Datové soubory oddílů
Dělení je technika optimalizace, která umožňuje Sparku maximalizovat výkon napříč pracovními uzly. Při filtrování dat v dotazech je možné dosáhnout vyššího zvýšení výkonu odstraněním nepotřebných vstupně-výstupních operací disku.
Rozdělení výstupního souboru
Pokud chcete datový rámec uložit jako dělenou sadu souborů, použijte při zápisu dat metodu partitionBy .
Následující příklad vytvoří odvozené pole Year . Pak ho použije k rozdělení dat.
from pyspark.sql.functions import year, col
# Load source data
df = spark.read.csv('/orders/*.csv', header=True, inferSchema=True)
# Add Year column
dated_df = df.withColumn("Year", year(col("OrderDate")))
# Partition by year
dated_df.write.partitionBy("Year").mode("overwrite").parquet("/data")
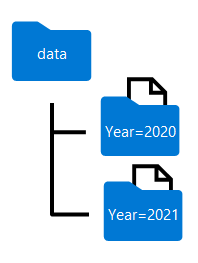
Názvy složek vygenerované při dělení datového rámce zahrnují název a hodnotu sloupce dělení ve formátu column=value , jak je znázorněno tady:
Poznámka:
Data můžete rozdělit podle několika sloupců, což vede k hierarchii složek pro každý klíč dělení. Můžete například rozdělit pořadí v příkladu podle roku a měsíce, aby hierarchie složek obsahovala složku pro každou hodnotu roku, která zase obsahuje podsložku pro každou hodnotu měsíce.
Filtrování souborů parquet v dotazu
Při čtení dat ze souborů parquet do datového rámce máte možnost načítat data z libovolné složky v hierarchických složkách. Tento proces filtrování se provádí s použitím explicitních hodnot a zástupných znaků pro dělená pole.
V následujícím příkladu následující kód stáhne prodejní objednávky, které byly umístěny v roce 2020.
orders_2020 = spark.read.parquet('/partitioned_data/Year=2020')
display(orders_2020.limit(5))
Poznámka:
Ve výsledném datovém rámci se vynechá sloupce dělení zadané v cestě k souboru. Výsledky vytvořené ukázkovým dotazem neobsahují sloupec Year – všechny řádky budou od roku 2020.