Seznámení s Apache Sparkem
Apache Spark je architektura pro zpracování distribuovaných dat, která umožňuje rozsáhlé analýzy dat tím, že koordinuje práci napříč několika uzly zpracování v clusteru.
Jak Spark funguje
Aplikace Apache Spark běží v clusteru jako nezávislé sady procesů, které koordinuje objekt SparkContext v hlavním programu (nazývá se program ovladače). SparkContext se připojí ke správci clusteru, který přiděluje prostředky napříč aplikacemi pomocí implementace Apache Hadoop YARN. Po připojení Spark získá exekutory na uzlech v clusteru, aby se spustil kód aplikace.
SparkContext spustí hlavní funkci a paralelní operace na uzlech clusteru a pak shromáždí výsledky operací. Uzly čtou a zapisují data ze systému souborů a ukládají do mezipaměti transformovaná data v paměti jako odolné distribuované datové sady (RDD).
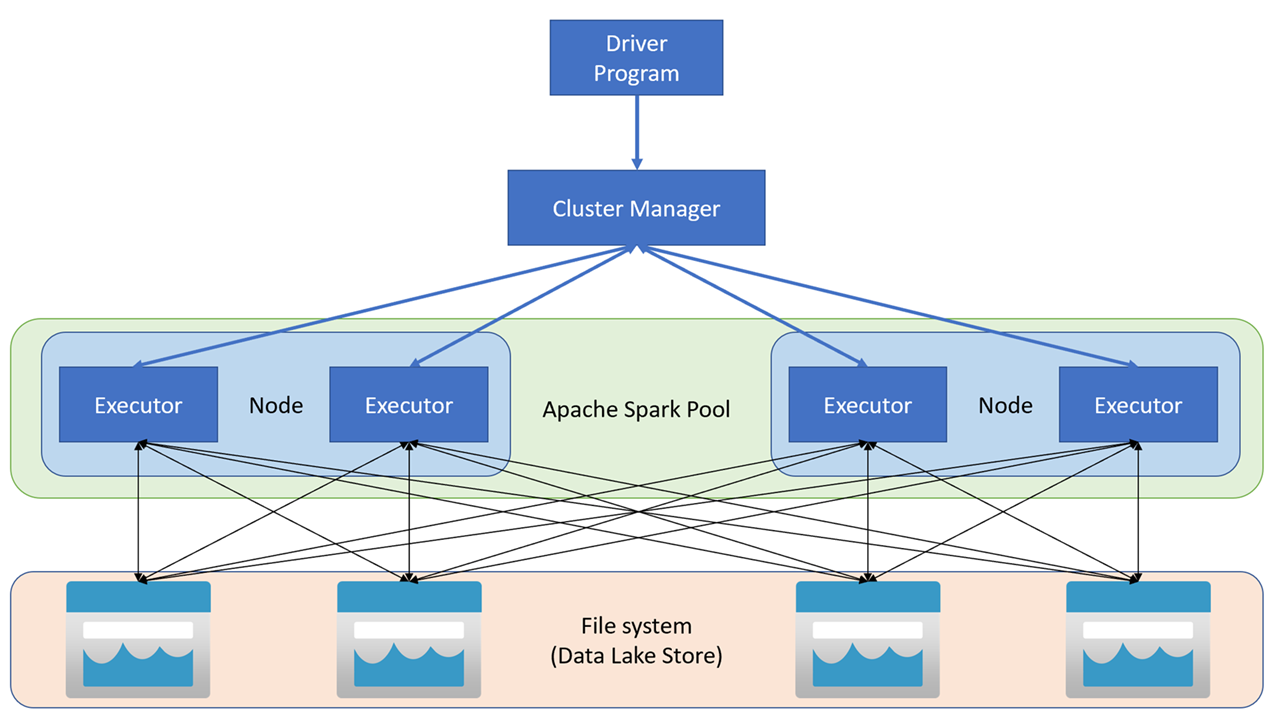
SparkContext zodpovídá za převod aplikace na směrovaný acyklický graf (DAG). Graf se skládá z jednotlivých úloh, které se provádějí v rámci procesu exekutoru na uzlech. Každá aplikace získá vlastní procesy exekutora, které zůstávají v provozu po dobu trvání celé aplikace a spouští úlohy ve více vláknech.
Fondy Sparku ve službě Azure Synapse Analytics
V Azure Synapse Analytics se cluster implementuje jako fond Sparku, který poskytuje modul runtime pro operace Sparku. Jeden nebo více fondů Sparku můžete vytvořit v pracovním prostoru Azure Synapse Analytics pomocí webu Azure Portal nebo v nástroji Azure Synapse Studio. Při definování fondu Sparku můžete zadat možnosti konfigurace pro fond, mezi které patří:
- Název fondu Spark.
- Velikost virtuálního počítače používaného pro uzly ve fondu, včetně možnosti používat uzly s podporou GPU s akcelerovaným hardwarem.
- Počet uzlů ve fondu a to, jestli je velikost fondu pevná nebo jednotlivé uzly se dají dynamicky převést do online režimu pro automatické škálování clusteru. V takovém případě můžete zadat minimální a maximální počet aktivních uzlů.
- Verze modulu Runtime Sparku, která se má použít ve fondu, která určuje verze jednotlivých komponent, jako je Python, Java a další, které se nainstalují.
Tip
Další informace o možnostech konfigurace fondu Sparku najdete v tématu Konfigurace fondu Apache Spark ve službě Azure Synapse Analytics v dokumentaci k Azure Synapse Analytics.
Fondy Sparku v pracovním prostoru Azure Synapse Analytics jsou bezserverové – spouští se na vyžádání a zastavují se při nečinnosti.