Posouzení klasifikačního modelu
Velkou částí strojového učení je posouzení toho, jak dobře modely fungují. Toto posouzení probíhá během trénování, pomáhá utvářet model a po trénování, abychom mohli posoudit, jestli je model v pořádku používat v reálném světě. Klasifikační modely potřebují posouzení, stejně jako regresní modely, i když způsob, jakým toto hodnocení děláme, může být někdy trochu složitější.
Aktualizace nákladů
Mějte na paměti, že během trénování vypočítáme, jak špatně model funguje, a zavoláme tyto náklady nebo ztrátu. Například v lineární regresi často používáme metriku s názvem střední kvadratická chyba (MSE). MSE se vypočítá porovnáním predikce a skutečného popisku, squaringem rozdílu a průměrem výsledku. MsE můžeme použít k přizpůsobení modelu a k hlášení o tom, jak dobře funguje.
Nákladové funkce pro klasifikaci
Klasifikační modely jsou hodnoceny buď podle pravděpodobností výstupu, například 40% pravděpodobností laviny, nebo konečných popisků ,no avalanche nebo avalanche. Použití pravděpodobností výstupu může být výhodné během trénování. Mírné změny modelu se projeví ve změnách pravděpodobností, i když nestačí ke změně konečného rozhodnutí. Použití konečných popisků pro nákladovou funkci je užitečnější, pokud chceme odhadnout skutečný výkon našeho modelu. Například v testovací sadě. Protože pro reálné použití používáme konečné popisky, nikoli pravděpodobnosti.
Ztráta protokolu
Ztráta protokolu je jednou z nejoblíbenějších nákladových funkcí pro jednoduchou klasifikaci. U výstupních pravděpodobností se použije ztráta protokolu. Podobně jako MSE mají malé objemy chyb za následek malé náklady, zatímco mírné množství chyb vede k velkým nákladům. V následujícím grafu vykreslujeme ztrátu protokolu pro popisek, kde byla správná odpověď 0 (false).
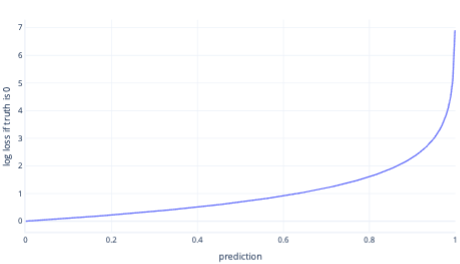
Osa x zobrazuje možné výstupy modelu – pravděpodobnosti od 0 do 1 – a osa y zobrazuje náklady. Pokud má model vysokou jistotu, že správná odpověď je 0 (například predikce 0,1). Náklady jsou pak nízké, protože v této instanci je správná odpověď 0. Pokud model s jistotou predikuje výsledek špatně (například predikuje hodnotu 0,9), pak se náklady stanou vysokou. Ve skutečnosti jsou náklady na x=1 tak vysoké, že ořízíme osu x zde na 0,999, aby graf byl čitelný.
Proč ne MSE?
MsE a ztráta protokolů jsou podobné metriky. Existuje několik složitých důvodů, proč je ztráta protokolů upřednostňována pro logistickou regresi, ale některé jednodušší důvody. Například ztráta protokolu trestá nesprávné odpovědi mnohem silněji než MSE. Například v následujícím grafu, kde je správná odpověď 0, mají předpovědi nad 0,8 vyšší náklady na ztrátu protokolů než MSE.
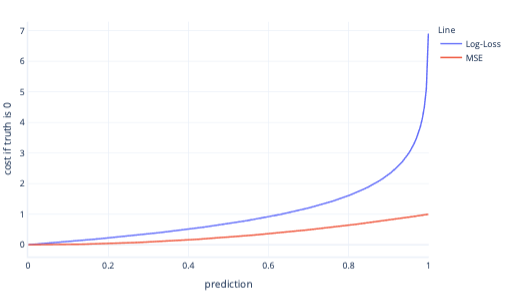
Vyšší náklady tímto způsobem pomáhají modelu rychleji se učit kvůli strmějšímu přechodu přímky. Podobně ztráta protokolů pomáhá modelům, aby získaly větší jistotu při poskytování správné odpovědi. Všimněte si v předchozím grafu, že náklady MSE na hodnoty menší než 0,2 jsou malé a přechod je téměř plochý. Tento vztah zpomaluje trénování pro modely, které jsou téměř správné. Ztráta protokolu má pro tyto hodnoty strmý přechod, který pomáhá modelu rychleji se učit.
Omezení nákladových funkcí
Použití jedné nákladové funkce pro lidské posouzení modelu je vždy omezené, protože vám neřekne, jaké chyby model dělá. Představte si například náš scénář předpovědi laviny. Vysoká hodnota ztráty protokolu může znamenat, že model opakovaně predikuje laviny, pokud neexistují žádné. Nebo to může znamenat, že se opakovaně nedaří předpovědět laviny, které se dějí.
Abychom lépe porozuměli našim modelům, může být snazší použít více než jedno číslo k vyhodnocení, jestli dobře fungují. Tento větší předmět probereme v jiných výukových materiálech, i když se na něj podíváme v následujících cvičeních.