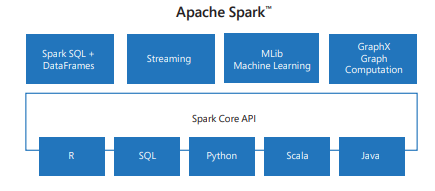
Spark obsahuje knihovny pro úlohy od SQL až po streamování a strojové učení, což z něj dělá nástroj pro úlohy zpracování dat. Mezi knihovny Sparku patří:
- Spark SQL: Práce se strukturovanými daty
- SparkML: Pro strojové učení.
- GraphX: Pro zpracování grafů.
- Streamování Sparku: Pro zpracování dat v reálném čase.
Kompatibilita
Spark může běžet na různých distribuovaných systémech, včetně Hadoop YARN, Apache Mesos, Kubernetes nebo vlastního správce clusteru Sparku. Také čte z různých zdrojů dat a zapisuje je do různých zdrojů dat, jako je HDFS, Cassandra, HBase a Amazon S3.